











💡 主要重點
-
視覺清晰度:逆向工程將繁雜的原始程式碼轉換為可讀的UML圖表,揭示隱藏的架構。
-
依賴關係映射:自動化分析可識別模組之間的關係,有助於重構與理解耦合性。
-
遺留系統現代化:從現有的程式碼庫建立圖表,可彌補技術負債與未來文件之間的差距。
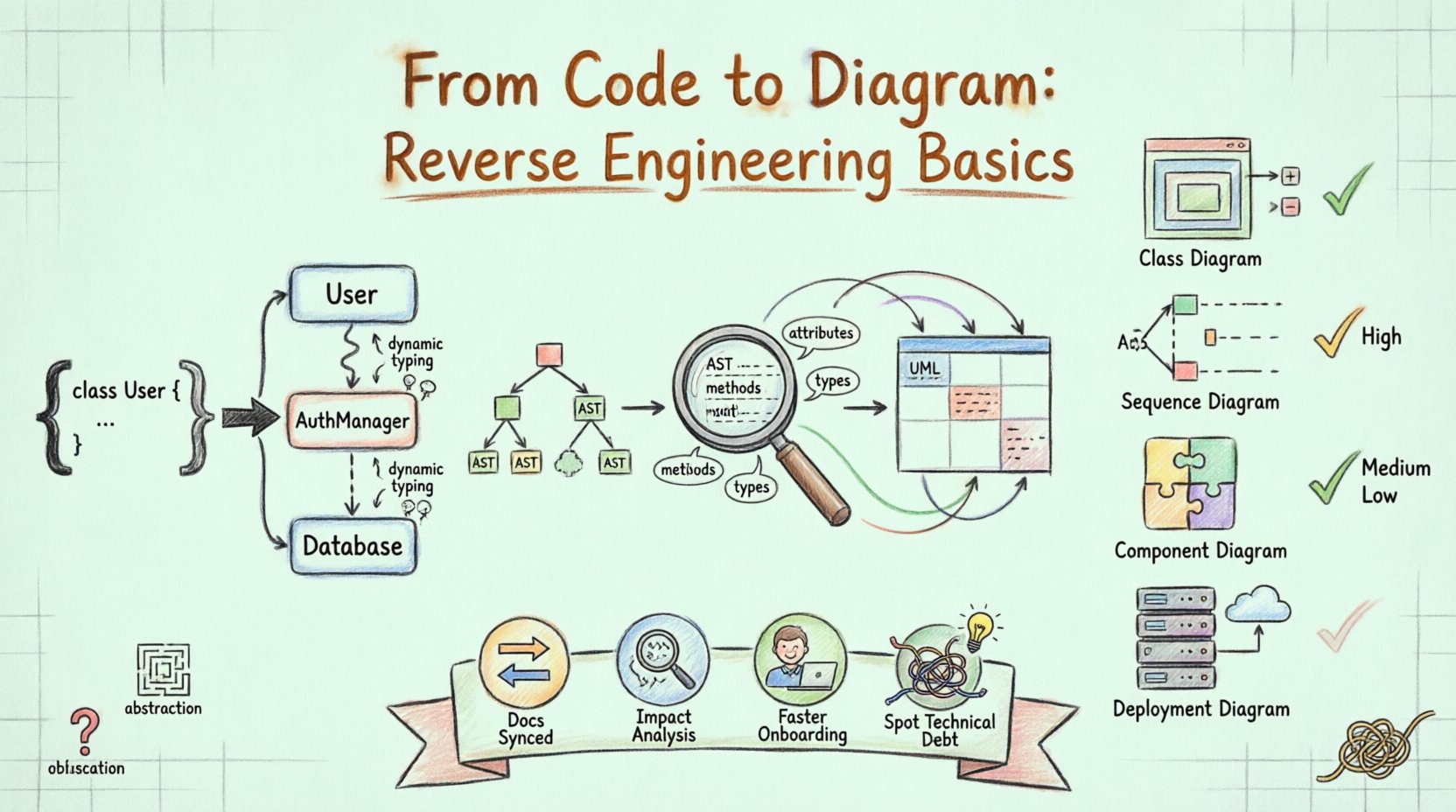
在軟體開發的領域中,維護文件經常落後於實作的速度。程式碼庫不斷擴大,功能陸續增加,原始的架構決策也逐漸模糊。這正是逆向工程成為必要學科的原因。它涉及分析現有的原始程式碼,以重建視覺化表示,通常使用統一模型語言(UML)圖表。此過程不僅僅是記錄現有的內容,更清楚地揭示組件之間如何互動、依賴關係位於何處,以及系統的結構為何。
理解UML環境下的逆向工程 🧩
在軟體開發中,逆向工程是分析系統以識別其組件及其相互關係的過程。當應用於UML時,目標是從實際實作中推導出圖示化表示。與正向工程(圖表引導程式碼撰寫)不同,逆向工程從程式碼出發,再推導出圖表。
此方法對於文件可能已過時或完全不存在的遺留系統尤為重要。透過解析原始程式碼,工具可提取類別名稱、方法簽章、繼承層次與關聯連結。這些元素構成了類別圖、序列圖與元件圖的基本構成單元。
核心目標
主要目標是達成理解的狀態。開發人員經常遇到感覺像黑箱般的遺留程式碼。逆向工程打開了這個黑箱,讓團隊能在不需閱讀每一行程式碼的情況下,視覺化資料流程與結構邏輯。它在程式碼的具體現實與設計的抽象概念之間架起了一座橋樑。
為什麼要從程式碼產生圖表? 📊
進行此過程有幾個戰略性原因。這不僅僅是為了創造漂亮的圖像,更在於降低風險與提升清晰度。
-
文件同步:程式碼經常變動。由程式碼生成的圖表永遠保持最新,反映系統的當前狀態。
-
影響分析:在重構模組之前,開發人員需要知道哪些部分依賴於它。圖表能清楚地標示這些依賴關係。
-
新成員融入:新成員透過檢視圖表,能比在檔案倉庫中摸索更快地掌握系統架構。
-
識別技術負債:複雜的結構通常在圖表中呈現為錯綜複雜的網絡,突顯出需要簡化的區域。
逆向工程的流程 🔄
將程式碼轉換為圖表涉及系統化的工作流程。雖然具體實作方式各有不同,但邏輯步驟在各環境中保持一致。
1. 解析與分析
第一步是讀取原始程式碼檔案。系統會解析語法以理解結構,識別類別、介面、函數與變數。此階段將原始文字轉換為結構化資料格式,通常是抽象語法樹(AST)。解析器必須具備語言感知能力,才能正確解讀所使用程式語言的語法。
2. 元資料提取
程式碼解析後,系統會提取特定的元資料。這包括:
-
屬性:類別中的資料欄位。
-
方法:函數及其存取修飾詞(public、private、protected)。
-
類型:與屬性和傳回值相關的資料類型。
-
關係:繼承(extends/implements)、關聯(使用)與聚合(組合)。
3. 映射至UML語義
提取的元資料必須對應至UML符號。例如,類別定義會對應至類別圖中的方框。函數內的方法呼叫會對應至序列圖中的互動。此對應過程需要邏輯推斷。若類別A建立類別B的實例,系統會推斷出關聯或依賴關係。
4. 可視化與渲染
最後一步是將資料渲染成視覺格式。這包括將元件放置在畫布上,並繪製線條來表示關係。佈局演算法試圖組織圖形,使其易於閱讀,減少線條交叉並將相關元件分組。
常見生成的圖表 📝
並非所有圖表都同等適用於逆向工程。有些圖表捕捉靜態結構,而其他圖表則捕捉動態行為。
|
圖表類型 |
重點 |
在逆向工程中的實用性 |
|---|---|---|
|
類別圖 |
靜態結構 |
高。可直接從程式碼中顯示繼承、屬性和方法。 |
|
序列圖 |
動態行為 |
中等。需要追蹤方法呼叫以理解互動流程。 |
|
元件圖 |
系統模組 |
高。將類別分組為邏輯單元或程式庫。 |
|
部署圖 |
基礎設施 |
低。需要了解伺服器設定,而不僅僅是程式碼。 |
流程中的挑戰 ⚠️
雖然強大,但逆向工程並非沒有困難。多種因素可能使生成精確圖表變得複雜。
抽象與隱藏
現代程式碼庫高度依賴抽象。介面與多態性可能掩蓋實際的實作。一個方法可能在介面中定義,卻在多個類別中實作。要呈現這種情況,必須同時顯示合約與實作,這可能使圖表變得混亂。
動態類型
支援動態類型的語言(變數類型在執行時期才決定)對靜態分析構成挑戰。逆向工程工具可能難以在不執行程式碼或分析複雜控制流程的情況下,準確判斷物件的類型。
程式碼混淆
在某些情境下,程式碼會被混淆以保護智慧財產權。壓縮與變數重命名使原始程式碼對人類與機器都難以閱讀。逆向工程混淆過的程式碼需要更為複雜的分析技術。
複雜依賴
大型系統通常具有循環依賴或緊密耦合的模組。當產生圖表時,這些依賴可能造成「義大利麵式」效應,使線條混亂交錯。通常需要手動介入來整理佈局,並邏輯性地分組相關元素。
確保準確性的最佳實務 ✅
為確保生成的圖表具有實用性,在逆向工程過程中應遵循某些實務。
-
過濾雜訊:排除標準函式庫或重複性程式碼,這些內容僅增加視覺雜訊而無架構價值。專注於自訂的商業邏輯。
-
群組模組:使用套件或命名空間來群組類別。這可避免圖表變成單一龐大的節點。
-
驗證關係:自動化工具有時可能誤解關係。應審查生成的連結,確保其準確反映程式碼邏輯。
-
迭代:逆向工程很少是一次性的任務。隨著程式碼庫的演進,圖表應定期重新產生並審查。
自動化的角色 🤖
手動逆向工程對大型專案不切實際。自動化至關重要。自動化解析器掃描程式碼庫,建立依賴圖,並匯出至 XMI 或 PlantUML 等標準格式。這使團隊能將圖表生成整合至 CI/CD 管道中。
自動化確保文件永遠不會過時。若開發者提交的變更破壞了依賴關係,圖表生成流程可標示出不一致之處。這種持續驗證有助於長期維持系統完整性。
將圖表整合至維護作業中 🛠️
圖表生成後,應積極使用。它們不僅僅用於展示。團隊可利用它們規劃重構工作。例如,若類別圖顯示某個類別具有過多依賴,則該類別應考慮拆分。
此外,圖表有助於程式碼審查。審查者可在閱讀差異內容前,先觀察提案變更的結構性影響。這使焦點從語法轉向架構,提升程式碼庫的品質。
關於結構洞察的結論 🏁
將程式碼逆向工程為 UML 圖表,是維護複雜軟體系統的基本做法。它能將封閉的程式碼轉化為透明的架構,促進更好的決策與更清晰的溝通。儘管動態類型與複雜依賴帶來挑戰,但同步文件的優勢仍遠超過成本。透過優先確保結構清晰,團隊能自信地導航遺留系統,並精準地現代化其應用程式。