











Modernizar um sistema legado para uma arquitetura de microserviços é uma jornada cheia de desafios técnicos e organizacionais. Embora muitas equipes se concentrem intensamente na refatoração de código e containerização, um obstáculo significativo frequentemente está na camada de dados. Especificamente, o modelo tradicional de Diagrama de Relacionamento de Entidades (ERD) pode se tornar uma restrição grave ao passar para sistemas distribuídos. 📉
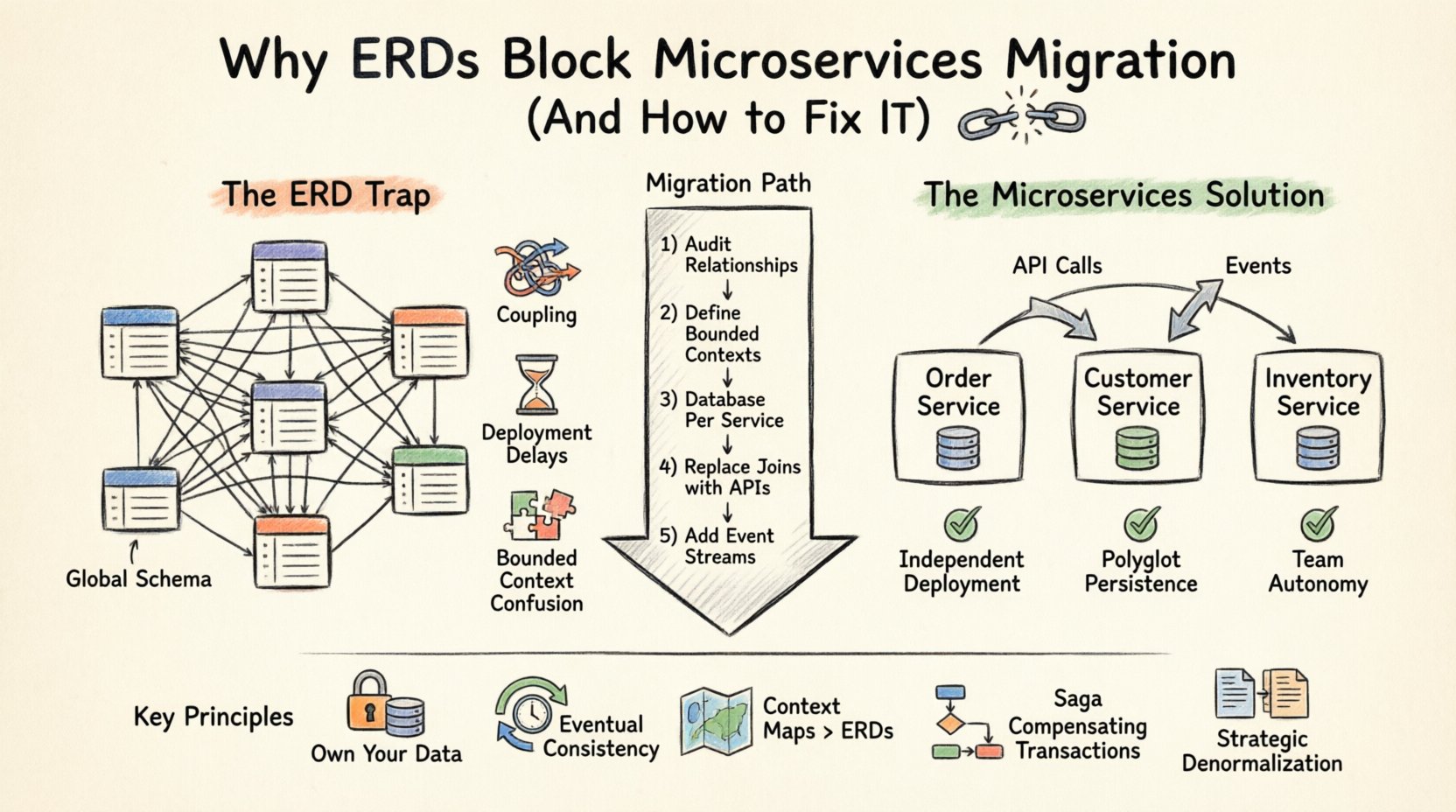
Quando você projeta um aplicativo monolítico, seu modelo de dados é centralizado. Um ERD representa a única fonte de verdade, com tabelas normalizadas ligadas por chaves estrangeiras. Esse método funciona bem para uma única instância de banco de dados. No entanto, os microserviços exigem autonomia. Quando você força uma estrutura de ERD monolítica em uma arquitetura distribuída, cria acoplamento rígido que anula os benefícios de dividir seu sistema. 🚧
Este guia explora por que a mentalidade clássica do ERD dificulta a adoção de microserviços e fornece um roteiro prático para transformar suas estratégias de modelagem de dados. Abordaremos a gestão distribuída de dados, modelos de consistência e técnicas de visualização alinhadas aos princípios do design orientado ao domínio. 🗺️
Compreendendo a armadilha do ERD em sistemas distribuídos 🧩
Um Diagrama de Relacionamento de Entidades é uma representação visual da estrutura lógica de um banco de dados. Ele define entidades (tabelas), atributos (colunas) e relacionamentos (chaves estrangeiras). Em um ambiente monolítico, essa centralização é uma vantagem. Garante a integridade dos dados por meio de transações ACID e simplifica a consulta em todo o aplicativo.
No entanto, a arquitetura de microserviços é baseada no princípio de independência de serviço. Cada serviço deve possuir seus próprios dados e expô-los apenas por meio de uma API. Quando você mantém um ERD compartilhado que abrange múltiplos serviços, viola a fronteira de propriedade. Isso leva aos seguintes problemas:
- Dependências de Esquema Globais: Se o Serviço A precisar unir dados do Serviço B diretamente no nível do banco de dados, eles já não são independentes. Uma mudança no esquema do Serviço B quebra o Serviço A.
- Fronteiras de Transação: Transações ACID entre múltiplos bancos de dados são complexas e pesadas em desempenho. Transações distribuídas frequentemente levam a contenção de bloqueios e picos de latência.
- Acoplamento de Implantação: Se o seu modelo de dados for compartilhado, você não pode implantar serviços de forma independente. Você precisa coordenar mudanças de esquema entre equipes, atrasando os ciclos de lançamento.
- Confusão de Contexto Delimitado: Serviços diferentes podem interpretar a mesma entidade de maneiras diferentes. Um ERD força uma única definição, ignorando nuances específicas do domínio.
O Problema de Acoplamento: Chaves Estrangeiras e Junções 🔗
Um dos erros mais comuns durante a migração é tentar manter o esquema de banco de dados existente intacto enquanto divide o código do aplicativo. Isso resulta em um anti-padrão de banco de dados compartilhado. Nesse cenário, múltiplos serviços se conectam à mesma instância de banco de dados, dependendo de chaves estrangeiras para manter relacionamentos.
Embora isso pareça uma estrutura de ERD válida, é um monólito oculto. Eis por que essa abordagem falha em um contexto de microserviços:
- Latência de Rede: Mesmo que o banco de dados esteja local na rede, consultas entre serviços introduzem saltos de rede que reduzem o desempenho em comparação com consultas locais.
- Ponto Único de Falha: Se o banco de dados falhar, todos os serviços falham. Os microserviços visam resiliência por meio da isolamento.
- Riscos de Segurança: Um serviço que não deveria ter acesso direto a outros dados ainda pode acessá-los por meio da string de conexão do banco de dados. As APIs fornecem uma interface controlada; o acesso direto ao banco de dados não oferece isso.
- Travamento de Tecnologia: Todos os serviços devem usar a mesma tecnologia de banco de dados. Os microserviços permitem persistência poliglota, em que diferentes serviços usam o armazenamento de dados mais adequado para suas necessidades específicas.
Para corrigir isso, você deve abandonar as junções SQL entre limites de serviços. Em vez disso, você deve usar composição de API ou sincronização de dados baseada em eventos. 🔄
Banco de Dados por Serviço: A Regra de Ouro 🏦
O padrão fundamental para a arquitetura de dados de microsserviços é Banco de Dados por Serviço. Cada serviço possui seu próprio esquema de banco de dados. Nenhum outro serviço é autorizado a acessar esse banco de dados diretamente. A comunicação ocorre estritamente por meio da API pública do serviço.
Essa mudança exige uma mudança fundamental na forma como você visualiza seus dados. Você já não pode desenhar um único ERD gigantesco para todo o sistema. Em vez disso, você cria múltiplos ERDs menores, um para cada serviço. 📄
| Aspecto | ERD Monolítico | Modelo de Microsserviços |
|---|---|---|
| Escopo do Esquema | Global / Unificado | Local / Específico do Serviço |
| Relacionamentos | Chaves Estrangeiras | Chamadas de API / Eventos |
| Consistência | Forte (ACID) | Eventual (BASE) |
| Implantação | Acoplado | Independente |
Gerenciando a Consistência Sem Transações Compartilhadas 🤝
Quando você separa os bancos de dados, perde a capacidade de executar uma única transação que atualize simultaneamente o Serviço A e o Serviço B. Em um monólito, você poderia usar uma transação de banco de dados para transferir dinheiro da Conta A para a Conta B. Em microsserviços, essas contas podem pertencer a serviços diferentes.
Como você não pode garantir consistência imediata em sistemas distribuídos, você deve adotar Consistência Eventual. Isso significa que o sistema alcançará um estado consistente ao longo do tempo, mas não necessariamente no exato momento em que o usuário clicar em um botão.
Implementando Sagas
Para lidar com fluxos de trabalho complexos que abrangem múltiplos serviços, use o padrão Saga. Uma saga é uma sequência de transações locais, onde cada transação atualiza o banco de dados dentro de um único serviço. Se uma etapa falhar, a saga executa transações compensatórias para desfazer as alterações feitas pelas etapas anteriores.
- Coreografia: Os serviços emitem eventos que acionam ações em outros serviços. Não há um coordenador central.
- Orquestração: Um serviço coordenador central gerencia o fluxo de trabalho e informa aos outros serviços o que fazer.
Esta abordagem garante a integridade dos dados sem exigir bloqueios compartilhados ou transações distribuídas. Acrescenta complexidade à implementação, mas é necessária para manter a saúde do sistema. 🛡️
Visualização de Dados Sem ERDs: Mapas de Contexto 🗺️
Se você abandonar o ERD tradicional, o que você usa para visualizar sua arquitetura de dados? A resposta está emMapas de Contexto do Design Orientado a Domínio (DDD). Enquanto um ERD se concentra em tabelas e colunas, um Mapa de Contexto se concentra em contextos delimitados e relacionamentos.
Em vez de desenhar linhas entre tabelas, você desenha linhas entre serviços. Você define como os dados fluem entre eles:
- Cliente-Fornecedor: Um serviço fornece dados a outro. O provedor define o contrato.
- Conformista: O serviço consumidor deve se adaptar ao modelo do provedor.
- Serviço de Hospedagem Aberta: Um serviço expõe seus dados por meio de um protocolo aberto.
- Caminhos Separados: Ambos os serviços evoluem seus próprios modelos independentemente.
Essa mudança na visualização ajuda as equipes a entenderempor que os dados são duplicados. Em um monólito, a duplicação é ruim. Em microserviços, a duplicação muitas vezes é uma característica para desacoplar serviços. Por exemplo, oServiço de Pedido pode armazenar uma cópia instantânea doNome do Cliente para evitar uma chamada de rede toda vez que um pedido é visualizado. Esse compromisso é aceitável para desempenho.
Passos de Migração: Migrando do ERD para Dados Distribuídos 🚀
Migrar de um ERD centralizado para um modelo de dados distribuído não é um evento único. É um processo em fases. Aqui está uma abordagem recomendada para gerenciar a migração.
Passo 1: Auditoria das Relações de Dados Existentes
Antes de dividir qualquer coisa, documente cada relação em seu ERD atual. Identifique quais tabelas são de leitura intensiva, quais são de escrita intensiva e quais são frequentemente unidas. Essa análise ajuda você a agrupar entidades em fronteiras lógicas de serviço. 📊
Passo 2: Definir Contextos Delimitados
Agrupe as entidades com base em domínios de negócios, e não em dependências técnicas. Por exemplo, um Catálogo de Produtos é diferente de um Gerenciamento de Estoque sistema, mesmo que ambos usem o campo ProductID campo. Certifique-se de que os limites estejam alinhados com as estruturas das equipes (Lei de Conway).
Etapa 3: Implementar Banco de Dados por Serviço
Crie uma nova instância de banco de dados para cada serviço. Mova os dados relevantes do banco de dados monolítico. Você não precisa mover tudo imediatamente. Comece com os dados principais necessários para o funcionamento do serviço. 🏗️
Etapa 4: Substituir Joins por Chamadas de API
Refatore suas consultas. Em vez de JOIN Orders, Customers, o seu código deve chamar a API do Cliente para buscar detalhes. Isso pode introduzir latência, então considere estratégias de cache ou desnormalização quando apropriado.
Etapa 5: Introduzir Fluxos de Eventos
Para atualizações em tempo real, implemente um barramento de eventos. Quando uma entidade muda em um serviço, publique um evento. Outros serviços podem se inscrever nesses eventos para atualizar suas cópias locais dos dados. Isso garante consistência eventual sem acoplamento direto.
Armadilhas Comuns Durante a Migração ⚠️
Mesmo com um plano, as equipes frequentemente tropeçam durante a transição. Esteja atento a esses problemas comuns.
- divisão prematura: Não divida serviços antes de entender o fluxo de dados. Dividir cedo demais pode levar a complexidade distribuída antes de estar preparado.
- Ignorar a Propriedade de Dados: Se múltiplas equipes reivindicarem a propriedade da mesma entidade de dados, conflitos surgirão. Atribua uma propriedade clara a cada serviço.
- Sobrenormalização: Em um sistema distribuído, a desnormalização é frequentemente preferida para reduzir o número de chamadas de API necessárias para renderizar uma página.
- Dependência da Rede: Nunca assuma que a rede é perfeita. Implemente tempos limite, repetições e interruptores de circuito para a comunicação entre serviços.
Alinhamento Organizacional 🤝
A arquitetura de dados não é apenas técnica; é organizacional. Um modelo de dados distribuído exige que as equipes se comuniquem de forma diferente. Em um monolito, os desenvolvedores conversam sobre um quadro branco compartilhado (o banco de dados). Em microserviços, eles conversam sobre o contrato da API.
Certifique-se de que suas equipes tenham poder para alterar seu esquema de banco de dados sem consultar um conselho de governança central. Essa autonomia é a única maneira de manter a velocidade do deploy independente. Se você introduzir uma equipe central que aprova todas as alterações de esquema, reintroduzirá o gargalo que tentou eliminar. 👥
Considerações Finais para a Estratégia de Dados 🧭
Mudar-se de um Diagrama Tradicional de Relacionamento de Entidades é um passo significativo. Exige uma mudança de mentalidade de integridade de dados por meio de restrições para integridade de dados por meio da lógica de aplicação e eventos. O ERD é uma ferramenta para bancos de dados relacionais, e não um projeto para sistemas distribuídos.
Ao adotar o padrão Banco de Dados por Serviço, utilizando arquitetura orientada a eventos e focando em contextos delimitados, você pode evitar o acoplamento que desacelera sua migração. O objetivo não é destruir seu modelo de dados existente, mas evoluí-lo para uma estrutura que suporte escalabilidade independente e resiliência.
Lembre-se de que a consistência é um espectro. Você não precisa de consistência forte em todos os lugares. Identifique quais partes do seu sistema exigem precisão rigorosa e quais podem tolerar consistência eventual. Esse pragmatismo o salvará de sobredimensionar sua solução.
Comece auditando seus diagramas atuais. Identifique as junções que cruzam os limites dos serviços. Planeje a migração dessas entidades específicas. Dê passos pequenos. Verifique os resultados. E mantenha sempre o domínio de negócios no centro do seu design de dados. 🎯
Principais Aprendizados 📝
- Evite bancos de dados compartilhados entre serviços para prevenir acoplamento.
- Use a composição de APIs em vez de junções SQL para dados entre serviços.
- Aceite a consistência eventual para ganhar disponibilidade e tolerância a partições.
- Visualize dados usando Mapas de Contexto em vez de ERDs globais.
- Atribua uma propriedade clara de dados às equipes individuais de serviço.
- Planeje a duplicação de dados como uma otimização de desempenho.
Ao seguir esses princípios, você pode navegar pelas complexidades da migração de dados sem deixar que seu ERD determine as limitações da sua nova arquitetura. O caminho adiante é distribuído, descentralizado e projetado para escala. 🚀