











Diagramy przepływu danych (DFD) nadal stanowią fundament analizy i projektowania systemów. Choć często wprowadzane na poziomie wstępnym, ich zastosowanie w złożonych środowiskach inżynierii oprogramowania wymaga subtelnej strategii. Ten przewodnik omawia zaawansowane techniki budowania, analizowania i utrzymywania diagramów przepływu danych. Przechodzimy dalej poza podstawowe przedstawienia w postaci pudełek i strzałek, aby rozwiązać problemy związane z współbieżnością, integralnością danych i zgodnością architektoniczną. Niezależnie od tego, czy modernizujesz systemy dziedziczne, czy projektujesz nowe architektury mikroserwisów, opanowanie tych diagramów zapewnia jasność komunikacji i precyzję w implementacji.
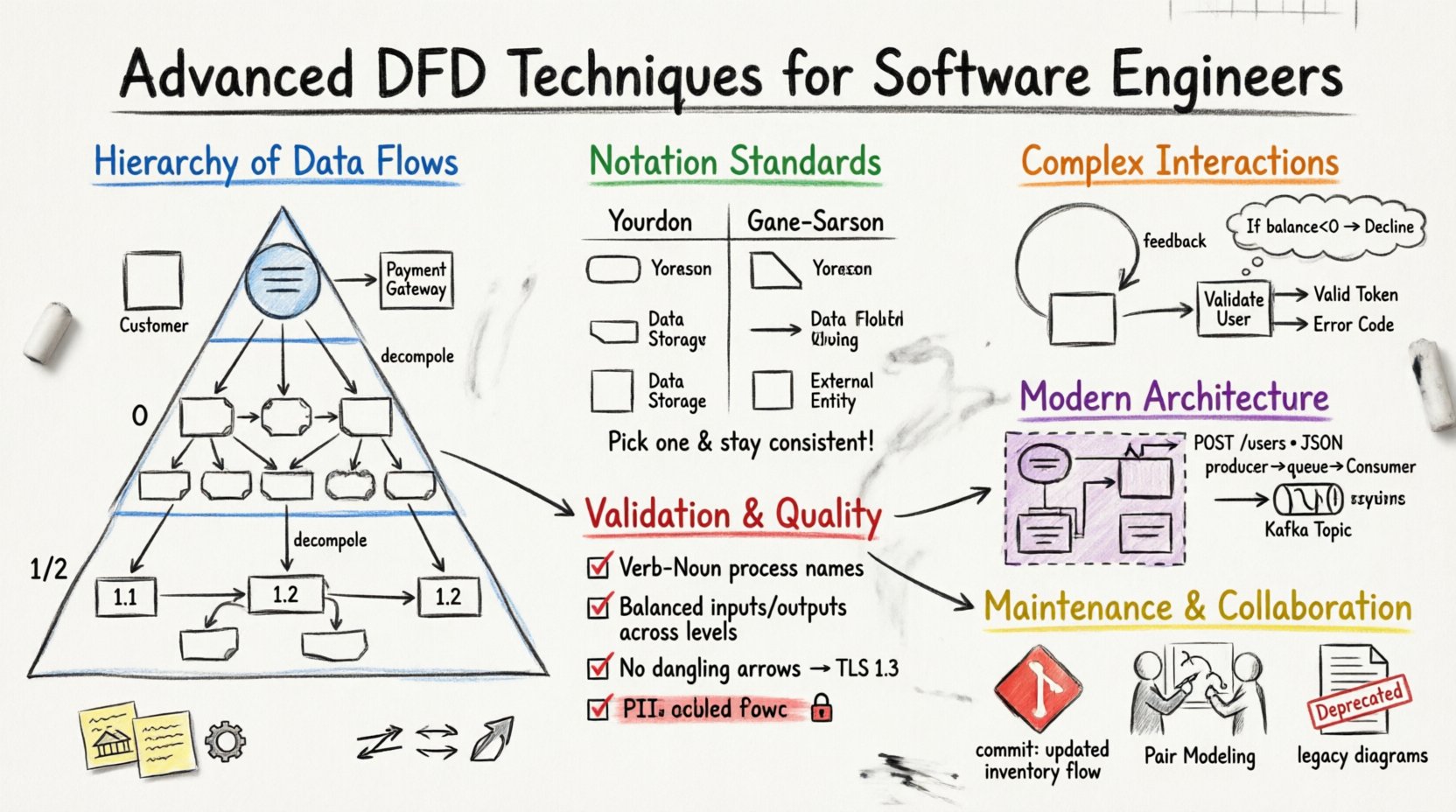
🏗️ Zrozumienie hierarchii przepływów danych
Solidna strategia DFD opiera się na podejściu warstwowym. Wizualizacja systemu na jednym poziomie często zakrywa kluczowe zależności. Przez rozkład systemu na konkretne poziomy inżynierowie mogą zarządzać złożonością i utrzymywać skupienie na istotnych szczegółach.
🌐 Diagramy kontekstowe: widok makro
Diagram kontekstowy służy do określenia granic systemu. Reprezentuje oprogramowanie jako pojedynczy proces i identyfikuje wszystkie zewnętrzne jednostki, które z nim współpracują. Ten poziom jest kluczowy do określenia zakresu projektu.
- Jednostki zewnętrzne: Są to użytkownicy, inne systemy lub urządzenia sprzętowe poza granicami systemu. Przykłady to Klient, brama płatności lub starsza baza danych.
- Przepływy danych: Strzałki wskazują ruch informacji do systemu lub z niego. Etykiety muszą określać zawartość, np. „Prośba o zamówienie” lub „Dane faktury”.
- Pojedynczy proces: System jest przedstawiony jako pojedynczy prostokąt z zaokrąglonymi rogami, często oznaczony nazwą systemu.
Podczas tworzenia diagramu kontekstowego unikaj uwzględniania procesów wewnętrznych. Celem jest ustalenie umowy interfejsu. Jeśli jednostka wysyła dane, ale nigdy ich nie otrzymuje, sprawdź, czy ten przepływ jest rzeczywiście potrzebny. Podobnie upewnij się, że wszystkie wymagane dane z zewnętrznych źródeł są zapisane.
📉 Poziom 0: Przegląd systemu
Znany również jako diagram „poziomu najwyższego” lub „rodzicielski”, poziom 0 rozszerza pojedynczy proces z diagramu kontekstowego na główne podsystemy lub obszary funkcjonalne. Ten poziom zapewnia ogólny obraz możliwości systemu bez szczegółowego opisu logiki wewnętrznej.
Kluczowe cechy poziomu 0 to:
- Główne procesy: Zazwyczaj od 5 do 9 procesów. Zbyt dużo wskazuje na potrzebę grupowania na wyższym poziomie; zbyt mało sugeruje brakujące funkcjonalności.
- Magazyny danych: Określ, gdzie przechowywane są dane trwałe. Ten poziom pokazuje *to*, że dane są przechowywane, a niekoniecznie jak są zorganizowane.
- Spójność przepływu: Każdy wejście i wyjście z diagramu kontekstowego musi się tu pojawić. Zapewnia to, że rozkład nie zmienił zewnętrznego kontraktu systemu.
🧩 Poziom 1 i 2: Strategie rozkładu
Podczas przejścia do poziomu 1 i 2 skupienie przesuwa się na konkretne funkcje i manipulację danymi. To właśnie tutaj dokumentowana jest logika pracy inżynierskiej.
- Rozkład: Rozbij procesy poziomu 0 na podprocesy. Na przykład „Przetwarzanie zamówienia” może stać się „Weryfikacja stanu magazynowego”, „Załadunek płatności” i „Generowanie paragonu”.
- Szczegółowanie: Każdy proces powinien być oznaczony numerem (np. 1.0, 1.1, 1.2), aby śledzić relacje między diagramami.
- Dostęp do magazynu danych: Jasno zaznacz, które procesy odczytują lub zapisują dane do których magazynów. Unikaj bezpośrednich połączeń między jednostkami zewnętrznymi a magazynami danych; cały dostęp musi przechodzić przez proces.
Podczas dekompozycji upewnij się, że nie utraci się przepływy danych. Powszechnym błędem jest pominięcie przepływu danych na diagramie potomnym, który istniał na diagramie nadrzędnej. Jest to znane jako naruszenie „zrównoważenia”.
🔣 Standardy notacji i znaczenie symboli
Wybór odpowiedniego systemu notacji zapewnia, że diagramy są powszechnie rozumiane przez zespół programistów. Choć standardy się różnią, dwie główne szkoły myślenia dominują w branży.
| Cecha | Notacja Your-Donnell | Notacja Gane-Sarson |
|---|---|---|
| Procesy | Okrągłe prostokąty | Prostokąty z przciętymi rogami |
| Magazyny danych | Prostokąty otwarte na jednym końcu | Prostokąty otwarte na jednym końcu |
| Zewnętrzne jednostki | Kwadraty | Kwadraty |
| Przepływy danych | Linie z strzałkami | Linie z strzałkami |
| Etykiety | Frazy rzeczownikowe | Frazy rzeczownikowe |
Spójność jest najważniejsza. Mieszanie notacji w ramach tego samego zestawu dokumentacji powoduje zamieszanie. Wybierz jeden standard i przestrzegaj go we wszystkich diagramach. Wybór często zależy od kultury inżynierskiej lub istniejących szablonów dokumentacji.
⚙️ Zarządzanie złożonymi interakcjami danych
Systemy rzeczywiste rzadko są liniowe. Zajmują się one pętlami, logiką rozgałęzieniową i zdarzeniami asynchronicznymi. Przedstawienie tych dynamicznych zjawisk na statycznym diagramie wymaga specyficznych technik.
🔄 Obsługa pętli i iteracji
Diagramy przepływu danych (DFD) nie są schematami blokowymi; nie pokazują jawnie przepływu sterowania (jeśli-to-else). Jednak pętle danych są powszechne. Na przykład proces „Oblicz podatek” może wysłać dane do magazynu „Wyszukiwanie stawki” i otrzymać wynik z powrotem.
- Pętle sprzężenia zwrotnego:Używaj strzałek powracających do procesu, aby wskazać ponowną ocenę. Jasną etykietą zaznacz, jakie dane są aktualizowane.
- Procesy iteracyjne: Jeśli proces powtarza się, dopóki nie zostanie spełniony warunek, zaznacz ten warunek w opisie procesu lub w adnotacji tekstowej. Unikaj rysowania pętli jako linii przepływu sterowania.
- Aktualizacje danych: Pokaż przepływ danych powracający do magazynu danych, aby oznaczyć operację aktualizacji.
🧭 Reprezentacja punktów decyzyjnych
Logika decyzyjna powinna znajdować się w opisie procesu, a nie w samym diagramie. Proces o nazwie „Weryfikacja użytkownika” sugeruje wewnętrzną logikę. Nie dziel proces na „Weryfikacja” i „Odmowa”. Zachowaj proces jako jednostkę.
- Różnicowanie wyjść: Jeśli proces wysyła różne dane w zależności od wewnętrznej decyzji, użyj różnych etykiet przepływu danych (np. „Poprawny token” w porównaniu do „Kod błędu”).
- Adnotacje: Użyj pól tekstowych, aby wyjaśnić kryteria decyzyjne. Na przykład: „Jeśli saldo < 0, przepływ ‘Odmowa'”.
- Atomowość: Upewnij się, że każdy proces wykonuje jedną funkcję logiczną. Jeśli obsługuje wiele różnych decyzji, rozważ podział na osobne procesy.
🔗 Integracja DFD z nowoczesnymi architekturami
Inżynieria oprogramowania się zmieniła. Przejście w kierunku systemów rozproszonych, obliczeń chmurowych i projektowania opartego na interfejsach API zmienia sposób, w jaki postrzegamy przepływy danych. DFD muszą się dostosować, by odzwierciedlać te rzeczywistości, nie stając się przestarzałymi.
☁️ Mikroserwisy i punkty końcowe interfejsów API
W architekturze monolitycznej proces może reprezentować moduł. W środowisku mikroserwisów proces często reprezentuje instancję usługi. Przepływ danych staje się wywołaniem interfejsu API.
- Granice usług: Narysuj prostokąt wokół zestawu procesów, które tworzą pojedynczy mikroserwis. Przepływy danych przekraczające tę granicę są żądaniami sieciowymi.
- Umowy interfejsów API: Oznacz przepływy danych konkretnym punktem końcowym interfejsu API lub strukturą danych (np. „POST /users”, „Ciało w formacie JSON”).
- Bezstanowość: Jeśli usługa jest bezstanowa, nie pokazuj magazynu danych wewnątrz granicy usługi, chyba że jest to tymczasowe buforowanie. Trwałe przechowywanie danych powinno odbywać się poza granicą usługi.
📨 Komunikacja asynchroniczna i kolejki
Nie wszystkie przepływy danych odbywają się w czasie rzeczywistym. Zadania w tle i architektury oparte na zdarzeniach opierają się na kolejkach.
- Kolejki jako magazyny danych: Reprezentuj kolejki komunikatów (np. RabbitMQ, tematy Kafka) za pomocą symbolu magazynu danych. To wyjaśnia, że dane są tymczasowo przechowywane.
- Producent/konsument: Pokaż proces producenta zapisujący do kolejki oraz proces konsumenta odczytujący z niej. Przepływ jest rozłączony.
- Skutki opóźnień: Zaznacz w adnotacjach, że dane nie są od razu dostępne po zapisie. Jest to kluczowe dla zrozumienia zachowania systemu w przypadku awarii.
🛡️ Weryfikacja i sprawdzanie spójności
Diagram jest użyteczny tylko wtedy, gdy dokładnie odzwierciedla system. Weryfikacja zapewnia, że model jest poprawny matematycznie i logicznie. Inżynierowie powinni wykonać te sprawdzenia przed zakończeniem dokumentacji.
⚖️ Weryfikacja równowagi danych
Każny przepływ danych wejściowych do diagramu musi być zarejestrowany. Jest to zasada zachowania danych.
- Dopasowanie wejść/wyjść: Upewnij się, że każde wejście z diagramu nadrzędnego pojawia się w diagramie potomnym. Żadne wejście nie może zniknąć.
- Pełność wyjść: Wszystkie wyjścia zdefiniowane na wyższym poziomie muszą być obecne na niższym poziomie. Jeśli proces potomny generuje nowe wyjście, musi być uzasadnione jako nowa wymagania lub wewnętrzny efekt uboczny.
- Spójność magazynów: Magazyny danych muszą być spójne na wszystkich poziomach. Jeśli magazyn jest tworzony na poziomie 1, musi istnieć również na poziomie 0.
🏷️ Zasady nazewnictwa
Jasność nazewnictwa zapobiega nieporozumieniom. Złe etykiety to najczęstsza przyczyna nieporozumień w dokumentacji technicznej.
- Format czasownik-przysłówek: Procesy powinny być nazwane za pomocą czasownika i rzeczownika (np. „Oblicz podatek”, „Zaktualizuj profil”). Unikaj tylko rzeczowników (np. „Podatek”) lub czasowników bez obiektu (np. „Obliczanie”).
- Etykiety przepływów danych: Używaj konkretnych rzeczowników (np. „ID faktury”, „Sesja użytkownika”). Unikaj nieprecyzyjnych słów takich jak „Dane” lub „Informacje”.
- Nazwy encji: Encje zewnętrzne powinny być spójne. „Klient” nie powinien zmieniać się na „Klienta” lub „Użytkownika” w tym samym zestawie diagramów.
🔄 Konserwacja i cykl życia dokumentacji
Diagramy przepływu danych nie są statycznymi artefaktami. Muszą ewoluować wraz z zmianami oprogramowania. Diagram przestarzały jest gorszy niż brak diagramu, ponieważ tworzy iluzję zrozumienia.
📦 Kontrola wersji dla diagramów
Traktuj diagramy jak kod. Przechowuj je w systemie kontroli wersji razem z repozytorium kodu źródłowego.
- Komunikaty commitów: Dokumentuj zmiany w commitach diagramów. „Dodano proces bramy płatności”, „Zaktualizowano przepływ zapasów”.
- Wizualne porównanie różnic: Używaj narzędzi umożliwiających wizualne porównanie diagramów, aby wykryć niechciane zmiany strukturalne.
- Powiązania: Powiąż diagramy z konkretnymi żądaniami zmian lub biletami, które spowodowały zmianę. Zapewnia to śledzenie zmian.
🤝 Strategie współpracy
Dokumentacja to praca zespołu. Zależność od jednego architekta w utrzymaniu diagramów przepływu danych prowadzi do węzłów zakłóceń i przestarzałych informacji.
- Modelowanie w parach: Niech dwóch inżynierów narysuje diagram razem w fazie projektowania. Pozwala to wykryć błędy na wczesnym etapie.
- Cykle przeglądu:Uwzględnij przeglądy DFD w standardowym procesie przeglądu kodu. Jeśli kod ulegnie zmianie, diagram powinien zostać zaktualizowany lub oznaczony jako niezgodny.
- Dokumenty żywe:Unikaj archiwizowania starych diagramów. Zamiast tego oznacz je jako „Przestarzałe” lub „Używane w przeszłości” w repozytorium. Zachowuje to historię bez zanieczyszczenia aktualnego widoku.
🧠 Zaawansowane kwestie implementacji
Poza reprezentacją wizualną, struktury danych i logika leżące u podstaw decydują o przepływie. Inżynierowie muszą brać pod uwagę ograniczenia fizyczne danych.
📏 Objętość danych i przepustowość
Diagramy przepływu danych opisują przepływ logiczny, a nie wydajność. Jednak przepływy o dużym obciążeniu wpływają na projektowanie.
- Przepływy danych masowych: Jeśli przepływ obejmuje duże pliki lub dzienniki, oznacz to etykietą. Może to wywołać decyzję o użyciu innego mechanizmu przesyłania.
- Kompresja: Zaznacz, czy dane są kompresowane przed przesłaniem. Ma to wpływ na obciążenie przetwarzania na końcu odbiorczym.
- Kodowanie: Określ kodowanie znaków, jeśli przepływ przekracza granice platform (np. UTF-8 vs. ASCII).
🔒 Bezpieczeństwo i kontrola dostępu
Bezpieczeństwo nie jest myślą wtórną. Musi być widoczne w przepływie danych.
- Szyfrowanie:Oznacz przepływy wymagające szyfrowania. Użyj etykiety takiej jak „Zaszyfrowany strumień” lub „TLS 1.3”.
- Obsługa danych osobowych:Wyróżnij przepływy zawierające dane osobowe. Zapewnia to spełnienie wymogów zgodności w projekcie.
- Uwierzytelnianie:Pokaż, gdzie przekazywane są dane uwierzytelniające. Unikaj pokazywania haseł w przepływach tekstowych; oznacz jako „Token uwierzytelniający”.
📝 Lista kontrolna jakości diagramu
Zanim zakończysz pracę z zestawem diagramów przepływu danych, przejdź przez tę listę weryfikacji.
- Czy wszystkie jednostki zewnętrzne są jasno zdefiniowane?
- Czy wszystkie przepływy danych mają opisowe etykiety?
- Czy każdy proces ma nazwę w strukturze czasownik-przysłówek?
- Czy są jakieś przecinające się linie, które można przesunąć dla lepszej czytelności?
- Czy każdy wejściowy element w diagramie nadrzędnym pojawia się w diagramie podrzędnym?
- Czy magazyny danych są odpowiednio oddzielone od procesów?
- Czy diagram jest zrównoważony w stosunku do diagramu kontekstowego?
- Czy są wisiące strzałki (przepływy bez docelowego punktu)?
- Czy notacja jest spójna we wszystkich dokumentach?
- Czy na wrażliwych przepływach zaznaczono ograniczenia dotyczące bezpieczeństwa?
Przestrzegając tych zaawansowanych technik, inżynierowie oprogramowania mogą tworzyć dokumentację, która pełni rolę wiarygodnego projektu budowy. Diagramy przepływu danych (DFD) zamykają lukę między abstrakcyjnymi wymaganiami a konkretną realizacją. Ułatwiają komunikację między zaangażowanymi stronami, zmniejszają niepewność w logice i stanowią podstawę do testowania. Gdy są utrzymywane z dyscypliną i regularnie aktualizowane, pozostają potężnym narzędziem w arsenale inżynierskim.
🚀 Ostateczne rozważania na temat modelowania systemu
Wartość diagramu przepływu danych polega na jego zdolności do uproszczenia złożoności. Usuwa szum związany z składnią i szczegółami implementacji, skupiając się na przepływie wartości. Dla inżynierów oprogramowania ta skupienie jest kluczowa. Pozwala wykrywać wczesne błędy w projektowaniu, ułatwia onboardowanie nowych członków zespołu oraz tworzy wspólny model mentalny architektury systemu. Zadbaj o proces modelowania. Wymaga to wysiłku, ale zwrot z inwestycji w przejrzystość systemu jest znaczny.
Pamiętaj, że diagram to środek do celu. Wspiera kod, a nie odwrotnie. Trzymaj diagramy zwięzłe, dokładne i dostępne. Gdy system się rozwija, niech diagramy rozwijają się razem z nim. Ta dynamiczna metoda zapewnia, że dokumentacja pozostaje żyjącym zasobem, a nie statycznym obciążeniem.