











Hiện đại hóa một hệ thống cũ thành kiến trúc microservices là một hành trình đầy thách thức về mặt kỹ thuật và tổ chức. Trong khi nhiều nhóm tập trung mạnh vào việc tái cấu trúc mã nguồn và đóng gói bằng container, một rào cản lớn thường nằm ở lớp dữ liệu. Cụ thể, mô hình sơ đồ quan hệ thực thể (ERD) truyền thống có thể trở thành một rào cản nghiêm trọng khi chuyển đổi sang các hệ thống phân tán. 📉
Khi bạn thiết kế một ứng dụng đơn thể, mô hình dữ liệu của bạn được tập trung hóa. Một sơ đồ ERD đại diện cho nguồn thông tin duy nhất, với các bảng chuẩn hóa được liên kết bởi các khóa ngoại. Cách tiếp cận này hoạt động tốt với một phiên bản cơ sở dữ liệu duy nhất. Tuy nhiên, microservices đòi hỏi tính độc lập. Khi bạn ép buộc cấu trúc ERD đơn thể lên kiến trúc phân tán, bạn tạo ra sự gắn kết chặt chẽ, làm mất đi lợi ích của việc tách rời hệ thống của mình. 🚧
Hướng dẫn này khám phá lý do tại sao tư duy ERD truyền thống cản trở việc áp dụng microservices và cung cấp một lộ trình thực tế để chuyển đổi chiến lược mô hình hóa dữ liệu của bạn. Chúng ta sẽ đề cập đến quản lý dữ liệu phân tán, các mô hình nhất quán, và các kỹ thuật trực quan hóa phù hợp với nguyên tắc thiết kế theo miền. 🗺️
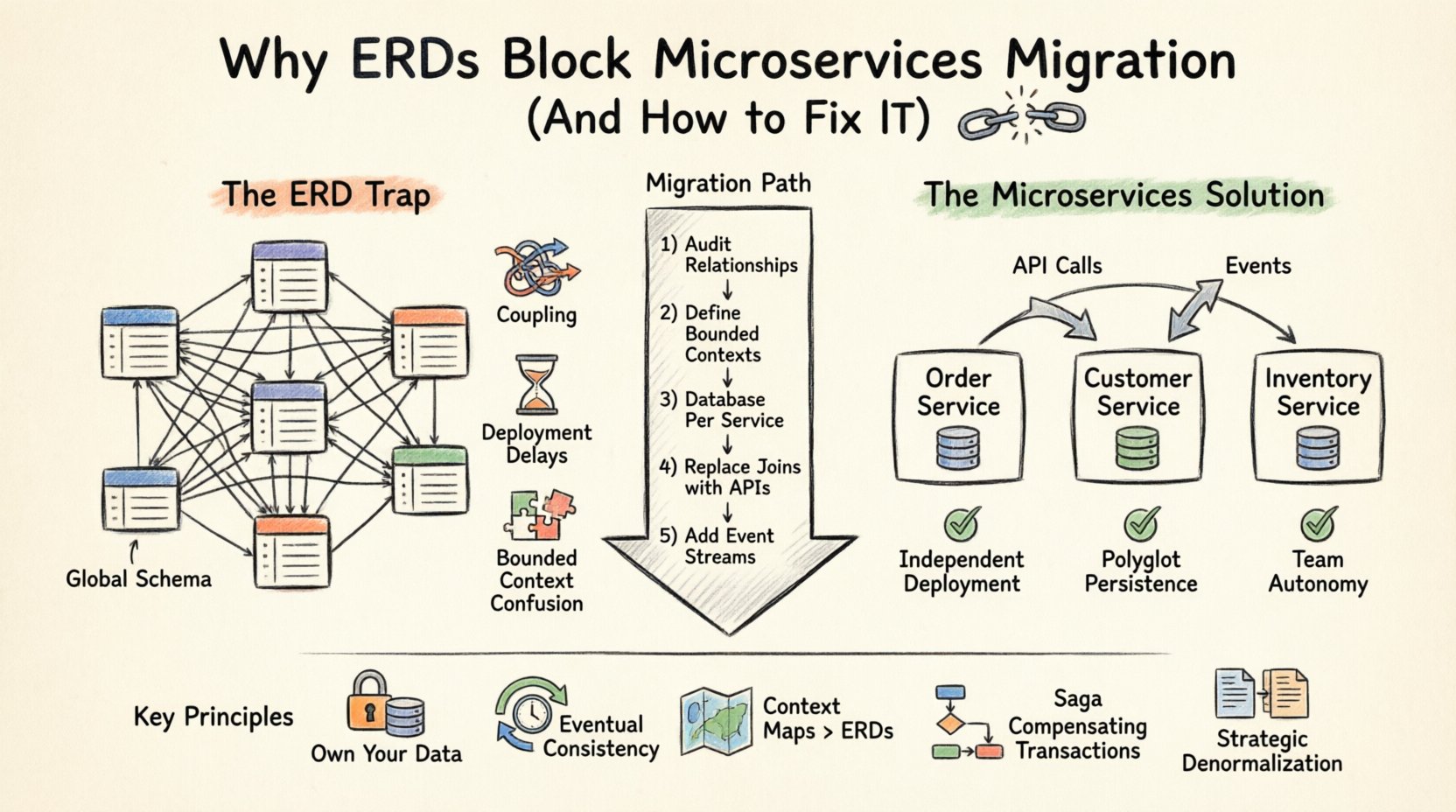
Hiểu rõ Bẫy ERD trong Các Hệ Thống Phân Tán 🧩
Sơ đồ quan hệ thực thể là một biểu diễn trực quan về cấu trúc logic của cơ sở dữ liệu. Nó xác định các thực thể (bảng), thuộc tính (cột) và mối quan hệ (khóa ngoại). Trong môi trường đơn thể, sự tập trung này là một điểm mạnh. Nó đảm bảo tính toàn vẹn dữ liệu thông qua các giao dịch ACID và đơn giản hóa việc truy vấn trên toàn bộ ứng dụng.
Tuy nhiên, kiến trúc microservices được xây dựng trên nguyên tắc độc lập dịch vụ. Mỗi dịch vụ nên sở hữu dữ liệu của mình và chỉ tiết lộ nó thông qua một API. Khi bạn duy trì một sơ đồ ERD chung bao trùm nhiều dịch vụ, bạn vi phạm ranh giới sở hữu. Điều này dẫn đến các vấn đề sau:
- Phụ thuộc vào lược đồ toàn cục: Nếu Dịch vụ A cần kết hợp dữ liệu từ Dịch vụ B trực tiếp ở cấp độ cơ sở dữ liệu, chúng không còn độc lập nữa. Một thay đổi trong lược đồ của Dịch vụ B sẽ làm hỏng Dịch vụ A.
- Ranh giới giao dịch: Các giao dịch ACID xuyên suốt nhiều cơ sở dữ liệu là phức tạp và tốn kém về hiệu năng. Các giao dịch phân tán thường dẫn đến xung đột khóa và tăng độ trễ.
- Gắn kết triển khai: Nếu mô hình dữ liệu của bạn được chia sẻ, bạn không thể triển khai các dịch vụ một cách độc lập. Bạn phải phối hợp thay đổi lược đồ giữa các nhóm, làm chậm chu kỳ phát hành.
- Sự nhầm lẫn về bối cảnh giới hạn: Các dịch vụ khác nhau có thể hiểu thực thể giống nhau theo cách khác nhau. Một sơ đồ ERD buộc phải có một định nghĩa duy nhất, bỏ qua những sắc thái đặc thù theo miền.
Vấn đề Gắn Kết: Khóa Ngoại và Kết Nối 🔗
Một trong những sai lầm phổ biến nhất trong quá trình chuyển đổi là cố gắng giữ nguyên lược đồ cơ sở dữ liệu hiện tại trong khi tách mã nguồn ứng dụng. Điều này dẫn đến một mẫu chống lại cơ sở dữ liệu chung. Trong tình huống này, nhiều dịch vụ kết nối đến cùng một phiên bản cơ sở dữ liệu, dựa vào các khóa ngoại để duy trì mối quan hệ.
Mặc dù điều này trông giống như một cấu trúc ERD hợp lệ, nhưng thực chất là một hệ thống đơn thể ẩn. Dưới đây là lý do tại sao cách tiếp cận này thất bại trong bối cảnh microservices:
- Độ trễ mạng: Ngay cả khi cơ sở dữ liệu nằm trong mạng cục bộ, các truy vấn xuyên dịch vụ vẫn tạo ra các bước nhảy mạng làm giảm hiệu suất so với các truy vấn cục bộ.
- Điểm lỗi duy nhất: Nếu cơ sở dữ liệu ngừng hoạt động, mọi dịch vụ đều ngừng hoạt động. Microservices hướng đến khả năng phục hồi thông qua sự cô lập.
- Rủi ro bảo mật: Một dịch vụ mà không nên truy cập trực tiếp vào dữ liệu khác vẫn có thể truy cập nó thông qua chuỗi kết nối cơ sở dữ liệu. APIs cung cấp giao diện được kiểm soát; truy cập cơ sở dữ liệu trực tiếp thì không.
- Bị mắc kẹt công nghệ: Tất cả các dịch vụ phải sử dụng cùng một công nghệ cơ sở dữ liệu. Microservices cho phép lưu trữ đa ngôn ngữ, nơi các dịch vụ khác nhau sử dụng kho dữ liệu phù hợp nhất với nhu cầu cụ thể của chúng.
Để khắc phục điều này, bạn phải từ bỏ việc sử dụng các phép nối SQL qua các ranh giới dịch vụ. Thay vào đó, bạn nên sử dụng việc kết hợp API hoặc đồng bộ hóa dữ liệu dựa trên sự kiện. 🔄
Cơ sở dữ liệu theo từng dịch vụ: Quy tắc Vàng 🏦
Mô hình nền tảng cho kiến trúc dữ liệu microservices làCơ sở dữ liệu theo từng dịch vụ. Mỗi dịch vụ sở hữu lược đồ cơ sở dữ liệu riêng của mình. Không dịch vụ nào khác được phép truy cập cơ sở dữ liệu này trực tiếp. Giao tiếp diễn ra nghiêm ngặt thông qua API công khai của dịch vụ.
Sự thay đổi này đòi hỏi một thay đổi căn bản trong cách bạn hình dung dữ liệu. Bạn không còn có thể vẽ một sơ đồ ERD khổng lồ cho toàn bộ hệ thống. Thay vào đó, bạn tạo ra nhiều sơ đồ ERD nhỏ hơn, mỗi sơ đồ dành cho một dịch vụ. 📄
| Khía cạnh | Sơ đồ ERD Đơn thể | Mô hình Microservices |
|---|---|---|
| Phạm vi lược đồ | Toàn cục / Được thống nhất | Địa phương / Đặc thù dịch vụ |
| Mối quan hệ | Khóa ngoại | Gọi API / Sự kiện |
| Tính nhất quán | Mạnh (ACID) | Cuối cùng (BASE) |
| Triển khai | Liên kết chặt chẽ | Độc lập |
Quản lý tính nhất quán mà không cần giao dịch chung 🤝
Khi bạn tách biệt các cơ sở dữ liệu, bạn mất khả năng thực hiện một giao dịch duy nhất cập nhật đồng thời cả Dịch vụ A và Dịch vụ B. Trong một hệ thống đơn thể, bạn có thể sử dụng giao dịch cơ sở dữ liệu để chuyển tiền từ Tài khoản A sang Tài khoản B. Trong microservices, các tài khoản này có thể thuộc về các dịch vụ khác nhau.
Vì bạn không thể đảm bảo tính nhất quán tức thì trong các hệ thống phân tán, bạn phải áp dụngTính nhất quán cuối cùng. Điều này có nghĩa là hệ thống sẽ đạt đến trạng thái nhất quán theo thời gian, nhưng không nhất thiết ngay lập tức khi người dùng nhấp vào nút.
Triển khai các Saga
Để xử lý các quy trình phức tạp trải dài qua nhiều dịch vụ, hãy sử dụngmô hình Saga. Một saga là một chuỗi các giao dịch cục bộ, trong đó mỗi giao dịch cập nhật cơ sở dữ liệu trong một dịch vụ duy nhất. Nếu một bước thất bại, saga sẽ thực hiện các giao dịch bù trừ để hoàn nguyên các thay đổi do các bước trước đó thực hiện.
- Kịch bản:Các dịch vụ phát ra sự kiện kích hoạt các hành động ở các dịch vụ khác. Không có bộ điều phối trung tâm nào.
- Điều phối:Một dịch vụ điều phối trung tâm quản lý luồng công việc và chỉ đạo các dịch vụ khác thực hiện điều gì.
Cách tiếp cận này đảm bảo tính toàn vẹn dữ liệu mà không cần đến các khóa chia sẻ hay giao dịch phân tán. Nó làm tăng độ phức tạp trong triển khai nhưng là điều cần thiết để duy trì sức khỏe hệ thống. 🛡️
Trực quan hóa Dữ liệu mà Không cần ERD: Bản đồ Bối cảnh 🗺️
Nếu bạn từ bỏ ERD truyền thống, bạn sẽ dùng gì để trực quan hóa kiến trúc dữ liệu của mình? Câu trả lời nằm ởBản đồ Bối cảnh Thiết kế Hướng miền (DDD). Trong khi ERD tập trung vào các bảng và cột, bản đồ bối cảnh lại tập trung vào các bối cảnh được giới hạn và các mối quan hệ.
Thay vì vẽ các đường nối giữa các bảng, bạn vẽ các đường nối giữa các dịch vụ. Bạn xác định cách dữ liệu chảy giữa chúng:
- Khách hàng-Nhà cung cấp:Một dịch vụ cung cấp dữ liệu cho dịch vụ khác. Bên cung cấp xác định hợp đồng.
- Tuân thủ:Dịch vụ tiêu thụ phải thích nghi với mô hình của bên cung cấp.
- Dịch vụ Chủ Mở:Một dịch vụ công khai dữ liệu của mình thông qua một giao thức mở.
- Đường riêng biệt:Cả hai dịch vụ đều phát triển mô hình riêng của chúng một cách độc lập.
Sự thay đổi này trong trực quan hóa giúp các đội hiểu rõ hơntại saodữ liệu bị sao chép. Trong một hệ thống monolith, việc sao chép là xấu. Trong microservices, việc sao chép thường là một tính năng để tách biệt các dịch vụ. Ví dụ, dịch vụDịch vụ Đơn hàngcó thể lưu trữ một bản sao dữ liệu củaTên Khách hàngđể tránh gọi mạng mỗi khi xem một đơn hàng. Sự đánh đổi này là chấp nhận được để cải thiện hiệu suất.
Các Bước Di chuyển: Chuyển từ ERD sang Dữ liệu Phân tán 🚀
Chuyển đổi từ ERD tập trung sang mô hình dữ liệu phân tán không phải là một sự kiện duy nhất. Đó là một quá trình theo từng giai đoạn. Dưới đây là cách tiếp cận được khuyến nghị để quản lý quá trình di chuyển.
Bước 1: Kiểm toán các mối quan hệ dữ liệu hiện có
Trước khi chia tách bất kỳ thứ gì, hãy ghi chép lại mọi mối quan hệ trong ERD hiện tại của bạn. Xác định các bảng nào là đọc nhiều, viết nhiều, và những bảng nào thường được kết hợp với nhau. Phân tích này giúp bạn nhóm các thực thể vào các ranh giới dịch vụ hợp lý. 📊
Bước 2: Xác định các Bối cảnh được giới hạn
Nhóm các thực thể dựa trên các miền kinh doanh thay vì các phụ thuộc kỹ thuật. Ví dụ, một Sổ tay sản phẩm là khác biệt với một Quản lý kho hệ thống, ngay cả khi cả hai đều sử dụng trường ProductID trường. Đảm bảo các ranh giới phù hợp với cấu trúc nhóm (Luật Conway).
Bước 3: Triển khai Cơ sở dữ liệu theo từng Dịch vụ
Tạo một phiên bản cơ sở dữ liệu mới cho từng dịch vụ. Chuyển dữ liệu liên quan từ cơ sở dữ liệu đơn thể. Bạn không cần di chuyển mọi thứ ngay lập tức. Bắt đầu bằng dữ liệu cốt lõi cần thiết để dịch vụ hoạt động. 🏗️
Bước 4: Thay thế các phép JOIN bằng lời gọi API
Tái cấu trúc các truy vấn của bạn. Thay vì JOIN Orders, Customers, mã của bạn nên gọi đến API Khách hàng để lấy chi tiết. Điều này có thể gây ra độ trễ, vì vậy hãy cân nhắc các chiến lược bộ nhớ đệm hoặc loại bỏ chuẩn hóa ở những nơi phù hợp.
Bước 5: Giới thiệu luồng sự kiện
Để cập nhật theo thời gian thực, triển khai một bus sự kiện. Khi một thực thể thay đổi trong một dịch vụ, hãy phát hành một sự kiện. Các dịch vụ khác có thể đăng ký các sự kiện này để cập nhật bản sao cục bộ của dữ liệu. Điều này đảm bảo tính nhất quán cuối cùng mà không cần liên kết trực tiếp.
Những sai lầm phổ biến trong quá trình di chuyển ⚠️
Ngay cả khi có kế hoạch, các nhóm thường vấp ngã trong quá trình chuyển đổi. Hãy cảnh giác với những vấn đề phổ biến này.
- chia tách quá sớm: Đừng chia tách dịch vụ trước khi bạn hiểu luồng dữ liệu. Việc chia tách quá sớm có thể dẫn đến sự phức tạp phân tán trước khi bạn sẵn sàng.
- Bỏ qua quyền sở hữu dữ liệu: Nếu nhiều nhóm tuyên bố sở hữu cùng một thực thể dữ liệu, xung đột sẽ xảy ra. Gán quyền sở hữu rõ ràng cho từng dịch vụ.
- Chuẩn hóa quá mức: Trong hệ thống phân tán, việc loại bỏ chuẩn hóa thường được ưu tiên để giảm số lượng lời gọi API cần thiết để hiển thị một trang.
- Phụ thuộc vào mạng: Không bao giờ giả định mạng là hoàn hảo. Triển khai thời gian chờ, thử lại và bộ ngắt mạch cho giao tiếp giữa các dịch vụ.
Sự đồng bộ tổ chức 🤝
Kiến trúc dữ liệu không chỉ là kỹ thuật; nó là tổ chức. Mô hình dữ liệu phân tán đòi hỏi các nhóm phải giao tiếp theo cách khác biệt. Trong một hệ thống đơn thể, các nhà phát triển nói chuyện qua một bảng trắng chung (cơ sở dữ liệu). Trong microservices, họ nói chuyện qua hợp đồng API.
Đảm bảo rằng các nhóm của bạn được trao quyền thay đổi lược đồ cơ sở dữ liệu của họ mà không cần tham khảo ban quản lý trung tâm. Tự chủ này là cách duy nhất để duy trì tốc độ triển khai độc lập. Nếu bạn giới thiệu một nhóm trung tâm phê duyệt mọi thay đổi lược đồ, bạn sẽ tái tạo lại điểm nghẽn mà bạn đã cố gắng loại bỏ. 👥
Những Xem xét Cuối Cùng về Chiến Lược Dữ Liệu 🧭
Từ bỏ sơ đồ quan hệ thực thể truyền thống là một bước quan trọng. Điều này đòi hỏi sự thay đổi tư duy từbảo toàn tính toàn vẹn dữ liệu thông qua các ràng buộc sangbảo toàn tính toàn vẹn dữ liệu thông qua logic ứng dụng và sự kiện. Sơ đồ ERD là công cụ dành cho cơ sở dữ liệu quan hệ, chứ không phải bản vẽ thiết kế cho các hệ thống phân tán.
Bằng cách áp dụng mẫu Cơ sở dữ liệu theo Dịch vụ, tận dụng kiến trúc dựa trên sự kiện và tập trung vào các bối cảnh được giới hạn, bạn có thể tránh được sự gắn kết làm chậm quá trình di dời của mình. Mục tiêu không phải là phá hủy mô hình dữ liệu hiện tại, mà là phát triển nó thành một cấu trúc hỗ trợ khả năng mở rộng độc lập và độ bền vững.
Hãy nhớ rằng tính nhất quán là một dải phổ. Bạn không cần tính nhất quán mạnh ở mọi nơi. Xác định những phần nào trong hệ thống của bạn yêu cầu độ chính xác nghiêm ngặt và phần nào có thể chấp nhận tính nhất quán cuối cùng. Sự thực tế này sẽ giúp bạn tránh được việc thiết kế giải pháp quá phức tạp.
Bắt đầu bằng việc kiểm toán các sơ đồ hiện tại của bạn. Xác định các phép nối vượt qua ranh giới dịch vụ. Lên kế hoạch di dời những thực thể cụ thể đó. Thực hiện từng bước nhỏ. Xác minh kết quả. Và luôn đặt lĩnh vực kinh doanh làm trung tâm trong thiết kế dữ liệu của bạn. 🎯
Những Bài Học Quan Trọng 📝
- Tránh sử dụng cơ sở dữ liệu chung giữa các dịch vụ để ngăn chặn sự gắn kết.
- Sử dụng kết hợp API thay vì các phép nối SQL để xử lý dữ liệu xuyên dịch vụ.
- Chấp nhận tính nhất quán cuối cùng để đạt được khả năng sẵn sàng và khả năng chịu đựng sự phân mảnh.
- Trực quan hóa dữ liệu bằng Bản đồ Bối cảnh thay vì sơ đồ ERD toàn cục.
- Giao quyền sở hữu dữ liệu rõ ràng cho từng đội ngũ dịch vụ.
- Lên kế hoạch cho việc sao chép dữ liệu như một biện pháp tối ưu hóa hiệu suất.
Bằng cách tuân theo những nguyên tắc này, bạn có thể vượt qua những phức tạp trong việc di dời dữ liệu mà không để sơ đồ ERD của bạn định đoạt giới hạn cho kiến trúc mới của mình. Con đường phía trước là phân tán, phi tập trung và được thiết kế để mở rộng quy mô. 🚀