











💡 Wichtige Erkenntnisse
-
Visuelle Klarheit:Die Rückwärtssynthese wandelt dichte Quellcode in lesbare UML-Diagramme um und bringt versteckte Architekturen ans Licht.
-
Abhängigkeitszuordnung:Automatisierte Analyse erkennt Beziehungen zwischen Modulen und unterstützt das Refactoring sowie das Verständnis der Kopplung.
-
Modernisierung veralteter Systeme:Das Erstellen von Diagrammen aus bestehenden Codebasen schließt die Lücke zwischen technischem Schulden und zukünftiger Dokumentation.
In der Landschaft der Softwareentwicklung bleibt die Dokumentation oft hinter dem Tempo der Implementierung zurück. Codebasen wachsen, Funktionen werden hinzugefügt und ursprüngliche architektonische Entscheidungen werden unscharf. Genau hier wird die Rückwärtssynthese zu einer essenziellen Disziplin. Sie beinhaltet die Analyse bestehender Quellcode, um eine visuelle Darstellung, typischerweise mithilfe von Unified Modeling Language (UML)-Diagrammen, wiederherzustellen. Dieser Prozess dokumentiert nicht nur, was existiert, sondern klärt, wie Komponenten interagieren, wo Abhängigkeiten liegen und wie das System strukturiert ist.
Verständnis der Rückwärtssynthese im Kontext von UML 🧩
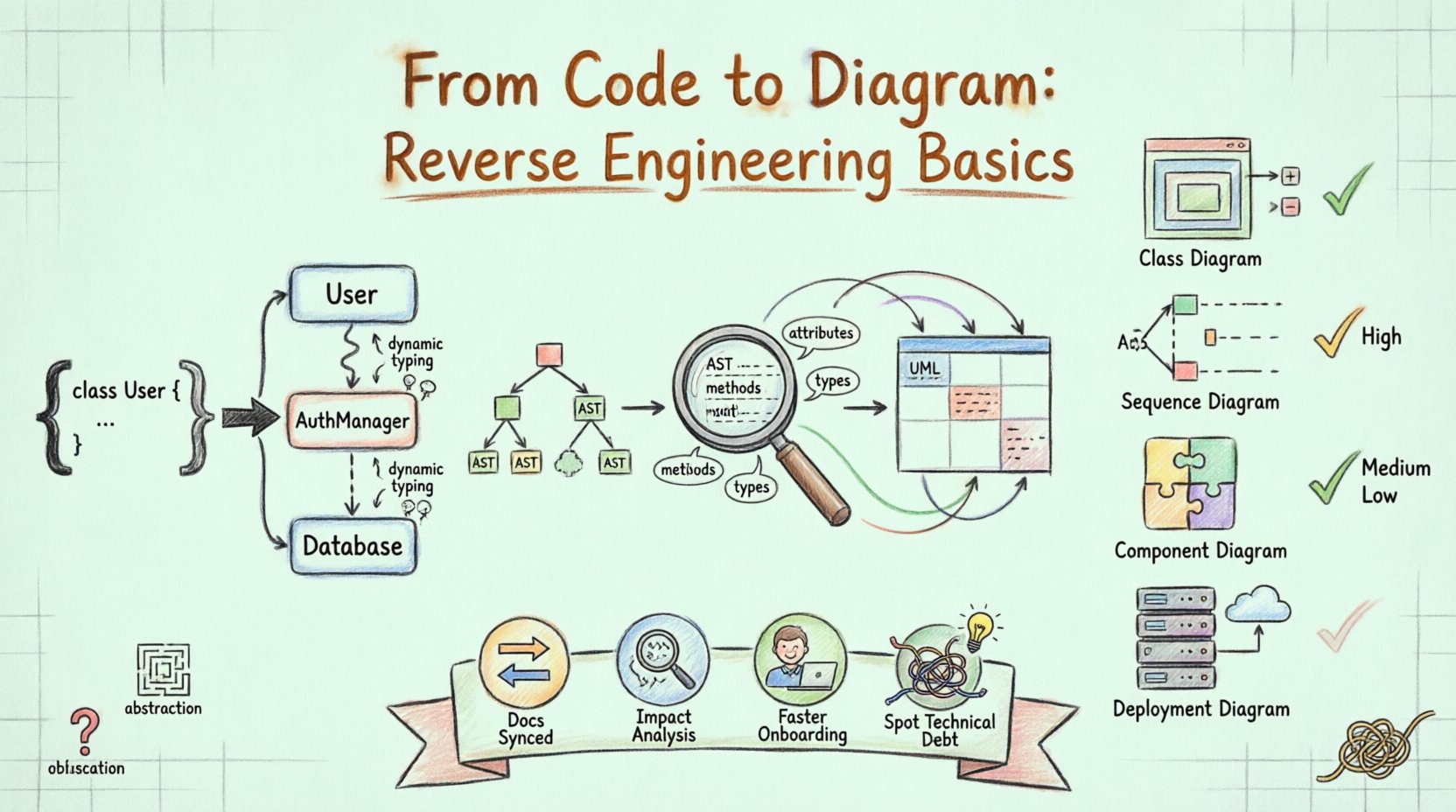
Die Rückwärtssynthese in der Softwareentwicklung ist der Prozess der Analyse eines Systems, um dessen Komponenten und deren Wechselwirkungen zu identifizieren. Bei Anwendung auf UML besteht das Ziel darin, eine diagrammatische Darstellung aus der tatsächlichen Implementierung abzuleiten. Im Gegensatz zur Vorwärtsentwicklung, bei der Diagramme die Codeerstellung leiten, beginnt die Rückwärtssynthese mit dem Code und leitet daraus die Diagramme ab.
Dieser Ansatz ist besonders wertvoll für veraltete Systeme, bei denen die Dokumentation möglicherweise veraltet oder gar nicht vorhanden ist. Durch die Analyse des Quellcodes können Werkzeuge Klassennamen, Methodensignaturen, Vererbungshierarchien und Assoziationsverbindungen extrahieren. Diese Elemente bilden die Grundbausteine für Klassendiagramme, Sequenzdiagramme und Komponentendiagramme.
Das zentrale Ziel
Das primäre Ziel ist es, einen Zustand des Verständnisses zu erreichen. Entwickler stoßen oft auf veralteten Code, der sich wie eine schwarze Kiste anfühlt. Die Rückwärtssynthese öffnet diese Kiste und ermöglicht es Teams, den Datenfluss und die strukturelle Logik zu visualisieren, ohne jede Zeile der Implementierung lesen zu müssen. Sie dient als Brücke zwischen der konkreten Realität des Codes und der abstrakten Konzeption des Designs.
Warum Diagramme aus Code generieren? 📊
Es gibt mehrere strategische Gründe, diesen Prozess durchzuführen. Es geht nicht nur darum, ansprechende Bilder zu erstellen, sondern um Risikominderung und Klarheit.
-
Dokumentationssynchronisation:Der Code ändert sich häufig. Aus dem Code generierte Diagramme sind immer aktuell und spiegeln den aktuellen Zustand des Systems wider.
-
Auswirkungsanalyse:Bevor ein Modul refaktorisiert wird, müssen Entwickler wissen, was darauf abhängt. Diagramme zeigen diese Abhängigkeiten deutlich hervor.
-
Onboarding:Neue Teammitglieder können die Systemarchitektur viel schneller verstehen, indem sie Diagramme betrachten, anstatt durch eine Datei-Repository zu navigieren.
-
Erkennen technischer Schulden:Komplexe Strukturen zeigen sich oft als verschlungene Netze in Diagrammen und markieren Bereiche, die vereinfacht werden müssen.
Der Prozess der Rückwärtssynthese 🔄
Die Umwandlung von Code in Diagramme erfordert einen systematischen Arbeitsablauf. Obwohl die konkreten Implementierungen variieren, bleiben die logischen Schritte über verschiedene Umgebungen hinweg konsistent.
1. Parsen und Analyse
Der erste Schritt besteht darin, die Quellcode-Dateien zu lesen. Das System parsen die Syntax, um die Struktur zu verstehen. Es identifiziert Klassen, Schnittstellen, Funktionen und Variablen. In dieser Phase wird roher Text in ein strukturiertes Datenformat umgewandelt, oft ein abstraktes Syntaxbaum (AST). Der Parser muss sprachbewusst sein, um die Syntax korrekt zu interpretieren, die spezifisch für die verwendete Programmiersprache ist.
2. Extraktion von Metadaten
Sobald der Code geparst ist, extrahiert das System spezifische Metadaten. Dazu gehören:
-
Attribute: Datenfelder innerhalb von Klassen.
-
Methoden: Funktionen und ihre Zugriffsmodifizierer (public, private, protected).
-
Typen: Die Datentypen, die mit Attributen und Rückgabewerten verbunden sind.
-
Beziehungen: Vererbung (extends/implements), Assoziation (Verwendung) und Aggregation (Zusammensetzung).
3. Abbildung auf UML-Semantik
Die extrahierten Metadaten müssen in die UML-Notation abgebildet werden. Zum Beispiel entspricht eine Klassendefinition einem Kasten in einem Klassendiagramm. Ein Methodenaufruf innerhalb einer Funktion entspricht einer Interaktion in einem Sequenzdiagramm. Diese Abbildung erfordert logische Inferenz. Wenn Klasse A eine Instanz von Klasse B erstellt, schließt das System eine Assoziation oder Abhängigkeit ab.
4. Visualisierung und Darstellung
Der letzte Schritt ist die Darstellung der Daten in einem visuellen Format. Dazu gehören das Anordnen von Elementen auf einer Leinwand und das Zeichnen von Linien zur Darstellung von Beziehungen. Die Layout-Algorithmen versuchen, das Diagramm so zu organisieren, dass es lesbar ist, wobei sich kreuzende Linien minimieren und verwandte Komponenten gruppiert werden.
Häufig generierte Diagramme 📝
Nicht alle Diagramme sind gleich gut für die Rückwärtssynthese geeignet. Einige erfassen die statische Struktur, während andere dynamisches Verhalten erfassen.
|
Diagrammtyp |
Schwerpunkt |
Nutzung bei der Rückwärtssynthese |
|---|---|---|
|
Klassendiagramm |
Statische Struktur |
Hoch. Zeigt Vererbung, Attribute und Methoden direkt aus dem Code an. |
|
Sequenzdiagramm |
Dynamisches Verhalten |
Mittel. Erfordert das Verfolgen von Methodenaufrufen, um den Interaktionsablauf zu verstehen. |
|
Komponentendiagramm |
Systemmodule |
Hoch. Gruppiert Klassen zu logischen Einheiten oder Bibliotheken. |
|
Bereitstellungsdigramm |
Infrastruktur |
Niedrig. Erfordert Kenntnisse über Serverkonfiguration, nicht nur über Code. |
Herausforderungen im Prozess ⚠️
Während umfangreich, birgt Reverse Engineering keine Schwierigkeiten. Mehrere Faktoren können die Erstellung genauer Diagramme erschweren.
Abstraktion und Verbergen
Moderne Codebasen stützen sich stark auf Abstraktion. Schnittstellen und Polymorphismus können die eigentliche Implementierung verschleiern. Eine Methode könnte in einer Schnittstelle definiert sein, aber in mehreren Klassen implementiert werden. Die Visualisierung erfordert, sowohl den Vertrag als auch die Realisierung darzustellen, was ein Diagramm verunreinigen kann.
Dynamische Typisierung
Sprachen, die dynamische Typisierung unterstützen (bei der Variable-Typen zur Laufzeit bestimmt werden), stellen eine Herausforderung für die statische Analyse dar. Das Reverse-Engineering-Tool kann Schwierigkeiten haben, den genauen Typ eines Objekts zu bestimmen, ohne den Code auszuführen oder komplexe Steuerflüsse zu analysieren.
Code-Obfuskation
In einigen Kontexten wird Code obfuskiert, um geistiges Eigentum zu schützen. Minifizierung und Umbenennung von Variablen machen den Quellcode für Menschen und Maschinen schwer lesbar. Das Reverse-Engineering von obfuskiertem Code erfordert deutlich fortgeschrittener Analysetechniken.
Komplexe Abhängigkeiten
Große Systeme haben oft zirkuläre Abhängigkeiten oder eng gekoppelte Module. Wenn ein Diagramm generiert wird, können diese Abhängigkeiten einen „Spaghetti-Effekt“ erzeugen, bei dem Linien chaotisch kreuzen. Häufig ist manuelle Intervention erforderlich, um die Anordnung aufzuräumen und verwandte Elemente logisch zu gruppieren.
Best Practices für Genauigkeit ✅
Um sicherzustellen, dass die generierten Diagramme nützlich sind, sollten während des Reverse-Engineering-Prozesses bestimmte Praktiken befolgt werden.
-
Rauschen filtern: Ausschluss von Standardbibliotheken oder Boilerplate-Code, die visuelle Unordnung ohne architektonischen Wert hinzufügen. Fokus auf benutzerdefinierte Geschäftslogik.
-
Module gruppieren: Verwenden Sie Pakete oder Namespaces, um Klassen zu gruppieren. Dadurch vermeidet man, dass das Diagramm zu einem einzigen riesigen Knoten wird.
-
Beziehungen validieren:Automatisierte Werkzeuge können Beziehungen manchmal falsch interpretieren. Überprüfen Sie die generierten Verbindungen, um sicherzustellen, dass sie die Code-Logik korrekt widerspiegeln.
-
Iterieren:Reverse Engineering ist selten eine einmalige Aufgabe. Sobald sich die Codebasis weiterentwickelt, sollten die Diagramme neu generiert und regelmäßig überprüft werden.
Die Rolle der Automatisierung 🤖
Manuelles Reverse Engineering ist für große Projekte unpraktisch. Automatisierung ist entscheidend. Automatisierte Parser scannen Repositories, erstellen Abhängigkeitsgraphen und exportieren in Standardformate wie XMI oder PlantUML. Dadurch können Teams die Diagrammerstellung in ihre CI/CD-Pipelines integrieren.
Die Automatisierung stellt sicher, dass Dokumentation niemals veraltet ist. Wenn ein Entwickler eine Änderung committet, die eine Abhängigkeit bricht, kann der Prozess der Diagrammerstellung die Inkonsistenz erkennen. Diese kontinuierliche Validierung hilft, die Systemintegrität über die Zeit hinweg zu erhalten.
Diagramme in die Wartung integrieren 🛠️
Sobald Diagramme generiert wurden, sollten sie aktiv genutzt werden. Sie dienen nicht nur der Präsentation. Teams können sie nutzen, um Refaktorisierungsmaßnahmen zu planen. Wenn beispielsweise ein Klassendiagramm eine Klasse mit übermäßigen Abhängigkeiten zeigt, ist sie ein Kandidat für eine Aufteilung.
Darüber hinaus helfen Diagramme bei Code-Reviews. Reviewer können sich vor dem Lesen des Diff die strukturelle Auswirkung einer vorgeschlagenen Änderung ansehen. Dadurch verlagert sich der Fokus von der Syntax auf die Architektur und verbessert die Qualität des Codebasen.
Fazit zu strukturellen Erkenntnissen 🏁
Das Reverse-Engineering von Code in UML-Diagramme ist eine grundlegende Praxis zur Pflege komplexer Software-Systeme. Es wandelt undurchsichtigen Code in durchsichtige Architektur um, was bessere Entscheidungsfindung und klarere Kommunikation ermöglicht. Obwohl Herausforderungen bezüglich dynamischer Typisierung und komplexer Abhängigkeiten bestehen, überwiegen die Vorteile synchroner Dokumentation die Kosten. Durch die Priorisierung struktureller Klarheit können Teams Legacy-Systeme mit Vertrauen navigieren und ihre Anwendungen präzise modernisieren.