











डेटा को प्रबंधित करने वाले प्रणालियों को डिज़ाइन करना एक जटिल कार्य है। जैसे-जैसे प्रोजेक्ट्स छोटे स्क्रिप्ट्स से एंटरप्राइज-ग्रेड प्लेटफॉर्म तक बढ़ते हैं, आर्किटेक्चर के माध्यम से जानकारी के आवागमन को वर्णित करने वाले दस्तावेज़ों को विकसित करने की आवश्यकता होती है। डेटा फ्लो डायग्राम्स (DFDs) इन प्रणालियों के लिए आर्किटेक्चरल ब्लूप्रिंट्स के रूप में कार्य करते हैं। वे प्रक्रियाओं, डेटा स्टोर्स और बाहरी एजेंसियों के बीच डेटा के आवागमन को मैप करते हैं। हालांकि, एक सरल एप्लिकेशन के लिए काम करने वाला डायग्राम अक्सर बड़े पैमाने के प्रोजेक्ट के भार के तले ढह जाता है। DFDs को स्केल करने के लिए जैसे हीरार्की, डिकॉम्पोजिशन और रखरखाव के लिए एक अनुशासित दृष्टिकोण की आवश्यकता होती है। यह गाइड जटिलता बढ़ने के साथ डेटा फ्लो दस्तावेज़ीकरण को स्पष्ट, सटीक और उपयोगी बनाए रखने के लिए आवश्यक रणनीतियों का अध्ययन करता है।
छोटे परिसर से बड़े पैमाने के वातावरण में संक्रमण के साथ चुनौतियाँ उत्पन्न होती हैं जिन्हें सिर्फ अधिक बॉक्स और तीर जोड़कर हल नहीं किया जा सकता। एक संरचित विधि के बिना, डायग्राम्स अपठनीय जाल के रूप में बन जाते हैं। इससे स्टेकहोल्डर्स, डेवलपर्स और आर्किटेक्ट्स में भ्रम उत्पन्न होता है। स्पष्टता बनाए रखने के लिए, टीमों को संगठन के लिए विशिष्ट पैटर्न अपनाने की आवश्यकता होती है। हम स्केलिंग के तकनीकी पहलुओं का अध्ययन करेंगे, जैसे प्रारंभिक संदर्भ स्तर से लेकर विस्तृत प्रक्रिया विभाजन तक। हम यह भी बताएंगे कि डेटा स्टोर्स और बाहरी सीमाओं को बिना वृक्षों के जंगल खोए बिना कैसे प्रबंधित किया जाए।
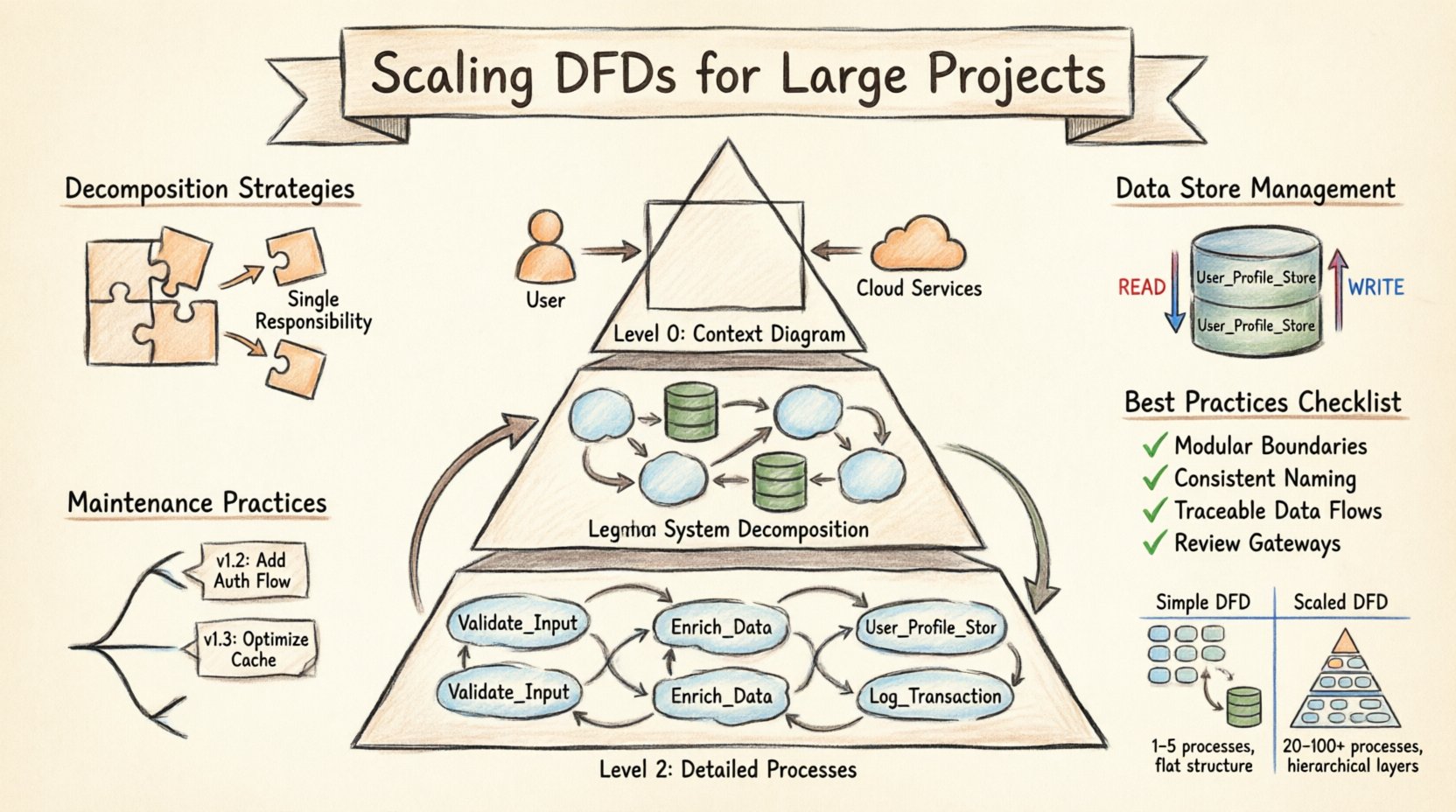
DFDs की हीरार्की को समझना 📚
स्केलिंग का आधार डायग्राम की हीरार्की संरचना में है। एकल, समतल डायग्राम बड़ी प्रणालियों के लिए अक्सर पर्याप्त नहीं होता है। इसके बजाय, बहु-स्तरीय दृष्टिकोण के द्वारा स्टेकहोल्डर्स को प्रणाली को विभिन्न विस्तारों में देखने की अनुमति मिलती है। इस विधि को अक्सर लेवल 0, लेवल 1, लेवल 2 संरचना के रूप में जाना जाता है। प्रत्येक स्तर एक विशिष्ट दर्शक और उद्देश्य के लिए कार्य करता है।
- लेवल 0 (संदर्भ डायग्राम): यह सबसे ऊंचा स्तर का दृश्य है। यह पूरी प्रणाली को एकल प्रक्रिया के रूप में दिखाता है। यह प्रणाली को बाहरी एजेंसियों, जैसे उपयोगकर्ता, तृतीय-पक्ष सेवाएं या हार्डवेयर से जोड़ता है। यहां लक्ष्य प्रणाली की सीमा और मुख्य इनपुट और आउटपुट को परिभाषित करना है। इसमें आंतरिक प्रक्रियाओं या डेटा स्टोर्स को शामिल नहीं करना चाहिए।
- लेवल 1 (प्रणाली विघटन): यह स्तर लेवल 0 की एकल प्रक्रिया को मुख्य उप-प्रक्रियाओं में बांटता है। यह डेटा स्टोर्स को पेश करता है और यह दिखाता है कि डेटा मुख्य कार्यात्मक क्षेत्रों के बीच कैसे बहता है। यहीं पर मूल आर्किटेक्चर दिखाई देता है। इसका उपयोग आमतौर पर सिस्टम आर्किटेक्ट्स और सीनियर डेवलपर्स द्वारा किया जाता है।
- लेवल 2 (विस्तृत प्रक्रियाएं): लेवल 1 से प्रत्येक मुख्य प्रक्रिया को अलग डायग्राम में विस्तारित किया जाता है। इस स्तर पर तर्क, विशिष्ट डेटा रूपांतरण और डेटा स्टोर्स के साथ बातचीत का विस्तार से वर्णन किया जाता है। इसका उपयोग उन लोगों द्वारा किया जाता है जो एक कार्य की विशिष्ट यांत्रिकी समझना चाहते हैं, जैसे इम्प्लीमेंटर्स और टेस्टर्स।
जब स्केलिंग की जाती है, तो इन स्तरों के बीच संबंध को कठोरता से बनाए रखना आवश्यक है। लेवल 0 डायग्राम पर प्रत्येक इनपुट और आउटपुट को लेवल 1 में ध्यान में रखना चाहिए। लेवल 1 प्रक्रिया से निकलने वाले प्रत्येक डेटा फ्लो को संबंधित लेवल 2 डायग्राम में स्पष्ट किया जाना चाहिए। यह सुसंगतता जानकारी के नुकसान को रोकती है और ट्रेसेबिलिटी सुनिश्चित करती है। यदि कोई डेटा फ्लो एक निम्न स्तर के डायग्राम में दिखाई देता है लेकिन उच्च स्तर के डायग्राम में नहीं दिखाई देता है, तो इसका मतलब है कि एक असंगति है जिसे निरस्त करने की आवश्यकता है।
जटिलता के लिए डिकॉम्पोजिशन रणनीतियाँ 🔨
डिकॉम्पोजिशन जटिल प्रक्रियाओं को छोटे, प्रबंधनीय घटकों में तोड़ने की क्रिया है। बड़े पैमाने के प्रोजेक्ट्स में, यह सिर्फ सरलीकरण के बारे में नहीं है; यह ज्ञानात्मक भार को प्रबंधित करने के बारे में है। एक प्रक्रिया जो बहुत सारे अलग-अलग कार्यों को संभालती है, समझ में एक बॉटलनेक बन जाती है। प्रभावी डिकॉम्पोजिशन विशिष्ट नियमों का पालन करता है ताकि डायग्राम उपयोगी बना रहे।
- प्रत्येक प्रक्रिया में एक कार्य: प्रत्येक प्रक्रिया बबल या बॉक्स को डेटा के एकल, विशिष्ट रूपांतरण का प्रतिनिधित्व करना चाहिए। यदि कोई प्रक्रिया डेटा सत्यापन और डेटा स्टोरेज दोनों को संभालती है, तो इसे विभाजित करना चाहिए। इस विभाजन से प्रत्येक घटक की जिम्मेदारी स्पष्ट हो जाती है।
- संगत विस्तार: जबकि स्तरों में विस्तार भिन्न होता है, एक ही स्तर के भीतर विस्तार को संगत रखना चाहिए। यदि एक प्रक्रिया बहुत विस्तृत है, तो पड़ोसी प्रक्रियाओं को धुंधले सारांश नहीं होना चाहिए। इस संतुलन से डायग्राम असमान और भ्रमित नहीं होता है।
- तार्किक समूहन: संबंधित प्रक्रियाओं को दृश्य रूप से या नामकरण प्रथाओं द्वारा एक साथ ग्रुप करें। इससे पाठक को कार्यात्मक क्षेत्रों, जैसे “प्रमाणीकरण,” “बिलिंग,” या “रिपोर्टिंग” की पहचान करने में मदद मिलती है। तार्किक समूहन के कारण पूरे पृष्ठ पर रेखाओं को ट्रेस करने की आवश्यकता कम हो जाती है।
- क्रॉस-लेवल लीकेज से बचना: उच्च स्तर के डायग्राम में उन विवरणों को न शामिल करें जो निम्न स्तर में आने चाहिए। विपरीत रूप से, लेवल 1 डायग्राम में महत्वपूर्ण डेटा स्टोर्स को न छोड़ें जो प्रणाली की स्थिति को समझने के लिए आवश्यक हैं।
स्केलिंग के दौरान, ऐसी प्रक्रियाओं का सामना करना सामान्य है जो एकल श्रेणी में आसानी से फिट नहीं होती हैं। इन मामलों में, प्रक्रिया को समानांतर धाराओं में विभाजित करना या एक निर्दिष्ट इंटरफेस लेयर के माध्यम से संभालना हो सकता है। लक्ष्य यह है कि प्रवाह रेखीय और तार्किक बना रहे। यदि कोई प्रक्रिया पांच अलग-अलग स्रोतों से डेटा की आवश्यकता करती है और परिणामों को तीन अलग-अलग गंतव्यों पर भेजती है, तो यह एकल बॉक्स के लिए बहुत जटिल होने की संभावना है। इसे मध्यवर्ती चरणों में विभाजित करने से क्रियाओं के क्रम को स्पष्ट करने में मदद मिलती है।
पैमाने पर डेटा स्टोर्स का प्रबंधन 🗄️
डेटा स्टोर्स प्रणाली के स्थायी अवस्था का प्रतिनिधित्व करते हैं। छोटे प्रोजेक्ट्स में, एकल डेटाबेस पूरे एप्लिकेशन के लिए पर्याप्त हो सकता है। बड़े पैमाने के प्रोजेक्ट्स में, डेटा बहुत सी प्रणालियों, स्कीमाओं और सेवाओं के बीच वितरित होता है। DFD पर इन स्टोर्स को सटीक रूप से मैप करना डेटा अखंडता और पहुंच पैटर्न को समझने के लिए महत्वपूर्ण है।
- स्पष्ट नामकरण: डेटा स्टोर को सिर्फ “डेटाबेस” के रूप में नामित न करें। विशिष्ट नाम जैसे “उपयोगकर्ता_प्रोफाइल_स्टोर” या “लेनदेन_लॉग” का उपयोग करें। इस विशिष्टता से डेवलपर्स को यह पहचानने में मदद मिलती है कि कौन-सी प्रणाली कौन-से डेटा को रखती है।
- पढ़ना बनाम लिखना फ्लो: यह दर्शाएं कि डेटा कहां पढ़ा जाता है और कहां लिखा जाता है। जबकि DFDs पारंपरिक रूप से डेटा फ्लो को दिशात्मकता के बिना दिखाते हैं, स्केलिंग के लिए अवस्था परिवर्तन के बारे में स्पष्टता आवश्यक है। अलग-अलग नोटेशन या लेजेंड का उपयोग करें ताकि पता चले कि कोई प्रक्रिया स्टोर को अपडेट करती है या सिर्फ इसकी जांच करती है।
- साझा डेटा स्टोर्स: बड़े सिस्टम अक्सर प्रक्रियाओं के बीच डेटा स्टोर को साझा करते हैं। सुनिश्चित करें कि आरेख यह दर्शाता हो कि कौन-सी प्रक्रियाएं किन स्टोर्स तक पहुंच रखती हैं। इससे संभावित समानांतरता समस्याओं या सुरक्षा कमजोरियों की पहचान में मदद मिलती है।
- डेटा स्टोर संबंधों: यदि डेटा एक स्टोर से दूसरे स्टोर में बहता है, तो इसे स्पष्ट रूप से दिखाएं। इससे संकेत मिल सकता है कि प्रतिलिपि बनाने की प्रक्रिया, एक ETL कार्यक्रम या समन्वय सूची है। इन प्रवाहों को अक्सर नजरअंदाज किया जाता है, लेकिन ये सिस्टम की विश्वसनीयता के लिए बहुत महत्वपूर्ण हैं।
जैसे-जैसे डेटा स्टोर्स की संख्या बढ़ती है, आरेख भी भारी हो सकता है। इसके बचाव के लिए समूहीकरण तकनीकों का उपयोग करने का विचार करें। संबंधित डेटा स्टोर्स को एक सीमा के भीतर बंद करें जो एक विशिष्ट उपप्रणाली का प्रतिनिधित्व करती है। इससे दृश्य शोर कम होता है जबकि तार्किक संबंध बना रहता है। हालांकि, इस बात का ध्यान रखें कि इन समूहों के बीच डेटा के प्रवाह को छिपाने में न आएं। संबंधों को दिखाए रखना आवश्यक है ताकि पूरी तस्वीर समझी जा सके।
बाहरी एजेंसी सीमाएं 🌐
बाहरी एजेंसियां सिस्टम की सीमाओं के बाहर डेटा के स्रोत और गंतव्य का प्रतिनिधित्व करती हैं। इनमें मानव उपयोगकर्ता, अन्य सॉफ्टवेयर प्रणालियां, पुरानी मेनफ्रेम मशीनें या नियामक निकाय शामिल हो सकते हैं। बड़े पैमाने पर परियोजनाओं में बाहरी एजेंसियों की संख्या बहुत बढ़ सकती है। इन सीमाओं के प्रबंधन के लिए परियोजना के दायरे को परिभाषित करना आवश्यक है।
- स्पष्ट इंटरफेस परिभाषित करें: बाहरी एजेंसी और प्रक्रिया के बीच प्रत्येक संबंध एक इंटरफेस का प्रतिनिधित्व करता है। इन बातचीत के अपेक्षित प्रारूप और प्रोटोकॉल को दस्तावेज़ित करें। तीसरे पक्ष के सिस्टम के साथ एकीकरण के समय अस्पष्टता से बचने में यह मदद करता है।
- समान एजेंसियों को संगठित करें: यदि कई उपयोगकर्ता एक ही कार्य करते हैं, तो उन्हें एकल सामान्य एजेंसी (जैसे “ग्राहक”) के रूप में दर्शाएं, जिसके साथ भूमिका भिन्नताओं की व्याख्या करने वाला नोट हो। इससे बहुलता कम होती है बिना कार्यक्षमता के नुकसान के।
- सुरक्षा प्रभाव: बाहरी एजेंसियां अक्सर सुरक्षा सीमाओं का प्रतिनिधित्व करती हैं। बाहरी एजेंसी से सिस्टम में बहने वाले डेटा को प्रामाणिकता या एन्क्रिप्शन की आवश्यकता हो सकती है। DFD को आदर्श रूप से इन सुरक्षा आवश्यकताओं को टेक्स्ट या प्रतीकों के माध्यम से नोट करना चाहिए।
- पुरानी प्रणालियां: बड़ी परियोजनाएं अक्सर पुरानी प्रणालियों के साथ बातचीत करती हैं। इन एजेंसियों के पास कठोर डेटा प्रारूप हो सकते हैं। इन बातचीत को ध्यान से मैप करें ताकि नई प्रणाली डेटा को सही तरीके से संभाल सके बिना मौजूदा प्रवाह को तोड़े।
स्केलिंग के समय, छोटी बाहरी एजेंसियों को नजरअंदाज करने के लिए आकर्षक होता है। हालांकि, छोटे इनपुट्स के भी महत्वपूर्ण नीचे के प्रभाव हो सकते हैं। एक छोटी एजेंसी द्वारा डेटा भेजने के तरीके में बदलाव पूरी प्रणाली में फैल सकता है। इसलिए, सभी एजेंसियों को संदर्भ आरेख में शामिल किया जाना चाहिए और उनका विभाजन स्तरों तक अनुसरण किया जाना चाहिए।
रखरखाव और संस्करण नियंत्रण 🔄
एक DFD एक जीवित दस्तावेज है। बड़े पैमाने पर परियोजनाओं में आवश्यकताएं अक्सर बदलती हैं। प्रक्रियाओं को जोड़ा जाता है, डेटा स्टोर्स को मिलाया जाता है, और बाहरी इंटरफेस को अप्रचलित कर दिया जाता है। एक मजबूत रखरखाव रणनीति के बिना, आरेख जल्दी से अप्रचलित हो जाता है, जिससे दस्तावेज़ीकरण और कोड के बीच असंगति आती है।
- संस्करण निर्धारण: आरेखों को संस्करण संख्या दें। इससे टीमों को समय के साथ बदलावों का अनुसरण करने में मदद मिलती है। यदि कोई बग रिपोर्ट किया जाता है, तो आप उस विशिष्ट संस्करण को संदर्भित कर सकते हैं जो कोड लिखे जाने के समय उपलब्ध था।
- बदलाव लॉग: विभिन्न संस्करणों के बीच क्या बदलाव हुए हैं, इसका वर्णन करने वाला अलग लॉग बनाए रखें। तारीख, लेखक और बदलाव का कारण शामिल करें। यह भविष्य के विकासकर्ताओं के लिए संदर्भ प्रदान करता है जो शायद यह नहीं याद रखेंगे कि एक निर्णय क्यों लिया गया था।
- समीक्षा चक्र: DFDs की नियमित समीक्षा की योजना बनाएं। इनका बड़े रिलीज चक्रों के साथ मेल बनना चाहिए। इन समीक्षाओं के दौरान, यह सुनिश्चित करें कि आरेख वर्तमान कार्यान्वयन के अनुरूप हैं। यदि अंतर पाए जाते हैं, तो तुरंत उन्हें अपडेट करें।
- पहुंच नियंत्रण: सुनिश्चित करें कि केवल अधिकृत कर्मचारी ही आरेखों को संशोधित कर सकते हैं। नियंत्रण बिना संपादन संघर्ष और भ्रम का कारण बन सकता है। एक प्रणाली का उपयोग करें जो बताए कि किसने बदलाव किया और कब।
विकास के लिए रखरखाव को अक्सर नजरअंदाज किया जाता है। हालांकि, अप्रचलित आरेख बिल्कुल भी आरेख न होने से भी ज्यादा खतरनाक होते हैं। इनके कारण गलत सुरक्षा की भावना बनती है। टीमें दस्तावेज़ीकरण पर भरोसा कर सकती हैं जो वास्तविकता को दर्शाते नहीं हैं। DFD को कोड की तरह लेने और उसी संस्करण नियंत्रण और समीक्षा प्रक्रियाओं के अधीन रखने से टीमें सटीकता सुनिश्चित कर सकती हैं।
तुलना: स्केल्ड बनाम सरल DFDs 📊
एक सरल DFD और एक स्केल्ड DFD के बीच अंतर को समझना टीमों को संक्रमण के लिए तैयार करने में मदद करता है। नीचे दी गई तालिका संरचना, जटिलता और प्रबंधन में मुख्य अंतरों को चित्रित करती है।
| विशेषता | सरल DFD | स्केल्ड डीएफडी |
|---|---|---|
| प्रक्रियाओं की संख्या | 1 से 5 | 20 से 100+ |
| स्तर | 1 (समतल) | 3 से 5 (पदानुक्रमिक) |
| उपयोग किए गए उपकरण | कलम और कागज | विशेषज्ञ आरेखण सॉफ्टवेयर |
| संस्करण नियंत्रण | हाथ से | स्वचालित प्रणालियाँ |
| समीक्षा आवृत्ति | डिलीवरी पर | प्रति स्प्रिंट/रिलीज |
| डेटा भंडार विवरण | सामान्य | विशिष्ट और नामांकित |
| बाहरी एकाइयाँ | न्यूनतम | व्यापक और वर्गीकृत |
दस्तावेज़ीकरण गुणवत्ता के लिए सर्वोत्तम प्रथाएँ ✅
DFD को मूल्यवान संपत्ति बनाए रखने के लिए, इन सर्वोत्तम प्रथाओं का पालन करें। इन दिशानिर्देशों पर स्पष्टता, सांस्कृतिक स्थिरता और उपयोगिता पर ध्यान केंद्रित किया गया है।
- संगत नामकरण प्रणाली: प्रक्रियाओं, डेटा प्रवाह और भंडार के नामकरण के लिए एक मानक प्रारूप का उपयोग करें। उदाहरण के लिए, प्रक्रियाओं के लिए “क्रिया-संज्ञा” का उपयोग करें (जैसे, “कर की गणना करें”)। इससे आरेख पठनीय और खोजने योग्य बन जाता है।
- रेखा के प्रतिच्छेदन को कम करें: आरेख को व्यवस्थित करें ताकि एक दूसरे को काटने वाली रेखाओं की संख्या कम हो। इससे दृश्य प्रवाह में सुधार होता है और डेटा पथ का अनुसरण करने के लिए आवश्यक मानसिक प्रयास कम होता है।
- प्रतीकों और कुंजियों का उपयोग करें: यदि सुरक्षा, डेटा प्रकार या बाहरी प्रणालियों के लिए विशेष प्रतीकों का उपयोग कर रहे हैं, तो एक प्रतीक सूची प्रदान करें। यह न मानें कि पाठक हर प्रतीक का अर्थ जानता है।
- विनिर्देशों के लिए लिंक: जहां संभव हो, आरेख को विस्तृत आवश्यकता दस्तावेजों या कोड भंडारों से लिंक करें। इससे उच्च स्तरीय दृश्य और कार्यान्वयन विवरणों के बीच एक पुल बनता है।
- अपडेट रखें: आरेख को सही रखने को बेहतर बनाने की तुलना में प्राथमिकता दें। थोड़ा अव्यवस्थित लेकिन सही आरेख, चमकदार लेकिन अद्यतन नहीं होने वाले आरेख से अधिक उपयोगी होता है।
अन्य दस्तावेजों के साथ एकीकरण 📝
एक डीएफडी अकेले नहीं मौजूद होता है। यह तकनीकी दस्तावेजों के बड़े पारिस्थितिकी तंत्र का हिस्सा है। इसके मूल्य को अधिकतम करने के लिए, इसे अन्य कलाकृतियों के साथ एकीकृत करना आवश्यक है।
- डेटाबेस स्कीमा: डीएफडी में डेटा भंडार को डेटाबेस स्कीमा के सीधे मैप करना चाहिए। इससे यह सुनिश्चित होता है कि भौतिक कार्यान्वयन तार्किक डिजाइन के अनुरूप है।
- एपीआई विनिर्देश: बाहरी एकाधिकार और प्रक्रियाओं के बीच के प्रवाह अक्सर एपीआई एंडपॉइंट्स के संगत होते हैं। इन दस्तावेजों का पारस्परिक संदर्भ एकीकरण बिंदुओं की पुष्टि करने में मदद करता है।
- सुरक्षा नीतियाँ: संवेदनशील जानकारी वाले डेटा प्रवाहों को सुरक्षा नीतियों के साथ पारस्परिक संदर्भित करना चाहिए। इससे यह सुनिश्चित होता है कि एन्क्रिप्शन और पहुंच नियंत्रण की आवश्यकताएं पूरी हों।
- परीक्षण मामले: परीक्षण मामलों को डेटा प्रवाहों से निकाला जाना चाहिए। प्रत्येक प्रवाह परीक्षण के लिए एक संभावित मार्ग का प्रतिनिधित्व करता है। इससे तंत्र के तर्क के व्यापक कवरेज सुनिश्चित होता है।
बचने वाले सामान्य त्रुटियाँ ⚠️
सर्वोत्तम इच्छाओं के साथ भी, टीमें डीएफडी को बढ़ावा देते समय गलतियाँ कर सकती हैं। इन त्रुटियों के बारे में जागरूकता आम जाल में फंसने से बचने में मदद करती है।
- अत्यधिक डिजाइन करना: ऐसा आरेख न बनाएं जो स्तर के लिए बहुत विस्तृत हो। लेवल 1 आरेख में लेवल 2 प्रक्रिया के तर्क को नहीं शामिल करना चाहिए। अभिकल्पना स्तर को उचित रखें।
- नियंत्रण प्रवाहों को नजरअंदाज करना: जबकि डीएफडी डेटा पर ध्यान केंद्रित करते हैं, नियंत्रण संकेत (जैसे “शुरू”, “रुको”, “त्रुटि”) अक्सर जटिल प्रणालियों में आवश्यक होते हैं। इन्हें डेटा प्रवाहों से स्पष्ट रूप से अलग करें।
- रेखीयता मान लेना: प्रणालियाँ लगभग कभी रेखीय नहीं होती हैं। लूप, प्रतिपुष्टि तंत्र और असमान घटनाएँ सामान्य हैं। इन्हें सही ढंग से दर्शाएं, भले ही आरेख पढ़ने में कठिन हो जाए।
- मानकीकरण की कमी: यदि विभिन्न टीम सदस्य अलग-अलग शैलियों में आरेख बनाते हैं, तो समग्र दस्तावेज़ीकरण टुकड़ों में बंट जाता है। जल्दी से एक शैली गाइड बनाएं और उसका पालन करें।
स्केलेबिलिटी पर निष्कर्ष 🏗️
डेटा प्रवाह आरेखों को स्केल करना लचीले, बड़े पैमाने पर प्रणालियों के निर्माण के लिए एक आवश्यक विषय है। बस अधिक बॉक्स बनाने से अधिक चाहिए; इसमें श्रेणीकरण, विघटन और रखरखाव के लिए संरचित दृष्टिकोण की आवश्यकता होती है। इस गाइड में बताए गए रणनीतियों का पालन करके टीमें ऐसा दस्तावेज़ीकरण बना सकती हैं जो विकास का समर्थन करता है बिना बोझ बने। लक्ष्य स्पष्टता है। जब आरेख स्पष्ट होता है, तो प्रणाली को समझना, बनाए रखना और विस्तार करना आसान होता है। इस दस्तावेज़ीकरण में निवेश का लाभ गलतियों में कमी और नए सदस्यों के तेजी से एकीकरण में दिखता है।
याद रखें कि आरेख संचार का एक उपकरण है, केवल तकनीकी वस्तु नहीं। यह व्यावसायिक आवश्यकताओं और तकनीकी कार्यान्वयन के बीच के अंतर को पार करता है। जैसे ही प्रणाली बढ़ती है, वैसे ही दस्तावेज़ीकरण को भी बढ़ाना चाहिए। नियमित समीक्षा और कठोर संस्करण नियंत्रण सुनिश्चित करता है कि डीएफडी प्रोजेक्ट के जीवनचक्र के दौरान भी विश्वसनीय सत्य का स्रोत बनी रहे। सही दृष्टिकोण के साथ, डीएफडी को स्केल करना एक नियंत्रित कार्य बन जाता है, बजाय अव्यवस्थित प्रयास के।