











データを管理するシステムを設計することは複雑な作業である。プロジェクトが小さなスクリプトから企業向けのプラットフォームへと拡大するにつれて、アーキテクチャ内を情報がどのように移動するかを説明するドキュメントも進化しなければならない。データフローダイアグラム(DFD)は、こうしたシステムのアーキテクチャ設計図として機能する。これらはプロセス、データストア、外部エンティティ間のデータの移動をマッピングする。しかし、単純なアプリケーションに適していた図は、大規模プロジェクトでは重みに耐えられず崩れてしまうことがある。DFDのスケーリングには、階層構造、分解、保守の面で厳格なアプローチが必要となる。このガイドでは、複雑性が増す中でデータフローのドキュメントを明確で正確かつ有用な状態に保つために必要な戦略を検討する。
小規模な範囲から大規模な環境への移行は、単にボックスや矢印を追加するだけでは解決できない課題をもたらす。構造的なメソドロジーがなければ、図は読み取り不可能な接続の網目になってしまう。これにより、ステークホルダー、開発者、アーキテクトの間で混乱が生じる。明確さを保つためには、チームが組織化のための特定のパターンを採用しなければならない。スケーリングのメカニズムについて、初期のコンテキストレベルから詳細なプロセス分解まで検討する。また、木を失って森が見えなくなることなく、データストアや外部境界を管理する方法についても取り上げる。
DFDの階層構造を理解する 📚
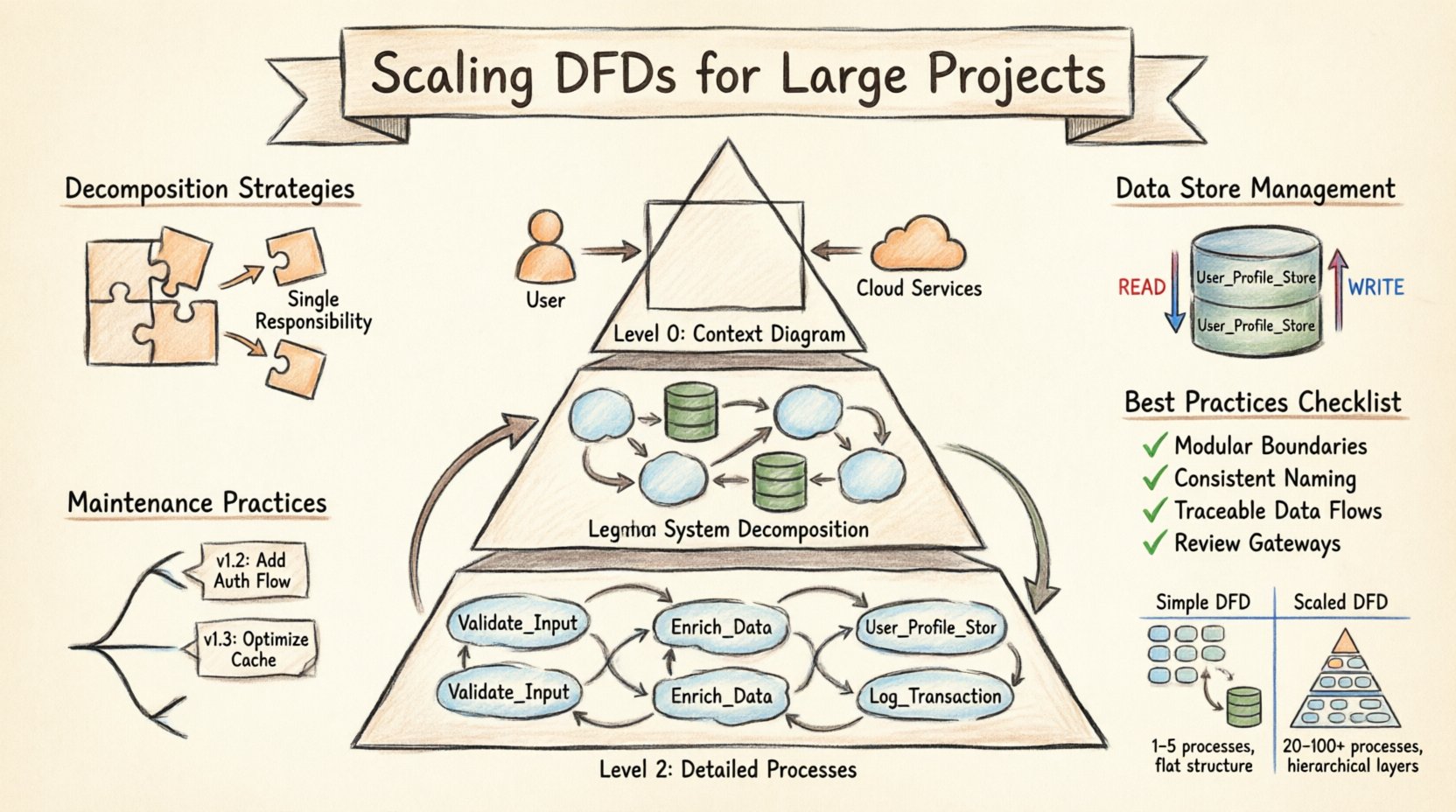
スケーリングの基盤は、図自体の階層構造にある。単一のフラットな図は、大規模なシステムではほとんど十分ではない。代わりに、複数のレベルを用いるアプローチにより、ステークホルダーはシステムを異なる詳細度で見ることができる。この方法は、しばしばレベル0、レベル1、レベル2の構造と呼ばれる。各レベルは特定の対象者と目的に応じて機能する。
- レベル0(コンテキスト図): これは最も高いレベルの視点である。システム全体を単一のプロセスとして示す。ユーザー、サードパーティサービス、ハードウェアなどの外部エンティティとシステムを接続する。ここでの目的は、システムの境界と主要な入力・出力を定義することである。内部プロセスやデータストアは含めないべきである。
- レベル1(システムの分解): このレベルでは、レベル0の単一プロセスを主要なサブプロセスに分解する。データストアを導入し、主要な機能領域間でのデータの流れを示す。ここでは、コアアーキテクチャが可視化される。通常、システムアーキテクトやシニア開発者が使用する。
- レベル2(詳細プロセス): レベル1の各主要プロセスが、別々の図に展開される。このレベルでは、論理、特定のデータ変換、データストアとの相互作用を詳細に記述する。関数の具体的なメカニズムを理解する必要がある実装者やテスト担当者が使用する。
スケーリングを行う際には、これらのレベル間の関係を厳密に維持しなければならない。レベル0の図にあるすべての入力・出力は、レベル1で説明されなければならない。レベル1のプロセスから出るすべてのデータフローは、対応するレベル2の図で説明されなければならない。この一貫性により、情報の損失を防ぎ、トレーサビリティを確保できる。下位レベルの図に存在するデータフローが上位レベルの図にない場合、それは解決すべき不整合を示している。
複雑性への分解戦略 🔨
分解とは、複雑なプロセスをより小さな、管理可能なコンポーネントに分割する行為である。大規模プロジェクトでは、これは単なる簡略化以上のものであり、認知負荷を管理することにある。多くの異なる機能を処理するプロセスは、理解のボトルネックとなる。効果的な分解は、図が有用な状態を保つために特定のルールに従う必要がある。
- プロセスごとに1つの機能: 各プロセスのバブルまたはボックスは、データの単一で明確な変換を表すべきである。データ検証とデータ保存の両方を処理するプロセスは、分割すべきである。この分離により、各コンポーネントの責任が明確になる。
- 一貫した粒度: レベルごとに詳細度は異なるが、単一のレベル内での粒度は一貫しているべきである。あるプロセスが非常に詳細である場合、隣接するプロセスは曖昧な要約であってはならない。このバランスが、図が不均一で混乱しにくくする。
- 論理的なグループ化: 関連するプロセスを視覚的にまたは命名規則によってまとめる。これにより、読者は「認証」、「請求」、「レポート」などの機能領域を識別しやすくなる。論理的なグループ化により、ページ全体にわたって線を追跡する必要が減る。
- レベル間の漏れを避ける: 上位レベルの図に、下位レベルに属する詳細を導入してはならない。逆に、システムの状態を理解するために不可欠な重要なデータストアを、レベル1の図から省略してはならない。
スケーリングを行う際には、単一のカテゴリにうまく収まらないプロセスに遭遇することは珍しくない。このような場合、プロセスは並列の流れに分割するか、専用のインターフェース層を通じて処理する必要がある。目的は、フローを線形かつ論理的に保つことである。あるプロセスが5つの異なるソースからデータを必要とし、3つの異なる宛先に結果を送信する場合、それは単一のボックスではあまりにも複雑である可能性が高い。中間ステップに分解することで、処理の順序が明確になる。
スケーリング時のデータストアの管理 🗄️
データストアは、システムの永続的な状態を表す。小規模なプロジェクトでは、単一のデータベースがアプリケーション全体をカバーする場合がある。大規模プロジェクトでは、データは複数のシステム、スキーマ、サービスに分散される。DFD上でこれらのストアを正確にマッピングすることは、データの整合性やアクセスパターンを理解するために不可欠である。
- 明確な命名: データストアを単に「Database」とだけラベル付けしてはならない。代わりに「User_Profile_Store」や「Transaction_Log」など、具体的な名前を使用する。この明確さにより、開発者はどのシステムがどのデータを保持しているかを識別しやすくなる。
- 読み込みと書き込みのフロー: データが読み込まれる場所と書き込まれる場所を明示する。DFDは伝統的に方向性を示さないデータフローを描くが、スケーリングでは状態変化の明確さが求められる。プロセスがストアを更新するのか、単に照会するのかを示すために、明確な記号や凡例を使用する。
- 共有データストア: 大規模なシステムでは、プロセス間でデータストアを共有することがよくあります。図がどのプロセスがどのストアにアクセスできるかを正確に反映していることを確認してください。これにより、並行処理の問題やセキュリティ上の脆弱性を特定しやすくなります。
- データストアの関係: データが1つのストアから別のストアへ流れている場合は、それを明示的に表示してください。これはレプリケーションプロセス、ETLジョブ、または同期ルーチンを示している可能性があります。これらのデータフローはしばしば見過ごされがちですが、システムの信頼性にとって不可欠です。
データストアの数が増えるにつれて、図がごちゃごちゃになりがちです。これを緩和するため、グループ化の手法を検討してください。関連するデータストアを、特定のサブシステムを表す境界で囲みます。これにより視覚的なノイズを減らしつつ、論理的なつながりを維持できます。ただし、これらのグループ間のデータフローを隠してはいけません。全体像を理解するために、接続部分は明確に見えるようにしなければなりません。
外部エンティティの境界 🌐
外部エンティティは、システム境界外のデータの発信元および受信先を表します。人間のユーザー、他のソフトウェアシステム、レガシーメインフレーム、または規制機関などが該当します。大規模なプロジェクトでは、外部エンティティの数が急増する可能性があります。これらの境界を適切に管理することは、プロジェクトの範囲を明確にするために不可欠です。
- 明確なインターフェースを定義する: 外部エンティティとプロセスの間のすべての接続は、インターフェースを表します。これらの相互作用の想定されるフォーマットとプロトコルを文書化してください。これにより、サードパーティのシステムとの統合時に曖昧さが生じにくくなります。
- 類似したエンティティを統合する: 複数のユーザーが同じ機能を実行している場合、役割の違いを注記付きで「顧客」などの単一の汎用エンティティとして表現してください。これにより冗長性を減らしつつ、機能は失われません。
- セキュリティ上の影響: 外部エンティティはしばしばセキュリティ境界を表します。外部エンティティからシステムへデータが流れ込む場合、認証や暗号化が必要になることがあります。DFDは、これらのセキュリティ要件をテキスト内または凡例を通じて明記することが望ましいです。
- レガシーシステム: 大規模なプロジェクトでは、しばしばレガシーシステムとやり取りします。これらのエンティティは厳格なデータフォーマットを持つことがあります。新しいシステムが既存のワークフローを壊さずに正しくデータを処理できるように、これらのやり取りを慎重にマッピングしてください。
スケーリングする際には、小さな外部エンティティを無視したくなるものですが、小さな入力でも重大な下流への影響を及ぼすことがあります。小さなエンティティがデータを送信する方法が変更されると、システム全体に波及する可能性があります。したがって、すべてのエンティティはコンテキスト図に反映され、分解レベルを通じて追跡されるべきです。
保守とバージョン管理 🔄
DFDは動的な文書です。大規模なプロジェクトでは要件が頻繁に変化します。プロセスが追加され、データストアが統合され、外部インターフェースが廃止されることがあります。堅固な保守戦略がなければ、図はすぐに古くなり、ドキュメントとコードの間にズレが生じます。
- バージョン管理: 図にバージョン番号を付与してください。これによりチームは変更履歴を時系列で追跡できます。バグが報告された場合、コードが書かれた時点での図の特定バージョンを参照できます。
- 変更ログ: バージョン間で何が変更されたかを記述する別々のログを維持してください。日付、作成者、変更の理由を含めてください。これにより、将来の開発者がなぜその決定がなされたのかを思い出せない場合でも、背景が把握できます。
- レビュー周期: DFDの定期的なレビューをスケジュールしてください。これは主要なリリースサイクルと重ねることが望ましいです。レビュー中に、図が現在の実装と一致しているかを確認してください。不一致が見つかった場合は、直ちに更新してください。
- アクセス制御: 図の編集は、承認された人員に限ることを確保してください。制御のない編集は、衝突や混乱を招く可能性があります。誰がいつ変更を行ったかを追跡できるシステムを使用してください。
保守は開発に比べてしばしば軽視されがちです。しかし、古くなった図はまったく図がないよりも危険です。誤った安心感を生み出します。チームは現実と一致しないドキュメントに依存する可能性があります。DFDをコードと同様に扱い、同じバージョン管理とレビュープロセスを適用することで、正確性を保証できます。
比較:スケーリングされたDFDとシンプルなDFD 📊
シンプルなDFDとスケーリングされたDFDの違いを理解することは、移行に備える上でチームにとって重要です。以下の表は、構造、複雑さ、管理における主な違いを示しています。
| 機能 | シンプルなDFD | スケーリングされたDFD |
|---|---|---|
| プロセスの数 | 1~5 | 20~100以上 |
| レベル | 1(フラット) | 3~5(階層的) |
| 使用するツール | 鉛筆と紙 | 専用の図解ソフトウェア |
| バージョン管理 | 手動 | 自動化システム |
| レビュー頻度 | 納品時 | スプリント/リリースごと |
| データストアの詳細 | 汎用的 | 具体的で名前付き |
| 外部エンティティ | 最小限 | 包括的で分類済み |
ドキュメント品質のためのベストプラクティス ✅
DFDが価値ある資産のまま保たれるようにするため、これらのベストプラクティスに従ってください。これらのガイドラインは、明確さ、一貫性、および使いやすさに焦点を当てています。
- 一貫した命名規則:プロセス、データフロー、ストアの命名には標準的なフォーマットを使用してください。たとえば、プロセスには「動詞+名詞」を使用してください(例:「税金を計算する」)。これにより、図の読みやすさと検索性が向上します。
- 線の交差を最小限に抑える:線同士が交差する数を減らすように図を配置してください。これにより視覚的な流れが改善され、データパスを追跡するための認知的負荷が軽減されます。
- 凡例とキーを使用する:セキュリティ、データ型、または外部システムに特別な記号を使用する場合は、凡例を提供してください。読者がすべての記号の意味を知っていると仮定しないでください。
- 仕様へのリンク:可能な限り、図を詳細な要件文書やコードリポジトリにリンクしてください。これにより、高レベルの視点と実装の詳細との間の橋渡しが可能になります。
- 常に最新の状態を保つ:完璧に見えるようにするよりも、図の正確性を最優先してください。わずかに乱雑でも正確な図は、洗練されていても古くなっている図よりも有用です。
他のドキュメントとの統合 📝
DFDは孤立して存在するものではありません。技術文書の広いエコシステムの一部です。その価値を最大化するためには、他のアーティファクトと統合する必要があります。
- データベーススキーマ:DFD内のデータストアは、データベーススキーマに直接対応する必要があります。これにより、物理的実装が論理設計と一致することを保証します。
- API仕様:外部エンティティとプロセスの間のフローは、しばしばAPIエンドポイントに対応します。これらの文書を相互参照することで、統合ポイントの検証が可能になります。
- セキュリティポリシー:機密情報を含むデータフローは、セキュリティポリシーと相互参照する必要があります。これにより、暗号化やアクセス制御の要件が満たされていることを保証します。
- テストケース:テストケースはデータフローから導出されるべきです。各フローはテストの潜在的な経路を表しています。これにより、システムの論理に対する包括的なカバレッジが確保されます。
避けるべき一般的な落とし穴 ⚠️
最高の意図を持っていても、DFDをスケーリングする際にチームは誤りを犯すことがあります。これらの落とし穴への意識は、一般的な罠を避けるのに役立ちます。
- 過剰設計:レベルに不適切なほど詳細な図を作成しないでください。レベル1の図にはレベル2のプロセスの論理を含んではいけません。適切な抽象化レベルを保ってください。
- 制御フローを無視する:DFDはデータに焦点を当てる一方で、複雑なシステムでは制御信号(「開始」、「停止」、「エラー」など)が必要な場合があります。これらをデータフローと明確に区別してください。
- 線形性を仮定する:システムはほとんど線形ではありません。ループ、フィードバック機構、非同期イベントは一般的です。図を読みにくくしても、これらを正確に表現してください。
- 標準化の欠如:チームメンバーが異なるスタイルで図を描くと、全体のドキュメントが断片化します。早期にスタイルガイドを策定し、それを徹底して適用してください。
スケーラビリティに関する結論 🏗️
データフローダイアグラムをスケーリングすることは、堅牢で大規模なシステムを構築するための必須の分野です。単にボックスを増やすだけではなく、階層、分解、保守の構造化されたアプローチが求められます。このガイドで提示された戦略に従うことで、開発を支援するが負担にならないドキュメントを作成できます。目標は明確さです。図が明確であれば、システムは理解しやすく、保守・拡張も容易になります。このドキュメントへの投資は、エラーの削減と新メンバーの早期習得という恩恵をもたらします。
図は技術的アーティファクトだけでなく、コミュニケーションのツールであることを思い出してください。ビジネス要件と技術的実装の間のギャップを埋めます。システムが成長するにつれて、ドキュメントも成長しなければなりません。定期的なレビューと厳格なバージョン管理により、プロジェクトのライフサイクルを通じてDFDが信頼できる真実の源として機能します。適切なアプローチを取れば、DFDのスケーリングは混沌とした作業ではなく、管理可能なタスクになります。