











एक डेटा फ्लो डायग्राम (DFD) सिस्टम विश्लेषण और डिजाइन में एक मूल दृश्य प्रतिनिधित्व के रूप में कार्य करता है। यह एक सिस्टम के माध्यम से जानकारी के प्रवाह को नक्शा बनाता है, जो डेटा के इनपुट से आउटपुट तक गति को उजागर करता है। नियंत्रण तर्क पर ध्यान केंद्रित करने वाले फ्लोचार्ट्स के विपरीत, DFDs डेटा के गतिशीलता पर ध्यान केंद्रित करते हैं। यह मार्गदर्शिका विशिष्ट निजी उपकरणों पर निर्भरता के बिना सटीक आरेख बनाने की विधि को बताती है। प्रक्रिया में स्पष्ट सोच और स्थापित नोटेशन मानकों का पालन करने की आवश्यकता होती है।
🧐 मूल उद्देश्य को समझना
रेखाओं और आकृतियों को बनाने से पहले, एक को उद्देश्य को समझना चाहिए। एक DFD सिस्टम की क्रियात्मक आवश्यकताओं का मॉडल बनाता है। यह दिखाता है कि सिस्टम क्या करता है, जरूरी नहीं कि इसका भौतिक कार्यान्वयन कैसा है। यह अंतर विश्लेषकों के लिए निर्णायक है। यह स्टेकहोल्डर्स को तकनीकी कार्यान्वयन विवरणों में फंसे बिना व्यापार प्रक्रियाओं की तर्कसंगतता की पुष्टि करने की अनुमति देता है।
आरेख में पहचानने में मदद करता है:
- सिस्टम की सीमाओं के भीतर डेटा कहाँ से उत्पन्न होता है।
- डेटा को उपयोगी जानकारी में कैसे बदला जाता है।
- कहाँ डेटा भविष्य में पुनर्प्राप्ति के लिए संग्रहीत किया जाता है।
- कहाँ डेटा सिस्टम से बाहरी पक्षों को निकलता है।
इन तत्वों को दृश्य रूप से देखकर टीमें विकास चक्र के शुरुआती चरण में बॉटलनेक, अतिरेक या गायब डेटा मार्गों का पता लगा सकती हैं। यह तकनीकी टीमों और व्यापार उपयोगकर्ताओं के बीच संचार का सेतु के रूप में कार्य करता है।
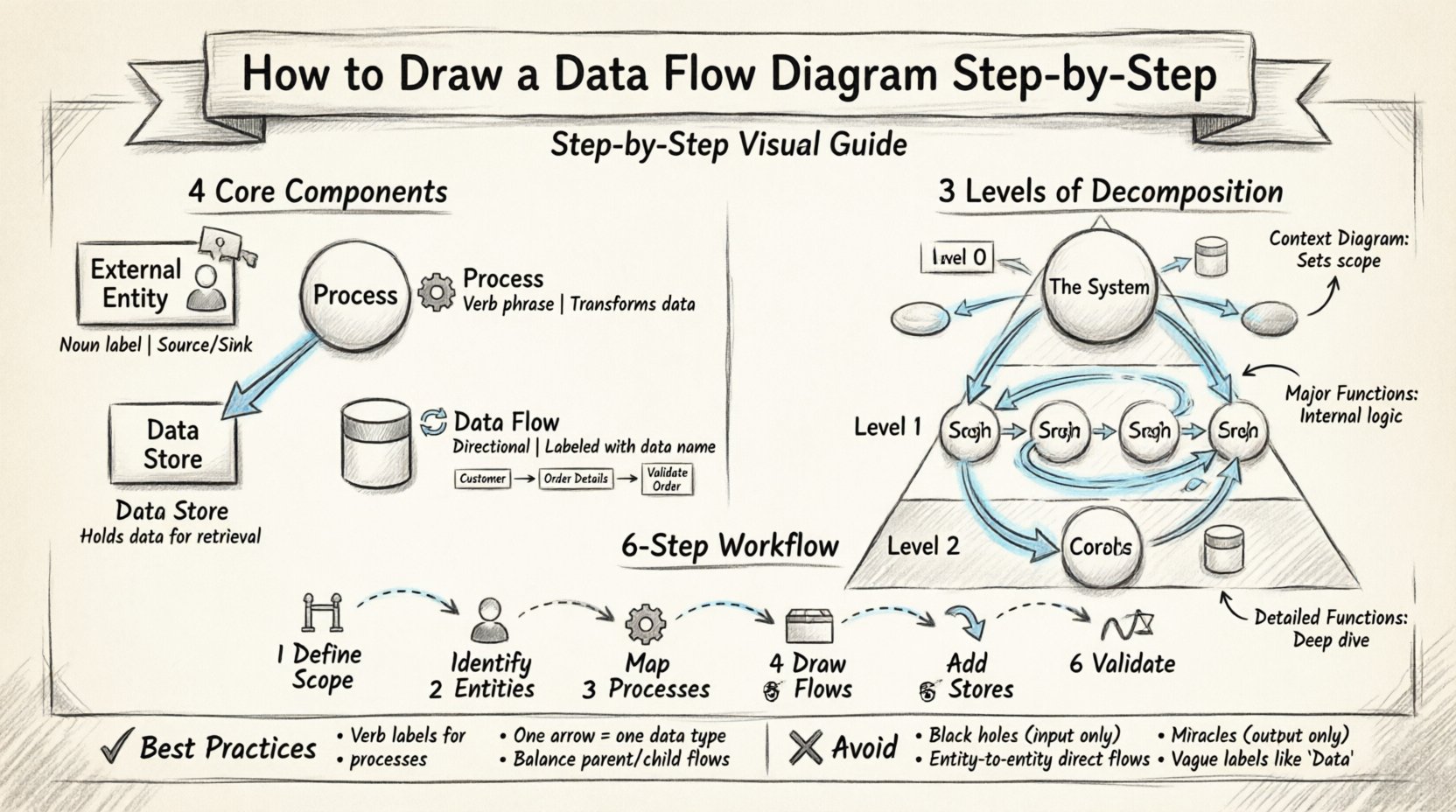
🛠️ चार मूल घटक
एक पूर्ण DFD चार प्रमुख प्रतीकों पर निर्भर करता है। बनाई गई हर तत्व इन श्रेणियों में से एक में आनी चाहिए। किसी अन्य आकृति का उपयोग अस्पष्टता लाता है। मानक नोटेशन आमतौर पर यूरडॉन और डेमार्को विधि या गेन और सर्सन विधि का अनुसरण करता है। इन शैलियों के बीच प्रतीकों में थोड़ा अंतर हो सकता है, लेकिन मूल तर्क समान रहता है।
1. बाहरी एंटिटीज 👤
बाहरी एंटिटीज सिस्टम सीमा के बाहर डेटा के स्रोत या गंतव्य का प्रतिनिधित्व करती हैं। वे उन क्रियाकलापों का प्रतिनिधित्व करती हैं जो सिस्टम के साथ बातचीत करते हैं। इनमें लोग, संगठन या अन्य सिस्टम शामिल हो सकते हैं।
- स्रोत: एक एंटिटी सिस्टम को इनपुट डेटा प्रदान करती है (उदाहरण के लिए, एक ग्राहक आदेश देना)।
- सिंक: एक एंटिटी सिस्टम से आउटपुट डेटा प्राप्त करती है (उदाहरण के लिए, कर अधिकारी रिपोर्ट प्राप्त करना)।
आरेख में, इन्हें आमतौर पर आयत या वर्ग द्वारा दर्शाया जाता है। इन्हें उनके भूमिका को दर्शाने वाले संज्ञा वाक्यांश द्वारा लेबल किया जाता है।
2. प्रक्रियाएँ ⚙️
प्रक्रियाएँ इनपुट डेटा को आउटपुट डेटा में बदलने वाले क्रियाकलापों का प्रतिनिधित्व करती हैं। वे आरेख का केंद्र बिंदु हैं। एक प्रक्रिया के हमेशा कम से कम एक इनपुट और एक आउटपुट होना चाहिए।
- परिवर्तन: यह डेटा के एक रूप से दूसरे रूप में बदलाव करता है (उदाहरण के लिए, कच्ची बिक्री आंकड़ों को सारांश रिपोर्ट में बदलना)।
- लेबलिंग: प्रक्रियाओं को आमतौर पर क्रिया वाक्यांश द्वारा लेबल किया जाता है (उदाहरण के लिए, “कर की गणना करें”, “उपयोगकर्ता की पुष्टि करें”)।
नोटेशन मानक के अनुसार इन्हें आमतौर पर वृत्त, गोल कोने वाले आयत या बबल के रूप में दर्शाया जाता है।
3. डेटा स्टोर्स 📂
डेटा स्टोर्स वह स्थान दर्शाते हैं जहाँ जानकारी बाद में उपयोग के लिए संग्रहीत की जाती है। यह एक भौतिक डेटाबेस फ़ाइल नहीं है, बल्कि एक तार्किक भंडार है। डेटा संग्रहण के लिए स्टोर में प्रवेश करता है और पुनर्प्राप्ति के लिए बाहर निकलता है।
- खुला बनाम बंद: डेटा स्टोर से पढ़ा जा सकता है और उसमें लिखा जा सकता है।
- स्थायित्व: डेटा तब भी उपलब्ध रहता है यदि उसे बनाने वाली प्रक्रिया समाप्त हो गई हो।
सामान्य प्रतीकों में खुले आयताकार या सिलेंडर शामिल हैं जो फाइलों और डेटाबेस का प्रतिनिधित्व करते हैं।
4. डेटा प्रवाह 🔄
डेटा प्रवाह एकताओं, प्रक्रियाओं और भंडारों के बीच डेटा के गति को दर्शाते हैं। वे दिशात्मक त стрेले होते हैं।
- दिशा: तीर उस दिशा में इशारा करता है जिस दिशा में डेटा गति कर रहा है।
- सामग्री: प्रत्येक प्रवाह को स्पष्ट डेटा के साथ लेबल किया जाना चाहिए जो स्थानांतरित किया जा रहा है (उदाहरण के लिए, “आदेश विवरण”, “भुगतान पुष्टि”)।
- सांस्कृतिकता: एक प्रक्रिया के माध्यम से गुजरे बिना दो बाहरी एकताओं के बीच डेटा प्रवाह नहीं हो सकता।
| घटक | प्रतीक आकृति | लेबल प्रकार | कार्य |
|---|---|---|---|
| बाहरी एकता | आयत / वर्ग | संज्ञा | स्रोत या गंतव्य |
| प्रक्रिया | वृत्त / गोल कागज | क्रिया वाक्यांश | डेटा को परिवर्तित करें |
| डेटा भंडार | खुला आयत / सिलेंडर | संज्ञा | डेटा रखें |
| डेटा प्रवाह | तीर | डेटा नाम | डेटा ले जाएँ |
📈 विघटन के स्तर
जटिल प्रणालियों को एक ही दृष्टिकोण में समझा नहीं जा सकता। DFDs पदानुक्रमिक होते हैं। आप एक उच्च स्तर के समीक्षा से शुरू करते हैं और क्रमशः प्रक्रियाओं को अधिक विस्तार में विभाजित करते हैं। इसे विघटन कहा जाता है।
स्तर 0: संदर्भ आरेख 🌍
संदर्भ आरेख सबसे ऊपरी स्तर है। यह पूरी प्रणाली को एकल प्रक्रिया बबल के रूप में दिखाता है। यह दिखाता है कि प्रणाली बाहरी दुनिया के साथ कैसे बातचीत करती है।
- केंद्र में केवल एक प्रक्रिया बनाई गई है।
- बाहरी एकाधिकार प्रक्रिया के चारों ओर होते हैं।
- डेटा प्रवाह एकाधिकारों को एकल प्रक्रिया से जोड़ते हैं।
- इस स्तर पर कोई डेटा भंडार नहीं दिखाए गए हैं।
यह आरेख सीमा तय करता है। यह परियोजना की सीमा को परिभाषित करता है।
स्तर 1: मुख्य प्रक्रियाएँ 🔍
स्तर 1 संदर्भ आरेख से एकल प्रक्रिया को मुख्य उप-प्रक्रियाओं में विस्तारित करता है। यहीं से आंतरिक तर्क दिखना शुरू होता है।
- एकल प्रक्रिया 3 से 7 तक मुख्य प्रक्रियाओं के समूह में बदल जाती है।
- यहाँ डेटा भंडार का परिचय किया जाता है।
- बाहरी एकाधिकार स्तर 0 के समान रहते हैं।
- प्रवाहों को स्तर 0 के इनपुट और आउटपुट के साथ संतुलित रहना चाहिए।
स्तर 2: विस्तृत कार्यों 🔬
स्तर 2 स्तर 1 से विशिष्ट प्रक्रियाओं को विभाजित करता है। इसका उपयोग जटिल संचालनों के लिए किया जाता है जिनकी आगे व्याख्या की आवश्यकता होती है।
- पिछले स्तर की एकल प्रक्रिया पर ध्यान केंद्रित करता है।
- विस्तृत तर्क और उप-चरण दिखाता है।
- जब स्तर 1 की प्रक्रिया एक ही दृश्य में प्रबंधित करने के लिए बहुत जटिल होती है, तब इसका उपयोग किया जाता है।
| स्तर | ध्यान केंद्र | प्रक्रियाएँ | डेटा भंडार |
|---|---|---|---|
| स्तर 0 | प्रणाली की सीमा | 1 (प्रणाली) | कोई नहीं |
| स्तर 1 | मुख्य कार्य | 3 से 7 | हाँ |
| स्तर 2 | विशिष्ट विवरण | स्तर 1 पर निर्भर | हाँ |
✍️ चरण-दर-चरण ड्राइंग विधि
DFD बनाने के लिए एक संरचित दृष्टिकोण की आवश्यकता होती है। इन चरणों का पालन करने से दस्तावेजीकरण के दौरान सुसंगतता और स्पष्टता सुनिश्चित होती है।
चरण 1: सीमा और सीमा को परिभाषित करें 🚧
सबसे पहले यह पहचानें कि सिस्टम के अंदर क्या है और बाहर क्या है। इस निर्णय बाहरी एकाधिकारों के स्थान को निर्धारित करता है। सीमा के बाहर सब कुछ एक बाहरी एकाधिकार है। सीमा के अंदर सब कुछ एक प्रक्रिया, स्टोर या प्रवाह है। यहाँ हार्डवेयर या कोड जैसी कार्यान्वयन विवरणों को शामिल न करें।
चरण 2: बाहरी एकाधिकारों की पहचान करें 👥
सिस्टम से बातचीत करने वाले सभी पक्षों की सूची बनाएं। निम्न प्रश्न पूछें:
- सिस्टम को कौन सूचना भेजता है?
- सिस्टम से रिपोर्ट या आउटपुट कौन प्राप्त करता है?
- क्या इसके साथ डेटा का आदान-प्रदान करने वाले अन्य सिस्टम हैं?
इन एकाधिकारों को अपने कार्यस्थल के परिधि के चारों ओर बनाएं। स्पष्ट, वर्णनात्मक नामों का उपयोग करें।
चरण 3: मुख्य प्रक्रियाओं का निर्धारण करें ⚙️
प्राप्त डेटा को आउटपुट में बदलने के लिए सिस्टम द्वारा किए जाने वाले मुख्य कार्यों की पहचान करें। संबंधित गतिविधियों को समूहित करें। उदाहरण के लिए, “आदेश प्रबंधन” एक मुख्य प्रक्रिया हो सकती है जिसमें “आदेश की पुष्टि” और “इन्वेंटरी को अपडेट करना” उप-प्रक्रियाओं के रूप में शामिल हो सकते हैं।
- प्रक्रियाओं की संख्या प्रबंधनीय रखें (स्तर 1 के लिए आदर्श रूप से 7 से कम)।
- यह सुनिश्चित करें कि प्रत्येक प्रक्रिया का स्पष्ट उद्देश्य हो।
- प्रक्रियाओं को क्रियाओं के साथ लेबल करें (उदाहरण के लिए, “भुगतान प्रक्रिया”)।
चरण 4: डेटा प्रवाह को मैप करें 🔄
एकाधिकारों को प्रक्रियाओं और प्रक्रियाओं को प्रक्रियाओं से जोड़ने वाली तीर बनाएं। प्रत्येक तीर को डेटा का वर्णन करने वाला लेबल होना चाहिए।
- यह जांचें कि डेटा तार्किक रूप से आगे बढ़ रहा है।
- यह सुनिश्चित करें कि कोई भी प्रवाह सिस्टम की सीमा को बिना किसी प्रक्रिया से गुजरे के पार नहीं करता है।
- प्रवाह को विशिष्ट डेटा पैकेट के साथ लेबल करें (उदाहरण के लिए, “ग्राहक आईडी”, केवल “डेटा” नहीं)।
चरण 5: डेटा स्टोर को जोड़ें 📂
यह पहचानें कि जानकारी कहाँ रखी जानी चाहिए। यदि बाद में डेटा की आवश्यकता हो, तो उसे स्टोर में जाना चाहिए।
- स्टोर को उन प्रक्रियाओं से जोड़ें जो उन्हें पढ़ती या लिखती हैं।
- सुनिश्चित करें कि डेटा एक स्टोर में प्रवेश करे ताकि इसे सहेजा जा सके।
- सुनिश्चित करें कि डेटा एक स्टोर से बाहर निकले ताकि इसका उपयोग किया जा सके।
चरण 6: प्रमाणीकरण और संतुलन ⚖️
यह सबसे महत्वपूर्ण तकनीकी चरण है। संतुलन सुनिश्चित करता है कि एक मातृ प्रक्रिया के इनपुट और आउटपुट उसके बच्चे डायग्राम (अगले नीचे के स्तर) के इनपुट और आउटपुट के मेल खाते हैं।
- यदि स्तर 0 का इनपुट “आदेश” है, तो स्तर 1 में भी “आदेश” के मुख्य प्रक्रिया में प्रवेश करना दिखाना चाहिए।
- यदि स्तर 1 एक प्रक्रिया को विभाजित करता है, तो उप-प्रक्रियाओं को मातृ प्रक्रिया के समान डेटा इनपुट और आउटपुट को संभालना चाहिए।
- अनाथ प्रक्रियाओं (बिना डेटा प्रवाह वाली प्रक्रियाओं) के लिए जांच करें।
- अनाथ डेटा स्टोर्स (बिना डेटा प्रवाह वाले स्टोर्स) के लिए जांच करें।
🧠 सर्वोत्तम प्रथाएं और नियम
कठोर नियमों का पालन करने से भ्रम से बचा जा सकता है। विचलन सिस्टम तर्क के गलत व्याख्यान की ओर जा सकते हैं।
1. नामकरण प्रथाएं 🏷️
सुसंगतता महत्वपूर्ण है। सभी तत्वों के लिए एक मानक नामकरण प्रथा का उपयोग करें।
- संस्थाएं: बहुवचन संज्ञा (उदाहरण के लिए, “ग्राहक”, “आपूर्तिकर्ता”)।
- प्रक्रियाएं: क्रिया वाक्यांश (उदाहरण के लिए, “इन्वेंटरी अपडेट करें”)।
- स्टोर्स: संज्ञा (उदाहरण के लिए, “इन्वेंटरी फ़ाइल”)।
- प्रवाह: डेटा के नाम (उदाहरण के लिए, “स्टॉक अपडेट”)।
2. नियंत्रण तर्क से बचें 🚫
DFD प्रवाहचित्र नहीं हैं। नियंत्रण प्रवाह का प्रतिनिधित्व करने वाले निर्णय हीरे या लूप शामिल न करें। यदि एक निर्णय डेटा प्रवाह को प्रभावित करता है, तो इसे तर्क स्थिति के बजाय डेटा सामग्री के आधार पर अलग-अलग पथों में प्रवाह को विभाजित करके दर्शाएं।
3. एक तीर, एक डेटा पैकेट
एक ही तीर में एक से अधिक प्रकार के डेटा को मिलाएं नहीं। यदि एक प्रक्रिया “आदेश डेटा” और “भुगतान डेटा” दोनों भेजती है, तो दो अलग-अलग तीर खींचें।
4. सीधे संस्था-से-संस्था प्रवाह नहीं
डेटा एक बाहरी संस्था से दूसरी बाहरी संस्था में सिस्टम के माध्यम से गुजरे बिना सीधे नहीं जा सकता है। यदि ऐसा होता है, तो इसका मतलब है कि सिस्टम को बायपास किया गया है, या डायग्राम का दायरा गलत है।
5. काले छेद और चमत्कार से बचें
- काला छेद: एक प्रक्रिया जिसमें इनपुट हैं लेकिन आउटपुट नहीं हैं। डेटा गायब हो जाता है। यह असंभव है।
- चमत्कार: एक प्रक्रिया जिसमें आउटपुट हैं लेकिन इनपुट नहीं हैं। डेटा कहीं से भी उपस्थित हो जाता है। यह असंभव है।
⚠️ बचने के लिए आम गलतियां
यहां तक कि अनुभवी विश्लेषक भी गलतियां करते हैं। आम जाल में फंसने से बचने के लिए जागरूक रहना समीक्षा के दौरान समय बचाता है।
गलती 1: स्तरों को मिलाना
एक ही पृष्ठ पर स्तर 0 और स्तर 1 की जानकारी को मिलाने से भ्रम उत्पन्न होता है। स्पष्टता बनाए रखने के लिए प्रत्येक स्तर को अलग रखें।
गलती 2: असंगत प्रवाह दिशा
यह सुनिश्चित करें कि तीर सही दिशा में इशारा करें। एक सामान्य गलती यह है कि भंडार से प्रक्रिया की ओर तीर खींचना, जबकि प्रक्रिया वास्तव में डेटा को भंडार में लिख रही है।
गलती 3: अस्पष्ट लेबल
“जानकारी”, “डेटा”, या “विवरण” जैसे लेबल से बचें। विशिष्ट हों। “ग्राहक विवरण” बेहतर है। “डेटा” विश्लेषण के लिए बेकार है।
गलती 4: डेटा स्टोर को नजरअंदाज करना
डेटा स्टोर को छोड़ने से अपूर्ण मॉडल बनता है। यदि डेटा बाद में उपयोग किया जाता है, तो उसे स्टोर करना आवश्यक है। स्टोर को शामिल न करने का मतलब है कि प्रणाली राज्यहीन है, जो जटिल एप्लिकेशन के लिए दुर्लभ है।
🔍 उन्नत विचारधाराएं
जैसे-जैसे प्रणालियां बढ़ती हैं, DFD को अधिक सख्त रखरखाव की आवश्यकता होती है। बड़े प्रोजेक्ट्स के लिए निम्नलिखित पर विचार करें।
भौतिक बनाम तार्किक DFD
- तार्किक DFD: व्यापार आवश्यकताओं पर केंद्रित है। यह कागजी फाइलों बनाम डेटाबेस जैसी तकनीकी कार्यान्वयन विवरणों को नजरअंदाज करता है।
- भौतिक DFD: वास्तविक कार्यान्वयन को दर्शाता है। यह हार्डवेयर, सॉफ्टवेयर और फाइल प्रकारों को निर्दिष्ट करता है।
सबसे अच्छी प्रथा यह है कि पहले तार्किक DFD बनाएं ताकि आवश्यकताओं पर सहमति बने, फिर विकास के लिए भौतिक DFD निर्मित करें।
समानांतरता और समय
मानक DFD में समय या समानांतरता नहीं दिखाई जाती है। वे यह दिखाते हैं कि क्या होता है, न कि कब। जहां समय की आवश्यकता आवश्यक हो, DFD के साथ-साथ अन्य मॉडलिंग तकनीकों जैसे राज्य संक्रमण आरेख की आवश्यकता हो सकती है।
सुरक्षा और पहुंच नियंत्रण
हालांकि DFD सुरक्षा प्रोटोकॉल को स्पष्ट रूप से नहीं दिखाते हैं, डेटा प्रवाहों में संवेदनशील जानकारी को इंगित करना चाहिए। “पासवर्ड” या “क्रेडिट कार्ड नंबर” वाले प्रवाहों को नोट करना चाहिए। इससे सुरक्षा वार्डों को यह पहचानने में मदद मिलती है कि एन्क्रिप्शन की आवश्यकता कहां है।
📝 प्रवाह का सारांश
डेटा प्रवाह आरेख बनाना प्रणालीगत सोच का एक अनुशासित अभ्यास है। इसमें जटिल प्रणाली को प्रबंधन योग्य भागों में बांटने की आवश्यकता होती है, जबकि डेटा के आवागमन की अखंडता बनाए रखी जाती है। प्रक्रिया संदर्भ आरेख के विशाल दृष्टिकोण से विस्तृत प्रक्रियाओं के सूक्ष्म दृष्टिकोण तक जाती है।
सफलता पर निर्भर करता है:
- सीमाओं की स्पष्ट पहचान।
- घटकों के स्थिर लेबलिंग।
- संतुलन नियमों का कठोर अनुपालन।
- हितधारकों के साथ पुष्टि।
इन चरणों का पालन करने और सामान्य त्रुटियों से बचने से आप प्रणाली विकास के लिए एक विश्वसनीय नक्शा बनाते हैं। यह दस्तावेज डेटाबेस डिजाइन, सॉफ्टवेयर आर्किटेक्चर और प्रक्रिया सुधार पहलों के लिए आधार बनता है। यह किसी भी संगठित प्रणाली में जानकारी के प्रवाह को समझने के लिए एक सदाशय उपकरण बना रहता है।