











Un diagramme de flux de données (DFD) constitue une représentation visuelle fondamentale dans l’analyse et la conception des systèmes. Il cartographie le flux d’information à travers un système, mettant en évidence la manière dont les données circulent du point d’entrée au point de sortie. Contrairement aux organigrammes qui se concentrent sur la logique de contrôle, les DFD se concentrent sur le déplacement des données. Ce guide décrit la méthodologie pour construire des diagrammes précis sans dépendre d’outils propriétaires spécifiques. Le processus exige une réflexion claire et le respect des normes établies de notation.
🧐 Comprendre le but fondamental
Avant de dessiner des lignes et des formes, il faut comprendre l’objectif. Un DFD modélise les exigences fonctionnelles d’un système. Il montre ce que le système fait, et non nécessairement comment il est physiquement mis en œuvre. Cette distinction est cruciale pour les analystes. Elle permet aux parties prenantes de valider la logique des processus métiers sans s’embrouiller dans les détails techniques de mise en œuvre.
Le diagramme aide à identifier :
- D’où proviennent les données à l’intérieur des limites du système.
- Comment les données sont transformées en informations utiles.
- Où les données sont stockées pour une récupération ultérieure.
- Où les données quittent le système pour des parties externes.
En visualisant ces éléments, les équipes peuvent détecter les goulets d’étranglement, les redondances ou les chemins de données manquants dès les premières étapes du cycle de développement. Il agit comme un pont de communication entre les équipes techniques et les utilisateurs métiers.
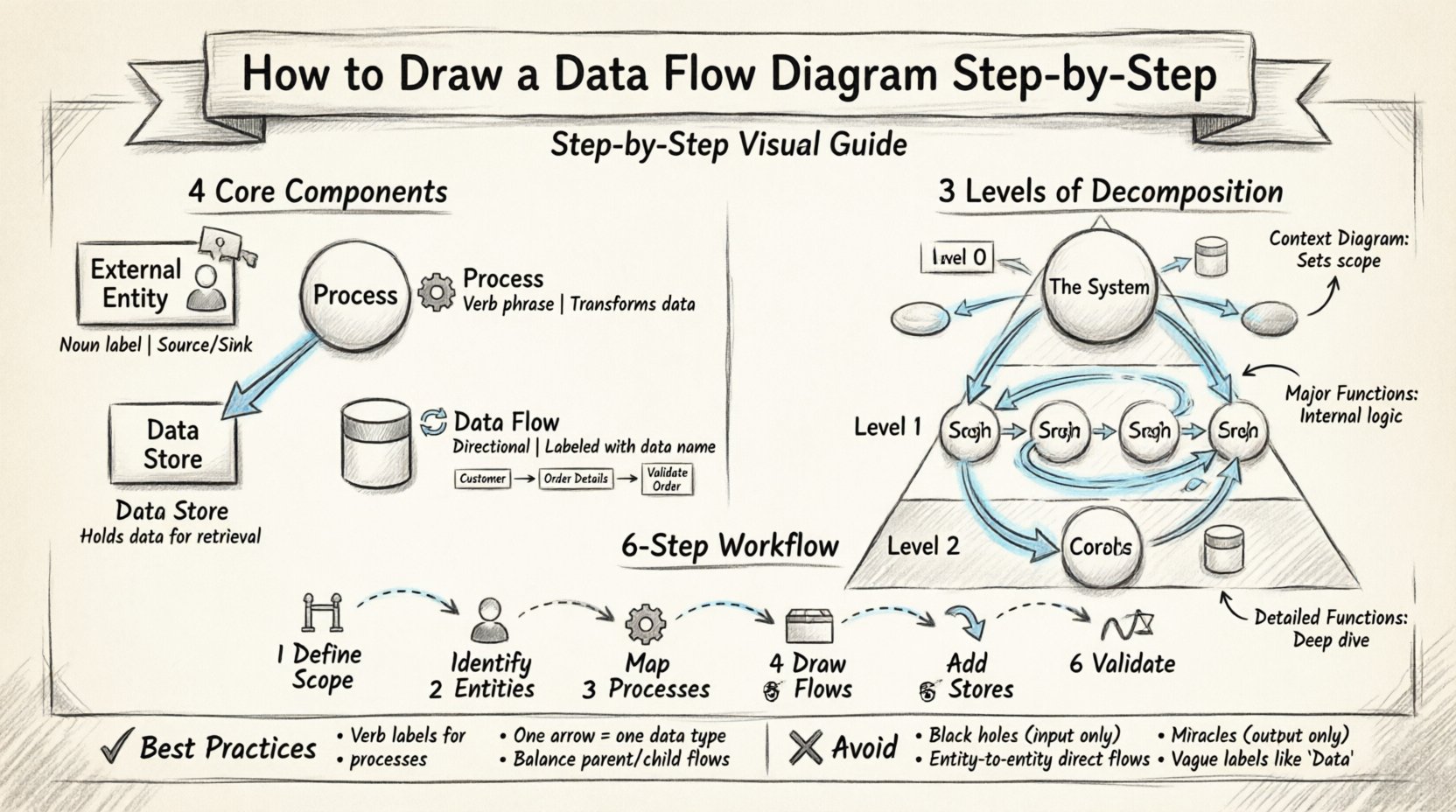
🛠️ Les quatre composants fondamentaux
Un DFD complet repose sur quatre symboles principaux. Chaque élément dessiné doit appartenir à l’une de ces catégories. Utiliser une autre forme introduit de l’ambiguïté. La notation standard suit généralement soit la méthode Yourdon & DeMarco, soit la méthode Gane & Sarson. Bien que les symboles puissent varier légèrement entre ces styles, la logique sous-jacente reste identique.
1. Entités externes 👤
Les entités externes représentent les sources ou destinations des données situées à l’extérieur des limites du système. Ce sont les acteurs interagissant avec le système. Il peut s’agir de personnes, d’organisations ou d’autres systèmes.
- Source : L’entité fournit des données d’entrée au système (par exemple, un client passant une commande).
- Puisard : L’entité reçoit des données de sortie du système (par exemple, une autorité fiscale recevant des rapports).
Dans un diagramme, ils sont généralement représentés par des rectangles ou des carrés. Ils sont étiquetés par une expression nominale indiquant leur rôle.
2. Processus ⚙️
Les processus représentent des actions qui transforment les données d’entrée en données de sortie. Ce sont le cœur du diagramme. Un processus doit toujours avoir au moins une entrée et une sortie.
- Transformation : Il transforme les données d’une forme à une autre (par exemple, convertir les chiffres bruts de ventes en un rapport récapitulatif).
- Étiquetage : Les processus sont généralement étiquetés par une expression verbale (par exemple, « Calculer la taxe », « Valider l’utilisateur »).
Ils sont souvent représentés par des cercles, des rectangles arrondis ou des bulles, selon la norme de notation utilisée.
3. Magasins de données 📂
Les magasins de données représentent l’emplacement où les informations sont sauvegardées pour une utilisation ultérieure. Ce n’est pas un fichier de base de données physique, mais un dépôt logique. Les données circulent vers le magasin pour être stockées et en sortent pour être récupérées.
- Ouvert vs. Fermé :Les données peuvent être lues depuis et écrites dans le magasin.
- Persistence : Les données restent disponibles même si le processus qui les a créées s’est terminé.
Les symboles courants incluent des rectangles ou des cylindres ouverts représentant des fichiers et des bases de données.
4. Flux de données 🔄
Les flux de données montrent le déplacement des données entre les entités, les processus et les stocks. Ce sont des flèches directionnelles.
- Direction : La flèche indique la direction du déplacement des données.
- Contenu : Chaque flux doit être étiqueté avec les données spécifiques transmises (par exemple, « Détails de la commande », « Confirmation de paiement »).
- Consistance : Les données ne peuvent pas circuler entre deux entités externes sans passer par un processus.
| Composant | Forme du symbole | Type d’étiquette | Fonction |
|---|---|---|---|
| Entité externe | Rectangle / Carré | Nom | Source ou destination |
| Processus | Cercle / Boîte arrondie | Phrase verbale | Transformer les données |
| Stockage de données | Rectangle ouvert / Cylindre | Nom | Stocker les données |
| Flux de données | Flèche | Nom des données | Déplacer les données |
📈 Niveaux de décomposition
Les systèmes complexes ne peuvent pas être compris en une seule vue. Les diagrammes de flux de données sont hiérarchiques. Vous commencez par un aperçu de haut niveau et décomposez progressivement les processus en plus de détails. Cela s’appelle la décomposition.
Niveau 0 : Diagramme de contexte 🌍
Le diagramme de contexte est le niveau le plus élevé. Il représente l’ensemble du système sous la forme d’une seule bulle de processus. Il illustre la manière dont le système interagit avec le monde extérieur.
- Un seul processus est dessiné au centre.
- Les entités externes entourent le processus.
- Les flux de données relient les entités au processus unique.
- Aucun stockage de données n’est représenté à ce niveau.
Ce diagramme définit le périmètre. Il détermine la frontière du projet.
Niveau 1 : Processus majeurs 🔍
Le niveau 1 étend le processus unique du diagramme de contexte en sous-processus majeurs. C’est ici que la logique interne commence à apparaître.
- Le processus unique devient un groupe de 3 à 7 processus majeurs.
- Les stockages de données sont introduits ici.
- Les entités externes restent les mêmes que au niveau 0.
- Les flux doivent être équilibrés avec les entrées et sorties du niveau 0.
Niveau 2 : Fonctions détaillées 🔬
Le niveau 2 décompose des processus spécifiques du niveau 1. Cela est utilisé pour des opérations complexes nécessitant une explication supplémentaire.
- Se concentre sur un seul processus du niveau précédent.
- Montre la logique détaillée et les sous-étapes.
- Utilisé lorsque un processus du niveau 1 est trop complexe pour être géré en une seule vue.
| Niveau | Focus | Processus | Stockages de données |
|---|---|---|---|
| Niveau 0 | Périmètre du système | 1 (Le système) | Aucun |
| Niveau 1 | Fonctions principales | 3 à 7 | Oui |
| Niveau 2 | Détails spécifiques | Dépend du niveau 1 | Oui |
✍️ Méthodologie de dessin étape par étape
La création d’un DFD nécessite une approche structurée. Suivre ces étapes garantit la cohérence et la clarté tout au long de la documentation.
Étape 1 : Définir le périmètre et la frontière 🚧
Commencez par identifier ce qui se trouve à l’intérieur du système et ce qui se trouve à l’extérieur. Cette décision détermine le positionnement des entités externes. Tout ce qui est à l’extérieur de la frontière est une entité externe. Tout ce qui est à l’intérieur est un processus, un stockage ou un flux. N’incluez pas ici les détails d’implémentation tels que le matériel ou le code.
Étape 2 : Identifier les entités externes 👥
Listez toutes les parties qui interagissent avec le système. Posez des questions telles que :
- Qui envoie des informations au système ?
- Qui reçoit des rapports ou des sorties du système ?
- Y a-t-il d’autres systèmes qui échangent des données avec celui-ci ?
Représentez ces entités autour du périmètre de votre espace de travail. Utilisez des noms clairs et descriptifs.
Étape 3 : Déterminer les processus principaux ⚙️
Identifiez les fonctions principales que le système doit effectuer pour transformer les entrées en sorties. Regroupez les activités connexes. Par exemple, « Gestion des commandes » pourrait être un processus principal comprenant « Valider la commande » et « Mettre à jour le stock » comme sous-processus.
- Maintenez le nombre de processus gérable (idéalement inférieur à 7 au niveau 1).
- Assurez-vous que chaque processus a un objectif clair.
- Nommez les processus avec des verbes (par exemple, « Traiter le paiement »).
Étape 4 : Cartographier les flux de données 🔄
Tracez des flèches reliant les entités aux processus et les processus aux processus. Chaque flèche doit être étiquetée pour décrire les données.
- Vérifiez que les données se déplacent de manière logique.
- Assurez-vous qu’aucun flux ne traverse la frontière du système sans passer par un processus.
- Étiquetez les flux avec le paquet de données spécifique (par exemple, « ID client », et non seulement « Données »).
Étape 5 : Ajouter des magasins de données 📂
Identifiez où les informations doivent être conservées. Si des données sont nécessaires ultérieurement, elles doivent être stockées.
- Connectez les magasins aux processus qui les lisent ou écrivent.
- Assurez-vous que les données circulent vers un magasin pour les sauvegarder.
- Assurez-vous que les données sortent d’un magasin pour les utiliser.
Étape 6 : Valider et équilibrer ⚖️
Il s’agit de la étape technique la plus critique. L’équilibrage garantit que les entrées et sorties d’un processus parent correspondent aux entrées et sorties de son diagramme enfant (le niveau suivant en dessous).
- Si le niveau 0 possède une entrée « Commande », le niveau 1 doit également montrer « Commande » entrant dans le processus principal.
- Si le niveau 1 divise un processus, les sous-processus doivent gérer les mêmes entrées et sorties de données que le processus parent.
- Vérifiez les processus orphelins (processus sans flux de données).
- Vérifiez les magasins de données orphelins (magasins sans flux de données entrant ou sortant).
🧠 Meilleures pratiques et règles
Le respect de règles strictes évite toute confusion. Les écarts peuvent entraîner une mauvaise interprétation de la logique du système.
1. Conventions de nommage 🏷️
La cohérence est essentielle. Utilisez une convention de nommage standard pour tous les éléments.
- Entités : noms pluriels (par exemple, « Clients », « Fournisseurs »).
- Processus : phrases verbales (par exemple, « Mettre à jour l’inventaire »).
- Magasins : noms (par exemple, « Fichier d’inventaire »).
- Flux : noms des données (par exemple, « Mise à jour du stock »).
2. Évitez la logique de contrôle 🚫
Les diagrammes de flux de données ne sont pas des organigrammes. N’incluez pas de losanges de décision ou de boucles représentant un flux de contrôle. Si une décision affecte le flux de données, représentez-la en divisant le flux en chemins différents basés sur le contenu des données, et non sur la condition logique elle-même.
3. Un flèche, un paquet de données
Ne combinez pas plusieurs types de données dans une seule flèche. Si un processus envoie à la fois « Données de commande » et « Données de paiement », dessinez deux flèches distinctes.
4. Pas de flux direct entre entités
Les données ne peuvent pas se déplacer directement d’une entité externe à une autre sans passer par le système. Si cela se produit, cela signifie que le système est contourné, ou que la portée du diagramme est incorrecte.
5. Évitez les trous noirs et les miracles
- Trou noir : Un processus qui a des entrées mais aucune sortie. Les données disparaissent. Cela est impossible.
- Miracle : Un processus qui a des sorties mais aucune entrée. Les données apparaissent de nulle part. Cela est impossible.
⚠️ Erreurs courantes à éviter
Même les analystes expérimentés commettent des erreurs. Être conscient des pièges courants permet de gagner du temps lors des revues.
Erreur 1 : Mélange des niveaux
Combiner les détails du niveau 0 et du niveau 1 sur la même page crée du désordre. Gardez chaque niveau séparé pour maintenir la clarté.
Erreur 2 : Direction du flux incohérente
Assurez-vous que les flèches pointent dans la bonne direction. Une erreur courante consiste à dessiner une flèche du magasin vers le processus alors que le processus écrit en réalité des données dans le magasin.
Erreur 3 : Libellés flous
Évitez les libellés comme « Info », « Données » ou « Détails ». Soyez précis. « Détails du client » est préférable. « Données » est inutile pour l’analyse.
Erreur 4 : Ignorer les magasins de données
Sauter les magasins de données conduit à un modèle incomplet. Si les données sont utilisées ultérieurement, elles doivent être stockées. L’omission des magasins implique un système sans état, ce qui est rarement exact pour les applications complexes.
🔍 Considérations avancées
À mesure que les systèmes grandissent, les diagrammes de flux de données nécessitent une maintenance plus rigoureuse. Prenez en compte les éléments suivants pour les projets plus importants.
Diagrammes physiques vs. diagrammes logiques
- Diagramme logique : Se concentre sur les exigences métiers. Il ignore les détails d’implémentation techniques tels que les fichiers papier par rapport aux bases de données.
- Diagramme physique : Représente l’implémentation réelle. Il précise le matériel, le logiciel et les types de fichiers.
Il est de bonne pratique de créer d’abord le diagramme logique pour convenir des exigences, puis d’en déduire le diagramme physique pour le développement.
Concurrence et temporisation
Les diagrammes de flux de données standards ne montrent ni le temps ni la concurrence. Ils montrent ce qui se produit, pas quand. Pour les systèmes où le timing est critique, d’autres techniques de modélisation comme les diagrammes de transition d’état peuvent être nécessaires en complément des diagrammes de flux de données.
Sécurité et contrôle d’accès
Bien que les diagrammes de flux de données ne montrent pas explicitement les protocoles de sécurité, les flux de données doivent indiquer les informations sensibles. Les flux contenant « Mot de passe » ou « Numéro de carte de crédit » doivent être signalés. Cela aide les architectes de sécurité à identifier où le chiffrement est nécessaire.
📝 Résumé du flux de travail
La construction d’un diagramme de flux de données est un exercice rigoureux de pensée systémique. Elle exige de décomposer un système complexe en parties gérables tout en maintenant l’intégrité du déplacement des données. Le processus va de la vue d’ensemble du diagramme de contexte à la vue détaillée des processus.
Le succès dépend de :
- Identification claire des limites.
- Libellés cohérents des composants.
- Respect strict des règles d’équilibre.
- Validation auprès des parties prenantes.
En suivant ces étapes et en évitant les pièges courants, vous créez un plan fiable pour le développement du système. Ce document sert de fondement à la conception de bases de données, à l’architecture logicielle et aux initiatives d’amélioration des processus. Il reste un outil intemporel pour comprendre comment l’information circule à travers tout système organisé.