











Модернизация устаревшей системы до архитектуры микросервисов — это путь, полный технических и организационных трудностей. Хотя многие команды сильно сосредоточены на рефакторинге кода и контейнеризации, значительным препятствием часто становится слой данных. В частности, традиционная модель диаграммы отношений сущностей (ERD) может стать серьезным ограничением при переходе к распределенным системам. 📉
Когда вы проектируете монолитное приложение, ваша модель данных централизована. Диаграмма отношений сущностей представляет собой единственный источник истины, при этом нормализованные таблицы связаны внешними ключами. Такой подход хорошо работает для одного экземпляра базы данных. Однако микросервисы требуют автономии. Когда вы навязываете монолитную структуру ERD распределенной архитектуре, вы создаете тесную связь, которая аннулирует преимущества разбиения вашей системы. 🚧
В этом руководстве рассматривается, почему классический подход к ERD мешает внедрению микросервисов, и предлагается практический путь перехода к новым стратегиям моделирования данных. Мы рассмотрим управление распределенными данными, модели согласованности и методы визуализации, соответствующие принципам проектирования, ориентированного на домен. 🗺️
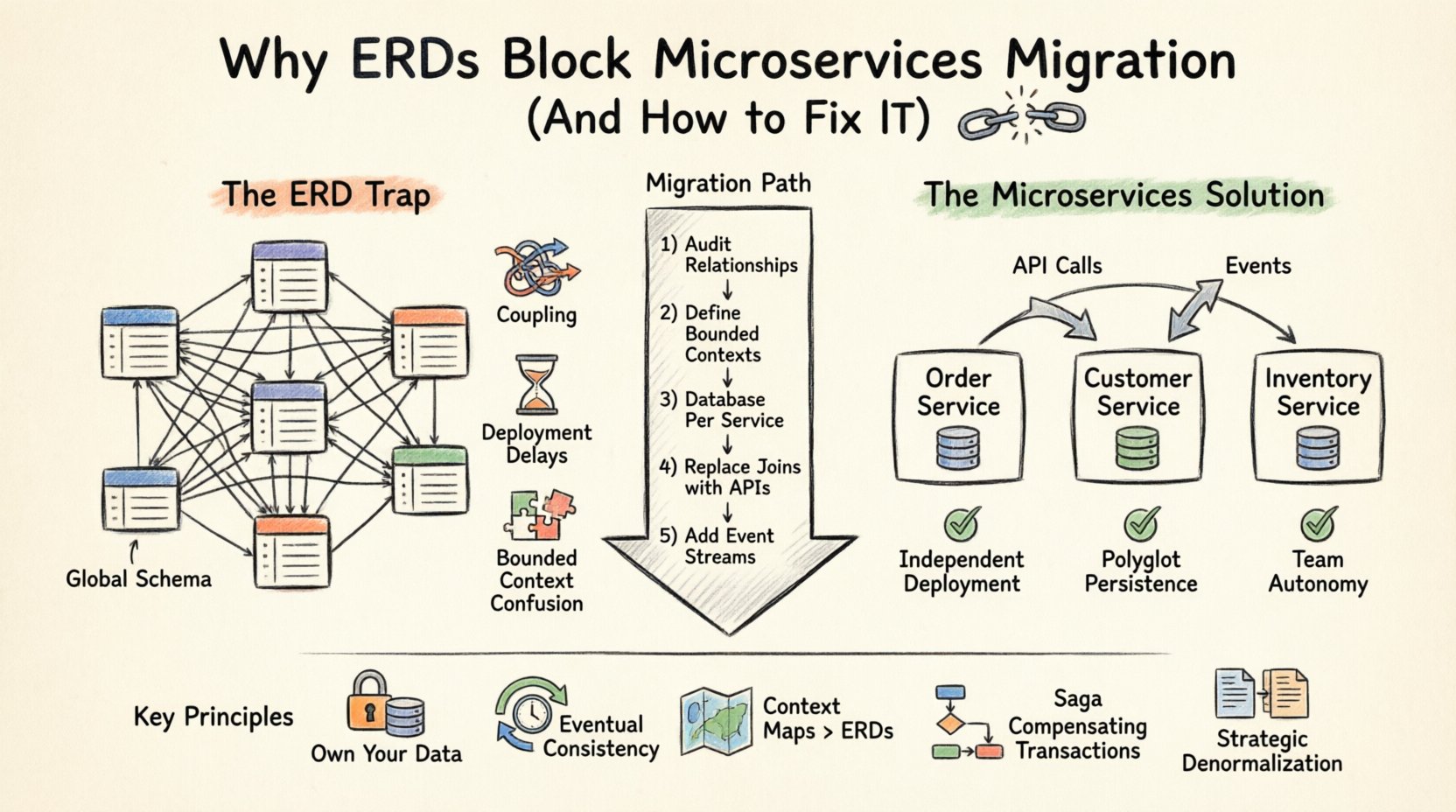
Понимание ловушки ERD в распределенных системах 🧩
Диаграмма отношений сущностей — это визуальное представление логической структуры базы данных. Она определяет сущности (таблицы), атрибуты (столбцы) и отношения (внешние ключи). В монолитной среде такая централизация является преимуществом. Она обеспечивает целостность данных с помощью транзакций ACID и упрощает запросы ко всей системе.
Однако архитектура микросервисов основана на принципенезависимости сервисов. Каждый сервис должен владеть своими данными и предоставлять их только через API. Когда вы поддерживаете общую ERD, охватывающую несколько сервисов, вы нарушаете границу владения. Это приводит к следующим проблемам:
- Глобальные зависимости схемы: Если сервис A должен объединять данные из сервиса B непосредственно на уровне базы данных, они уже не являются независимыми. Изменение схемы сервиса B приводит к сбоям в сервисе A.
- Границы транзакций: Транзакции ACID через несколько баз данных сложны и накладывают высокую нагрузку на производительность. Распределенные транзакции часто приводят к конфликтам блокировок и резким скачкам задержек.
- Связанность развертывания: Если ваша модель данных общая, вы не можете развертывать сервисы независимо. Вам необходимо координировать изменения схемы между командами, что замедляет циклы выпуска.
- Путаница в ограниченных контекстах: Разные сервисы могут по-разному трактовать одну и ту же сущность. ERD навязывает единственное определение, игнорируя особенности домена.
Проблема связывания: внешние ключи и соединения 🔗
Одной из самых распространенных ошибок при миграции является попытка сохранить существующую схему базы данных неизменной при разделении кода приложения. Это приводит кантипаттерну общей базы данных. В этом сценарии несколько сервисов подключаются к одному и тому же экземпляру базы данных, полагаясь на внешние ключи для поддержания связей.
Хотя это выглядит как корректная структура ERD, на самом деле это скрытый монолит. Вот почему такой подход не работает в контексте микросервисов:
- Задержки сети: Даже если база данных находится в пределах сети, запросы между сервисами вводят дополнительные сетевые переходы, что снижает производительность по сравнению с локальными запросами.
- Единая точка отказа: Если база данных выходит из строя, выходит из строя каждый сервис. Микросервисы нацелены на устойчивость за счет изоляции.
- Риски безопасности: Сервис, которому не следует иметь прямой доступ к другим данным, все равно может получить к ним доступ через строку подключения к базе данных. API обеспечивают контролируемый интерфейс; прямой доступ к БД — нет.
- Замкнутость на технологии: Все сервисы должны использовать одну и ту же технологию базы данных. Микросервисы позволяют использовать полиглотное хранение, при котором разные сервисы используют наиболее подходящее хранилище данных для своих конкретных потребностей.
Чтобы исправить это, вы должны отказаться от SQL-соединений через границы служб. Вместо этого вы должны использовать композицию API или синхронизацию данных на основе событий. 🔄
База данных на службу: Золотое правило 🏦
Основной паттерн архитектуры данных микросервисов — этоБаза данных на службу. Каждая служба владеет собственной схемой базы данных. Другие службы не имеют права напрямую обращаться к этой базе данных. Общение происходит строго через публичный API службы.
Этот переход требует фундаментального изменения подхода к визуализации ваших данных. Вы больше не можете рисовать одну гигантскую диаграмму ERD для всей системы. Вместо этого вы создаете несколько небольших диаграмм ERD — по одной для каждой службы. 📄
| Аспект | Монолитная диаграмма ERD | Модель микросервисов |
|---|---|---|
| Область действия схемы | Глобальная / Единая | Локальная / Специфичная для службы |
| Связи | Внешние ключи | Вызовы API / События |
| Согласованность | Сильная (ACID) | Потенциальная (BASE) |
| Развертывание | Связанная | Независимая |
Управление согласованностью без общих транзакций 🤝
Когда вы разделяете базы данных, вы теряете возможность выполнить одну транзакцию, которая одновременно обновит Service A и Service B. В монолите вы могли бы использовать транзакцию базы данных для перевода средств с счета A на счет B. В микросервисах эти счета могут принадлежать разным службам.
Поскольку вы не можете гарантировать немедленную согласованность в распределенных системах, вы должны принятьПотенциальную согласованность. Это означает, что система со временем достигнет согласованного состояния, но не обязательно в точный момент, когда пользователь нажмет кнопку.
Реализация саг
Чтобы обрабатывать сложные рабочие процессы, охватывающие несколько служб, используйтепаттерн саг. Сага — это последовательность локальных транзакций, при которой каждая транзакция обновляет базу данных в одной службе. Если шаг завершается неудачно, сага выполняет компенсирующие транзакции для отмены изменений, внесенных предыдущими шагами.
- Хореография:Сервисы генерируют события, которые запускают действия в других сервисах. Центрального координатора нет.
- Оркестрация:Центральный сервис координатора управляет рабочим процессом и указывает другим сервисам, что делать.
Этот подход обеспечивает целостность данных без необходимости в совместных блокировках или распределённых транзакциях. Он добавляет сложность реализации, но необходим для поддержания здоровья системы. 🛡️
Визуализация данных без ERD: карты контекстов 🗺️
Если вы отказываетесь от традиционного ERD, что вы используете для визуализации архитектуры данных? Ответ кроется вКарты контекстов по методологии проектирования, ориентированного на домен (DDD). В то время как ERD фокусируется на таблицах и столбцах, карта контекста фокусируется на ограниченных контекстах и отношениях.
Вместо того чтобы рисовать линии между таблицами, вы рисуете линии между сервисами. Вы определяете, как данные перемещаются между ними:
- Клиент-поставщик:Один сервис предоставляет данные другому. Поставщик определяет контракт.
- Согласующийся:Сервис, использующий данные, должен адаптироваться к модели поставщика.
- Открытый хост-сервис:Сервис публикует свои данные через открытый протокол.
- Отдельные пути:Оба сервиса независимо развивают свои модели.
Этот сдвиг в визуализации помогает командам понятьпочемуданные дублируются. В монолите дублирование — плохо. В микросервисах дублирование часто является особенностью, позволяющей развязать сервисы. Например, сервис заказовсервис заказовможет хранить снимокимени клиентачтобы избежать сетевого вызова каждый раз, когда просматривается заказ. Такой компромисс приемлем с точки зрения производительности.
Шаги миграции: переход от ERD к распределённым данным 🚀
Переход от централизованного ERD к распределённой модели данных — не одноразовое событие. Это поэтапный процесс. Вот рекомендуемый подход для управления миграцией.
Шаг 1: Аудит существующих связей данных
Прежде чем что-либо разделять, документируйте каждую связь в вашем текущем ERD. Определите, какие таблицы являются сильными в чтении, какие — в записи, и какие часто объединяются. Этот анализ помогает группировать сущности в логические границы сервисов. 📊
Шаг 2: Определение ограниченных контекстов
Группируйте сущности на основе бизнес-областей, а не технических зависимостей. Например, каталог продуктов отличается от системы управления запасами системы, даже если обе используют поле ProductID поле. Убедитесь, что границы совпадают со структурой команд (закон Конвея).
Шаг 3: Реализация базы данных на сервис
Создайте новую экземпляра базы данных для каждого сервиса. Перенесите соответствующие данные из монолитной базы данных. Вам не нужно сразу переносить всё. Начните с основных данных, необходимых для функционирования сервиса. 🏗️
Шаг 4: Замена JOIN на вызовы API
Перепишите свои запросы. Вместо JOIN Orders, Customers, ваш код должен вызывать API клиента для получения деталей. Это может привести к задержкам, поэтому рассмотрите стратегии кэширования или денормализацию при необходимости.
Шаг 5: Введение потоков событий
Для обновлений в реальном времени внедрите шину событий. Когда сущность изменяется в одном сервисе, публикуйте событие. Другие сервисы могут подписываться на эти события для обновления своих локальных копий данных. Это обеспечивает конечную согласованность без прямой привязки.
Распространённые ошибки при миграции ⚠️
Даже при наличии плана команды часто сталкиваются с трудностями во время перехода. Будьте внимательны к этим распространённым проблемам.
- преждевременное разделение: Не разделяйте сервисы до тех пор, пока не поймёте поток данных. Слишком раннее разделение может привести к распределённой сложности, пока вы к ней не готовы.
- Пренебрежение владением данными: Если несколько команд заявляют о владении одной и той же сущностью данных, возникнут конфликты. Назначьте чёткое владение каждому сервису.
- Чрезмерная нормализация: В распределённой системе денормализация часто предпочтительнее, чтобы сократить количество вызовов API, необходимых для отображения страницы.
- Зависимость от сети: Никогда не полагайтесь на идеальную сеть. Реализуйте таймауты, повторные попытки и прерыватели цепей для взаимодействия между сервисами.
Организационная согласованность 🤝
Архитектура данных — это не только техническая, но и организационная сфера. Распределённая модель данных требует от команд иного способа общения. В монолите разработчики общаются через общую доску (базу данных). В микросервисах они общаются через контракт API.
Убедитесь, что ваши команды могут изменять схему базы данных без консультаций с центральным органом управления. Только эта автономия позволяет сохранить скорость независимого развертывания. Если вы введёте центральную команду, одобряющую все изменения схемы, вы снова создадите узкое место, которое пытаетесь устранить. 👥
Заключительные соображения по стратегии данных 🧭
Отказ от традиционной диаграммы сущность-связь — это важный шаг. Это требует смены мышления отцелостности данных через ограничения кцелостности данных через логику приложения и события. Диаграмма сущность-связь — это инструмент для реляционных баз данных, а не чертеж для распределённых систем.
Приняв паттерн «База данных для каждого сервиса», используя архитектуру, основанную на событиях, и фокусируясь на ограниченных контекстах, вы можете избежать связывания, которое замедляет вашу миграцию. Цель — не уничтожать существующую модель данных, а развивать её в структуру, поддерживающую независимое масштабирование и отказоустойчивость.
Помните, что согласованность — это спектр. Вам не нужно строгое согласование повсюду. Определите, какие части вашей системы требуют строгой точности, а какие могут допускать конечное согласование. Такой прагматизм спасёт вас от чрезмерной сложности решения.
Начните с аудита текущих диаграмм. Определите соединения, пересекающие границы сервисов. Планируйте миграцию этих конкретных сущностей. Делайте небольшие шаги. Проверяйте результаты. И всегда держите бизнес-домен в центре вашей модели данных. 🎯
Ключевые выводы 📝
- Избегайте общих баз данных между сервисами, чтобы избежать связывания.
- Используйте композицию API вместо SQL-соединений для данных между сервисами.
- Примите конечное согласование, чтобы обеспечить доступность и устойчивость к разделению.
- Визуализируйте данные с помощью карт контекста, а не глобальных диаграмм сущность-связь.
- Назначьте чёткую ответственность за данные отдельным командам сервисов.
- Планируйте дублирование данных как оптимизацию производительности.
Следуя этим принципам, вы сможете преодолеть сложности миграции данных, не позволяя вашей диаграмме сущность-связь определять ограничения вашей новой архитектуры. Путь вперёд — распределённый, децентрализованный и рассчитанный на масштабирование. 🚀