











💡 Principais Pontos
-
Clareza Visual:A engenharia reversa transforma código-fonte denso em diagramas UML legíveis, revelando arquiteturas ocultas.
-
Mapeamento de Dependências:Análise automatizada identifica relações entre módulos, auxiliando na refatoração e na compreensão do acoplamento.
-
Modernização de Legado:Criar diagramas a partir de bases de código existentes fecha a lacuna entre dívida técnica e documentação futura.
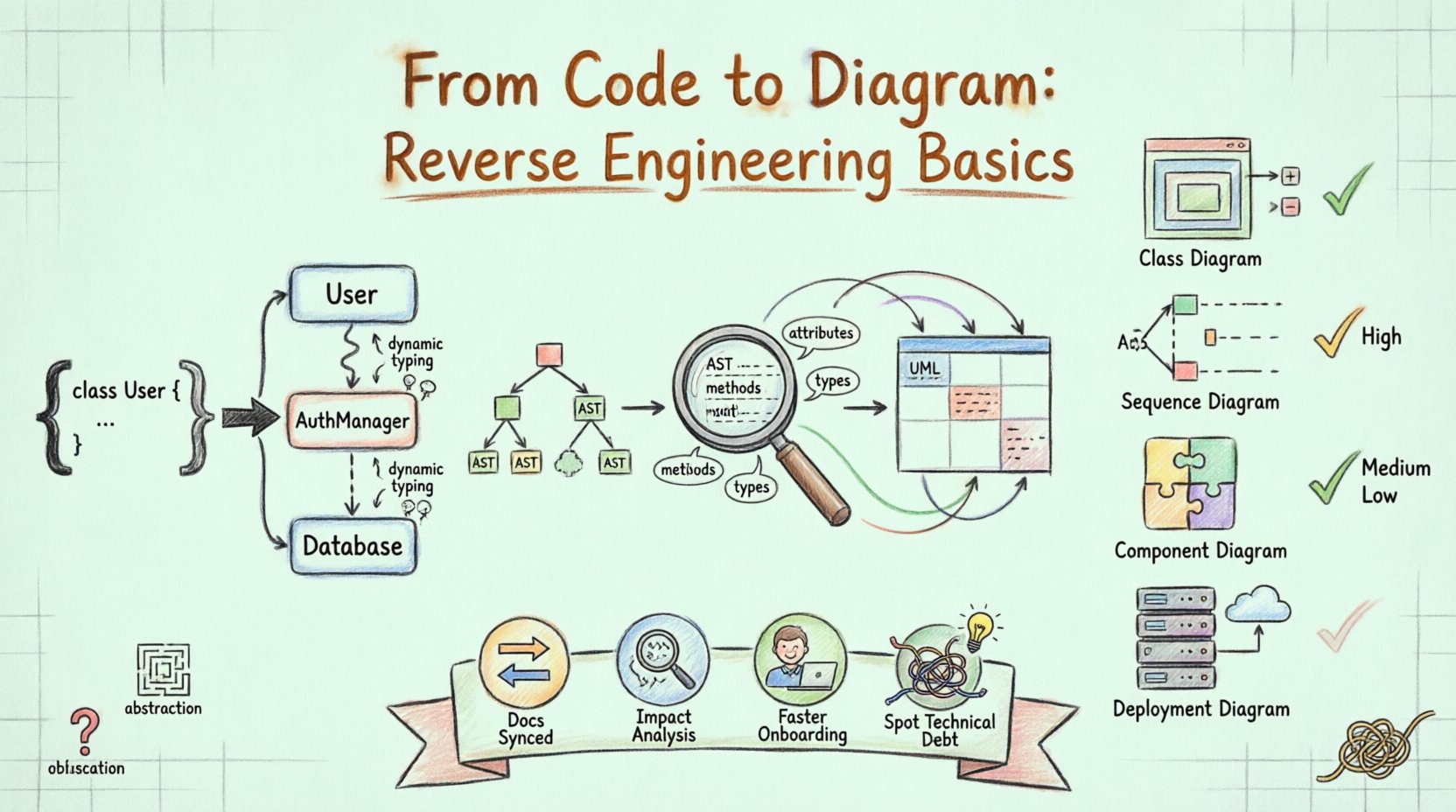
No cenário do desenvolvimento de software, manter a documentação frequentemente fica para trás em relação à velocidade da implementação. As bases de código crescem, funcionalidades são adicionadas e as decisões arquitetônicas originais tornam-se obscurecidas. É aqui que a engenharia reversa se torna uma disciplina essencial. Ela envolve a análise do código-fonte existente para reconstruir uma representação visual, geralmente usando diagramas da Linguagem de Modelagem Unificada (UML). Esse processo não se limita a documentar o que existe; ele esclarece como os componentes interagem, onde estão as dependências e como o sistema é estruturado.
Compreendendo a Engenharia Reversa no Contexto do UML 🧩
A engenharia reversa no desenvolvimento de software é o processo de analisar um sistema para identificar seus componentes e suas interrelações. Quando aplicada ao UML, o objetivo é derivar uma representação diagramática a partir da implementação real. Diferentemente da engenharia direta, em que diagramas orientam a escrita do código, a engenharia reversa começa com o código e deriva os diagramas.
Esta abordagem é particularmente valiosa para sistemas legados, onde a documentação pode estar desatualizada ou inexistente. Ao analisar o código-fonte, as ferramentas conseguem extrair nomes de classes, assinaturas de métodos, hierarquias de herança e links de associação. Esses elementos formam os blocos de construção dos diagramas de classes, diagramas de sequência e diagramas de componentes.
O Objetivo Central
O objetivo principal é alcançar um estado de compreensão. Os desenvolvedores frequentemente encontram código legado que parece uma caixa-preta. A engenharia reversa abre essa caixa, permitindo que as equipes visualizem o fluxo de dados e a lógica estrutural sem precisar ler cada linha da implementação. Serve como uma ponte entre a realidade concreta do código e a concepção abstrata do design.
Por que Gerar Diagramas a Partir do Código? 📊
Existem várias razões estratégicas para realizar esse processo. Não se trata apenas de criar imagens atraentes; trata-se de redução de riscos e clareza.
-
Sincronização da Documentação:O código muda frequentemente. Os diagramas gerados a partir do código estão sempre atualizados, refletindo o estado atual do sistema.
-
Análise de Impacto:Antes de refatorar um módulo, os desenvolvedores precisam saber o que depende dele. Os diagramas destacam essas dependências claramente.
-
Onboarding:Novos membros da equipe conseguem compreender a arquitetura do sistema muito mais rapidamente ao revisar diagramas do que navegando por um repositório de arquivos.
-
Identificação da Dívida Técnica:Estruturas complexas frequentemente se revelam como redes entrelaçadas nos diagramas, destacando áreas que precisam de simplificação.
O Processo da Engenharia Reversa 🔄
Transformar código em diagramas envolve um fluxo de trabalho sistemático. Embora as implementações específicas variem, os passos lógicos permanecem consistentes em diferentes ambientes.
1. Análise e Parsing
O primeiro passo envolve a leitura dos arquivos de código-fonte. O sistema analisa a sintaxe para compreender a estrutura. Ele identifica classes, interfaces, funções e variáveis. Nesta fase, o texto bruto é convertido em um formato de dados estruturado, frequentemente uma Árvore de Sintaxe Abstrata (AST). O analisador deve ser consciente da linguagem para interpretar corretamente a sintaxe específica da linguagem de programação em uso.
2. Extração de Metadados
Uma vez que o código é analisado, o sistema extrai metadados específicos. Isso inclui:
-
Atributos:Campos de dados dentro de classes.
-
Métodos:Funções e seus modificadores de acesso (público, privado, protegido).
-
Tipos:Os tipos de dados associados a atributos e valores de retorno.
-
Relações:Herança (extends/implements), associação (uso) e agregação (composição).
3. Mapeamento para Semântica UML
Os metadados extraídos devem ser mapeados para a notação UML. Por exemplo, uma definição de classe mapeia-se para uma caixa de Diagrama de Classes. Uma chamada de método dentro de uma função mapeia-se para uma interação em um Diagrama de Sequência. Esse mapeamento exige inferência lógica. Se a classe A cria uma instância da classe B, o sistema infere uma associação ou dependência.
4. Visualização e Renderização
O passo final é renderizar os dados em um formato visual. Isso envolve posicionar elementos em uma tela e desenhar linhas para representar relações. Os algoritmos de disposição tentam organizar o diagrama de forma que seja legível, minimizando linhas cruzadas e agrupando componentes relacionados.
Diagramas Comuns Gerados 📝
Nem todos os diagramas são igualmente adequados para engenharia reversa. Alguns capturam a estrutura estática, enquanto outros capturam o comportamento dinâmico.
|
Tipo de Diagrama |
Foco |
Utilidade na Engenharia Reversa |
|---|---|---|
|
Diagrama de Classes |
Estrutura Estática |
Alta. Mostra herança, atributos e métodos diretamente do código. |
|
Diagrama de Sequência |
Comportamento Dinâmico |
Média. Requer rastreamento de chamadas de métodos para entender o fluxo de interação. |
|
Diagrama de Componentes |
Módulos do Sistema |
Alta. Agrupa classes em unidades lógicas ou bibliotecas. |
|
Diagrama de Implantação |
Infraestrutura |
Baixa. Requer conhecimento de configuração de servidor, e não apenas do código. |
Desafios no Processo ⚠️
Embora poderoso, a engenharia reversa não está isento de dificuldades. Vários fatores podem complicar a geração de diagramas precisos.
Abstração e Ocultação
Bases de código modernas dependem fortemente da abstração. Interfaces e polimorfismo podem obscurecer a implementação real. Um método pode ser definido em uma interface, mas implementado em várias classes. Visualizar isso exige mostrar tanto o contrato quanto a realização, o que pode poluir um diagrama.
Tipagem Dinâmica
Linguagens que suportam tipagem dinâmica (onde os tipos de variáveis são determinados em tempo de execução) apresentam um desafio para a análise estática. A ferramenta de engenharia reversa pode ter dificuldades em determinar o tipo exato de um objeto sem executar o código ou analisar fluxos de controle complexos.
Obfuscamento de Código
Em alguns contextos, o código é obfuscado para proteger propriedade intelectual. A minificação e a renomeação de variáveis tornam o código-fonte difícil de ler para humanos e máquinas. A engenharia reversa de código obfuscado exige técnicas de análise significativamente mais sofisticadas.
Dependências Complexas
Sistemas grandes frequentemente têm dependências circulares ou módulos fortemente acoplados. Quando um diagrama é gerado, essas dependências podem criar um efeito ‘espaguete’, onde linhas se cruzam de forma caótica. Intervenção manual é frequentemente necessária para limpar o layout e agrupar elementos relacionados logicamente.
Melhores Práticas para Precisão ✅
Para garantir que os diagramas gerados sejam úteis, certas práticas devem ser seguidas durante o processo de engenharia reversa.
-
Filtrar Ruído: Exclua bibliotecas padrão ou código boilerplate que adicionam confusão visual sem valor arquitetônico. Foque na lógica de negócios personalizada.
-
Agrupar Módulos: Use pacotes ou namespaces para agrupar classes. Isso evita que o diagrama se torne um único nó massivo.
-
Validar Relacionamentos: Ferramentas automatizadas podem, às vezes, interpretar incorretamente relacionamentos. Revise os links gerados para garantir que reflitam com precisão a lógica do código.
-
Iterar: A engenharia reversa raramente é uma tarefa única. À medida que a base de código evolui, os diagramas devem ser regenerados e revisados periodicamente.
O Papel da Automação 🤖
A engenharia reversa manual é impraticável para projetos grandes. A automação é essencial. Analisadores automatizados escaneiam repositórios, constroem grafos de dependência e exportam para formatos padrão como XMI ou PlantUML. Isso permite que equipes integrem a geração de diagramas em seus pipelines de CI/CD.
A automação garante que a documentação nunca fique desatualizada. Se um desenvolvedor fizer um commit que quebre uma dependência, o processo de geração de diagramas pode sinalizar a inconsistência. Essa validação contínua ajuda a manter a integridade do sistema ao longo do tempo.
Integração de Diagramas na Manutenção 🛠️
Uma vez gerados, os diagramas devem ser usados ativamente. Eles não são apenas para apresentação. As equipes podem usá-los para planejar esforços de refatoração. Por exemplo, se um diagrama de classes mostrar uma classe com dependências excessivas, ela é candidata à decomposição.
Além disso, os diagramas ajudam nas revisões de código. Revisores podem analisar o impacto estrutural de uma mudança proposta antes de ler o diff. Isso desloca o foco da sintaxe para a arquitetura, melhorando a qualidade da base de código.
Conclusão sobre Insight Estrutural 🏁
A engenharia reversa de código em diagramas UML é uma prática fundamental para manter sistemas de software complexos. Transforma código opaco em arquitetura transparente, permitindo melhores decisões e comunicação mais clara. Embora existam desafios relacionados à tipagem dinâmica e dependências complexas, os benefícios da documentação sincronizada superam os custos. Priorizando a clareza estrutural, as equipes podem navegar em sistemas legados com confiança e modernizar seus aplicativos com precisão.