











एक प्रणाली के माध्यम से जानकारी के आवागमन का स्पष्ट दृश्य प्रतिनिधित्व बनाना प्रणाली विश्लेषण और डिजाइन के लिए मूलभूत है। डेटा फ्लो डायग्राम (DFD) इसी उद्देश्य को पूरा करता है। यह बाहरी स्रोतों से प्रणाली में डेटा के प्रवाह और निर्देशांक तक बाहर जाने के प्रवाह को नक्शा बनाता है, और रास्ते में होने वाले परिवर्तनों का विवरण देता है।
यह मार्गदर्शिका DFDs बनाने की यांत्रिकी में गहराई से जाने का अवसर प्रदान करती है। हम ऐतिहासिक संदर्भ, मूल संकेतों, पदानुक्रमिक स्तरों और किसी विशिष्ट निजी उपकरण के बिना एक कार्यात्मक आरेख बनाने के लिए आवश्यक व्यावहारिक चरणों का अध्ययन करेंगे। इस ट्यूटोरियल के अंत तक, आप रेखाओं के पीछे के तर्क को समझेंगे और जटिल प्रणालियों का प्रभावी रूप से दस्तावेजीकरण करने के लिए सक्षम होंगे।
🧠 DFD के उद्देश्य को समझना
एक भी रेखा खींचने से पहले, यह समझना आवश्यक है कि DFD वास्तव में क्या प्रतिनिधित्व करता है। एक फ्लोचार्ट के विपरीत, जो किसी प्रोग्राम के नियंत्रण प्रवाह या तर्क का वर्णन करता है, DFD केवल डेटा.
- डेटा पर ध्यान केंद्रित करें: यह दिखाता है कि डेटा कहाँ से आता है (स्रोत) और कहाँ जाता है (स्निक्स)।
- प्रक्रियाओं पर ध्यान केंद्रित करें: यह दिखाता है कि डेटा को विभिन्न रूपों में कैसे बदला जाता है।
- स्टोरेज पर ध्यान केंद्रित करें: यह दिखाता है कि डेटा कहाँ रखा जाता है ताकि बाद में प्राप्त किया जा सके।
DFDs को आवश्यकता संग्रह चरण के दौरान विशेष रूप से उपयोगी माना जाता है। ये स्टेकहोल्डर्स को प्रणाली की सीमाओं को दृश्य रूप से समझने में मदद करते हैं और यह सुनिश्चित करते हैं कि सभी आवश्यक इनपुट और आउटपुट को ध्यान में रखा गया है। यह दृश्य संचार तकनीकी टीमों और व्यापार उपयोगकर्ताओं के बीच के अंतर को पार करता है।
🛠️ मूल घटक और नोटेशन
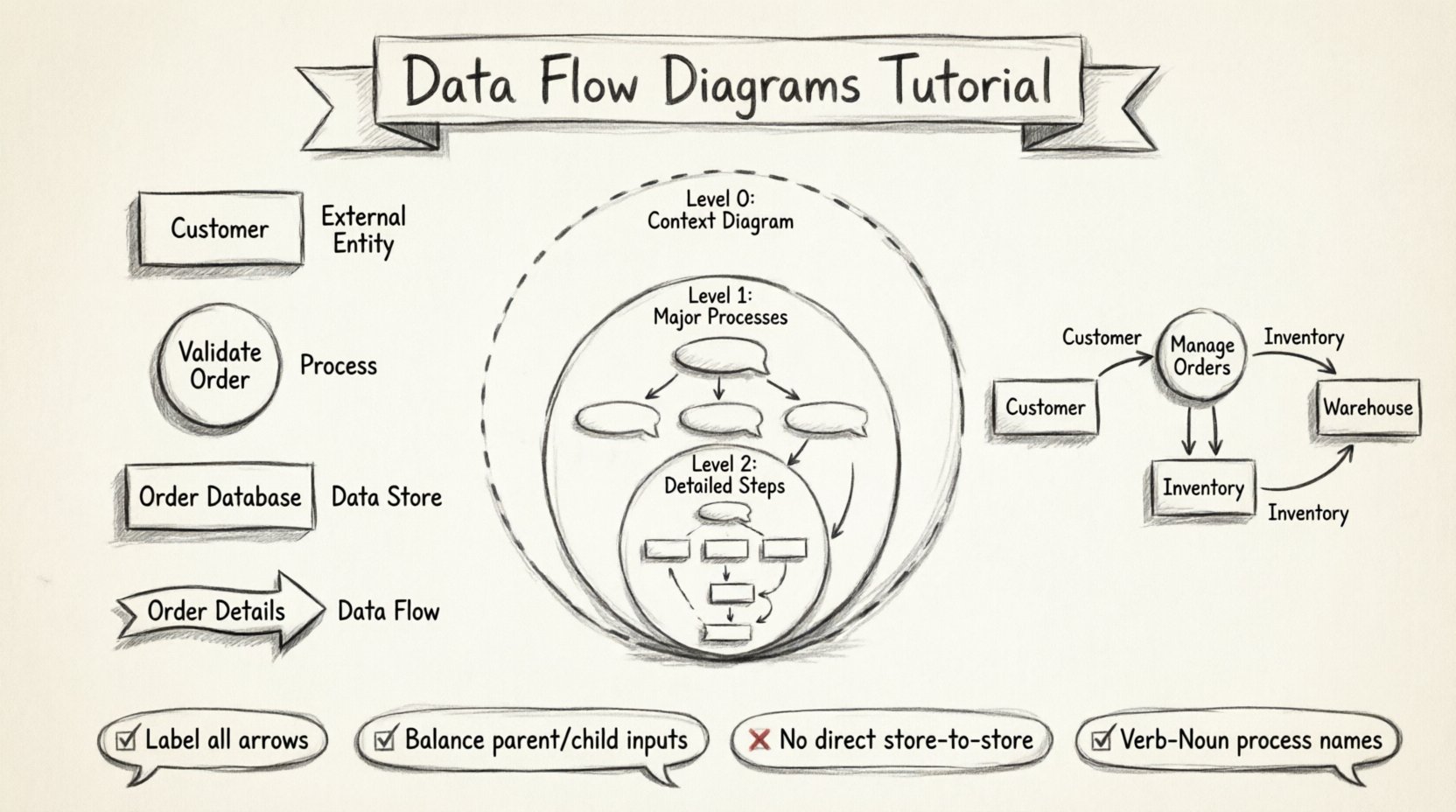
प्रत्येक डेटा फ्लो डायग्राम एक विशिष्ट आकृतियों और रेखाओं के सेट का उपयोग करके बनाया जाता है। हालांकि इतिहास में दो मुख्य नोटेशन का उपयोग किया गया है (यौरडॉन और डीमार्को बनाम गेन और सर्सन), अवधारणाएं संरेखित रहती हैं। नीचे किसी भी DFD के लिए आवश्यक चार मूल तत्वों का विवरण दिया गया है।
1. बाहरी एकाइयाँ (समाप्तकर्ता)
ये उन स्रोतों या गंतव्यों का प्रतिनिधित्व करते हैं जो प्रणाली की सीमा के बाहर होते हैं। ये वे लोग, विभाग या अन्य प्रणालियाँ हैं जो आपकी प्रक्रिया के साथ बातचीत करते हैं।
- उदाहरण:ग्राहक, आपूर्तिकर्ता, बैंक, सरकारी एजेंसी।
- दृश्य:आमतौर पर एक आयत या मानव प्रतीक।
- नियम: प्रणाली की सीमा के बाहर डेटा स्टोर या प्रक्रियाओं को नहीं रखें।
2. प्रक्रियाएं
एक प्रक्रिया आने वाले डेटा प्रवाह को बाहर जाने वाले डेटा प्रवाह में बदलती है। यह प्रणाली के भीतर किए जा रहे कार्य, गणनाओं या निर्णयों का प्रतिनिधित्व करती है।
- उदाहरण: “कर की गणना”, “आदेश की पुष्टि”, “रिपोर्ट तैयार करें”।
- दृश्य: एक वृत्त या गोल किनारे वाला आयत।
- नियम: प्रत्येक प्रक्रिया के कम से कम एक इनपुट और एक आउटपुट होने चाहिए।
3. डेटा स्टोर
ये वे भंडार हैं जहां डेटा भविष्य के उपयोग के लिए सहेजा जाता है। इसमें डेटाबेस, फाइल, भौतिक फाइलिंग कैबिनेट या अस्थायी बफर शामिल हो सकते हैं।
- उदाहरण: ग्राहक डेटाबेस, इन्वेंटरी लॉग, ऑर्डर इतिहास।
- दृश्य: खुला आयत या दो समानांतर रेखाएं।
- नियम: प्रक्रियाओं को डेटा स्टोर से पढ़ना या लिखना चाहिए; वे एक स्टोर से दूसरे स्टोर में डेटा सीधे नहीं भेज सकती हैं।
4. डेटा प्रवाह
ये वे मार्ग हैं जिन पर डेटा जाता है। इनका अर्थ एकताओं, प्रक्रियाओं और स्टोर के बीच डेटा के आवागमन का प्रतिनिधित्व करना है।
- उदाहरण: “ऑर्डर विवरण”, “भुगतान पुष्टिकरण”, “स्टॉक अद्यतन”।
- दृश्य: एक तीर जिस पर डेटा की सामग्री का वर्णन करने वाला लेबल हो।
- नियम: तीरों को लेबल करना आवश्यक है। बिना लेबल के तीर अमान्य हैं।
| घटक | प्रतीक आकृति (योर्डन और डेमार्को) | प्रतीक आकृति (गेन और सर्सन) | कार्य |
|---|---|---|---|
| बाहरी एकाई | आयत | गोल किनारों वाला वर्ग | स्रोत या गंतव्य |
| प्रक्रिया | वृत्त | गोल किनारों वाला आयत | डेटा को परिवर्तित करता है |
| डेटा स्टोर | खुला आयत | खुले छोर वाला आयत | डेटा स्टोर करता है |
| डेटा प्रवाह | तीर | तीर | डेटा को हटाता है |
📉 डीएफडी में संकल्पना के स्तर
जटिल प्रणालियों को एक ही आरेख में नहीं दर्शाया जा सकता है। जटिलता को प्रबंधित करने के लिए, डीएफडी को विभिन्न विवरण स्तरों पर बनाया जाता है, जैसे कि एक नक्शे पर जूम करना। इस पदानुक्रम को विभाजन के रूप में जाना जाता है।
स्तर 0: संदर्भ आरेख
यह सबसे ऊंचा स्तर का दृश्य है। यह पूरी प्रणाली को एकल प्रक्रिया के रूप में दिखाता है और इसके बाहरी एकाधिकारों के साथ बातचीत को दर्शाता है। यह प्रणाली की सीमा को स्पष्ट रूप से परिभाषित करता है।
- प्रक्रिया गिनती: 1 (पूरी प्रणाली)।
- विवरण स्तर:न्यूनतम। आंतरिक प्रक्रियाओं को नहीं दिखाया गया है।
- उपयोग:सीमा परिभाषा और उच्च स्तर की सहमति।
स्तर 1: मुख्य उप-प्रक्रियाएं
यहां, संदर्भ आरेख से एकल प्रक्रिया को उसकी मुख्य उप-प्रक्रियाओं में विस्तारित किया जाता है। यहीं से प्रणाली की आंतरिक संरचना दिखने लगती है।
- प्रक्रिया गिनती:पठनीयता के लिए 3 से 7 आदर्श है।
- विवरण स्तर:मुख्य कार्यात्मक क्षेत्र।
- उपयोग:मुख्य कार्यात्मक मॉड्यूल को समझना।
स्तर 2: विस्तृत उप-प्रक्रियाएं
यह स्तर विशिष्ट स्तर 1 प्रक्रियाओं में गहराई से जाता है। इसका उपयोग जटिल कार्यों के लिए किया जाता है जिन्हें आगे विभाजित करने की आवश्यकता होती है।
- प्रक्रिया गिनती:प्रत्येक मातृ प्रक्रिया के अनुसार भिन्न होता है।
- विवरण स्तर: किसी फ़ंक्शन के भीतर के विशिष्ट चरण।
- उपयोग: कार्यान्वयन मार्गदर्शन और विस्तृत तर्क।
स्तर 3: मूल आरेख
ये तब तक बहुत कम बनाए जाते हैं जब तक कि प्रणाली अत्यधिक जटिल नहीं होती है। इनका अर्थ होता है विवरण का सबसे निम्न स्तर, जो अक्सर विशिष्ट कोड मॉड्यूल या हाथ से किए जाने वाले प्रक्रियाओं से मेल खाता है।
🚀 डीएफ़डी बनाने का चरण-दर-चरण मार्गदर्शिका
अपने प्रोजेक्ट के लिए एक बलवान डेटा प्रवाह आरेख बनाने के लिए इस संरचित दृष्टिकोण का पालन करें।
चरण 1: प्रणाली सीमा की पहचान करें
यह निर्धारित करें कि प्रणाली के भीतर क्या है और बाहर क्या है। यह निर्धारित करने के लिए महत्वपूर्ण है कि कौन से एकाधिकार बाहरी हैं और कौन सी प्रक्रियाएं आंतरिक हैं। प्रणाली की प्रक्रियाओं के चारों ओर एक बॉक्स बनाएं।
चरण 2: बाहरी एकाधिकार की पहचान करें
सभी लोगों, संगठनों या बाहरी प्रणालियों की सूची बनाएं जो आपकी प्रणाली के साथ बातचीत करेंगे। उन्हें सीमा बॉक्स के बाहर रखें। उन्हें स्पष्ट रूप से लेबल करें।
चरण 3: संदर्भ आरेख (स्तर 0) बनाएं
पूरी प्रणाली का प्रतिनिधित्व करने वाले केंद्र में एक एकल वृत्त बनाएं। बाहरी एकाधिकार को इस वृत्त से तीरों के द्वारा जोड़ें। इन तीरों को आदान-प्रदान किए जा रहे डेटा के साथ लेबल करें (उदाहरण के लिए, “आदेश अनुरोध”, “बिल भेजा गया”)।
चरण 4: स्तर 1 में विभाजित करें
एकल वृत्त को कई प्रक्रियाओं में विस्तारित करें। पूछें: “इस प्रणाली के मुख्य कार्य क्या हैं?”।
- इनपुट डेटा की पहचान करें।
- आउटपुट डेटा की पहचान करें।
- आवश्यक डेटा स्टोर की पहचान करें।
- एकाधिकार, प्रक्रियाओं और स्टोर को जोड़ने वाले तीर बनाएं।
चरण 5: संतुलन नियम लागू करें
यह सबसे महत्वपूर्ण तकनीकी नियम है। एक माता-पिता प्रक्रिया के इनपुट और आउटपुट को उसके बच्चे आरेख के इनपुट और आउटपुट के मेल खाना चाहिए।
- यदि स्तर 0 प्रक्रिया का इनपुट “ग्राहक आईडी” है, तो स्तर 1 की बच्ची प्रक्रिया में भी “ग्राहक आईडी” के आने या जाने की स्थिति होनी चाहिए।
- यदि स्तर 1 प्रक्रिया “रिपोर्ट डेटा” उत्पन्न करती है, तो स्तर 0 का माता-पिता भी बाहरी एकाधिकार को “रिपोर्ट डेटा” आउटपुट करना चाहिए।
चरण 6: समीक्षा और मान्यता
अपने आरेख की आवश्यकताओं के अनुसार जांचें।
- क्या सभी तीर लेबल किए गए हैं?
- क्या सभी प्रक्रियाओं के इनपुट और आउटपुट हैं?
- क्या प्रत्येक एकाधिकार से किसी स्टोर या प्रक्रिया तक एक मार्ग है?
- क्या कोई “स्पैगेटी” लाइनें हैं (एक दूसरे को अनावश्यक रूप से क्रॉस करती हैं)।
🏪 उदाहरण परिदृश्य: ऑनलाइन स्टोर प्रणाली
अवधारणाओं को समझाने के लिए, आइए एक सरलीकृत ऑनलाइन स्टोर परिदृश्य के माध्यम से चलें।
संदर्भ आरेख (स्तर 0)
- एकाधिकार: ग्राहक।
- एकाधिकार: भुगतान गेटवे।
- एकाधिकार: भंडार।
- प्रक्रिया: ऑनलाइन स्टोर प्रणाली।
- प्रवाह:
- ग्राहक ➔ प्रणाली: आदेश विवरण
- प्रणाली ➔ ग्राहक: आदेश पुष्टि
- प्रणाली ➔ भुगतान गेटवे: भुगतान जानकारी
- भुगतान गेटवे ➔ प्रणाली: भुगतान स्थिति
- प्रणाली ➔ भंडार: शिपिंग अनुरोध
स्तर 1 विघटन
हम “ऑनलाइन स्टोर प्रणाली” को तीन मुख्य प्रक्रियाओं में विभाजित करते हैं:
- आदेश प्रबंधित करें: आदेश विवरण प्राप्त करता है, स्टॉक जांचता है।
- भुगतान प्रक्रिया करें: क्रेडिट कार्ड जानकारी का प्रबंधन करता है, धन की पुष्टि करता है।
- माल भेजें: भंडार के साथ संचार करता है।
डेटा भंडार
हम दो डेटा भंडार पेश करते हैं:
- आदेश डेटाबेस: आदेश इतिहास और स्थिति संग्रहीत करता है।
- इन्वेंटरी डेटाबेस: वर्तमान स्टॉक स्तर स्टोर करता है।
इस लेवल 1 आरेख में, “आदेश प्रबंधित करें” ऑर्डर डेटाबेस में लिखता है। “भुगतान प्रक्रिया” ऑर्डर डेटाबेस से पढ़ता है ताकि ऑर्डर मौजूद है या नहीं, इसकी पुष्टि कर सके और फिर कार्ड से चार्ज करे। “माल भेजें” इन्वेंट्री डेटाबेस से पढ़ता है ताकि आइटम उपलब्ध हैं या नहीं, इसकी पुष्टि कर सके और फिर शिपिंग अनुरोध भेजे।
⚠️ सामान्य गलतियाँ और खतरे
यहाँ तक कि अनुभवी विश्लेषक डीएफडी बनाते समय भी गलतियाँ करते हैं। अपने आरेखों को वैध और उपयोगी बनाए रखने के लिए इन सामान्य खतरों से बचें।
- नियंत्रण प्रवाह: नियंत्रण सिग्नल (जैसे, “बटन पर क्लिक करें”, “त्रुटि संदेश”) को दर्शाने वाली तीर न बनाएं, जब तक वे डेटा नहीं ले रहे हैं। डीएफडी डेटा का अनुसरण करते हैं, नियंत्रण तर्क नहीं।
- सीधे स्टोर से स्टोर प्रवाह: डेटा एक डेटा स्टोर से दूसरे डेटा स्टोर में सीधे नहीं जा सकता है। इसे पहले एक प्रक्रिया से गुजरना होगा। इससे यह सुनिश्चित होता है कि परिवर्तन या सत्यापन होता है।
- अनलेबल तीर: एक अनलेबल तीर को कोई जानकारी नहीं मिलती है। हमेशा उस रेखा में बहने वाले डेटा का नाम दें।
- भूत प्रक्रियाएँ: एक प्रक्रिया जिसके कोई इनपुट या आउटपुट नहीं है, बेकार है। प्रत्येक बबल को कुछ बदलना चाहिए।
- अत्यधिक जटिलता: यदि लेवल 1 आरेख में 7-9 से अधिक प्रक्रियाएँ हैं, तो यह अत्यधिक विस्तृत होने की संभावना है। इसे तार्किक कार्यात्मक क्षेत्रों में विभाजित करें।
- काले छेदों को नजरअंदाज करना: एक प्रक्रिया जिसमें केवल इनपुट हैं और कोई आउटपुट नहीं है, एक “काला छेद” है। यह डेटा का उपभोग करती है लेकिन कुछ नहीं उत्पन्न करती है।
- चमत्कारों को नजरअंदाज करना: एक प्रक्रिया जिसमें केवल आउटपुट हैं और कोई इनपुट नहीं है, एक “चमत्कार” है। यह किसी भी चीज के बिना डेटा बनाती है।
📝 दस्तावेजीकरण के लिए सर्वोत्तम प्रथाएँ
आरेख बनाना केवल काम का आधा हिस्सा है। दस्तावेजीकरण और रखरखाव यह सुनिश्चित करता है कि डीएफडी समय के साथ भी मूल्यवान बनी रहे।
संगत नामकरण प्रणाली
प्रक्रियाओं और प्रवाहों के नामकरण के लिए एक मानक प्रारूप का उपयोग करें।
- प्रक्रियाएँ: क्रिया-संज्ञा प्रारूप का उपयोग करें (जैसे, “उपयोगकर्ता की पुष्टि करें”, “रिपोर्ट उत्पन्न करें”)।
- प्रवाह: संज्ञा प्रारूप का उपयोग करें (जैसे, “उपयोगकर्ता प्रमाण”, “बिक्री रिपोर्ट”)।
- स्टोर: बहुवचन संज्ञाओं का उपयोग करें (जैसे, “ग्राहक रिकॉर्ड”, “उत्पाद सूची”)।
रंग कोडिंग
विभिन्न प्रकार के घटकों या विभिन्न स्तरों के सारांश के बीच अंतर करने के लिए रंगों का उपयोग करें।
- बाहरी एजेंटों के लिए नीला।
- प्रक्रियाओं के लिए हरा।
- डेटा स्टोर के लिए नारंगी।
- महत्वपूर्ण डेटा प्रवाह के लिए लाल।
संस्करण नियंत्रण
सिस्टम आवश्यकताएं बदलती हैं। आपके DFDs को इन बदलावों को दर्शाना चाहिए।
- अपने आरेखों को संस्करण संख्या दें (v1.0, v1.1)।
- क्या जोड़ा गया, हटाया गया या संशोधित किया गया है, इसका बदलाव लॉग रखें।
- एक ऑडिट ट्रेल बनाए रखने के लिए पुराने संस्करणों को आर्काइव करें।
🔗 अन्य विधियों के साथ एकीकरण
DFD अकेले नहीं मौजूद होते हैं। वे अक्सर एक बड़े संरचित विश्लेषण ढांचे का हिस्सा होते हैं।
एंटिटी-रिलेशनशिप आरेख (ERD)
जबकि DFD डेटा के प्रवाह को दिखाते हैं, ERD डेटा की संरचना दिखाते हैं। जब आप अपने DFD में डेटा स्टोर की पहचान करते हैं, तो आपको अक्सर उनके लिए टेबल डिज़ाइन करने की आवश्यकता होती है, जिसमें ERD का उपयोग किया जाता है। DFD आपको बताता है कि कौन सा डेटा आवश्यक है; ERD आपको बताता है कि डेटा कैसे संरचित है।
संरचित अंग्रेजी
DFD के भीतर जटिल प्रक्रियाओं के लिए, एक सरल आरेख पर्याप्त नहीं हो सकता है। संरचित अंग्रेजी प्रक्रिया बबल के भीतर के तर्क को वर्णित करने के लिए प्राकृतिक भाषा और प्रोग्रामिंग तर्क का मिश्रण है।
डेटा शब्दकोश
प्रत्येक डेटा प्रवाह, स्टोर और एंटिटी को एक डेटा शब्दकोश में परिभाषित किया जाना चाहिए। इस दस्तावेज़ में आरेख के लिए मेटाडेटा प्रदान करता है, जिसमें डेटा प्रकार, आकार और प्रारूप शामिल हैं (उदाहरण के लिए, “ग्राहक आईडी: पूर्णांक, 10 अंक”)।
🛠️ उपकरण और सॉफ्टवेयर चयन
DFD बनाने के लिए आपको महंगे सॉफ्टवेयर की आवश्यकता नहीं है। ध्यान तर्क पर होना चाहिए, न कि बाह्य रूपों पर।
- व्हाइटबोर्ड और मार्कर: स्टेकहोल्डर्स के साथ ब्रेनस्टॉर्मिंग और प्रारंभिक ड्राफ्ट के लिए उत्तम।
- कागज और पेंसिल: सॉफ्टवेयर की सीमाओं के बिना एक अवधारणा पर तेजी से पुनरावृत्ति करने का सबसे तेज़ तरीका।
- सामान्य ड्रॉइंग उपकरण: कोई भी वेक्टर ग्राफिक्स टूल शुद्ध, डिजिटल आरेख बनाने के लिए उपयोग किया जा सकता है।
- विशेषज्ञ विश्लेषण उपकरण: सिस्टम विश्लेषण के लिए बहुत सारे विशेष उपकरण उपलब्ध हैं। मानक DFD नोटेशन का समर्थन करने वाले और संस्करण नियंत्रण की अनुमति देने वाले उपकरण का चयन करें।
उपकरण के बावजूद, सुनिश्चित करें कि यह आपको टीम के साथ साझा करने के लिए मानक प्रारूप में आरेखों को निर्यात करने की अनुमति देता है।
🔄 रखरखाव और जीवनचक्र
एक DFD एक जीवित दस्तावेज़ है। जब कोई सिस्टम विकसित होता है, तो आरेख को भी विकसित होना चाहिए।
- परिवर्तन अनुरोध: जब कोई नया फीचर मांगा जाता है, तो प्रभाव को देखने के लिए स्तर 1 आरेख को अपडेट करें।
- प्रभाव विश्लेषण: यदि कोई प्रक्रिया बदलती है, तो जांचें कि इसके आउटपुट पर कौन-सी अन्य प्रक्रियाएं निर्भर हैं। उन आरेखों को भी अपडेट करें।
- कोड समीक्षा: डेवलपर्स को कोड को डेटा फ्लो तर्क के अनुरूप बनाने के लिए वास्तविकार्थ में DFD को देखना चाहिए।
- परीक्षण: परीक्षण मामले डेटा प्रवाह से निकाले जा सकते हैं। यदि कोई प्रवाह मौजूद है, तो उस मार्ग के साथ डेटा अखंडता की पुष्टि करने के लिए एक परीक्षण होना चाहिए।
📚 मुख्य सिद्धांतों का सारांश
प्रभावी डेटा प्रवाह आरेख बनाने के लिए महत्वपूर्ण बातों का सारांश:
- सरल शुरू करें: सीमा निर्धारित करने के लिए संदर्भ आरेख (स्तर 0) से शुरू करें।
- क्रमिक रूप से विभाजित करें: केवल आवश्यकता होने पर ही स्तर 0 से स्तर 1 और फिर स्तर 2 तक जाएं।
- कठोरता से संतुलन बनाएं: सुनिश्चित करें कि मुख्य और बच्चे के स्तरों के इनपुट और आउटपुट मेल खाते हों।
- सब कुछ लेबल करें: कोई अनलेबल तीर या प्रक्रिया नहीं।
- डेटा पर ध्यान केंद्रित करें: नियंत्रण तर्क को नजरअंदाज करें; केवल डेटा के हलचल का अनुसरण करें।
- हितधारकों के साथ प्रमाणीकरण करें: सटीकता सुनिश्चित करने के लिए व्यवसाय उपयोगकर्ताओं के साथ आरेखों की समीक्षा करें।
इन सिद्धांतों का पालन करने से आप एक दस्तावेज़ी सामग्री बनाते हैं जो डेवलपर्स, टेस्टर्स और व्यवसाय विश्लेषकों के लिए एक विश्वसनीय मानचित्र के रूप में काम करती है। आपके आरेख की स्पष्टता सिस्टम विकास चक्र की दक्षता से सीधे संबंधित है।
🏁 अंतिम विचार
डेटा प्रवाह आरेख के कला को समझने के लिए अभ्यास और प्रणाली चिंतन के अनुशासित दृष्टिकोण की आवश्यकता होती है। यह केवल आकृतियां बनाने के बारे में नहीं है; यह एक संगठन के भीतर जानकारी के जीवनचक्र को समझने के बारे में है। जब आप एक डेटा के उत्पत्ति से अंतिम गंतव्य तक निशान लगा सकते हैं, तो आपने वास्तव में प्रणाली को समझ लिया है।
इस ट्यूटोरियल को आधार के रूप में उपयोग करें। वास्तविक दुनिया के परिदृश्यों पर अभ्यास करें, अपने आरेखों की आम गलतियों के लिए आलोचना करें, और हमेशा जटिलता की तुलना में स्पष्टता को प्राथमिकता दें। एक अच्छी तरह से बनाया गया DFD टिकाऊ, विश्वसनीय सॉफ्टवेयर प्रणालियों के निर्माण में एक चुप्पी साथी है।