











データフローダイアグラム(DFD)は、システム分析および設計における基本的な視覚的表現です。情報の流れをシステム内にマッピングし、データが入力から出力へどのように移動するかを強調します。制御論理に焦点を当てるフローチャートとは異なり、DFDはデータの移動に注目します。このガイドは、特定の独自ツールに依存せずに正確な図を構築するための手法を概説します。このプロセスには明確な思考と、既定の記号規則への従いが求められます。
🧐 コア目的の理解
線や図形を描く前に、目的を理解する必要があります。DFDはシステムの機能要件をモデル化します。システムが何を行うかを示すものであり、物理的な実装方法を示すものではありません。この区別はアナリストにとって極めて重要です。ステークホルダーが技術的な実装の詳細に巻き込まれることなく、ビジネスプロセスの論理を検証できるようにします。
この図は以下の点を特定するのに役立ちます:
- データがシステムの境界内でどこから始まるか。
- データがどのように有用な情報に変換されるか。
- データが将来の参照のためにどこに保存されるか。
- データがシステムから外部の当事者へどのように出るか。
これらの要素を可視化することで、開発ライフサイクルの初期段階でボトルネック、重複、または欠落しているデータ経路を検出できます。これは技術チームとビジネスユーザーの間のコミュニケーションの橋渡しとなります。
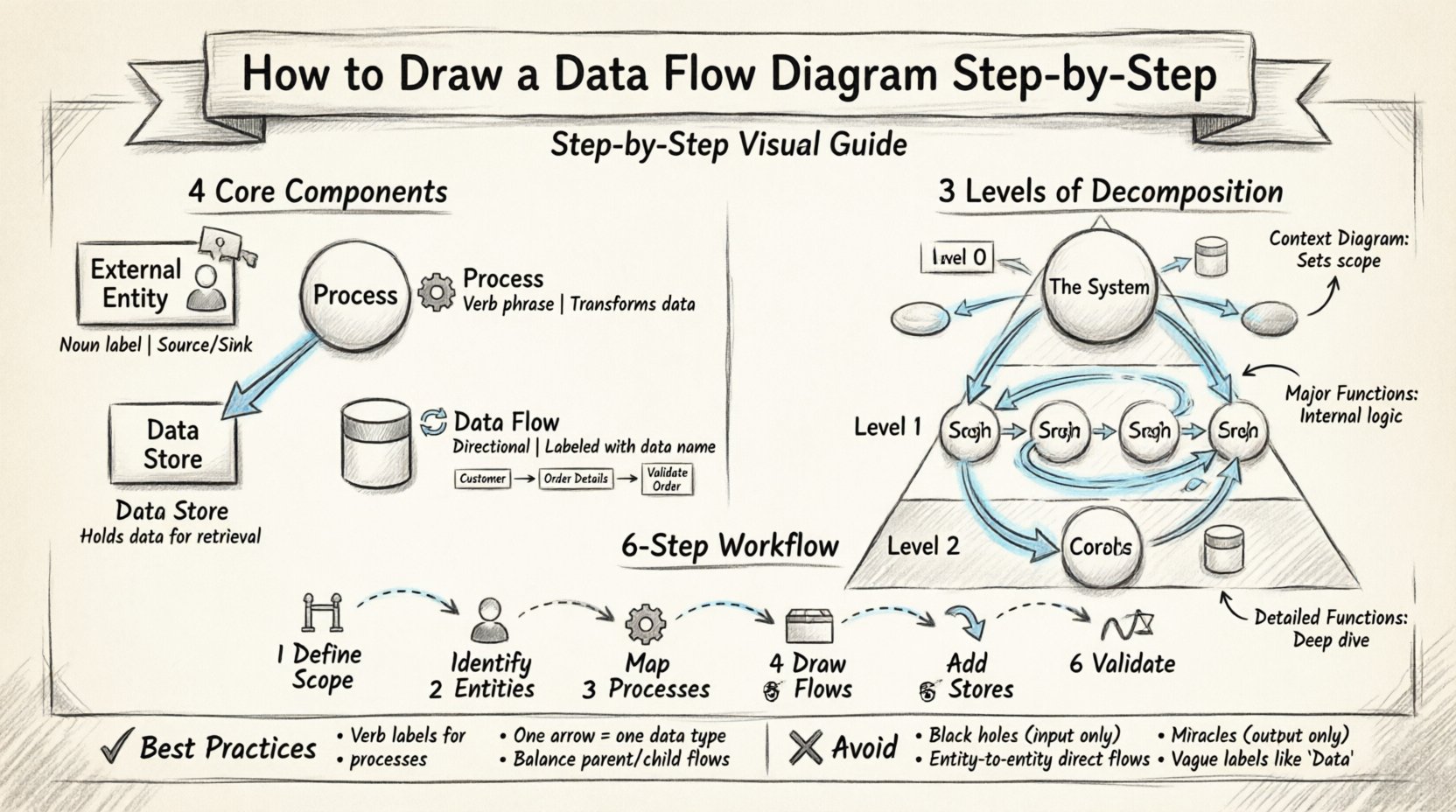
🛠️ 四つの基本構成要素
完全なDFDは四つの主要な記号に依存します。描かれるすべての要素は、これらのカテゴリのいずれかに属する必要があります。他の形状を使用すると、曖昧さが生じます。標準的な記号法は、一般的にユーデンとデマーコの方法またはゲインとサーソンの方法のどちらかに従います。これらのスタイル間で記号にわずかな違いがあるものの、根本的な論理は同一です。
1. 外部エンティティ 👤
外部エンティティは、システム境界外のデータの発生源または到着地を表します。これらはシステムとやり取りする主体です。人、組織、または他のシステムが含まれます。
- 発生源: エンティティがシステムに入力データを提供する(例:顧客が注文を出す)。
- 到着地: エンティティがシステムからの出力データを受け取る(例:税務当局が報告書を受け取る)。
図では、これらは通常長方形または正方形で表されます。役割を示す名詞句でラベル付けされます。
2. プロセス ⚙️
プロセスは、入力データを出力データに変換する行動を表します。これらは図の核となる部分です。プロセスは常に少なくとも1つの入力と1つの出力を備えている必要があります。
- 変換: データを一つの形式から別の形式に変更する(例:売上データの原データを要約レポートに変換する)。
- ラベル付け: プロセスは通常、動詞句でラベル付けされます(例:「税金を計算する」、「ユーザーを検証する」)。
記号の標準によって、円、角丸長方形、または泡の形で描かれることが多いです。
3. データストア 📂
データストアは、情報が後で使用するために保存される場所を表します。これは物理的なデータベースファイルではなく、論理的なリポジトリです。データは保存のためにストアに入り、参照のために出力されます。
- オープン vs. クローズド: データはストアから読み取られ、書き込まれる可能性があります。
- 永続性: 作成したプロセスが終了しても、データは利用可能である。
一般的な記号には、ファイルやデータベースを表す開放された長方形や円筒がある。
4. データフロー 🔄
データフローは、エンティティ、プロセス、ストア間でのデータの移動を示す。方向性を持つ矢印である。
- 方向: 矢印はデータの移動方向を示す。
- 内容: 各フローは、送信中の特定のデータ(例:「注文詳細」、「支払い確認」)でラベル付けされなければならない。
- 一貫性: プロセスを経由せずに、2つの外部エンティティ間でデータが流れることはできない。
| 構成要素 | 記号の形状 | ラベルの種類 | 機能 |
|---|---|---|---|
| 外部エンティティ | 長方形/正方形 | 名詞 | 発信元または受信先 |
| プロセス | 円/角丸ボックス | 動詞句 | データを変換する |
| データストア | 開放された長方形/円筒 | 名詞 | データを保持する |
| データフロー | 矢印 | データ名 | データを移動 |
📈 分解の段階
複雑なシステムは1つの視点では理解できません。DFDは階層的です。高レベルの概要から始め、段階的にプロセスをより詳細に分解していきます。これを分解と呼びます。
レベル0:コンテキスト図 🌍
コンテキスト図は最も高い段階です。システム全体を1つのプロセスのバブルとして示します。システムが外部世界とどのように相互作用するかを示します。
- 中心には1つのプロセスだけが描かれています。
- 外部エンティティがプロセスを囲んでいます。
- データフローがエンティティと単一のプロセスを結びつけています。
- この段階ではデータストアは表示されません。
この図は範囲を設定します。プロジェクトの境界を定義します。
レベル1:主要プロセス 🔍
レベル1では、コンテキスト図の単一プロセスが主要なサブプロセスに拡張されます。ここから内部ロジックが現れ始めます。
- 単一のプロセスが3~7つの主要プロセスのクラスタに変わります。
- ここではデータストアが導入されます。
- 外部エンティティはレベル0と同じままです。
- フローはレベル0の入力と出力とバランスを取らなければなりません。
レベル2:詳細な機能 🔬
レベル2では、レベル1の特定のプロセスをさらに分解します。詳細な説明が必要な複雑な操作に使用されます。
- 前の段階の1つのプロセスに焦点を当てます。
- 詳細なロジックとサブステップを示します。
- レベル1のプロセスが1つのビューで管理するのに複雑すぎる場合に使用されます。
| 段階 | 焦点 | プロセス | データストア |
|---|---|---|---|
| レベル0 | システム範囲 | 1(システム) | なし |
| レベル1 | 主要な機能 | 3~7 | はい |
| レベル2 | 具体的な詳細 | レベル1に依存 | はい |
✍️ ステップバイステップの描画手法
DFDを作成するには構造的なアプローチが必要です。これらのステップに従うことで、ドキュメント全体に一貫性と明確性が保たれます。
ステップ1:範囲と境界を定義する 🚧
まず、システムの内部と外部にあるものを特定します。この判断が外部エンティティの配置を決定します。境界の外にあるすべてが外部エンティティです。境界の内側にあるすべてがプロセス、ストア、またはフローです。ハードウェアやコードなどの実装詳細はここに含めないでください。
ステップ2:外部エンティティを特定する 👥
システムとやり取りするすべての当事者をリストアップします。次のような質問をします:
- 誰がシステムに情報を送信しますか?
- 誰がシステムからのレポートや出力を受信しますか?
- このシステムとデータをやり取りする他のシステムはありますか?
これらのエンティティをワークスペースの周囲に描きます。明確で説明的な名前を使用してください。
ステップ3:主要なプロセスを決定する ⚙️
入力を出力に変換するためにシステムが実行すべき主要な機能を特定します。関連する活動をグループ化します。たとえば、「注文管理」は「注文の検証」と「在庫の更新」をサブプロセスとして含む主要プロセスである可能性があります。
- プロセスの数を管理可能な範囲に保ちます(レベル1では理想的には7未満)。
- すべてのプロセスに明確な目的があることを確認します。
- プロセスには動詞をラベルとして付けます(例:「支払い処理」)
ステップ4:データフローをマッピングする 🔄
エンティティとプロセス、およびプロセス同士をつなぐ矢印を描きます。すべての矢印には、データを説明するラベルが必要です。
- データの流れが論理的であるか確認します。
- プロセスを経由せずにシステム境界を越えるフローがないことを確認します。
- フローには特定のデータパケット(例:「顧客ID」、単に「データ」とはしない)をラベル付けします。
ステップ5:データストアを追加する 📂
情報が保管される場所を特定します。後でデータが必要な場合は、必ずストアに格納する必要があります。
- データを読み書きするプロセスとストアを接続します。
- データを保存するには、ストアにデータが流れ込むようにしてください。
- データを使用するには、ストアからデータが流れ出すようにしてください。
ステップ6:検証とバランス調整 ⚖️
これは最も重要な技術的ステップです。バランス調整により、親プロセスの入力と出力が、その子図(次のレベル)の入力と出力と一致していることを保証します。
- レベル0に「注文」の入力がある場合、レベル1でもメインプロセスに入る「注文」を示す必要があります。
- レベル1でプロセスが分割される場合、サブプロセスは親プロセスと同じデータ入力と出力を処理しなければなりません。
- 孤立したプロセス(データフローのないプロセス)がないか確認してください。
- 孤立したデータストア(入出力のないストア)がないか確認してください。
🧠 最良の実践とルール
厳格なルールを遵守することで混乱を防ぎます。ルールから逸脱すると、システム論理の誤解を招くことがあります。
1. 名前付け規則 🏷️
一貫性が重要です。すべての要素に標準的な名前付け規則を使用してください。
- エンティティ:複数形の名詞(例:「顧客」、「仕入先」)。
- プロセス:動詞フレーズ(例:「在庫を更新」)。
- ストア:名詞(例:「在庫ファイル」)。
- フロー:データ名(例:「在庫更新」)。
2. コントロールロジックを避ける 🚫
DFDはフローチャートではありません。コントロールフローを表す決定のダイアモンドやループを含めないでください。決定がデータフローに影響する場合、論理条件ではなくデータの内容に基づいてフローを異なるパスに分けることで表現してください。
3. 1本の矢印、1つのデータパケット
複数のデータタイプを1本の矢印にまとめてはいけません。プロセスが「注文データ」と「支払いデータ」の両方を送信する場合、2本の別々の矢印を描いてください。
4. エンティティ間の直接的なフローは禁止
データはシステムを経由せずに、外部エンティティから別の外部エンティティへ直接移動することはできません。もし直接移動する場合、システムがバイパスされているか、図の範囲が誤っていることを意味します。
5. ブラックホールとミラクルを避ける
- ブラックホール:入力はあるが出力がないプロセス。データが消える。これは不可能です。
- ミラクル:出力はあるが入力がないプロセス。データがどこからともなく出現する。これは不可能です。
⚠️ 避けるべき一般的なミス
経験豊富なアナリストですらミスを犯します。一般的な落とし穴に気づいておくことで、レビュー時に時間を節約できます。
ミス1:レベルの混同
レベル0とレベル1の詳細を同じページに組み合わせると、混雑が生じます。各レベルを別々に保つことで、明確さを維持できます。
ミス2:流れの方向が一貫していない
矢印が正しい方向を向いていることを確認してください。プロセスがストアにデータを書き込んでいるのに、ストアからプロセスへ矢印を描くという誤りがよくあります。
ミス3:曖昧なラベル
「情報」や「データ」、「詳細」のようなラベルは避けましょう。具体的にしましょう。「顧客の詳細」の方が良いです。「データ」という表現は分析には役立ちません。
ミス4:データストアを無視する
データストアをスキップすると、モデルが不完全になります。後でデータが使われる場合は、必ず保存しなければなりません。ストアを含めないということは、状態を持たないシステムであることを意味し、複雑なアプリケーションではほとんど正確ではありません。
🔍 レベルの高い考慮事項
システムが大きくなるにつれて、DFDの保守がより厳格な管理を必要とします。大規模なプロジェクトでは以下の点を検討しましょう。
物理的DFDと論理的DFD
- 論理的DFD:ビジネス要件に焦点を当てる。紙のファイルとデータベースの違いのような技術的実装の詳細は無視する。
- 物理的DFD:実際の実装を反映する。ハードウェア、ソフトウェア、ファイルの種類を明確に指定する。
ベストプラクティスとして、まず要件を合意するために論理的DFDを作成し、開発用に物理的DFDを導出することです。
並行処理とタイミング
標準的なDFDは時間や並行処理を示しません。何が起こるかを示すだけで、いつ起こるかは示しません。タイミングが重要なシステムでは、状態遷移図などの他のモデリング手法をDFDと一緒に使用する必要がある場合があります。
セキュリティとアクセス制御
DFDはセキュリティプロトコルを明示的に示しませんが、データフローは機密情報の存在を示すべきです。「パスワード」や「クレジットカード番号」を含むフローは特に注目すべきです。これにより、セキュリティアーキテクトは暗号化が必要な場所を特定できます。
📝 ワークフローの要約
データフローダイアグラムを作成することは、システム思考の厳格な演習です。複雑なシステムを扱いやすい部分に分解しつつ、データの移動の整合性を保つ必要があります。このプロセスは、コンテキスト図のマクロ視点から、詳細なプロセスのマイクロ視点へと移行します。
成功の鍵は以下の通りです:
- 境界の明確な識別。
- コンポーネントの一貫したラベル付け。
- バランスルールへの厳格な従い。
- ステークホルダーとの検証。
これらのステップを踏み、一般的な落とし穴を避けることで、システム開発の信頼できる設計図を作成できます。この文書は、データベース設計、ソフトウェアアーキテクチャ、プロセス改善の基盤となります。あらゆる組織化されたシステムにおける情報の流れを理解するための、永続的なツールとして機能し続けます。