











Modernizar un sistema heredado para convertirlo en una arquitectura de microservicios es un camino lleno de desafíos técnicos y organizativos. Mientras que muchos equipos se enfocan intensamente en el refactorización de código y la contenerización, un obstáculo significativo a menudo reside en la capa de datos. Específicamente, el modelo tradicional de diagramas de relaciones de entidades (ERD) puede convertirse en una restricción grave al pasar a sistemas distribuidos. 📉
Cuando diseñas una aplicación monolítica, tu modelo de datos es centralizado. Un ERD representa la única fuente de verdad, con tablas normalizadas unidas por claves foráneas. Este enfoque funciona bien para una única instancia de base de datos. Sin embargo, los microservicios requieren autonomía. Cuando fuerzas una estructura de ERD monolítica sobre una arquitectura distribuida, creas un acoplamiento estrecho que anula los beneficios de descomponer tu sistema. 🚧
Esta guía explora por qué la mentalidad clásica de ERD obstaculiza la adopción de microservicios y proporciona una hoja de ruta práctica para transformar tus estrategias de modelado de datos. Cubriremos la gestión distribuida de datos, modelos de consistencia y técnicas de visualización que se alinean con los principios del diseño centrado en el dominio. 🗺️
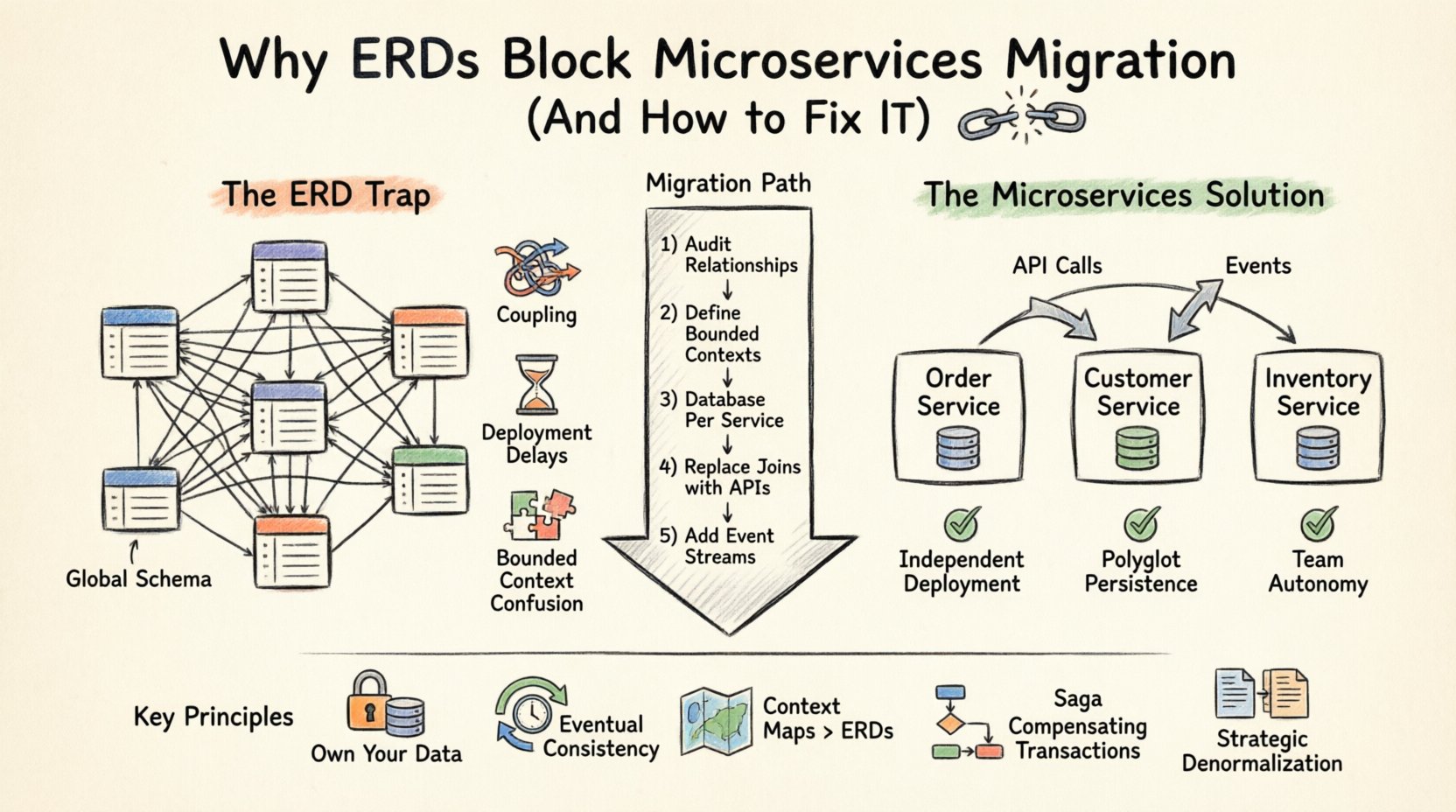
Comprender la trampa del ERD en sistemas distribuidos 🧩
Un diagrama de relaciones de entidades es una representación visual de la estructura lógica de una base de datos. Define entidades (tablas), atributos (columnas) y relaciones (claves foráneas). En un entorno monolítico, esta centralización es una ventaja. Garantiza la integridad de los datos mediante transacciones ACID y simplifica las consultas a través de toda la aplicación.
Sin embargo, la arquitectura de microservicios se basa en el principio de independencia del servicio. Cada servicio debe poseer sus propios datos y exponerlos únicamente a través de una API. Cuando mantienes un ERD compartido que abarca múltiples servicios, violas la frontera de propiedad. Esto conduce a los siguientes problemas:
- Dependencias de esquema globales: Si el servicio A necesita unir datos del servicio B directamente a nivel de base de datos, ya no son independientes. Un cambio en el esquema del servicio B rompe al servicio A.
- Límites de transacción: Las transacciones ACID entre múltiples bases de datos son complejas y de alto costo en rendimiento. Las transacciones distribuidas a menudo provocan contención de bloqueos y picos de latencia.
- Acoplamiento en la implementación: Si tu modelo de datos es compartido, no puedes implementar servicios de forma independiente. Debes coordinar los cambios de esquema entre equipos, lo que ralentiza los ciclos de lanzamiento.
- Confusión en el contexto acotado: Diferentes servicios pueden interpretar la misma entidad de forma distinta. Un ERD impone una única definición, ignorando las particularidades específicas del dominio.
El problema de acoplamiento: claves foráneas y uniones 🔗
Uno de los errores más comunes durante la migración es intentar mantener intacto el esquema de base de datos existente mientras se divide el código de la aplicación. Esto da lugar a un anti-patrón de base de datos compartida. En esta situación, múltiples servicios se conectan a la misma instancia de base de datos, confiando en claves foráneas para mantener las relaciones.
Aunque esto parece una estructura de ERD válida, es un monolito oculto. Aquí está por qué este enfoque falla en un contexto de microservicios:
- Latencia de red: Aunque la base de datos esté localizada en la red, las consultas entre servicios introducen saltos de red que degradan el rendimiento en comparación con las consultas locales.
- Punto único de fallo: Si la base de datos falla, todos los servicios también fallan. Los microservicios buscan resiliencia mediante aislamiento.
- Riesgos de seguridad: Un servicio que no debería tener acceso directo a otros datos aún puede acceder a ellos a través de la cadena de conexión de la base de datos. Las APIs proporcionan una interfaz controlada; el acceso directo a la base de datos no lo hace.
- Atracción tecnológica: Todos los servicios deben usar la misma tecnología de base de datos. Los microservicios permiten la persistencia políglota, donde diferentes servicios usan el almacén de datos más adecuado para sus necesidades específicas.
Para solucionar esto, debe alejarse de los joins de SQL a través de los límites de los servicios. En su lugar, debe utilizar la composición de API o la sincronización de datos impulsada por eventos. 🔄
Base de datos por servicio: La regla de oro 🏦
El patrón fundamental para la arquitectura de datos de microservicios es Base de datos por servicio. Cada servicio posee su propio esquema de base de datos. Ningún otro servicio tiene permitido acceder directamente a esta base de datos. La comunicación ocurre estrictamente a través de la API pública del servicio.
Este cambio requiere un cambio fundamental en la forma en que visualiza sus datos. Ya no puede dibujar un único ERD gigantesco para todo el sistema. En su lugar, crea múltiples ERD más pequeños, uno para cada servicio. 📄
| Aspecto | ERD monolítico | Modelo de microservicios |
|---|---|---|
| Alcance del esquema | Global / Unificado | Local / Específico del servicio |
| Relaciones | Claves foráneas | Llamadas a API / Eventos |
| Consistencia | Fuerte (ACID) | Eventual (BASE) |
| Despliegue | Acoplado | Independiente |
Gestionar la consistencia sin transacciones compartidas 🤝
Cuando separa las bases de datos, pierde la capacidad de ejecutar una única transacción que actualice simultáneamente el Servicio A y el Servicio B. En un monolito, podría usar una transacción de base de datos para transferir dinero de la Cuenta A a la Cuenta B. En microservicios, estas cuentas podrían pertenecer a servicios diferentes.
Dado que no puede garantizar la consistencia inmediata en sistemas distribuidos, debe adoptar Consistencia eventual. Esto significa que el sistema alcanzará un estado consistente con el tiempo, pero no necesariamente en el momento exacto en que el usuario hace clic en un botón.
Implementación de sagas
Para manejar flujos de trabajo complejos que abarcan múltiples servicios, utilice el patrón Saga. Una saga es una secuencia de transacciones locales donde cada transacción actualiza la base de datos dentro de un único servicio. Si un paso falla, la saga ejecuta transacciones compensatorias para deshacer los cambios realizados por los pasos anteriores.
- Coreografía:Los servicios emiten eventos que desencadenan acciones en otros servicios. No hay un coordinador central.
- Orquestación:Un servicio coordinador central gestiona el flujo de trabajo y indica a otros servicios qué hacer.
Este enfoque garantiza la integridad de los datos sin requerir bloqueos compartidos ni transacciones distribuidas. Añade complejidad a la implementación, pero es necesario para mantener la salud del sistema. 🛡️
Visualización de datos sin ERD: Mapas de contexto 🗺️
Si abandona el ERD tradicional, ¿qué utiliza para visualizar su arquitectura de datos? La respuesta está enMapas de contexto del Diseño Dirigido por Dominio (DDD). Mientras que un ERD se centra en tablas y columnas, un mapa de contexto se centra en contextos delimitados y relaciones.
En lugar de dibujar líneas entre tablas, dibujas líneas entre servicios. Definirás cómo fluye la data entre ellos:
- Cliente-Proveedor:Un servicio proporciona datos a otro. El proveedor define el contrato.
- Conformista:El servicio consumidor debe adaptarse al modelo del proveedor.
- Servicio de hospedaje abierto:Un servicio expone sus datos mediante un protocolo abierto.
- Camino separado:Ambos servicios evolucionan sus propios modelos de forma independiente.
Este cambio en la visualización ayuda a los equipos a comprenderpor quéla data se duplica. En un monolito, la duplicación es mala. En microservicios, la duplicación a menudo es una característica para desacoplar servicios. Por ejemplo, elServicio de pedidospodría almacenar una instantánea delNombre del clientepara evitar una llamada de red cada vez que se visualiza un pedido. Esta compensación es aceptable para el rendimiento.
Pasos de migración: pasar del ERD a datos distribuidos 🚀
Transitar de un ERD centralizado a un modelo de datos distribuido no es un evento único. Es un proceso por fases. Aquí se presenta un enfoque recomendado para gestionar la migración.
Paso 1: Auditoría de las relaciones de datos existentes
Antes de dividir cualquier cosa, documenta cada relación en tu ERD actual. Identifica qué tablas son de lectura intensiva, cuáles de escritura intensiva y cuáles se unen con frecuencia. Este análisis te ayuda a agrupar entidades en límites lógicos de servicios. 📊
Paso 2: Definir contextos delimitados
Agrupa las entidades según dominios de negocio en lugar de dependencias técnicas. Por ejemplo, una Catálogo de Productos es diferente de una Gestión de Inventarios sistema, incluso si ambas usan el campo ProductID campo. Asegúrate de que los límites coincidan con las estructuras del equipo (Ley de Conway).
Paso 3: Implementar una base de datos por servicio
Crea una instancia de base de datos nueva para cada servicio. Mueve los datos relevantes desde la base de datos monolítica. No necesitas mover todo de inmediato. Comienza con los datos centrales necesarios para que el servicio funcione. 🏗️
Paso 4: Reemplazar los JOIN por llamadas a API
Refactoriza tus consultas. En lugar de JOIN Pedidos, Clientes, tu código debería llamar a la API de Cliente para obtener detalles. Esto podría introducir latencia, por lo que considera estrategias de caché o desnormalización cuando sea apropiado.
Paso 5: Introducir flujos de eventos
Para actualizaciones en tiempo real, implementa un bus de eventos. Cuando una entidad cambia en un servicio, publica un evento. Otros servicios pueden suscribirse a estos eventos para actualizar sus copias locales de los datos. Esto garantiza la consistencia eventual sin acoplamiento directo.
Errores comunes durante la migración ⚠️
Aunque tengas un plan, los equipos a menudo tropiezan durante la transición. Sé consciente de estos problemas comunes.
- división prematura: No dividas los servicios antes de entender el flujo de datos. Dividir demasiado pronto puede generar complejidad distribuida antes de estar preparado.
- Ignorar la propiedad de los datos: Si múltiples equipos reclaman la propiedad de la misma entidad de datos, surgirán conflictos. Asigna una propiedad clara a cada servicio.
- Sobrenormalización: En un sistema distribuido, a menudo se prefiere la desnormalización para reducir el número de llamadas a la API necesarias para renderizar una página.
- Dependencia de la red: Nunca asumas que la red es perfecta. Implementa tiempos de espera, reintentos y interruptores de circuito para la comunicación entre servicios.
Alineación organizacional 🤝
La arquitectura de datos no es solo técnica; es organizacional. Un modelo de datos distribuido requiere que los equipos se comuniquen de forma diferente. En un monolito, los desarrolladores hablan sobre un pizarrón compartido (la base de datos). En microservicios, hablan sobre el contrato de la API.
Asegúrate de que tus equipos tengan el poder para cambiar su esquema de base de datos sin consultar a un comité de gobernanza central. Esta autonomía es la única forma de mantener la velocidad de despliegue independiente. Si introduces un equipo central que apruebe todos los cambios de esquema, reintroduces el cuello de botella que intentabas eliminar. 👥
Consideraciones Finales para la Estrategia de Datos 🧭
Alejarse de un Diagrama de Relación de Entidades tradicional es un paso importante. Requiere un cambio de mentalidad desdela integridad de los datos mediante restriccioneshaciala integridad de los datos mediante lógica de aplicación y eventos. El ERD es una herramienta para bases de datos relacionales, no un plano para sistemas distribuidos.
Al adoptar el patrón de Base de Datos por Servicio, utilizar una arquitectura impulsada por eventos y centrarse en contextos acotados, puedes evitar el acoplamiento que ralentiza tu migración. El objetivo no es destruir tu modelo de datos existente, sino evolucionarlo hacia una estructura que permita escalabilidad independiente y resiliencia.
Recuerda que la consistencia es un espectro. No necesitas consistencia fuerte en todas partes. Identifica qué partes de tu sistema requieren precisión estricta y cuáles pueden tolerar consistencia eventual. Esta pragmática te ahorrará de sobrediseñar tu solución.
Empieza auditando tus diagramas actuales. Identifica las uniones que cruzan los límites de los servicios. Planifica la migración de esas entidades específicas. Da pasos pequeños. Verifica los resultados. Y mantén siempre el dominio del negocio en el centro de tu diseño de datos. 🎯
Conclusiones Clave 📝
- Evita bases de datos compartidas entre servicios para prevenir el acoplamiento.
- Utiliza la composición de API en lugar de uniones SQL para datos entre servicios.
- Acepta la consistencia eventual para obtener disponibilidad y tolerancia a particiones.
- Visualiza los datos utilizando Mapas de Contexto en lugar de ERDs globales.
- Asigna una propiedad clara de los datos a los equipos individuales de servicios.
- Planifica la duplicación de datos como una optimización de rendimiento.
Siguiendo estos principios, puedes navegar las complejidades de la migración de datos sin que tu ERD determine las limitaciones de tu nueva arquitectura. El camino hacia adelante es distribuido, descentralizado y diseñado para escalar. 🚀