











Проектирование систем, управляющих данными, — сложная задача. По мере роста проектов от небольших скриптов до платформ корпоративного уровня документация, описывающая движение информации в архитектуре, должна эволюционировать. Диаграммы потоков данных (DFD) служат архитектурными чертежами для этих систем. Они отображают перемещение данных между процессами, хранилищами данных и внешними сущностями. Однако диаграмма, работающая для простого приложения, часто не выдерживает нагрузки крупномасштабного проекта. Масштабирование DFD требует дисциплинированного подхода к иерархии, декомпозиции и поддержке. В этом руководстве рассматриваются стратегии, необходимые для сохранения ясности, точности и полезности документации по потокам данных по мере роста сложности.
Переход от небольшого масштаба к крупномасштабной среде порождает вызовы, которые нельзя решить просто добавлением большего количества блоков и стрелок. Без структурированного подхода диаграммы превращаются в непонятные сети соединений. Это приводит к путанице среди заинтересованных сторон, разработчиков и архитекторов. Чтобы сохранить ясность, команды должны внедрять конкретные шаблоны организации. Мы рассмотрим механизмы масштабирования — от начального уровня контекста до детального разбора процессов. Также мы обсудим, как управлять хранилищами данных и внешними границами, не теряя общей картины.
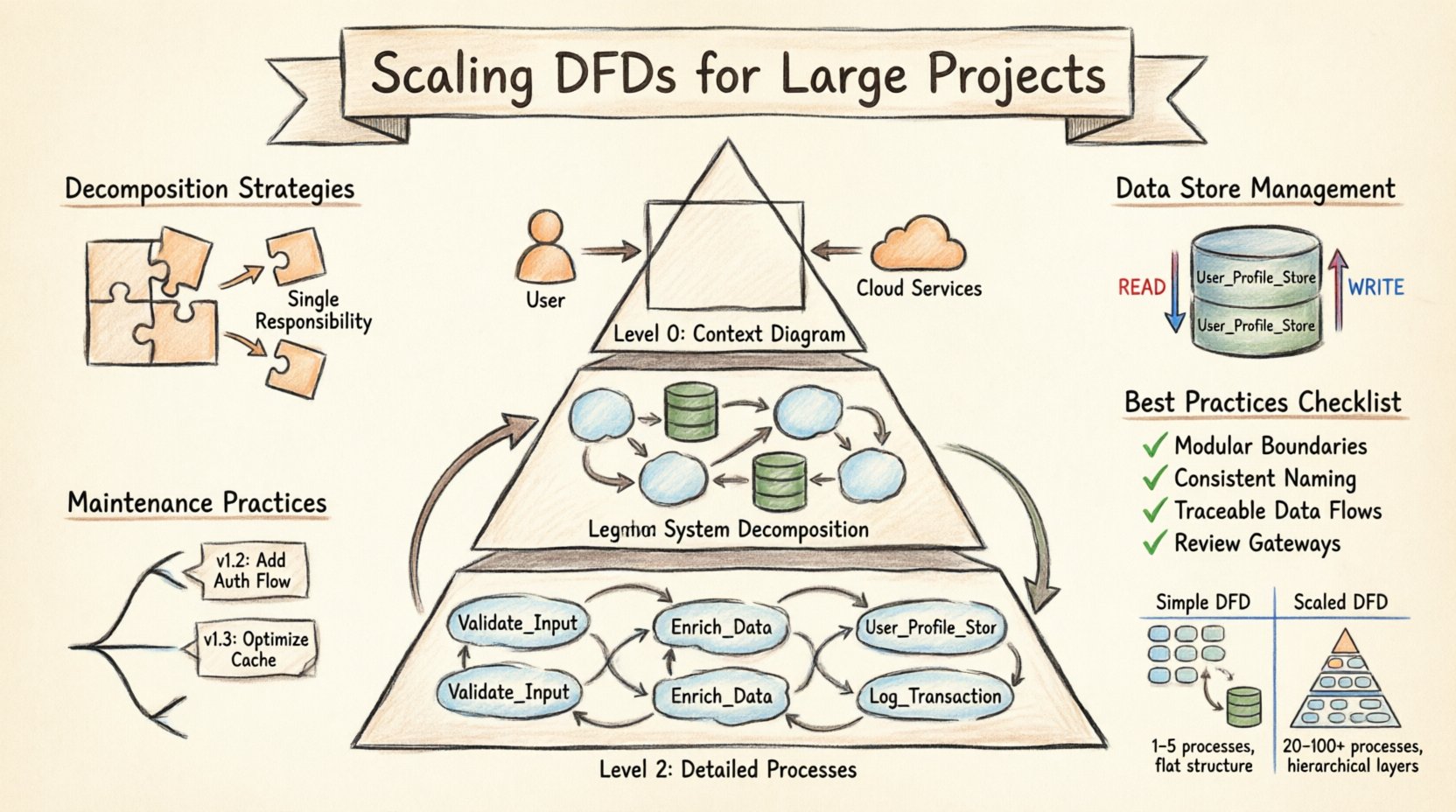
Понимание иерархии DFD 📚
Основа масштабирования заключается в иерархической структуре самой диаграммы. Одна плоская диаграмма редко достаточна для крупных систем. Вместо этого многоуровневый подход позволяет заинтересованным сторонам рассматривать систему на разных уровнях детализации. Этот метод часто называют структурой Level 0, Level 1, Level 2. Каждый уровень предназначен для определённой аудитории и выполняет свою задачу.
- Уровень 0 (диаграмма контекста): Это самый высокий уровень представления. Он показывает всю систему как один процесс. Он соединяет систему с внешними сущностями, такими как пользователи, сторонние сервисы или оборудование. Цель здесь — определить границы системы и основные входы и выходы. Она не должна содержать внутренние процессы или хранилища данных.
- Уровень 1 (декомпозиция системы): На этом уровне единственный процесс уровня 0 разбивается на основные подпроцессы. Вводятся хранилища данных и показывается, как данные перемещаются между основными функциональными областями. Именно здесь становится видимой основная архитектура. Обычно её используют архитекторы систем и старшие разработчики.
- Уровень 2 (детальные процессы): Каждый основной процесс уровня 1 расширяется в отдельную диаграмму. На этом уровне детализируются логика, конкретные преобразования данных и взаимодействие с хранилищами данных. Используется разработчиками и тестировщиками, которым нужно понять конкретные механизмы функции.
При масштабировании отношения между этими уровнями должны строго соблюдаться. Каждый вход и выход на диаграмме уровня 0 должны быть учтены на уровне 1. Каждый поток данных, выходящий из процесса уровня 1, должен быть объяснён на соответствующей диаграмме уровня 2. Такая согласованность предотвращает потерю информации и обеспечивает отслеживаемость. Если поток данных появляется на диаграмме нижнего уровня, но отсутствует на более высоком, это указывает на расхождение, которое необходимо устранить.
Стратегии декомпозиции для сложности 🔨
Декомпозиция — это процесс разбиения сложных процессов на более мелкие, управляемые компоненты. В крупномасштабных проектах это не просто упрощение, а управление когнитивной нагрузкой. Процесс, выполняющий слишком много различных функций, становится узким местом в понимании. Эффективная декомпозиция следует определённым правилам, чтобы диаграмма оставалась полезной.
- Одна функция на процесс: Каждый процесс (область или блок) должен представлять одну, чётко определённую трансформацию данных. Если процесс выполняет как валидацию данных, так и их хранение, он должен быть разделён. Такое разделение уточняет ответственность каждого компонента.
- Согласованная детализация: Хотя уровни различаются по степени детализации, детализация на одном уровне должна быть одинаковой. Если один процесс чрезвычайно детализирован, соседние процессы не должны быть расплывчатыми обобщениями. Такое равновесие предотвращает неравномерность и путаницу на диаграмме.
- Логическая группировка: Объединяйте связанные процессы визуально или по соглашениям по именованию. Это помогает читателю определить функциональные области, такие как «Аутентификация», «Счета» или «Отчетность». Логическая группировка уменьшает необходимость отслеживания линий по всей странице.
- Избегание перетекания между уровнями: Не вводите детали в диаграмму более высокого уровня, которые относятся к более низкому уровню. Напротив, не опускайте критически важные хранилища данных на диаграмме уровня 1, которые необходимы для понимания состояния системы.
При масштабировании часто возникают процессы, которые не укладываются в одну категорию. В таких случаях процесс может потребовать разделения на параллельные потоки или обработки через специальный слой интерфейса. Цель — сохранить линейность и логичность потока. Если процесс требует данных из пяти разных источников и отправляет результаты в три разных пункта назначения, он, скорее всего, слишком сложен для одного блока. Разбивка его на промежуточные шаги уточняет последовательность операций.
Управление хранилищами данных в масштабе 🗄️
Хранилища данных представляют собой постоянное состояние системы. В небольших проектах один база данных может обслуживать всю приложение. В крупномасштабных проектах данные распределены по нескольким системам, схемам и сервисам. Точное отображение этих хранилищ на DFD критически важно для понимания целостности данных и паттернов доступа.
- Чёткое наименование: Не называйте хранилище данных просто «База данных». Используйте конкретные имена, такие как «User_Profile_Store» или «Transaction_Log». Такая конкретность помогает разработчикам определить, в какой системе хранится какая информация.
- Потоки чтения и записи: Указывайте, где данные читаются, а где записываются. Хотя DFD традиционно показывают поток данных без указания направления, масштабирование требует чёткости в изменениях состояния. Используйте различные обозначения или легенды, чтобы показать, обновляет ли процесс хранилище или просто запрашивает данные.
- Общие хранилища данных: В крупных системах часто происходит совместное использование хранилищ данных между процессами. Убедитесь, что диаграмма отражает, какие процессы имеют доступ к каким хранилищам. Это помогает выявить потенциальные проблемы с одновременным доступом или уязвимости в безопасности.
- Связи между хранилищами данных: Если данные перемещаются от одного хранилища к другому, покажите это явно. Это может указывать на процесс репликации, задание ETL или процедуру синхронизации. Такие потоки часто игнорируются, но они крайне важны для надежности системы.
По мере роста количества хранилищ данных диаграмма может стать перегруженной. Чтобы смягчить это, рассмотрите использование техник группировки. Объедините связанные хранилища данных в границу, представляющую конкретную подсистему. Это уменьшит визуальную помеху, сохраняя логические связи. Однако будьте осторожны, чтобы не скрыть поток данных между этими группами. Соединения должны оставаться видимыми, чтобы обеспечить полное понимание картины.
Границы внешних сущностей 🌐
Внешние сущности представляют источники и пункты назначения данных за пределами границ системы. К ним могут относиться человеко-пользователи, другие программные системы, устаревшие мейнфреймы или регулирующие органы. В крупных проектах количество внешних сущностей может резко возрасти. Управление этими границами необходимо для определения масштаба проекта.
- Определите четкие интерфейсы: Каждое соединение между внешней сущностью и процессом представляет собой интерфейс. Документируйте ожидаемый формат и протокол взаимодействия. Это предотвращает неоднозначность при интеграции с сторонними системами.
- Объедините похожие сущности: Если несколько пользователей выполняют одну и ту же функцию, представьте их как одну общую сущность (например, «Клиент») с примечанием, объясняющим различия ролей. Это уменьшает избыточность без потери функциональности.
- Последствия для безопасности: Внешние сущности часто представляют границы безопасности. Данные, поступающие от внешней сущности в систему, могут требовать аутентификации или шифрования. Диаграмма потоков данных (DFD) должна, по возможности, отмечать эти требования к безопасности, либо в тексте, либо с помощью легенды.
- Устаревшие системы: Крупные проекты часто взаимодействуют с устаревшими системами. Эти сущности могут иметь жесткие форматы данных. Тщательно проработайте эти взаимодействия, чтобы убедиться, что новая система может корректно обрабатывать данные без нарушения существующих рабочих процессов.
При масштабировании соблазнительно игнорировать незначительные внешние сущности. Однако даже небольшие входные данные могут оказывать значительное влияние вниз по потоку. Изменение способа передачи данных незначительной сущностью может повлиять на всю систему. Поэтому все сущности должны быть учтены в контекстной диаграмме и прослежены на всех уровнях декомпозиции.
Обслуживание и контроль версий 🔄
DFD — это живой документ. В крупных проектах требования часто меняются. Добавляются процессы, объединяются хранилища данных, устаревают внешние интерфейсы. Без надежной стратегии обслуживания диаграмма быстро устаревает, что приводит к несоответствию между документацией и кодом.
- Версионирование: Назначьте номера версий диаграммам. Это позволяет командам отслеживать изменения во времени. Если сообщается об ошибке, можно сослаться на конкретную версию диаграммы, которая была актуальна на момент написания кода.
- Журналы изменений: Ведите отдельный журнал, описывающий, что изменилось между версиями. Включите дату, автора и причину изменения. Это обеспечит контекст для будущих разработчиков, которые могут не помнить, почему была принята та или иная решимость.
- Циклы обзора: Планируйте регулярные обзоры DFD. Они должны совпадать с основными циклами выпуска. В ходе этих обзоров убедитесь, что диаграммы соответствуют текущей реализации. Немедленно обновите их при обнаружении расхождений.
- Контроль доступа: Убедитесь, что только уполномоченный персонал может изменять диаграммы. Неуправляемые правки могут привести к конфликтам и путанице. Используйте систему, которая фиксирует, кто и когда вносил изменения.
Обслуживание часто игнорируется в пользу разработки. Однако устаревшие диаграммы опаснее, чем их отсутствие. Они создают ложное ощущение безопасности. Команды могут полагаться на документацию, которая не отражает реальность. Рассматривая DFD как код, подлежащий тем же процессам контроля версий и обзора, команды могут обеспечить точность.
Сравнение: масштабируемые DFD против простых DFD 📊
Понимание различий между простой DFD и масштабируемой DFD помогает командам подготовиться к переходу. В таблице ниже перечислены ключевые различия по структуре, сложности и управлению.
| Функция | Простая DFD | Масштабируемая DFD |
|---|---|---|
| Количество процессов | 1–5 | 20–100+ |
| Уровни | 1 (Плоская) | 3–5 (Иерархическая) |
| Используемые инструменты | Ручка и бумага | Специализированное программное обеспечение для диаграмм |
| Система контроля версий | Ручной | Автоматизированные системы |
| Частота обзора | Во время сдачи | На каждый спринт/релиз |
| Детализация хранилища данных | Общие | Конкретные и именованные |
| Внешние сущности | Минимальные | Полные и категоризированные |
Лучшие практики качества документации ✅
Чтобы обеспечить, что DFD остается ценным активом, придерживайтесь этих лучших практик. Эти рекомендации ориентированы на ясность, согласованность и удобство использования.
- Согласованные соглашения об именовании: Используйте стандартный формат для именования процессов, потоков данных и хранилищ. Например, используйте «глагол-существительное» для процессов (например, «Рассчитать налог»). Это делает диаграмму читаемой и поисковой.
- Минимизируйте пересечения линий: Расположите диаграмму так, чтобы минимизировать количество пересекающихся линий. Это улучшает визуальное течение и снижает когнитивные затраты, необходимые для отслеживания путей данных.
- Используйте легенды и ключи: Если используются специальные символы для безопасности, типов данных или внешних систем, предоставьте легенду. Не предполагайте, что читатель знает значение каждого символа.
- Ссылка на спецификации: По возможности, свяжите диаграмму с подробными документами требований или репозиториями кода. Это создает мост между общим видом и деталями реализации.
- Держите его в актуальном состоянии: Приоритет отдайте точности диаграммы, а не ее внешнему виду. Немного неаккуратная, но точная диаграмма полезнее, чем отполированная, но устаревшая.
Интеграция с другой документацией 📝
DFD не существует в вакууме. Он является частью более крупной экосистемы технической документации. Чтобы максимизировать его ценность, он должен интегрироваться с другими артефактами.
- Схема базы данных: Хранилища данных в DFD должны напрямую соответствовать схеме базы данных. Это гарантирует, что физическая реализация соответствует логическому проекту.
- Спецификации API: Потоки между внешними сущностями и процессами часто соответствуют конечным точкам API. Перекрестная ссылка на эти документы помогает проверить точки интеграции.
- Политики безопасности: Потоки данных, затрагивающие конфиденциальную информацию, должны быть перекрестно проверены с политиками безопасности. Это гарантирует соблюдение требований к шифрованию и контролю доступа.
- Тестовые случаи: Тестовые случаи должны быть основаны на потоках данных. Каждый поток представляет собой возможный путь для тестирования. Это обеспечивает полное покрытие логики системы.
Распространенные ошибки, которые следует избегать ⚠️
Даже при лучших намерениях команды могут допускать ошибки при масштабировании DFD. Осознание этих ошибок помогает избежать распространенных ловушек.
- Чрезмерная детализация: Не создавайте диаграмму, которая слишком детализирована для данного уровня. Диаграмма уровня 1 не должна содержать логику процесса уровня 2. Сохраняйте соответствующий уровень абстракции.
- Пренебрежение потоками управления: Хотя DFD фокусируется на данных, сигналы управления (например, «Старт», «Стоп», «Ошибка») часто необходимы в сложных системах. Четко различайте их от потоков данных.
- Предположение линейности: Системы редко бывают линейными. Циклы, механизмы обратной связи и асинхронные события — обычное дело. Точно отображайте их, даже если это усложняет чтение диаграммы.
- Отсутствие стандартизации: Если разные члены команды рисуют диаграммы в разных стилях, общая документация становится фрагментированной. Сразу установите руководство по стилю и строго его соблюдайте.
Заключение по масштабируемости 🏗️
Масштабирование диаграмм потоков данных — необходимая дисциплина для создания надежных, масштабных систем. Это требует больше, чем просто рисование дополнительных блоков; требуется структурированный подход к иерархии, декомпозиции и поддержке. Следуя стратегиям, описанным в этом руководстве, команды могут создавать документацию, которая поддерживает разработку, не становясь обузой. Цель — ясность. Когда диаграмма понятна, система легче понимается, поддерживается и расширяется. Такая инвестиция в документацию окупается меньшим количеством ошибок и более быстрой адаптацией новых членов команды.
Помните, что диаграмма — это инструмент коммуникации, а не просто технический артефакт. Она служит мостом между бизнес-требованиями и технической реализацией. По мере роста системы должна расти и документация. Регулярные проверки и строгий контроль версий гарантируют, что DFD остается надежным источником истины на протяжении всего жизненного цикла проекта. При правильном подходе масштабирование DFD превращается из хаотичного процесса в управляемую задачу.