











Создание четкого визуального представления о том, как информация перемещается через систему, является фундаментальным элементом анализа и проектирования систем. Диаграмма потока данных (DFD) выполняет именно эту задачу. Она отображает поток данных из внешних источников в систему и далее к пунктам назначения, детализируя преобразования, происходящие на протяжении всего пути.
Это руководство предоставляет глубокое погружение в механику построения DFD. Мы рассмотрим исторический контекст, основные символы, иерархические уровни и практические шаги, необходимые для создания функциональной диаграммы без использования специфических проприетарных инструментов. К концу этого руководства вы поймете логику, стоящую за линиями, и сможете эффективно документировать сложные системы.
🧠 Понимание цели диаграммы потока данных
Прежде чем начертить одну линию, необходимо понимать, что на самом деле представляет собой DFD. В отличие от блок-схемы, которая описывает поток управления или логику программы, DFD сосредоточен исключительно наданных.
- Фокус на данных: Она показывает, откуда поступают данные (источники) и куда они направляются (приемники).
- Фокус на процессах: Она иллюстрирует, как данные преобразуются в различные формы.
- Фокус на хранении: Она указывает, где данные хранятся для последующего извлечения.
DFD особенно полезны на этапе сбора требований. Они помогают заинтересованным сторонам визуализировать границы системы и подтвердить, что все необходимые входы и выходы учтены. Такая визуальная коммуникация устраняет разрыв между техническими командами и бизнес-пользователями.
🛠️ Основные компоненты и нотация
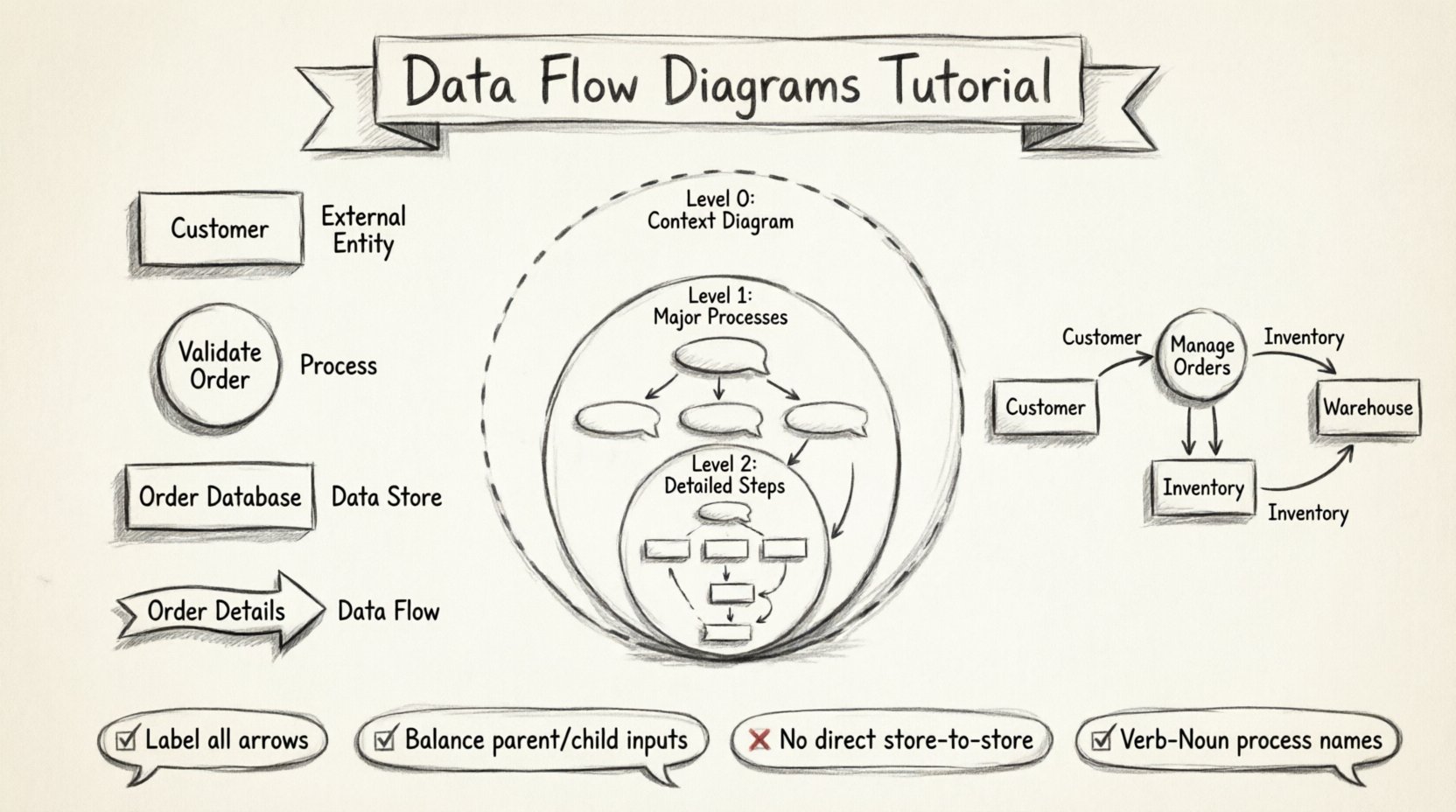
Каждая диаграмма потока данных строится с использованием определенного набора фигур и линий. Хотя исторически использовались две основные нотации (Yourdon & DeMarco против Gane & Sarson), концепции остаются одинаковыми. Ниже приведено описание четырех основных элементов, необходимых для любой DFD.
1. Внешние сущности (терминаторы)
Они представляют источники или пункты назначения данных, находящиеся за пределами границ системы. Это люди, отделы или другие системы, взаимодействующие с вашим процессом.
- Примеры:Клиент, Поставщик, Банк, Государственное учреждение.
- Визуальное представление: Обычно прямоугольник или иконка человека.
- Правило: Не размещайте хранилища данных или процессы за пределами границ системы.
2. Процессы
Процесс преобразует входящие потоки данных в исходящие. Он представляет собой выполняемую работу, вычисления или принимаемые решения внутри системы.
- Примеры: «Рассчитать налог», «Проверить заказ», «Создать отчет».
- Визуальное представление: Окружность или прямоугольник с закругленными углами.
- Правило: Каждый процесс должен иметь хотя бы один вход и один выход.
3. Хранилища данных
Это хранилища, где данные сохраняются для последующего использования. Это может быть база данных, файл, физический файловый шкаф или временный буфер.
- Примеры: База данных клиентов, журнал инвентаризации, история заказов.
- Визуальное представление: Открытый прямоугольник или две параллельные линии.
- Правило: Процессы должны читать из или записывать в хранилища данных; они не могут передавать данные напрямую из одного хранилища в другое.
4. Потоки данных
Это пути, по которым проходят данные. Они представляют перемещение данных между сущностями, процессами и хранилищами.
- Примеры: «Сведения о заказе», «Подтверждение оплаты», «Обновление остатков».
- Визуальное представление: Стрелка с меткой, описывающей содержимое данных.
- Правило: Стрелки должны быть помечены. Непомеченные стрелки недействительны.
| Компонент | Форма символа (Юрдон и Демарко) | Форма символа (Гейн и Сарсон) | Функция |
|---|---|---|---|
| Внешняя сущность | Прямоугольник | Квадрат с закруглёнными углами | Источник или назначение |
| Процесс | Окружность | Округлённый прямоугольник | Преобразует данные |
| Хранилище данных | Открытый прямоугольник | Прямоугольник с открытым концом | Хранит данные |
| Поток данных | Стрелка | Стрелка | Передает данные |
📉 Уровни абстракции в диаграммах потоков данных
Сложные системы не могут быть представлены на одной диаграмме. Чтобы управлять сложностью, диаграммы потоков данных рисуются на разных уровнях детализации, аналогично увеличению масштаба на карте. Эта иерархия известна как декомпозиция.
Уровень 0: Диаграмма контекста
Это самый высокий уровень представления. Он показывает всю систему как единый процесс и её взаимодействие с внешними сущностями. Чётко определяет границы системы.
- Количество процессов: 1 (вся система).
- Уровень детализации:Минимальный. Внутренние процессы не показаны.
- Использование: Определение области и согласование на высоком уровне.
Уровень 1: Основные подпроцессы
Здесь единственный процесс из диаграммы контекста раскрывается на основные подпроцессы. Именно здесь начинает проявляться внутренняя структура системы.
- Количество процессов:3–7 — идеальное количество для читаемости.
- Уровень детализации:Основные функциональные области.
- Использование: Понимание основных функциональных модулей.
Уровень 2: Подробные подпроцессы
На этом уровне происходит углубление в конкретные процессы уровня 1. Используется для сложных функций, требующих дальнейшего разбиения.
- Количество процессов: Варьируется в зависимости от родительского процесса.
- Уровень детализации: Конкретные шаги внутри функции.
- Использование: Руководство по реализации и подробная логика.
Уровень 3: Примитивные диаграммы
Они редко рисуются, за исключением случаев, когда система чрезвычайно сложна. Они представляют самый низкий уровень детализации, часто соответствующий конкретным модулям кода или ручным процедурам.
🚀 Пошаговое руководство по построению диаграммы потоков данных
Следуйте этому структурированному подходу, чтобы создать надежную диаграмму потоков данных для вашего проекта.
Шаг 1: Определите границы системы
Определите, что находится внутри системы, а что снаружи. Это критически важно для определения, какие сущности внешние, а какие процессы внутренние. Нарисуйте прямоугольник вокруг процессов системы.
Шаг 2: Определите внешние сущности
Перечислите всех людей, организаций или внешних систем, которые будут взаимодействовать с вашей системой. Расположите их за пределами рамки системы. Четко обозначьте их.
Шаг 3: Нарисуйте контекстную диаграмму (уровень 0)
Нарисуйте один круг в центре, представляющий всю систему. Соедините внешние сущности с этим кругом стрелками. Обозначьте стрелки передаваемыми данными (например, «Запрос заказа», «Выслан счет»).
Шаг 4: Разбейте на уровень 1
Расширьте один круг до нескольких процессов. Задайте себе вопрос: «Каковы основные функции этой системы?».
- Определите входные данные.
- Определите выходные данные.
- Определите необходимые хранилища данных.
- Нарисуйте стрелки, соединяющие сущности, процессы и хранилища.
Шаг 5: Примените правила балансировки
Это наиболее важное техническое правило. Входы и выходы родительского процесса должны совпадать с входами и выходами его дочерней диаграммы.
- Если процесс уровня 0 имеет вход «Идентификатор клиента», то дочерний процесс уровня 1 также должен иметь входящий или исходящий «Идентификатор клиента».
- Если процесс уровня 1 генерирует «Данные отчета», то родительский процесс уровня 0 также должен передавать «Данные отчета» внешней сущности.
Шаг 6: Проверка и валидация
Проверьте свою диаграмму на соответствие требованиям.
- Все стрелки обозначены?
- У всех процессов есть входы и выходы?
- Есть ли путь от каждой сущности к хранилищу или процессу?
- Есть ли «спагетти-линии» (линии, пересекающиеся друг с другом без необходимости)?
🏪 Пример сценария: система интернет-магазина
Чтобы проиллюстрировать концепции, давайте пройдемся по упрощенному сценарию интернет-магазина.
Диаграмма контекста (уровень 0)
- Сущность: Покупатель.
- Сущность: Платежный шлюз.
- Сущность: Склад.
- Процесс: Система интернет-магазина.
- Потоки:
- Покупатель ➔ Система: Детали заказа
- Система ➔ Покупатель: Подтверждение заказа
- Система ➔ Платежный шлюз: Информация о платеже
- Платежный шлюз ➔ Система: Статус платежа
- Система ➔ Склад: Запрос на доставку
Разложение на уровне 1
Мы разбиваем «Систему интернет-магазина» на три основных процесса:
- Управление заказами: Получает детали заказа, проверяет наличие товара.
- Обработка платежей: Обрабатывает информацию о кредитной карте, проверяет наличие средств.
- Отправка товаров: Общается со складом.
Хранилища данных
Мы вводим два хранилища данных:
- База данных заказов: Хранит историю и статус заказов.
- База данных инвентаря: Хранит текущие уровни запасов.
На этом диаграмме первого уровня «Управление заказами» записывает в базу данных заказов. «Обработка платежей» читает из базы данных заказов, чтобы подтвердить существование заказа перед списанием средств с карты. «Отгрузка товаров» читает из базы данных инвентаря, чтобы подтвердить наличие товаров перед отправкой запроса на доставку.
⚠️ Распространенные ошибки и ловушки
Даже опытные аналитики допускают ошибки при составлении диаграмм потоков данных. Избегайте этих распространённых ловушек, чтобы обеспечить, что ваши диаграммы остаются корректными и полезными.
- Управление потоками:Не рисуйте стрелки, представляющие сигналы управления (например, «Нажать кнопку», «Сообщение об ошибке»), если они не содержат данных. Диаграммы потоков данных отслеживают данные, а не логику управления.
- Прямые потоки между хранилищами:Данные не могут перемещаться напрямую из одного хранилища данных в другое. Они должны сначала пройти через процесс. Это гарантирует, что будет выполнена трансформация или проверка.
- Непомеченные стрелки:Стрелка без метки не несёт никакой информации. Всегда называйте данные, проходящие по линии.
- Призрачные процессы:Процесс, не имеющий входов или выходов, бесполезен. Каждый элемент должен что-то трансформировать.
- Чрезмерная сложность:Если диаграмма первого уровня содержит более 7–9 процессов, она, скорее всего, слишком детализирована. Разделите её на логические функциональные области.
- Пренебрежение «чёрными дырами»:Процесс, имеющий только входы и не имеющий выходов, называется «чёрной дырой». Он потребляет данные, но ничего не выдаёт.
- Пренебрежение «чудесами»:Процесс, имеющий только выходы и не имеющий входов, называется «чудом». Он создаёт данные из ничего.
📝 Лучшие практики документирования
Создание диаграммы — это только половина работы. Документирование и поддержка гарантируют, что диаграмма потоков данных остаётся полезной в течение длительного времени.
Согласованные правила именования
Используйте стандартный формат для именования процессов и потоков.
- Процессы:Используйте формат глагол-существительное (например, «Проверить пользователя», «Создать отчёт»).
- Потоки:Используйте формат существительного (например, «Учётные данные пользователя», «Отчёт о продажах»).
- Хранилища:Используйте множественное число существительных (например, «Записи клиентов», «Список товаров»).
Цветовая кодировка
Используйте цвета для различения различных типов компонентов или различных уровней абстракции.
- Синий для внешних сущностей.
- Зеленый для процессов.
- Оранжевый для хранилищ данных.
- Красный для критических потоков данных.
Контроль версий
Требования к системе меняются. Ваши диаграммы потоков данных должны отражать эти изменения.
- Назначьте номера версий своим диаграммам (v1.0, v1.1).
- Ведите журнал изменений, фиксируя, что было добавлено, удалено или изменено.
- Архивируйте старые версии, чтобы сохранить следы аудита.
🔗 Интеграция с другими методологиями
Диаграммы потоков данных не существуют изолированно. Они часто являются частью более крупной структурированной аналитической основы.
Диаграммы сущность-связь (ERD)
В то время как диаграммы потоков данных показывают движение данных, диаграммы сущность-связь показывают структуру данных. Когда вы выявляете хранилища данных на своей диаграмме потоков данных, вам часто необходимо разработать таблицы для них с помощью диаграммы сущность-связь. Диаграмма потоков данных показывает, какие данные необходимы; диаграмма сущность-связь показывает, как они структурированы.
Структурированный английский
Для сложных процессов внутри диаграммы потоков данных простая диаграмма может быть недостаточной. Структурированный английский — это сочетание естественного языка и логики программирования, используемое для описания логики внутри процесса.
Словарь данных
Каждый поток данных, хранилище и сущность должны быть определены в словаре данных. Этот документ предоставляет метаданные для диаграммы, включая типы данных, размеры и форматы (например, «ID клиента: целое число, 10 цифр»).
🛠️ Инструменты и выбор программного обеспечения
Для создания диаграммы потоков данных не нужно дорогое программное обеспечение. Акцент должен быть на логике, а не на внешнем виде.
- Доски и маркеры:Отлично подходит для мозгового штурма и первоначальных черновиков с заинтересованными сторонами.
- Бумага и карандаш:Самый быстрый способ протестировать концепцию без ограничений программного обеспечения.
- Общие инструменты рисования:Любой инструмент векторной графики может использоваться для создания чистых цифровых диаграмм.
- Специализированные инструменты анализа:Существует множество специализированных инструментов для системного анализа. Выберите тот, который поддерживает стандартную нотацию диаграмм потоков данных и позволяет вести версионирование.
Независимо от выбранного инструмента, убедитесь, что он позволяет экспортировать диаграммы в стандартном формате для обмена с командой.
🔄 Обслуживание и жизненный цикл
Диаграмма потоков данных — это живой документ. Когда система развивается, диаграмма должна развиваться вместе с ней.
- Запросы на изменение: Когда запрашивается новая функция, обновите диаграмму уровня 1, чтобы увидеть последствия.
- Анализ воздействия: Если процесс изменяется, проверьте, какие другие процессы зависят от его выходных данных. Обновите также эти диаграммы.
- Обзоры кода: Разработчики должны обращаться к DFD при реализации, чтобы убедиться, что код соответствует логике потока данных.
- Тестирование: Тестовые случаи могут быть получены из потоков данных. Если поток существует, должен быть тест для проверки целостности данных по этому пути.
📚 Обзор ключевых принципов
Для краткого изложения основных выводов по созданию эффективных диаграмм потоков данных:
- Начните просто: Начните с диаграммы контекста (уровень 0), чтобы определить границы.
- Постепенно разделяйте: Переходите от уровня 0 к уровню 1 и далее к уровню 2 только при необходимости.
- Строго соблюдайте баланс: Убедитесь, что входы и выходы совпадают между родительским и дочерним уровнями.
- Маркируйте всё: Нет стрелок или процессов без меток.
- Фокусируйтесь на данных: Игнорируйте логику управления; отслеживайте только перемещение данных.
- Проверяйте с заинтересованными сторонами: Обсуждайте диаграммы с бизнес-пользователями, чтобы обеспечить точность.
Следуя этим принципам, вы создаете документ, который служит надежной картой для разработчиков, тестировщиков и бизнес-аналитиков. Четкость вашей диаграммы напрямую связана с эффективностью жизненного цикла разработки системы.
🏁 Заключительные мысли
Овладение искусством диаграммы потоков данных требует практики и дисциплинированного подхода к системному мышлению. Это не просто рисование фигур; это понимание жизненного цикла информации в организации. Когда вы можете проследить данные от их источника до конечного пункта назначения, вы действительно поняли систему.
Используйте это руководство как основу. Практикуйтесь на реальных сценариях, критикуйте свои собственные диаграммы на наличие распространенных ошибок и всегда ставьте ясность выше сложности. Хорошо нарисованная DFD — это молчаливый союзник при создании надежных и устойчивых программных систем.