











💡 主なポイント
-
視覚的明確さ:リバースエンジニアリングは、濃密なソースコードを読みやすいUML図に変換し、隠されたアーキテクチャを明らかにする。
-
依存関係のマッピング:自動分析によりモジュール間の関係が特定され、リファクタリングや結合度の理解を支援する。
-
レガシーシステムの近代化:既存のコードベースから図を作成することで、技術的負債と将来のドキュメントの間のギャップを埋める。
ソフトウェア開発の文脈において、ドキュメントの維持は実装のスピードに追いつかないことがよくある。コードベースは拡大し、機能が追加され、元のアーキテクチャ設計の意思決定が曖昧になる。このような状況でリバースエンジニアリングは不可欠な分野となる。既存のソースコードを分析し、視覚的な表現(通常は統一モデリング言語UML図)を再構築するプロセスである。このプロセスは単に存在するものを記録するだけでなく、コンポーネントがどのように相互作用するか、依存関係がどこにあるか、システムがどのように構造化されているかを明確にする。
UMLの文脈におけるリバースエンジニアリングの理解 🧩
ソフトウェア開発におけるリバースエンジニアリングとは、システムの構成要素とそれらの相互関係を特定するために分析を行うプロセスである。UMLに適用すると、実際の実装から図式的表現を導き出すことが目的となる。フロントエンドエンジニアリングとは異なり、図がコードの記述をガイドするのに対し、リバースエンジニアリングはコードから始まり、図を導出する。
このアプローチは、ドキュメントが古くなっているか、存在しないレガシーシステムにおいて特に価値がある。ソースコードを解析することで、ツールはクラス名、メソッドシグネチャ、継承階層、関連リンクを抽出できる。これらの要素が、クラス図、シーケンス図、コンポーネント図の構成要素となる。
核心的な目的
主な目的は、理解の状態に到達することである。開発者はしばしばブラックボックスのように感じられるレガシーコードに直面する。リバースエンジニアリングによりそのボックスが開かれ、チームは実装の各行を読むことなく、データフローと構造的論理を視覚化できる。これは、コードの具体的な現実と設計の抽象的な概念との間の橋渡しとなる。
なぜコードから図を生成するのか? 📊
このプロセスを実施するにはいくつかの戦略的な理由がある。美しい図を描くことだけではなく、リスク低減と明確化が目的である。
-
ドキュメントの同期:コードは頻繁に変更される。コードから生成された図は常に最新であり、システムの現在の状態を反映している。
-
影響分析:モジュールのリファクタリングを行う前に、開発者はそれが何に依存しているかを把握する必要がある。図はこれらの依存関係を明確に示す。
-
オンボーディング:新規チームメンバーは、ファイルのリポジトリをナビゲートするよりも、図を確認することでシステムアーキテクチャをはるかに迅速に理解できる。
-
技術的負債の特定:複雑な構造はしばしば図の中で絡み合ったネットワークとして現れ、簡素化が必要な領域を強調する。
リバースエンジニアリングのプロセス 🔄
コードを図に変換するには、体系的なワークフローが必要である。具体的な実装は異なるが、論理的なステップは環境を問わず一貫している。
1. パースと分析
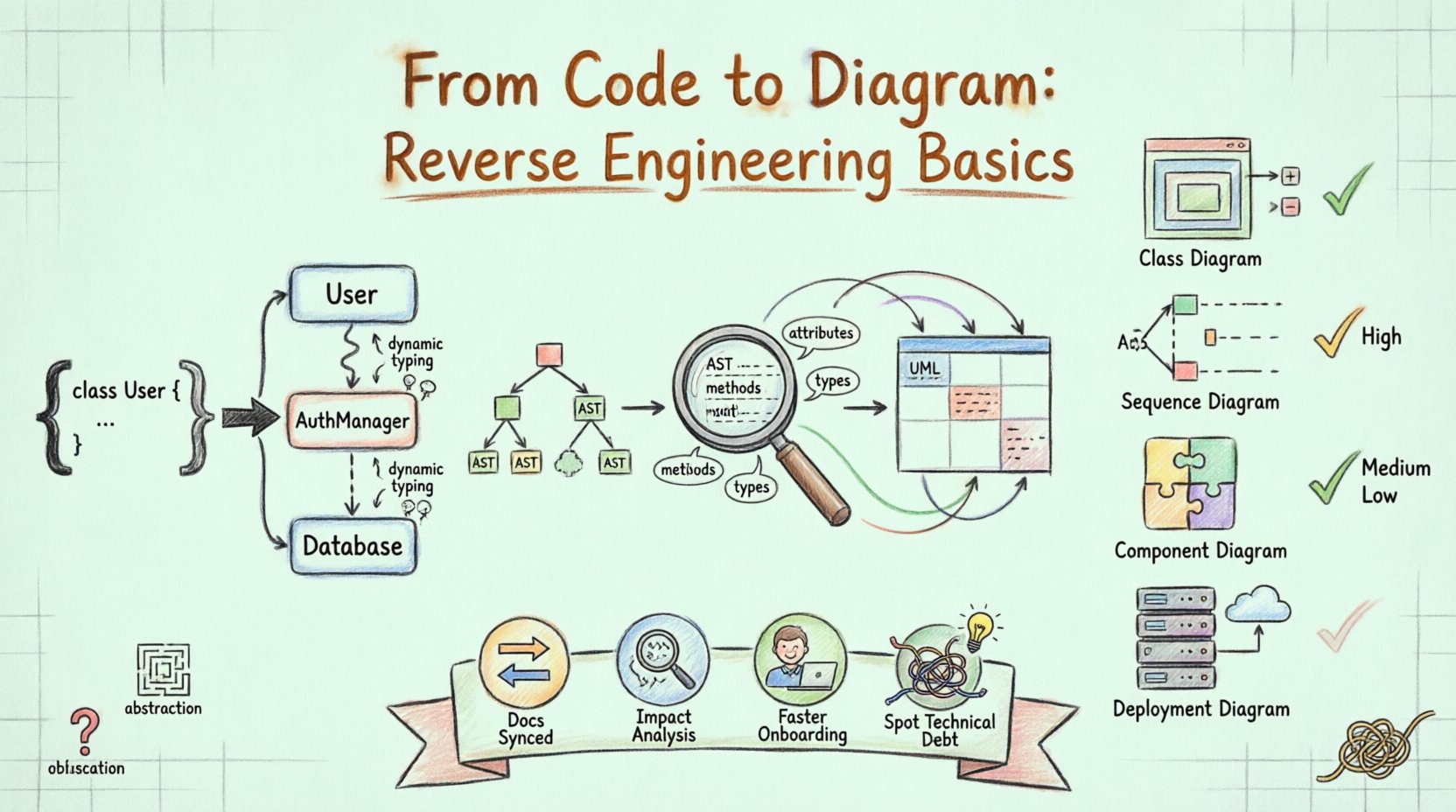
最初のステップは、ソースコードファイルを読み込むことである。システムは構文を解析して構造を理解する。クラス、インターフェース、関数、変数を特定する。この段階で、生のテキストを構造化されたデータ形式(通常は抽象構文木AST)に変換する。パーサーは使用中のプログラミング言語固有の構文を正しく解釈できるように、言語に特化した知識を持つ必要がある。
2. メタデータの抽出
コードがパースされると、システムは特定のメタデータを抽出する。これには以下が含まれる:
-
属性:クラス内のデータフィールド。
-
メソッド:関数とそのアクセス修飾子(public、private、protected)。
-
型:属性および戻り値に関連するデータ型。
-
関係:継承(extends/implements)、関連(使用)、集約(コンポジション)。
3. UML意味へのマッピング
抽出されたメタデータはUML表記にマッピングされなければならない。例えば、クラス定義はクラス図のボックスに対応する。関数内のメソッド呼び出しはシーケンス図における相互作用に対応する。このマッピングには論理的推論が必要である。クラスAがクラスBのインスタンスを生成する場合、システムは関連または依存関係を推論する。
4. 可視化とレンダリング
最終段階は、データを視覚形式にレンダリングすることである。これは、要素をキャンバス上に配置し、関係を表す線を引くことを含む。レイアウトアルゴリズムは、図が読みやすく、交差する線を最小限に抑え、関連するコンポーネントをグループ化するように図を整理しようとする。
一般的に生成される図 📝
すべての図がリバースエンジニアリングに同等に適しているわけではない。一部は静的構造を捉え、他の一部は動的動作を捉える。
|
図の種類 |
焦点 |
リバースエンジニアリングにおける有用性 |
|---|---|---|
|
クラス図 |
静的構造 |
高。コードから直接継承、属性、メソッドを示す。 |
|
シーケンス図 |
動的動作 |
中。相互作用の流れを理解するにはメソッド呼び出しの追跡が必要。 |
|
コンポーネント図 |
システムモジュール |
高。クラスを論理的な単位やライブラリにグループ化する。 |
|
配置図 |
インフラ構造 |
低。コードだけでなく、サーバー構成の知識が必要。 |
プロセスにおける課題 ⚠️
強力ではあるが、リバースエンジニアリングには難しさも伴う。正確な図を生成する際に複数の要因が複雑さをもたらすことがある。
抽象化と隠蔽
現代のコードベースは抽象化に大きく依存している。インターフェースやポリモーフィズムは実際の実装を曖昧にすることがある。メソッドはインターフェースで定義されているが、複数のクラスで実装されている場合もある。これを可視化するには契約と実装の両方を示す必要があり、図を混雑させてしまうことがある。
動的型付け
実行時に変数の型が決定される動的型付けをサポートする言語は、静的解析に課題をもたらす。リバースエンジニアリングツールは、コードを実行せずに複雑な制御フローを分析しない限り、オブジェクトの正確な型を特定できず、困難に直面することがある。
コードの難読化
ある文脈では、知的財産を保護するためにコードが難読化される。変数のミニファイや名前の変更により、ソースコードは人間や機械にとって読みにくくなる。難読化されたコードのリバースエンジニアリングには、はるかに高度な分析技術が必要となる。
複雑な依存関係
大規模なシステムでは、循環依存や密結合されたモジュールがよく見られる。図を生成すると、これらの依存関係が「スパゲッティ効果」と呼ばれる、線が混沌として交差する状態を生じる。レイアウトを整理し、関連する要素を論理的にグループ化するには、しばしば手動での介入が必要となる。
正確性のためのベストプラクティス ✅
生成された図が有用であることを確実にするため、リバースエンジニアリングの過程で特定の実践を守るべきである。
-
ノイズをフィルタリングする:アーキテクチャ上の価値がないのに視覚的なごみを増やす標準ライブラリやボイラープレートコードを除外する。カスタムビジネスロジックに注目する。
-
モジュールをグループ化する:パッケージや名前空間を使ってクラスをグループ化する。これにより、図が単一の大規模なノードになるのを防ぐ。
-
関係性を検証する:自動化ツールは時に関係性を誤解することがある。生成されたリンクを確認し、コードの論理を正確に反映しているかを検証する。
-
反復する:リバースエンジニアリングはほとんど一度限りの作業ではない。コードベースが進化するにつれて、図は定期的に再生成・レビューされるべきである。
自動化の役割 🤖
大規模なプロジェクトでは手動でのリバースエンジニアリングは現実的ではない。自動化が鍵となる。自動化されたパーサーがリポジトリをスキャンし、依存関係グラフを構築し、XMIやPlantUMLなどの標準フォーマットにエクスポートする。これにより、チームは図の生成をCI/CDパイプラインに統合できる。
自動化により、ドキュメントが古くなることはない。開発者が依存関係を破壊する変更をコミットした場合、図の生成プロセスが不整合を検出できる。この継続的な検証により、時間の経過とともにシステムの整合性を維持できる。
図を保守に統合する 🛠️
図が生成された後は、積極的に活用すべきである。プレゼンテーション用だけではない。チームはリファクタリングの計画に図を使用できる。たとえば、クラス図で過剰な依存関係を持つクラスが示された場合、それは分解の対象となる。
さらに、図はコードレビューを助ける。レビュアーはdiffを読む前に、提案された変更の構造的影響を確認できる。これにより、構文からアーキテクチャへと焦点が移り、コードベースの品質が向上する。
構造的インサイトに関する結論 🏁
コードをUML図にリバースエンジニアリングすることは、複雑なソフトウェアシステムを維持するための基本的な実践である。不透明なコードを透明なアーキテクチャに変換することで、より良い意思決定と明確なコミュニケーションを可能にする。動的型付けや複雑な依存関係に関する課題は存在するが、同期されたドキュメントの利点はそのコストを上回る。構造的明確性を優先することで、チームはレガシーシステムを自信を持って扱い、アプリケーションを正確に近代化できる。