











將傳統系統現代化為微服務架構是一段充滿技術與組織挑戰的旅程。雖然許多團隊高度關注程式碼重構與容器化,但一個顯著的障礙往往出現在資料層。具體而言,傳統的實體關係圖(ERD)模型在轉向分散式系統時,可能成為嚴重的限制。 📉
當您設計單一應用程式時,資料模型是集中的。ERD 代表唯一的真實來源,以正規化表格透過外鍵連結。此方法在單一資料庫執行個體中運作良好。然而,微服務需要自主性。當您將單一應用程式的 ERD 結構強加於分散式架構時,會產生緊密耦合,從而抵消拆分系統所帶來的好處。 🚧
本指南探討傳統 ERD 思維模式如何阻礙微服務的採用,並提供實用的轉型路徑,協助您調整資料模型策略。我們將涵蓋分散式資料管理、一致性模型,以及符合領域驅動設計原則的視覺化技術。 🗺️
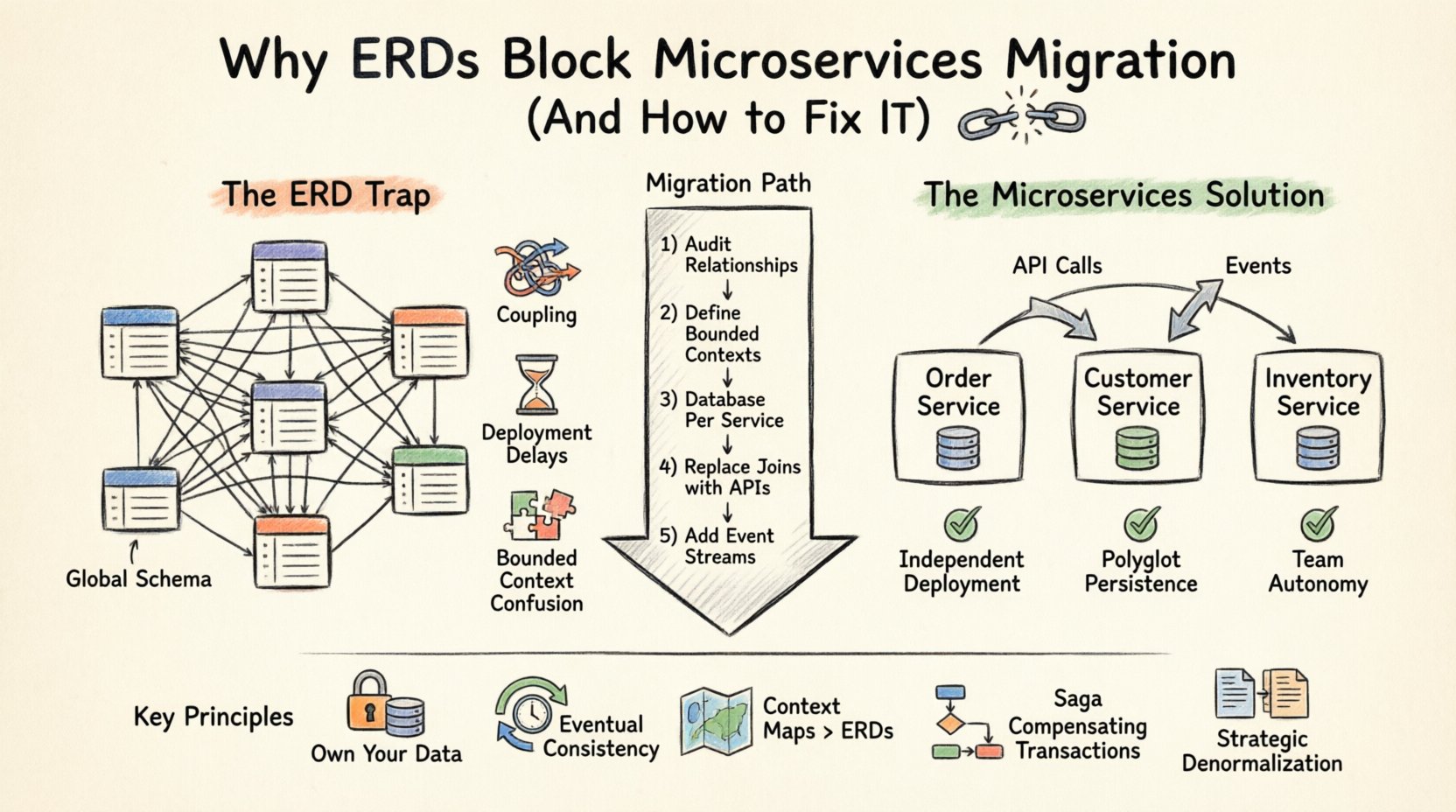
理解分散式系統中的 ERD 陷阱 🧩
實體關係圖是資料庫邏輯結構的視覺化表示。它定義了實體(表格)、屬性(欄位)和關係(外鍵)。在單一應用程式環境中,這種集中化是一大優勢。它透過 ACID 交易確保資料完整性,並簡化對整個應用程式的查詢。
然而,微服務架構建立在「服務自主性」原則之上。每個服務應擁有其資料,並僅透過 API 暴露。當您維持一個跨越多個服務的共享 ERD 時,便違反了所有權的界線。這會導致以下問題:
- 全域結構依賴: 如果服務 A 需要在資料庫層級直接與服務 B 的資料進行關聯,它們就不再獨立。服務 B 的結構變更會導致服務 A 失效。
- 交易邊界: 跨多個資料庫的 ACID 交易複雜且效能負擔沉重。分散式交易經常導致鎖競爭與延遲波動。
- 部署耦合: 如果您的資料模型是共享的,便無法獨立部署服務。您必須跨團隊協調結構變更,從而拖慢發布週期。
- 封閉上下文混淆: 不同的服務可能對同一實體有不同的理解。ERD 強制單一定義,忽略了領域特定的細節差異。
耦合問題:外鍵與關聯 🔗
遷移過程中最常見的錯誤之一,是在拆分應用程式程式碼的同時,試圖保持現有資料庫結構不變。這會導致「共享資料庫反模式」。在此情境下,多個服務連接到同一個資料庫執行個體,依賴外鍵來維持關係。
雖然這看起來像是有效的 ERD 結構,但其實是一種隱藏的單一應用程式。以下是此方法在微服務環境中失敗的原因:
- 網路延遲: 即使資料庫位於同一網路內,跨服務查詢仍會引入網路跳躍,導致效能劣於本地查詢。
- 單點故障: 如果資料庫當機,所有服務都會當機。微服務的目標是透過隔離來實現韌性。
- 安全風險: 本不應直接存取其他資料的服務,仍可透過資料庫連接字串存取資料。API 提供受控介面;直接存取資料庫則無法做到。
- 技術鎖定: 所有服務都必須使用相同的資料庫技術。微服務允許多語言持久化,讓不同服務可根據其特定需求使用最合適的資料儲存方式。
為了解決這個問題,您必須遠離跨服務邊界的 SQL 連接。相反地,您應該使用 API 組合或事件驅動的資料同步。 🔄
每個服務一個資料庫:黃金法則 🏦
微服務資料架構的基礎模式是每個服務一個資料庫。每個服務擁有自己的資料庫結構。其他任何服務都不得直接存取此資料庫。通訊必須完全透過服務的公開 API 進行。
這種轉變需要您在視覺化資料的方式上進行根本性的改變。您不能再為整個系統繪製一個巨大的實體關係圖(ERD)。相反地,您應為每個服務建立多個較小的 ERD。 📄
| 面向 | 單體式 ERD | 微服務模型 |
|---|---|---|
| 結構範圍 | 全域/整合式 | 本地/服務特定 |
| 關係 | 外鍵 | API 呼叫/事件 |
| 一致性 | 強一致性(ACID) | 最終一致性(BASE) |
| 部署 | 緊耦合 | 獨立 |
在沒有共享交易的情況下管理一致性 🤝
當您分離資料庫時,便失去了執行單一交易同時更新服務 A 和服務 B 的能力。在單體系統中,您可能會使用資料庫交易將資金從帳戶 A 轉移到帳戶 B。但在微服務中,這些帳戶可能屬於不同的服務。
由於您無法確保分散式系統之間的即時一致性,因此必須採用最終一致性。這表示系統將在一段時間後達到一致狀態,但不一定在使用者點擊按鈕的那一刻立即達成。
實作 Sagas
為了處理跨越多個服務的複雜工作流程,請使用Saga 模式。Sagas 是一系列本地交易,其中每個交易只會更新單一服務內的資料庫。如果某一步驟失敗,Sagas 會執行補償交易,以撤銷先前步驟所造成的變更。
- 編舞: 服務會發出事件,觸發其他服務的動作。沒有中央協調者。
- 指揮: 一個中央協調服務管理工作流程,並告訴其他服務該做什麼。
這種方法確保資料完整性,而無需共享鎖或分散式交易。雖然會增加實作的複雜度,但對於維持系統健康是必要的。🛡️
無需ERD即可視化資料:情境地圖 🗺️
如果你放棄傳統的ERD,你會用什麼來視化你的資料架構?答案就在於領域驅動設計(DDD)情境地圖。雖然ERD專注於資料表和欄位,情境地圖則專注於有界上下文與關係。
不再在資料表之間畫線,而是於服務之間畫線。你定義資料在它們之間如何流動:
- 客戶-供應商: 一個服務向另一個服務提供資料。提供者定義合約。
- 順從者: 使用服務必須適應提供者的模型。
- 開放主機服務: 一個服務透過開放協定公開其資料。
- 分道揚鑣: 兩個服務各自獨立地發展其模型。
這種視覺化方式的轉變,有助於團隊理解為什麼資料會被重複。在單體系統中,重複是壞事。在微服務中,重複通常是為了解耦服務而設計的功能。例如,訂單服務可能會儲存客戶姓名的快照,以避免每次檢視訂單時都進行網路呼叫。這種取捨在性能上是可以接受的。
遷移步驟:從ERD轉向分散式資料 🚀
從集中式的ERD轉向分散式資料模型並非一次性的事件,而是一個分階段的過程。以下是一種建議的方法,用來管理遷移。
步驟1:審查現有的資料關係
在拆分任何內容之前,請記錄下當前ERD中的每一種關係。識別哪些資料表是讀取密集型,哪些是寫入密集型,以及哪些經常被關聯。此分析有助於將實體分組為邏輯服務邊界。📊
步驟2:定義有界上下文
根據業務領域而非技術依賴關係對實體進行分組。例如,一個產品目錄與一個庫存管理系統不同,即使它們都使用ProductID欄位。確保邊界與團隊結構一致(康威定律)。
步驟 3:為每個服務實現獨立資料庫
為每個服務建立新的資料庫實例。從單體資料庫中遷移相關資料。不需要立即移動所有內容。從服務運作所需的關鍵資料開始。🏗️
步驟 4:以 API 呼叫取代 JOIN 操作
重構您的查詢。不再使用JOIN Orders, Customers,您的程式碼應呼叫Customer API以取得詳細資訊。這可能會引入延遲,因此在適當情況下應考慮快取策略或反規範化。
步驟 5:引入事件串流
為了即時更新,實作事件總線。當某個服務中的實體發生變更時,發佈事件。其他服務可訂閱這些事件,以更新其本地資料副本。這可確保最終一致性,且無直接耦合。
遷移過程中的常見陷阱 ⚠️
即使有計畫,團隊在轉換過程中仍經常出錯。請留意這些常見問題。
- 過早拆分:在理解資料流程之前,不要拆分服務。過早拆分可能導致在準備不足時就出現分散式複雜性。
- 忽視資料所有權:如果多個團隊聲稱對同一個資料實體擁有所有權,將會產生衝突。應為每個服務明確分配所有權。
- 過度規範化:在分散式系統中,通常偏好反規範化,以減少渲染頁面所需的 API 呼叫次數。
- 過度依賴網路:永遠不要假設網路是完美的。為服務間通訊實作逾時、重試與電路斷路器。
組織對齊 🤝
資料架構不僅是技術問題,更是組織問題。分散式資料模型要求團隊以不同方式溝通。在單體系統中,開發人員透過共享的白板(資料庫)溝通。在微服務中,他們則透過 API 合約溝通。
確保你的團隊能夠自主變更其資料庫結構,無需諮詢中央治理委員會。這種自主性是維持獨立部署速度的唯一途徑。如果你引入一個中央團隊來審核所有結構變更,你將重新引入原本想要消除的瓶頸。👥
數據戰略的最終考量 🧭
遠離傳統的實體關係圖是一項重大舉措。這需要思維上的轉變,從透過限制條件維持資料完整性轉向透過應用程式邏輯與事件維持資料完整性。ERD 是關係型資料庫的工具,而非分散式系統的藍圖。
透過採用「每個服務對應一個資料庫」的模式,運用事件驅動架構,並聚焦於有限上下文,你可以避免拖慢遷移過程的耦合問題。目標並非摧毀現有的資料模型,而是使其演進為支援獨立擴展與韌性的結構。
請記住,一致性是一種光譜。你不需要在所有地方都追求強一致性。辨識出系統中哪些部分需要嚴格的準確性,哪些部分可以接受最終一致性。這種務實態度將幫助你避免過度設計解決方案。
從審核現有的圖表開始。找出跨越服務邊界的連接(join)。規劃這些特定實體的遷移。採取小步前進的方式。驗證結果。並始終將業務領域放在資料設計的核心位置。 🎯
關鍵要點 📝
- 避免服務之間共用資料庫,以防止耦合。
- 跨服務資料應使用 API 組合,而非 SQL 連接。
- 接受最終一致性,以獲得可用性與分割容錯能力。
- 使用上下文地圖來視覺化資料,而非全域的 ERD。
- 將明確的資料所有權分配給各個服務團隊。
- 規劃資料複製,作為效能優化的手段。
遵循這些原則,你可以在不讓 ERD 制約新架構限制的情況下,應對資料遷移的複雜性。未來的路徑是分散式、去中心化且專為擴展而設計的。 🚀