











将遗留系统现代化为微服务架构是一条充满技术和组织挑战的旅程。尽管许多团队将大量精力集中在代码重构和容器化上,但一个显著的障碍往往出现在数据层。具体来说,传统的实体关系图(ERD)模型在向分布式系统过渡时可能成为严重制约因素。 📉
当你设计一个单体应用程序时,你的数据模型是集中的。ERD代表了单一的真相来源,通过外键连接的规范化表。这种方法在单个数据库实例中运行良好。然而,微服务需要自主性。当你将单体的ERD结构强加于分布式架构时,会产生紧密耦合,从而抵消了拆分系统所带来的优势。 🚧
本指南探讨了为什么传统的ERD思维模式会阻碍微服务的采用,并提供了一条实用的路线图,帮助你转变数据建模策略。我们将涵盖分布式数据管理、一致性模型以及与领域驱动设计原则相一致的可视化技术。 🗺️
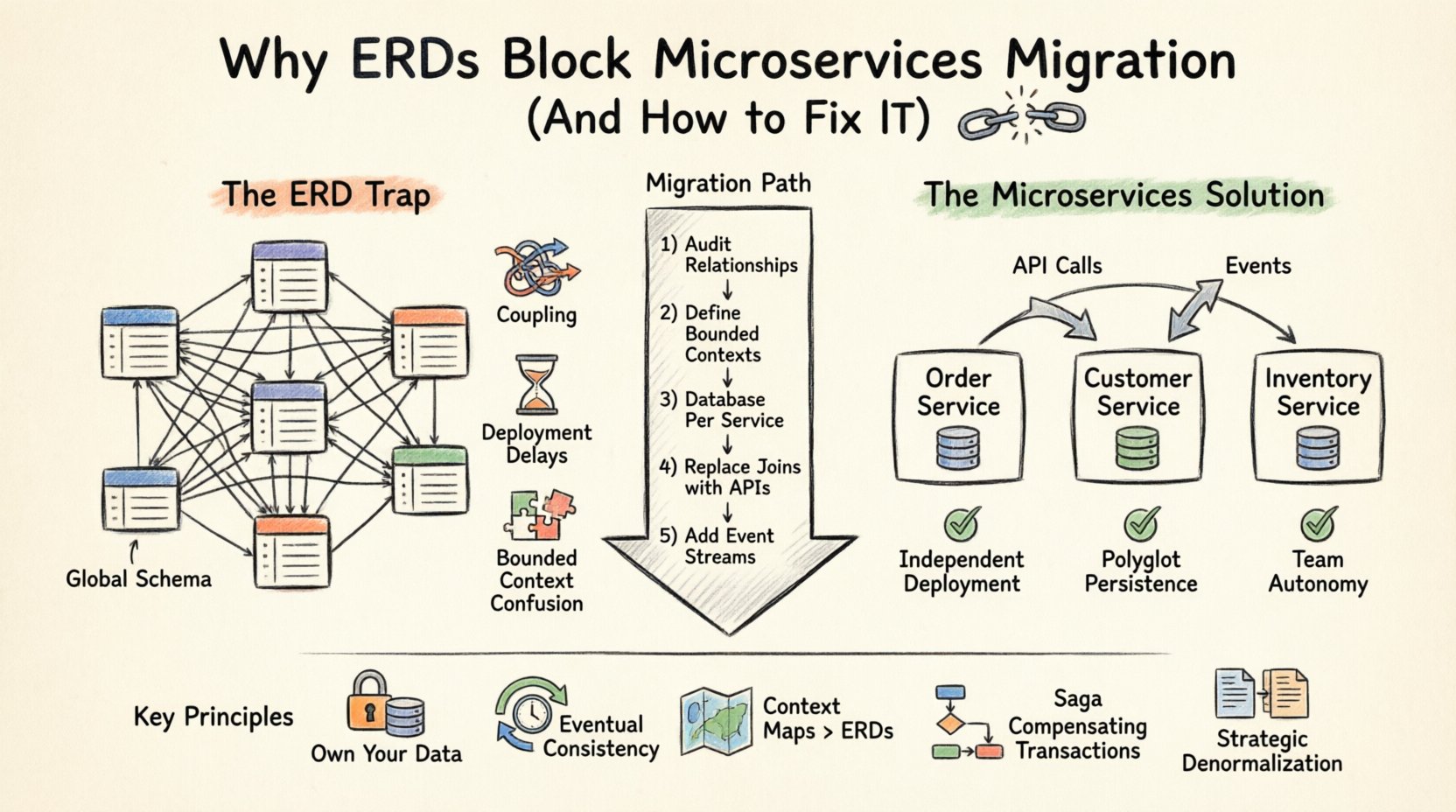
理解分布式系统中的ERD陷阱 🧩
实体关系图是数据库逻辑结构的可视化表示。它定义了实体(表)、属性(列)和关系(外键)。在单体环境中,这种集中化是一种优势。它通过ACID事务确保数据完整性,并简化了在整个应用程序中进行查询。
然而,微服务架构建立在服务独立性的原则之上。每个服务都应拥有自己的数据,并仅通过API暴露。当你维护一个跨越多个服务的共享ERD时,你就违反了所有权的边界。这会导致以下问题:
- 全局模式依赖:如果服务A需要在数据库层面直接连接服务B的数据,那么它们就不再独立。服务B的模式一旦更改,就会导致服务A失效。
- 事务边界:跨多个数据库的ACID事务复杂且性能开销大。分布式事务常常导致锁争用和延迟飙升。
- 部署耦合:如果数据模型是共享的,你就无法独立部署服务。你必须在团队之间协调模式变更,从而减慢发布周期。
- 有界上下文混淆:不同的服务可能对同一实体有不同的理解。ERD强制采用单一定义,忽略了领域特定的细微差别。
耦合问题:外键与连接 🔗
迁移过程中最常见的错误之一,就是在拆分应用程序代码的同时试图保持现有数据库模式不变。这会导致共享数据库反模式。在这种情况下,多个服务连接到同一个数据库实例,依赖外键来维持关系。
虽然这看起来像是一个有效的ERD结构,但实际上是一个隐藏的单体。以下是这种方法在微服务环境中失败的原因:
- 网络延迟:即使数据库位于本地网络中,跨服务查询也会引入网络跳转,导致性能相比本地查询下降。
- 单点故障:如果数据库宕机,每个服务都会宕机。微服务的目标是通过隔离实现弹性。
- 安全风险:一个本不应直接访问其他数据的服务,仍可通过数据库连接字符串访问。API提供受控接口;而直接访问数据库则不具备这种控制。
- 技术锁定:所有服务都必须使用相同的数据库技术。微服务允许使用多语言持久化,即不同服务可根据其特定需求使用最合适的数据存储。
为了解决这个问题,您必须摆脱跨服务边界使用SQL连接的做法。相反,您应该使用API组合或事件驱动的数据同步。 🔄
每个服务一个数据库:黄金法则 🏦
微服务数据架构的基础模式是每个服务一个数据库。每个服务拥有自己的数据库模式。不允许其他服务直接访问该数据库。通信必须严格通过服务的公共API进行。
这种转变要求您在可视化数据的方式上进行根本性改变。您不能再为整个系统绘制一个巨大的ERD。相反,您需要为每个服务创建多个较小的ERD。 📄
| 方面 | 单体ERD | 微服务模型 |
|---|---|---|
| 模式范围 | 全局/统一 | 本地/服务特定 |
| 关系 | 外键 | API调用/事件 |
| 一致性 | 强一致性(ACID) | 最终一致性(BASE) |
| 部署 | 耦合 | 独立 |
在没有共享事务的情况下管理一致性 🤝
当您分离数据库时,就失去了同时更新服务A和服务B的单一事务能力。在单体架构中,您可能使用数据库事务将资金从账户A转移到账户B。在微服务架构中,这些账户可能属于不同的服务。
由于无法保证分布式系统中的即时一致性,您必须采用最终一致性。这意味着系统将在一段时间后达到一致状态,但不一定是用户点击按钮的那一刻。
实现Saga模式
为了处理跨越多个服务的复杂工作流,请使用Saga模式。Saga是一系列本地事务的序列,其中每个事务仅更新单个服务内的数据库。如果某一步骤失败,Saga将执行补偿事务,以撤销之前步骤所做的更改。
- 编排: 服务会发出事件,触发其他服务中的操作。没有中央协调者。
- 编排: 一个中央协调服务管理工作流,并告诉其他服务该做什么。
这种方法确保了数据完整性,而无需使用共享锁或分布式事务。虽然会增加实现的复杂性,但为了保持系统健康是必要的。🛡️
无需ERD来可视化数据:上下文地图 🗺️
如果你放弃了传统的ERD,你会用什么来可视化你的数据架构?答案在于领域驱动设计(DDD)上下文地图。虽然ERD关注的是表和列,但上下文地图关注的是有界上下文和关系。
与其在表之间画线,不如在服务之间画线。你定义数据在它们之间如何流动:
- 客户-供应商: 一个服务向另一个服务提供数据。提供方定义合同。
- 遵从者: 消费方服务必须适应提供方的模型。
- 开放主机服务: 一个服务通过开放协议暴露其数据。
- 独立发展: 两个服务独立地发展自己的模型。
这种可视化方式的转变有助于团队理解为什么数据会被复制。在单体架构中,复制是坏事。但在微服务中,复制通常是解耦服务的一种特性。例如,订单服务可能会存储客户姓名的快照,以避免每次查看订单时都进行网络调用。这种权衡在性能上是可以接受的。
迁移步骤:从ERD转向分布式数据 🚀
从集中式的ERD转向分布式数据模型并不是一次性的事件,而是一个分阶段的过程。以下是一种推荐的方法来管理迁移。
步骤1:审计现有的数据关系
在拆分任何内容之前,请记录下当前ERD中的每一个关系。识别哪些表是读取密集型的,哪些是写入密集型的,哪些表经常被连接。这种分析有助于将实体分组到逻辑服务边界中。📊
步骤2:定义有界上下文
根据业务领域而非技术依赖关系对实体进行分组。例如,一个产品目录与一个库存管理系统不同,即使它们都使用ProductID字段。确保边界与团队结构保持一致(康威定律)。
步骤3:为每个服务实现独立数据库
为每个服务创建一个新的数据库实例。将单体数据库中的相关数据迁移过来。你不需要立即迁移所有内容。从服务运行所必需的核心数据开始。🏗️
步骤4:用API调用替代JOIN操作
重构你的查询。不再使用JOIN Orders, Customers,你的代码应调用Customer API来获取详细信息。这可能会引入延迟,因此在适当情况下应考虑使用缓存策略或反规范化。
步骤5:引入事件流
为了实现实时更新,应实现事件总线。当一个服务中的实体发生变化时,发布一个事件。其他服务可以订阅这些事件,以更新其本地数据副本。这确保了最终一致性,而无需直接耦合。
迁移过程中的常见陷阱 ⚠️
即使有计划,团队在迁移过程中仍常常遇到问题。请留意这些常见问题。
- 过早拆分:在理解数据流之前不要拆分服务。过早拆分可能导致在准备不足时就出现分布式复杂性。
- 忽视数据所有权:如果多个团队声称对同一数据实体拥有所有权,就会产生冲突。应为每个服务明确分配所有权。
- 过度规范化:在分布式系统中,通常更倾向于反规范化,以减少渲染页面所需的API调用次数。
- 对网络的依赖:永远不要假设网络是完美的。为服务间通信实现超时、重试和熔断机制。
组织对齐 🤝
数据架构不仅是技术问题,更是组织问题。分布式数据模型要求团队以不同的方式沟通。在单体架构中,开发者通过共享的白板(数据库)进行交流。在微服务中,他们通过API契约进行沟通。
确保你的团队能够自主更改其数据库模式,而无需咨询中央治理委员会。这种自主性是保持独立部署速度的唯一途径。如果你引入一个需要批准所有模式变更的中央团队,你就会重新引入你试图消除的瓶颈。👥
数据战略的最终考量 🧭
远离传统的实体关系图是一个重要的步骤。这需要思维方式的转变,从通过约束保证数据完整性转变为通过应用逻辑和事件保证数据完整性。ERD是关系型数据库的工具,而不是分布式系统的蓝图。
通过采用每个服务独立数据库的模式,利用事件驱动架构,并聚焦于有界上下文,你可以避免拖慢迁移过程的耦合问题。目标不是摧毁现有的数据模型,而是将其演进为支持独立扩展和弹性的结构。
请记住,一致性是一个光谱。你不需要在所有地方都使用强一致性。识别出系统中哪些部分需要严格准确,哪些可以接受最终一致性。这种务实的态度将帮助你避免过度设计解决方案。
首先审查你当前的图表。识别出跨越服务边界的连接。规划这些特定实体的迁移。采取小步前进的方式。验证结果。并始终将业务领域作为数据设计的核心。🎯
关键要点 📝
- 避免服务间共享数据库,以防止耦合。
- 使用API组合而非SQL连接来处理跨服务数据。
- 接受最终一致性,以获得可用性和分区容错性。
- 使用上下文图而非全局ERD来可视化数据。
- 为每个服务团队明确分配数据所有权。
- 将数据复制作为性能优化的计划。
遵循这些原则,你可以在不使ERD限制新架构的情况下,应对数据迁移的复杂性。前进的道路是分布式的、去中心化的,并且专为可扩展性而设计。🚀