











數據流圖(DFD)仍然是系統分析與設計的基石。雖然通常在入門課程中介紹,但在複雜的軟體工程環境中應用時,需要採取細膩的方法。本指南探討了構建、分析和維護數據流圖的高級技術。我們超越基本的方框與箭頭表示法,以應對並發性、資料完整性與架構對齊等問題。無論您是在重構遺留系統,還是設計新的微服務架構,掌握這些圖表都能確保溝通清晰且實現精確。
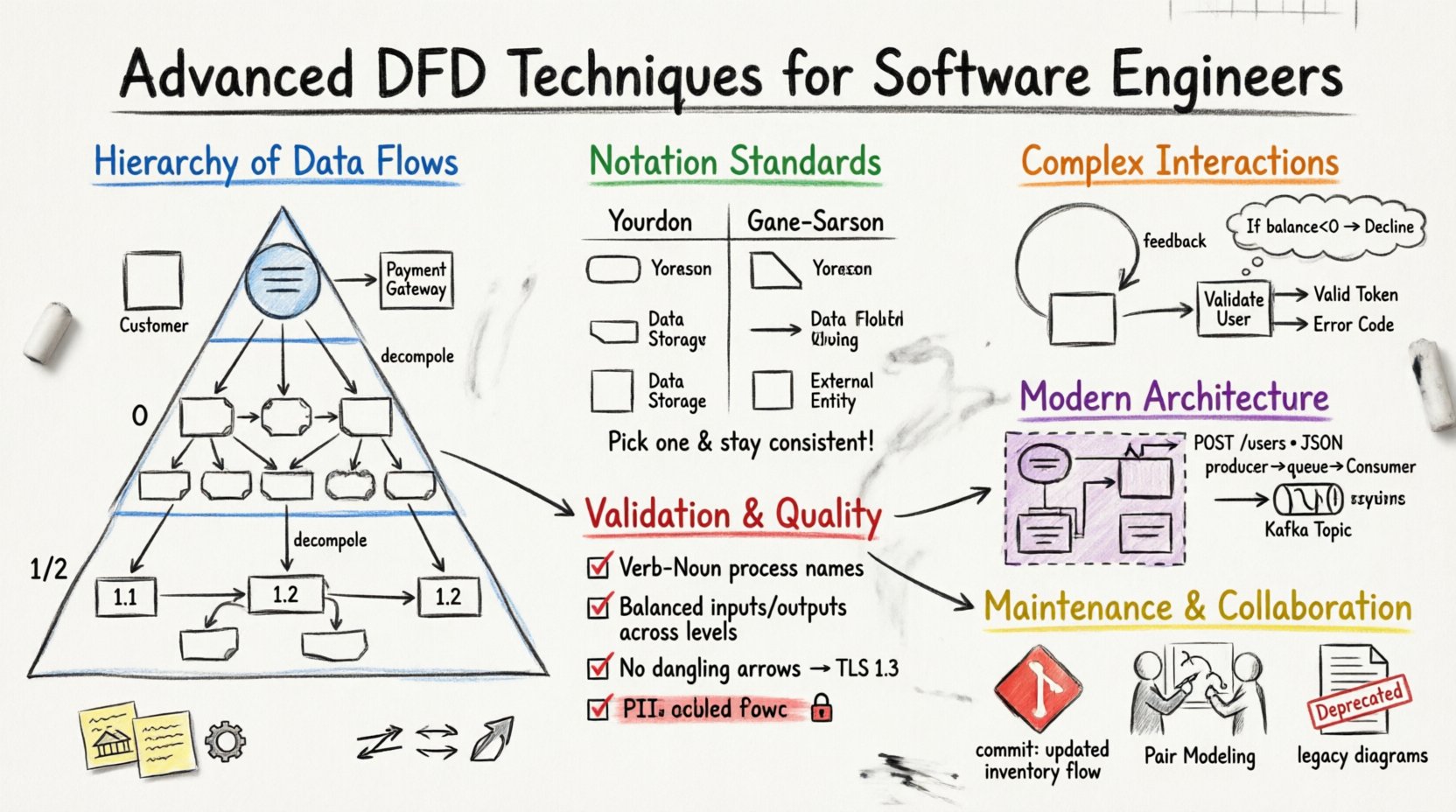
🏗️ 數據流層次結構的理解
強健的DFD策略依賴於分層方法。將系統僅在單一層級上進行視覺化,往往會掩蓋關鍵的依賴關係。透過將系統分解為特定層級,工程師可以管理複雜性,並專注於相關細節。
🌐 上下文圖:宏觀視角
上下文圖作為系統邊界的定義。它將軟體表示為單一處理過程,並識別所有與其互動的外部實體。此層級對於定義專案範圍至關重要。
- 外部實體: 這些是邊界以外的使用者、其他系統或硬體裝置。範例包括客戶、付款網關或遺留資料庫。
- 資料流: 箭頭表示資訊進入或離開系統的移動方向。標籤必須明確指出內容,例如「訂單請求」或「發票資料」。
- 單一處理過程: 系統本身以一個圓角矩形表示,通常標示系統名稱。
建立上下文圖時,應避免包含內部處理過程。目標是建立介面合約。如果某實體發送資料但從未接收,請確認該資料流是否必要。同樣地,確保所有來自外部來源的必要輸入都已捕捉。
📉 第0層:系統概覽
也稱為「頂層」或「父圖」,第0層將上下文圖中的單一處理過程擴展為主要子系統或功能區域。此層級提供系統功能的高階地圖,而不詳述內部邏輯。
第0層的主要特徵包括:
- 主要處理過程: 通常為5至9個處理過程。數量過多表示需要更高層級的分組;數量過少則暗示功能缺失。
- 資料儲存: 識別持久性資料存放的位置。此層級顯示資料被儲存,但不一定顯示其結構方式。
- 流程一致性: 上下文圖中的每一項輸入與輸出都必須在此出現。這確保分解過程未改變系統的外部合約。
🧩 第1層與第2層:分解策略
當您深入第1層與第2層時,焦點轉向特定功能與資料操作。這正是記錄工程工作邏輯的地方。
- 分解: 將第0層的處理過程分解為子處理過程。例如,“處理訂單”可能分解為“驗證庫存”、“收取付款”和“生成收據”。
- 細節化: 每個處理過程應編號(例如1.0、1.1、1.2),以便在各圖之間追蹤關係。
- 資料儲存存取: 明確標示哪些處理過程讀取或寫入哪些資料儲存。避免外部實體與資料儲存之間的直接連接;所有存取都必須透過處理過程進行。
分解時,請確保不會遺失資料流。常見的錯誤是遺漏子圖中原本存在於父圖的資料流。這被稱為「平衡」違規。
🔣 記號標準與符號語義
選擇正確的記號系統,可確保開發團隊所有人都能普遍理解圖表。雖然標準各不相同,但業界主要由兩種主要觀點主導。
| 功能 | Your-Donnell 記號 | Gane-Sarson 記號 |
|---|---|---|
| 處理程序 | 圓角矩形 | 切角矩形 |
| 資料儲存 | 開口矩形 | 開口矩形 |
| 外部實體 | 正方形 | 正方形 |
| 資料流 | 帶箭頭的線條 | 帶箭頭的線條 |
| 標籤 | 名詞片語 | 名詞片語 |
一致性至關重要。在同一套文件中混合使用不同記號會造成混淆。應選擇一種標準,並在所有圖表中嚴格遵守。選擇通常取決於工程文化或現有的文件模板。
⚙️ 管理複雜的資料互動
現實世界的系統很少是線性的。它們涉及迴圈、分支邏輯和非同步事件。在靜態圖表中呈現這些動態,需要特定的技巧。
🔄 處理迴圈與迭代
DFD 不是流程圖;它們不會明確顯示控制流程(if-then-else)。然而,資料迴圈很常見。例如,「計算稅額」處理程序可能將資料傳送至「稅率查詢」儲存,並接收結果回饋。
- 回饋迴圈:使用返回至處理程序的箭頭來表示重新評估。清楚標示這些箭頭,以顯示正在更新的資料。
- 迭代處理程序:如果一個處理程序會重複執行直到滿足某個條件,請在處理程序描述或文字註解中標示該條件。避免將迴圈繪製為控制流程線。
- 資料更新:顯示資料流返回資料儲存,以表示更新作業。
🧭 表示決策點
決策邏輯應出現在流程說明中,而非圖示本身。名為「驗證使用者」的流程暗示內部邏輯。不要將流程拆分為「驗證」與「拒絕」。保持流程的原子性。
- 輸出差異化:若流程根據內部決策傳送不同的資料,請使用不同的資料流標籤(例如「有效權杖」對應「錯誤代碼」)。
- 註解:使用文字方塊來明確決策條件。例如:「若餘額 < 0,則流程為『拒絕』」。
- 原子性:確保每個流程僅執行一個邏輯功能。若流程處理多個不同的決策,應考慮拆分為獨立的流程。
🔗 將資料流程圖整合至現代架構
軟體工程已演進。朝向分散式系統、雲端運算與 API 驅動設計的轉變,改變了我們看待資料流的方式。資料流程圖必須適應這些現實,而不致過時。
☁️ 微服務與 API 端點
在單體架構中,流程可能代表一個模組。在微服務環境中,流程通常代表一個服務實例。資料流則變為 API 呼叫。
- 服務邊界:在代表單一微服務的一組流程周圍畫一個框。跨越此邊界的資料流為網路請求。
- API 合約:以特定的 API 端點或資料結構標示資料流(例如:「POST /users」、「JSON 資料結構」)。
- 無狀態性:若服務為無狀態,除非用於暫時快取,否則不要在服務邊界內顯示資料儲存。持久化儲存應位於外部。
📨 異步通訊與佇列
並非所有資料流都以即時方式發生。背景作業與事件驅動架構依賴佇列。
- 佇列作為資料儲存:使用資料儲存符號來表示訊息佇列(例如 RabbitMQ、Kafka 主題)。這能明確表示資料僅暫時持久化。
- 生產者/消費者:顯示生產者流程寫入佇列,消費者流程從佇列讀取。資料流是解耦的。
- 延遲影響:在註解中指出,寫入後資料並非立即可用。這對於理解系統在故障情境下的行為至關重要。
🛡️ 驗證與一致性檢查
圖示只有在準確反映系統時才具有價值。驗證確保模型在數學與邏輯上皆正確。工程師應在最終定稿文件前執行這些檢查。
⚖️ 數據平衡驗證
進入圖表的每一筆資料流都必須被記錄。這是資料守恆的原則。
- 輸入/輸出匹配: 確保父圖中的每一筆輸入都出現在子圖中。任何輸入都不允許消失。
- 輸出完整性: 高層級定義的所有輸出都必須在低層級中存在。如果子流程產生了新的輸出,必須說明其為新需求或內部副作用。
- 儲存一致性: 資料儲存在各層級之間必須保持一致。如果在第1層建立了一個儲存,則第0層也必須存在。
🏷️ 命名規範
命名清晰可避免歧義。標籤不清是技術文件中誤解的最常見來源。
- 動詞-名詞格式: 流程應以動詞加名詞命名(例如:「計算稅額」、「更新個人資料」)。避免僅使用名詞(例如:「稅額」)或無對象的動詞短語(例如:「計算中」)。
- 資料流標籤: 使用具體的名詞(例如:「發票編號」、「使用者會話」)。避免使用「資料」或「資訊」等模糊詞語。
- 實體名稱: 外部實體應保持一致。「客戶」不應在相同圖表集內切換為「客戶」或「使用者」。
🔄 維護與文件生命週期
DFD不是靜態的產物。隨著軟體的變更,它們必須持續演進。一份過時的圖表比沒有圖表更糟糕,因為它會造成錯誤的理解。
📦 圖表的版本控制
將圖表視為程式碼。與原始碼倉庫一同儲存在版本控制系統中。
- 提交訊息: 在圖表提交中記錄變更。「新增付款網關流程」、「更新庫存流程」。
- 視覺差異比對: 使用可進行圖表視覺比對的工具,以發現未預期的結構性變更。
- 關聯性: 將圖表連結至導致變更的特定拉取請求或工單。這能提供可追蹤性。
🤝 協作策略
文件編寫是團隊合作的成果。過度依賴單一架構師維護DFD會造成瓶頸與資訊過時。
- 雙人建模: 在設計階段讓兩位工程師共同繪製圖表。這能及早發現錯誤。
- 審查週期:將DFD審查納入標準程式碼審查流程。若程式碼變更,圖表應予以更新,或標示為不同步。
- 活文件:避免存檔舊圖表。相反地,應在倉庫內將其標示為「已棄用」或「遺留」。如此可保留歷史紀錄,又不會使當前視圖混雜。
🧠 高階實作考量
除了視覺呈現之外,底層的資料結構與邏輯決定了資料流動。工程師必須考慮資料的實際物理限制。
📏 資料量與吞吐量
DFD描述的是邏輯流程,而非效能。然而,高流量的資料流會影響設計。
- 大量資料流:若某一流程涉及大型檔案或記錄檔,請以標籤標示。這可能觸發改用不同傳輸機制的決策。
- 壓縮:請註明資料在傳輸前是否已壓縮。這會影響接收端的處理負載。
- 編碼:若資料流跨越平台邊界(例如 UTF-8 與 ASCII 之間),請明確指定字元編碼。
🔒 安全性與存取控制
安全性不能是事後補救。它必須在資料流中清晰可見。
- 加密:標示需要加密的資料流。可使用「加密串流」或「TLS 1.3」等標籤。
- 個人識別資訊處理:強調包含個人識別資訊的資料流。確保設計符合合規性要求。
- 驗證:標示憑證傳遞的位置。避免在明文資料流中顯示密碼;應標示為「驗證金鑰」。
📝 圖表品質檢查清單
在最終確定一組資料流圖表之前,請逐一核對此驗證清單。
- 所有外部實體是否都已明確定義?
- 所有資料流是否都有描述性標籤?
- 每個流程是否都以動詞-名詞結構命名?
- 是否有交叉的線條可重新佈線以提升清晰度?
- 父圖中的每個輸入是否都出現在子圖中?
- 資料儲存是否與流程正確分離?
- 該圖是否與上下文圖保持平衡?
- 是否有懸空的箭頭(沒有目的地的流程)?
- 文件集中的符號使用是否一致?
- 敏感流程上是否標註了安全限制?
透過遵循這些進階技巧,軟體工程師可以產出作為開發可靠藍圖的文件。資料流程圖彌補了抽象需求與具體實作之間的差距。它促進了利害關係人之間的溝通,減少邏輯上的模糊性,並提供測試的基準。只要以紀律維護並嚴格更新,它們仍然是工程工具箱中強大的工具。
🚀 對系統建模的最終思考
資料流程圖的價值在於其簡化複雜性的能力。它剔除了語法和實作細節的干擾,專注於價值的流動。對軟體工程師而言,這種專注至關重要。它能促進設計缺陷的早期發現,讓新成員更容易上手,並建立系統架構的共通心智模型。投入建模的過程。雖然需要付出努力,但系統清晰度的投資回報極為顯著。
請記住,圖表只是一種達成目標的手段。它支援程式碼,而不是相反。保持圖表簡潔、準確且易於存取。隨著系統的演進,讓圖表也隨之演進。這種動態方法確保文件始終是活躍的資產,而非靜態的負擔。