











Диаграмма потока данных (DFD) служит основным визуальным представлением при анализе и проектировании систем. Она отображает поток информации через систему, подчеркивая, как данные перемещаются от входа к выходу. В отличие от блок-схем, которые фокусируются на логике управления, DFD сосредоточены на перемещении данных. В этом руководстве описывается методология построения точных диаграмм без использования специфических проприетарных инструментов. Процесс требует ясного мышления и соблюдения установленных стандартов нотации.
🧐 Понимание основной цели
Прежде чем рисовать линии и фигуры, необходимо понимать цель. DFD моделирует функциональные требования системы. Она показывает, что делает система, а не обязательно, как она физически реализована. Это различие имеет решающее значение для аналитиков. Оно позволяет заинтересованным сторонам проверить логику бизнес-процессов, не вдаваясь в технические детали реализации.
Диаграмма помогает выявить:
- Откуда данные поступают внутри границ системы.
- Как данные преобразуются в полезную информацию.
- Где данные хранятся для последующего извлечения.
- Где данные покидают систему и передаются внешним сторонам.
Визуализируя эти элементы, команды могут выявить узкие места, избыточность или отсутствующие пути передачи данных на ранних этапах жизненного цикла разработки. Она выступает в качестве коммуникационного моста между техническими командами и бизнес-пользователями.
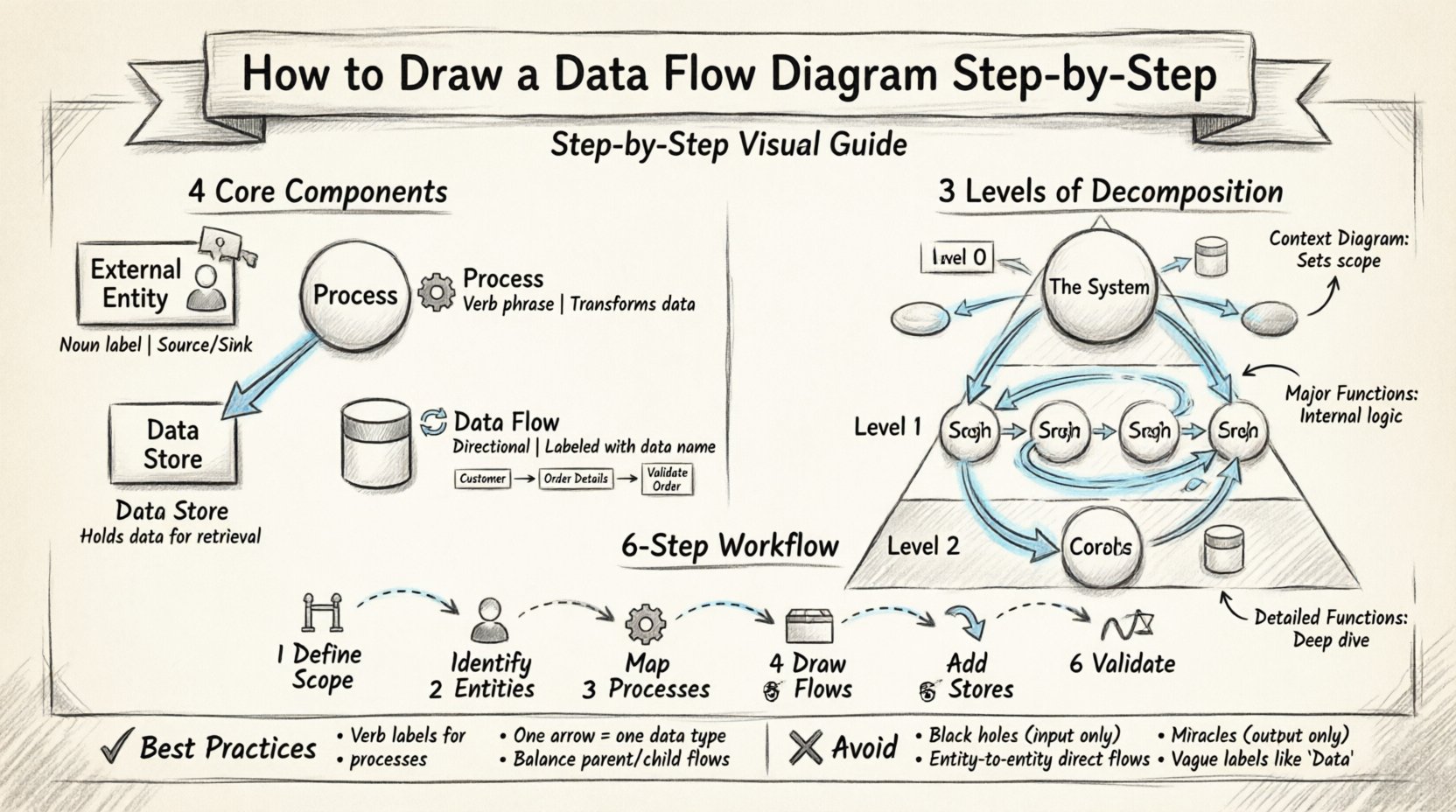
🛠️ Четыре основных компонента
Полная DFD опирается на четыре основных символа. Каждый элемент, нарисованный на диаграмме, должен относиться к одной из этих категорий. Использование любой другой формы вводит неоднозначность. Стандартная нотация обычно следует либо методу Юрдона и Демарко, либо методу Гейна и Сарсона. Хотя символы могут незначительно отличаться между этими стилями, лежащая в основе логика остается одинаковой.
1. Внешние сущности 👤
Внешние сущности представляют источники или пункты назначения данных за пределами границ системы. Это акторы, взаимодействующие с системой. К ним могут относиться люди, организации или другие системы.
- Источник: Сущность поставляет входные данные в систему (например, клиент размещает заказ).
- Приемник: Сущность получает выходные данные из системы (например, налоговая инспекция получает отчеты).
На диаграмме они обычно изображаются прямоугольниками или квадратами. Они помечаются существительными, указывающими на их роль.
2. Процессы ⚙️
Процессы представляют действия, преобразующие входные данные в выходные. Они являются сердцем диаграммы. Процесс всегда должен иметь хотя бы один вход и один выход.
- Преобразование: Оно изменяет данные с одной формы на другую (например, преобразование исходных данных о продажах в сводный отчет).
- Метки: Процессы обычно помечаются глагольной фразой (например, «Рассчитать налог», «Проверить пользователя»).
Они часто изображаются в виде кругов, закругленных прямоугольников или пузырей в зависимости от стандарта нотации.
3. Хранилища данных 📂
Хранилища данных представляют собой места, где информация сохраняется для последующего использования. Это не физический файл базы данных, а логическое хранилище. Данные поступают в хранилище для хранения и выходят из него для извлечения.
- Открытое vs. Закрытое: Данные могут как читаться из хранилища, так и записываться в него.
- Сохранность: Данные остаются доступными даже если процесс, который их создал, завершился.
Распространенные символы включают прямоугольники с открытым концом или цилиндры, представляющие файлы и базы данных.
4. Потоки данных 🔄
Потоки данных показывают перемещение данных между сущностями, процессами и хранилищами. Это направленные стрелки.
- Направление: Стрелка указывает в направлении движения данных.
- Содержание: Каждый поток должен быть помечен конкретными данными, передаваемыми (например, «Сведения о заказе», «Подтверждение оплаты»).
- Согласованность: Данные не могут перемещаться между двумя внешними сущностями без прохождения через процесс.
| Компонент | Форма символа | Тип метки | Функция |
|---|---|---|---|
| Внешняя сущность | Прямоугольник / Квадрат | Существительное | Источник или назначение |
| Процесс | Окружность / Скруглённый прямоугольник | Глагольная фраза | Преобразовать данные |
| Хранилище данных | Прямоугольник с открытым концом / Цилиндр | Существительное | Хранить данные |
| Поток данных | Стрелка | Имя данных | Переместить данные |
📈 Уровни декомпозиции
Сложные системы нельзя понять в одном представлении. Диаграммы потоков данных являются иерархическими. Вы начинаете с общего обзора высокого уровня и постепенно разбиваете процессы на более подробные детали. Это называется декомпозицией.
Уровень 0: Диаграмма контекста 🌍
Диаграмма контекста — это самый высокий уровень. Она показывает всю систему как один элемент процесса. Она иллюстрирует, как система взаимодействует с внешним миром.
- В центре изображается только один процесс.
- Внешние сущности окружают процесс.
- Потоки данных соединяют сущности с единственным процессом.
- На этом уровне не показываются хранилища данных.
Эта диаграмма определяет границы проекта. Она задает рамки проекта.
Уровень 1: Основные процессы 🔍
Уровень 1 расширяет единственный процесс из диаграммы контекста до основных подпроцессов. Именно здесь начинает проявляться внутренняя логика.
- Единственный процесс превращается в группу из 3–7 основных процессов.
- Здесь вводятся хранилища данных.
- Внешние сущности остаются такими же, как на уровне 0.
- Потоки должны соответствовать входам и выходам уровня 0.
Уровень 2: Детальные функции 🔬
Уровень 2 разбивает конкретные процессы уровня 1. Это используется для сложных операций, которые требуют дополнительного объяснения.
- Фокусируется на одном процессе с предыдущего уровня.
- Показывает детальную логику и подшаги.
- Используется, когда процесс уровня 1 слишком сложен для управления в одном представлении.
| Уровень | Фокус | Процессы | Хранилища данных |
|---|---|---|---|
| Уровень 0 | Область системы | 1 (Система) | Нет |
| Уровень 1 | Основные функции | 3 до 7 | Да |
| Уровень 2 | Конкретные сведения | Зависит от уровня 1 | Да |
✍️ Пошаговая методология рисования
Создание диаграммы потока данных требует структурированного подхода. Следование этим шагам обеспечивает последовательность и ясность на протяжении всей документации.
Шаг 1: Определите масштаб и границы 🚧
Начните с определения того, что находится внутри системы, а что снаружи. Это решение определяет размещение внешних сущностей. Всё, что находится за границей, — это внешняя сущность. Всё, что внутри, — это процесс, хранилище или поток. Не включайте здесь детали реализации, такие как аппаратное обеспечение или код.
Шаг 2: Определите внешние сущности 👥
Перечислите всех участников, взаимодействующих с системой. Задайте вопросы, например:
- Кто отправляет информацию в систему?
- Кто получает отчеты или выходные данные из системы?
- Есть ли другие системы, обменивающиеся данными с этой?
Нарисуйте эти сущности по периметру вашего рабочего пространства. Используйте четкие, описательные названия.
Шаг 3: Определите основные процессы ⚙️
Определите основные функции, которые система должна выполнять для преобразования входных данных в выходные. Сгруппируйте связанные действия. Например, «Управление заказами» может быть основным процессом, включающим «Проверка заказа» и «Обновление инвентаря» как подпроцессы.
- Держите количество процессов в разумных пределах (идеально — менее 7 на уровне 1).
- Убедитесь, что каждый процесс имеет четкую цель.
- Обозначьте процессы глаголами (например, «Обработка платежа»).
Шаг 4: Нанесите потоки данных 🔄
Нарисуйте стрелки, соединяющие сущности с процессами и процессы с процессами. Каждая стрелка должна иметь метку, описывающую данные.
- Проверьте, что данные перемещаются логично.
- Убедитесь, что ни один поток не пересекает границу системы без прохождения через процесс.
- Обозначьте потоки конкретными пакетами данных (например, «Идентификатор клиента», а не просто «Данные»).
Шаг 5: Добавьте хранилища данных 📂
Определите, где необходимо хранить информацию. Если данные понадобятся позже, они должны быть помещены в хранилище.
- Соедините хранилища с процессами, которые читают или записывают в них.
- Убедитесь, что данные поступают в хранилище, чтобы сохранить их.
- Убедитесь, что данные выходят из хранилища, чтобы использовать их.
Шаг 6: Проверка и балансировка ⚖️
Это самый важный технический этап. Балансировка обеспечивает соответствие входов и выходов родительского процесса входам и выходам его дочерней диаграммы (следующий уровень вниз).
- Если на уровне 0 есть вход «Заказ», на уровне 1 также должен быть показан вход «Заказ» в основной процесс.
- Если на уровне 1 процесс разделяется, дочерние процессы должны обрабатывать те же входные и выходные данные, что и родительский процесс.
- Проверьте наличие изолированных процессов (процессов без потока данных).
- Проверьте наличие изолированных хранилищ данных (хранилищ без входящего или исходящего потока данных).
🧠 Лучшие практики и правила
Соблюдение строгих правил предотвращает путаницу. Отклонения могут привести к неверной интерпретации логики системы.
1. Правила именования 🏷️
Согласованность — ключевое условие. Используйте единый стандарт именования для всех элементов.
- Сущности: множественное число существительных (например, «Клиенты», «Поставщики»).
- Процессы: глагольные фразы (например, «Обновить инвентаризацию»).
- Хранилища: существительные (например, «Файл инвентаризации»).
- Потоки: имена данных (например, «Обновление запасов»).
2. Избегайте логики управления 🚫
DFD — это не блок-схема. Не включайте ромбы принятия решений или циклы, представляющие поток управления. Если решение влияет на поток данных, отображайте его путем разделения потока на разные пути на основе содержимого данных, а не самой логической условной конструкции.
3. Один стрелочный элемент — один пакет данных
Не объединяйте несколько типов данных в одну стрелку. Если процесс отправляет как «Данные заказа», так и «Данные оплаты», нарисуйте две отдельные стрелки.
4. Нет прямых потоков между внешними сущностями
Данные не могут перемещаться напрямую от одной внешней сущности к другой без прохождения через систему. Если это происходит, значит, система обойдена, или область диаграммы неверна.
5. Избегайте черных дыр и чудес
- Черная дыра: Процесс, имеющий входы, но не имеющий выходов. Данные исчезают. Это невозможно.
- Чудо: Процесс, имеющий выходы, но не имеющий входов. Данные появляются ниоткуда. Это невозможно.
⚠️ Распространённые ошибки, которые следует избегать
Даже опытные аналитики допускают ошибки. Знание распространённых ловушек экономит время при проверке.
Ошибка 1: Смешение уровней
Совмещение деталей уровня 0 и уровня 1 на одной странице приводит к перегруженности. Держите каждый уровень отдельно, чтобы сохранить ясность.
Ошибка 2: Несогласованное направление потока
Убедитесь, что стрелки указывают в правильном направлении. Распространённая ошибка — рисование стрелки от хранилища к процессу, когда процесс на самом деле записывает данные в хранилище.
Ошибка 3: Неопределённые метки
Избегайте меток, таких как «Информация», «Данные» или «Детали». Будьте конкретны. «Сведения о клиенте» — лучше. «Данные» бесполезны для анализа.
Ошибка 4: Пренебрежение хранилищами данных
Пропуск хранилищ данных приводит к неполному моделированию. Если данные используются позже, они должны быть сохранены. Отсутствие хранилищ означает отсутствие состояния в системе, что редко соответствует реальности сложных приложений.
🔍 Дополнительные аспекты
По мере роста систем, диаграммы потоков данных требуют более строгого сопровождения. Учитывайте следующее при работе над крупными проектами.
Физические и логические диаграммы потоков данных
- Логическая диаграмма потоков данных: Сфокусирована на бизнес-требованиях. Игнорирует технические детали реализации, такие как бумажные файлы по сравнению с базами данных.
- Физическая диаграмма потоков данных: Отражает фактическую реализацию. Указывает аппаратное обеспечение, программное обеспечение и типы файлов.
Наилучшая практика — сначала создать логическую диаграмму потоков данных для согласования требований, а затем вывести физическую диаграмму для разработки.
Параллелизм и временные характеристики
Стандартные диаграммы потоков данных не показывают время или параллелизм. Они показывают, что происходит, но не когда. Для систем, где временные характеристики критичны, могут потребоваться дополнительные методы моделирования, такие как диаграммы переходов состояний, наряду с диаграммами потоков данных.
Безопасность и контроль доступа
Хотя диаграммы потоков данных не явно показывают протоколы безопасности, потоки данных должны указывать на конфиденциальную информацию. Потоки, содержащие «Пароль» или «Номер кредитной карты», следует отметить. Это помогает архитекторам безопасности определить, где требуется шифрование.
📝 Обобщение рабочего процесса
Построение диаграммы потоков данных — это дисциплинированное упражнение в системном мышлении. Требуется разбивать сложную систему на управляемые части, сохраняя при этом целостность перемещения данных. Процесс идет от макроперспективы диаграммы контекста к микроперспективе детализированных процессов.
Успех зависит от:
- Чёткое определение границ.
- Согласованная маркировка компонентов.
- Строгое соблюдение правил балансировки.
- Валидация с заинтересованными сторонами.
Следуя этим шагам и избегая распространённых ошибок, вы создадите надёжный чертёж для разработки системы. Этот документ служит основой для проектирования баз данных, архитектуры программного обеспечения и инициатив по улучшению процессов. Он остаётся незаменимым инструментом для понимания того, как информация течёт через любую организованную систему.