











💡 Kluczowe wnioski
-
Jasność wizualna:Inżynieria wsteczna przekształca gęsty kod źródłowy w czytelne diagramy UML, ujawniając ukrytą architekturę.
-
Mapowanie zależności:Automatyczna analiza identyfikuje relacje między modułami, wspomagając refaktoryzację i zrozumienie sprzężenia.
-
Modernizacja systemów dziedziczonych:Tworzenie diagramów na podstawie istniejących kodów źródłowych zamyka przerwę między długowiecznymi zaległościami technicznymi a przyszłą dokumentacją.
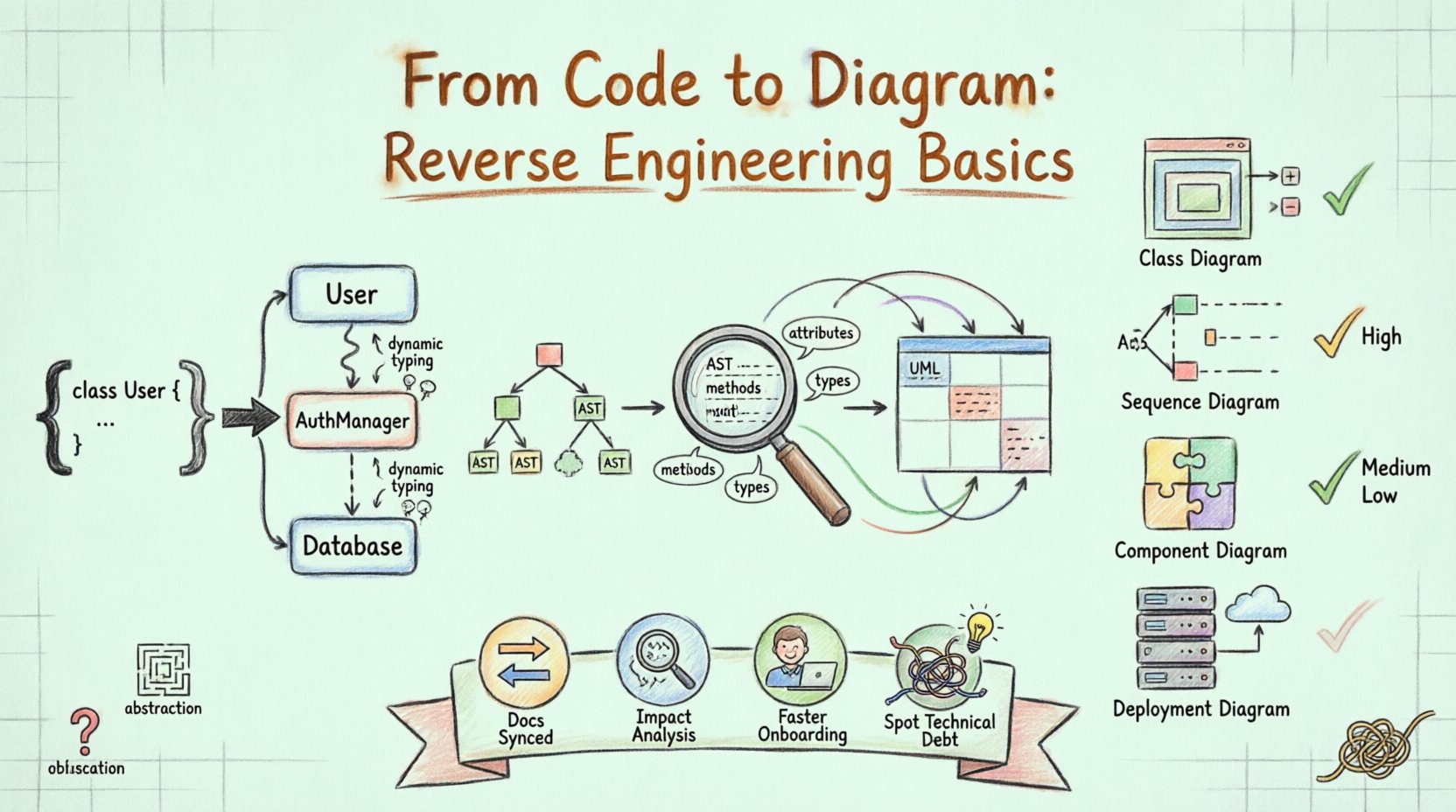
Na tle rozwoju oprogramowania utrzymywanie dokumentacji często nie nadąża z tempem implementacji. Kod źródłowy rośnie, dodawane są funkcje, a pierwotne decyzje architektoniczne stają się nieczytelne. To właśnie tutaj inżynieria wsteczna staje się niezbędną dziedziną. Polega na analizie istniejącego kodu źródłowego w celu odtworzenia wizualnej reprezentacji, zazwyczaj przy użyciu diagramów języka UML. Ten proces nie ogranicza się jedynie do dokumentowania tego, co istnieje; ujawnia sposób działania komponentów, położenie zależności oraz strukturę systemu.
Zrozumienie inżynierii wstecznej w kontekście UML 🧩
Inżynieria wsteczna w rozwoju oprogramowania to proces analizy systemu w celu identyfikacji jego składników i ich wzajemnych relacji. Gdy stosuje się ją do UML, celem jest wyprowadzenie reprezentacji diagramowej z rzeczywistej implementacji. W przeciwieństwie do inżynierii przedniej, gdzie diagramy kierują pisaniem kodu, inżynieria wsteczna zaczyna się od kodu i wyprowadza diagramy.
Ten podejście jest szczególnie wartościowe dla systemów dziedziczonych, gdzie dokumentacja może być przestarzała lub nie istnieć. Przez analizę kodu źródłowego narzędzia mogą wyodrębnić nazwy klas, sygnatury metod, hierarchie dziedziczenia oraz linki powiązań. Te elementy stanowią podstawę diagramów klas, diagramów sekwencji i diagramów składników.
Główny cel
Głównym celem jest osiągnięcie stanu zrozumienia. Programiści często napotykają kod dziedziczony, który wydaje się być czarną skrzynką. Inżynieria wsteczna otwiera tę skrzynkę, pozwalając zespołom wizualizować przepływ danych i logikę strukturalną bez konieczności czytania każdej linii implementacji. Stanowi most między konkretną rzeczywistością kodu a abstrakcyjnym pojęciem projektu.
Dlaczego generować diagramy z kodu? 📊
Istnieje kilka strategicznych powodów, aby podjąć ten proces. Nie chodzi jedynie o tworzenie atrakcyjnych obrazków; chodzi o redukcję ryzyka i jasność.
-
Synchronizacja dokumentacji:Kod często się zmienia. Diagramy generowane z kodu są zawsze aktualne, odzwierciedlając bieżący stan systemu.
-
Analiza wpływu:Zanim przeprowadzi się refaktoryzację modułu, programiści muszą wiedzieć, co na nim zależy. Diagramy jasno wyróżniają te zależności.
-
Wprowadzenie nowych członków zespołu:Nowi członkowie zespołu mogą szybciej zrozumieć architekturę systemu, przeglądając diagramy, niż przeszukując repozytorium plików.
-
Identyfikacja długów technicznych:Złożone struktury często ujawniają się jako zamętne sieci na diagramach, wyróżniając obszary wymagające uproszczenia.
Proces inżynierii wstecznej 🔄
Przekształcanie kodu w diagramy obejmuje systematyczny przepływ pracy. Choć konkretne implementacje się różnią, logiczne kroki pozostają spójne w różnych środowiskach.
1. Parsowanie i analiza
Pierwszy krok polega na odczytaniu plików kodu źródłowego. System parsuje składnię w celu zrozumienia struktury. Identyfikuje klasy, interfejsy, funkcje i zmienne. Ten etap przekształca surowy tekst w strukturalny format danych, często drzewo abstrakcyjnej składni (AST). Parsowanie musi być świadome języka, aby poprawnie zinterpretować składnię specyficzną dla używanego języka programowania.
2. Wyodrębnianie metadanych
Po przeparsowaniu kodu system wyodrębnia określone metadane. Obejmuje to:
-
Atrybuty:Pola danych w klasach.
-
Metody:Funkcje i ich modyfikatory dostępu (publiczne, prywatne, chronione).
-
Typy:Typy danych skojarzone z atrybutami i wartościami zwracanymi.
-
Związki:Dziedziczenie (extends/implements), asocjacja (użycie) i agregacja (kompozycja).
3. Mapowanie na semantykę UML
Wyodrębnione metadane muszą zostać przypisane do notacji UML. Na przykład definicja klasy odpowiada polu diagramu klasy. Wywołanie metody w funkcji odpowiada interakcji na diagramie sekwencji. To mapowanie wymaga wnioskowania logicznego. Jeśli klasa A tworzy instancję klasy B, system wnioskuje o istnienie związku lub zależności.
4. Wizualizacja i renderowanie
Ostatnim krokiem jest renderowanie danych w formacie wizualnym. Obejmuje to umieszczanie elementów na płótnie i rysowanie linii reprezentujących związki. Algorytmy układu stają się starać uporządkować diagram w taki sposób, aby był czytelny, minimalizując przecięcia linii i grupując powiązane komponenty.
Typowe generowane diagramy 📝
Nie wszystkie diagramy są równie odpowiednie do inżynierii wstecznej. Niektóre odzwierciedlają strukturę statyczną, inne zaś zachowanie dynamiczne.
|
Typ diagramu |
Skupienie |
Użyteczność w inżynierii wstecznej |
|---|---|---|
|
Diagram klas |
Struktura statyczna |
Wysoka. Pokazuje dziedziczenie, atrybuty i metody bezpośrednio z kodu źródłowego. |
|
Diagram sekwencji |
Zachowanie dynamiczne |
Średnia. Wymaga śledzenia wywołań metod w celu zrozumienia przepływu interakcji. |
|
Diagram składników |
Moduły systemu |
Wysoka. Grupuje klasy w jednostki logiczne lub biblioteki. |
|
Diagram wdrażania |
Infrastruktura |
Niska. Wymaga znajomości konfiguracji serwera, a nie tylko kodu źródłowego. |
Wyzwania w procesie ⚠️
Choć potężne, inżynieria wsteczna nie jest bez trudności. Kilka czynników może utrudniać generowanie dokładnych schematów.
Abstrakcja i ukrywanie
Nowoczesne bazy kodu bardzo dużo opierają się na abstrakcji. Interfejsy i polimorfizm mogą zakłócać rzeczywistą implementację. Metoda może być zdefiniowana w interfejsie, ale zaimplementowana w wielu klasach. Wizualizacja tego wymaga pokazania zarówno umowy, jak i realizacji, co może zaniechać schemat.
Dynamyczne typowanie
Języki wspierające dynamiczne typowanie (gdzie typy zmiennych są określone w czasie wykonywania) stwarzają wyzwanie dla analizy statycznej. Narzędzie do inżynierii wstecznej może mieć trudności z określeniem dokładnego typu obiektu bez uruchamiania kodu lub analizy skomplikowanych przepływów sterowania.
Zakłócanie kodu
W niektórych kontekstach kod jest zakłócony w celu ochrony własności intelektualnej. Minimalizacja i zmiana nazw zmiennych sprawiają, że kod źródłowy jest trudny do odczytania zarówno dla ludzi, jak i maszyn. Inżynieria wsteczna zakłóconego kodu wymaga znacznie bardziej zaawansowanych technik analizy.
Złożone zależności
Duże systemy często mają cykliczne zależności lub silnie powiązane moduły. Gdy generowany jest schemat, te zależności mogą tworzyć efekt „spaghetti”, w którym linie się chaotycznie przecinają. Często wymagana jest interwencja ręczna, aby uporządkować układ i logicznie grupować powiązane elementy.
Najlepsze praktyki dla dokładności ✅
Aby zapewnić, że wygenerowane schematy są użyteczne, podczas procesu inżynierii wstecznej należy stosować pewne praktyki.
-
Filtrowanie szumu: Wyklucz standardowe biblioteki lub kod szablonowy, który dodaje wizualny bałagan bez wartości architektonicznej. Skup się na niestandardowej logice biznesowej.
-
Grupuj moduły: Używaj pakietów lub przestrzeni nazw do grupowania klas. Zapobiega to temu, by schemat stał się jednym ogromnym węzłem.
-
Weryfikuj relacje: Narzędzia automatyczne czasem mogą źle rozumieć relacje. Przejrzyj wygenerowane linki, aby upewnić się, że poprawnie odzwierciedlają logikę kodu.
-
Iteruj: Inżynieria wsteczna rzadko jest zadaniem jednorazowym. W miarę ewolucji bazy kodu schematy powinny być ponownie generowane i okresowo przeglądana.
Rola automatyzacji 🤖
Ręczna inżynieria wsteczna jest nierealistyczna dla dużych projektów. Kluczowa jest automatyzacja. Automatyczne analizatory skanują repozytoria, budują grafy zależności i eksportują do standardowych formatów, takich jak XMI lub PlantUML. Pozwala to zespołom zintegrować generowanie schematów w swoich procesach CI/CD.
Automatyzacja zapewnia, że dokumentacja nigdy nie jest przestarzała. Jeśli programista zatwierdzi zmianę, która narusza zależność, proces generowania schematów może wykryć niezgodność. Ta ciągła weryfikacja pomaga utrzymać integralność systemu w czasie.
Integracja schematów w utrzymaniu 🛠️
Po wygenerowaniu schematów powinny one być aktywnie wykorzystywane. Nie są one tylko do prezentacji. Zespoły mogą ich używać do planowania działań refaktoryzacyjnych. Na przykład, jeśli diagram klasy pokazuje klasę z nadmierną liczbą zależności, jest kandydatem do rozkładania.
Dodatkowo, schematy pomagają w przeglądaniu kodu. Recenzenci mogą spojrzeć na wpływ strukturalny proponowanej zmiany, zanim przeczytają różnicę. Przesuwa to uwagę z składni na architekturę, poprawiając jakość bazy kodu.
Wnioski dotyczące zrozumienia strukturalnego 🏁
Inżynieria wsteczna kodu do schematów UML to podstawowa praktyka utrzymania złożonych systemów oprogramowania. Przekształca nieprzezroczysty kod w przejrzystą architekturę, umożliwiając lepsze podejmowanie decyzji i jasniejszą komunikację. Choć istnieją wyzwania związane z dynamicznym typowaniem i złożonymi zależnościami, korzyści z synchronizowanej dokumentacji przeważają nad kosztami. Poprzez priorytetyzowanie przejrzystości strukturalnej zespoły mogą bezpiecznie poruszać się po systemach dziedziczonych i modernizować swoje aplikacje z precyzją.