











災難恢復很少是關於災難本身;而是關於我們在暴風雨來臨前所建立結構的脆弱性。在我們最近的事件中,資料庫結構設計中看似微不足道的疏忽,卻成為整個恢復過程的瓶頸。罪魁禍首是一個未能準確反映生產環境資料依賴關係的實體關係圖(ERD)。原本應在四十五分鐘內完成的操作,卻延長為三個小時的手動介入與資料核對。 🕰️
本文詳細說明了此次失敗的技術細節、導致延遲的具體結構不一致問題,以及我們為防止類似事件再次發生所實施的程序變更。我們將探討資料完整性如何極大程度地依賴於設計文件的準確性,而不僅僅是程式碼本身。
ERD在資料韌性中的關鍵角色 🛡️
實體關係圖是數位基礎設施的藍圖。它們標示出資料表、欄位、主鍵與外鍵,定義資料如何連結與流動。當災難發生時,這些圖表是工程師試圖恢復系統狀態時的第一個參考依據。如果地圖錯誤,旅程就會延遲。
在災難恢復的背景下,ERD具有三個主要功能:
- 驗證: 確認恢復後的結構與應用程式預期狀態相符。
- 依賴關係映射: 它識別出哪些資料表依賴於其他資料表,從而決定恢復的順序。
- 約束驗證: 確保在匯入過程中正確應用參照完整性規則。
當ERD與實際資料庫設定不一致時,恢復腳本會在驗證階段失敗。這迫使工程師停止作業、進行調查,並手動修補結構。正是這個手動步驟導致了時間的損失。 ⏳
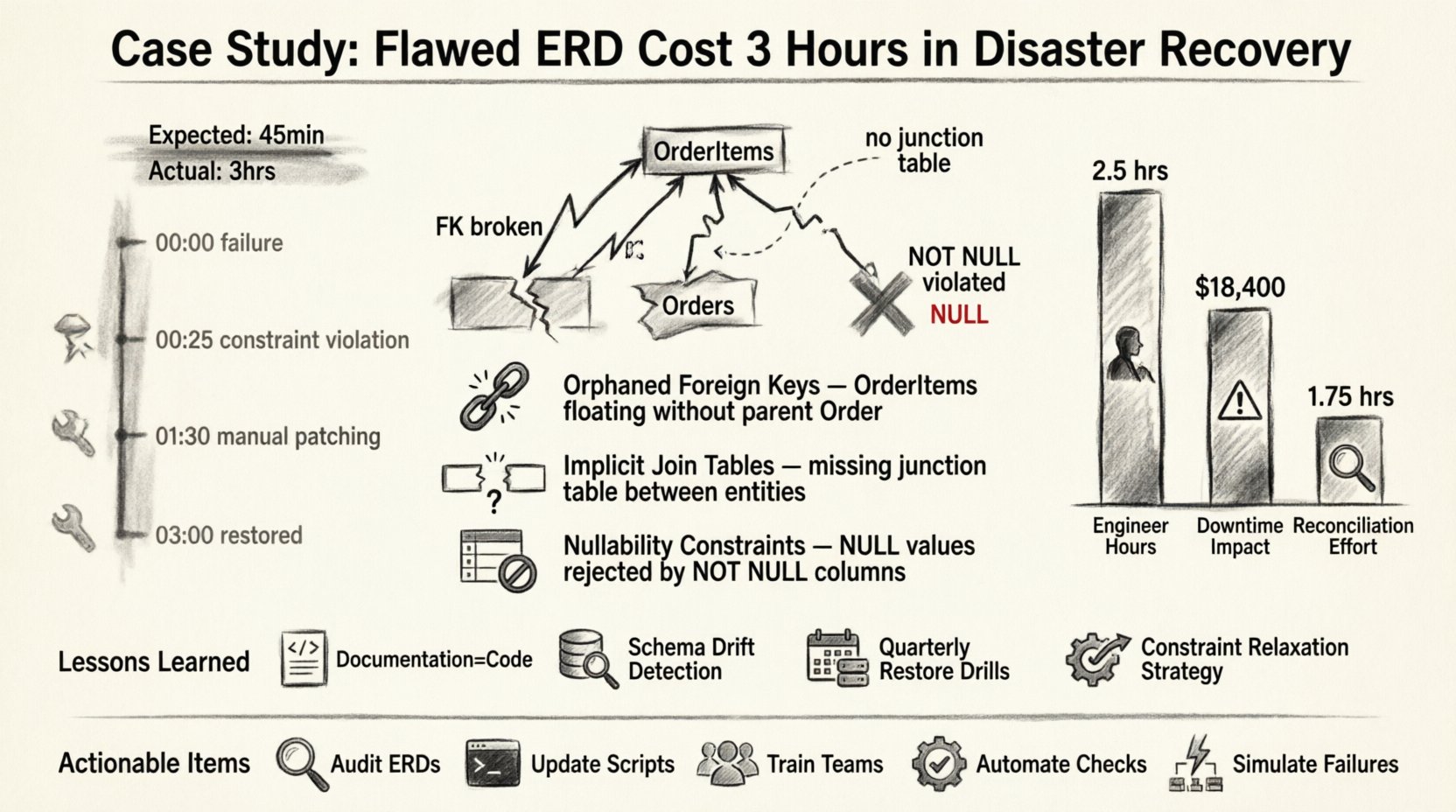
事件經過:錯誤時間軸 📉
事件始於主資料儲存區的故障。一場災難性的硬體錯誤觸發了系統切換至備用環境。標準作業程序是啟動恢復腳本,該腳本依賴於存放在文件倉庫中的靜態ERD版本。
以下是失敗的時間軸:
- 00:00 – 檢測到主系統故障。警報觸發事件回應。
- 00:05 – 工程團隊動員。已授予備用環境的存取權限。
- 00:15 – 根據文件中的ERD啟動恢復腳本。
- 00:25 – 腳本中止。檢測到外鍵約束違規。
- 00:30 – 調查開始。發現ERD與即時結構之間存在差異。
- 01:30 – 開始結構修補與手動資料核對。
- 03:00 – 系統恢復至可操作狀態。
三個小時的延遲並非由網路延遲或硬體速度慢所導致。這是因為設計文件與實際物理現實之間存在邏輯上的差距所致。🧩
已識別的具體資料結構缺陷 🔍
在將即時資料庫與ERD進行比對後,我們發現了三個關鍵差異。這些並非語法錯誤;而是邏輯上的遺漏,只有在系統試圖強制執行關係時才顯現出來。
1. 孤兒外鍵
ERD顯示「訂單」與「訂單項目」之間存在嚴格的一對多關係。然而,實際資料庫中包含舊資料,其中「訂單項目」存在,卻沒有對應的「訂單」記錄,這是因為先前的遷移未強制執行約束所致。ERD並未考慮到這種孤兒狀態。當還原腳本試圖重新建立外鍵時,資料庫拒絕了資料,因為父記錄遺失,或約束的強制方式與文件記載不同。
2. 隱含的關聯表格
多對多關係在ERD中被表示為兩個表格之間的直接連結。在實際實作中,這是由一個關聯表格處理的。還原邏輯預期的是直接連結,並試圖將資料插入錯誤的欄位中。這導致了一系列類型不匹配的錯誤,必須手動修改資料結構才能解決。
3. 空值約束
ERD指出幾個欄位是可選的(允許空值)。然而,生產環境的資料結構隨著時間推移已更新,為確保資料品質而強制要求非空值。ERD並未更新以反映此變更。還原過程中,腳本試圖將NULL值插入非空欄位,導致交易立即回滾。
這些差異突顯了技術文件中的一個常見問題:文件漂移。隨著系統的演進,文件會變得過時,造成一種錯誤的安全感。
成本分析:時間與準確性之間的權衡 💰
三個小時停機的財務影響相當重大,但聲譽損失的成本更高。以下是延遲期間所消耗資源的詳細分析。
| 資源 | 耗時 | 影響 |
|---|---|---|
| 資深工程師 | 3小時 | 高優先級工作被從開發中調離 |
| 系統停機 | 3小時 | 服務可用性降低15% |
| 資料核對 | 1.5 小時 | 需要手動驗證 |
| 文件更新 | 0.5 小時 | 事件後追蹤 |
該表格顯示,大部分成本並非還原本身,而是還原的修正。如果ERD準確無誤,還原過程將不會中斷。
技術分析:為何腳本失敗 🛠️
要理解錯誤的嚴重性,我們必須觀察還原腳本與資料庫引擎的互動方式。該腳本遵循標準流程:
- 根據ERD定義建立資料表。
- 套用約束條件(主鍵、外鍵)。
- 驗證完整性。
3. 插入資料。
當腳本執行到第二步時,試圖建立一個外鍵約束,將資料表A連結至資料表B。資料庫引擎掃描資料表B以查找現有資料。發現存在違反約束的記錄,因為缺少父鍵。由於腳本設計為可重複執行且安全,因此選擇停止,而非破壞資料。此安全機制雖有利於資料完整性,卻成為復原時間軸的阻礙。
腳本無法繼續執行,直到資料表B的資料被清理為止。清理資料需要:
- 識別孤立的記錄。
- 決定是刪除它們,還是建立虛擬的父記錄。
- 手動執行清理作業。
- 重新執行約束建立。
此鏈條中的每一步都會增加時間。ERD 應該在設計階段就標示出數據孤立的潛在風險,從而促使制定數據遷移策略,而非僅僅進行簡單的架構複製。
經驗教訓:強化架構生命周期 🔄
事件發生後,我們啟動了對架構管理流程的嚴格審查。我們意識到,僅依賴靜態文件進行災難恢復是不夠的。我們需要一種動態且具版本控制的架構設計方法。
以下是此次事件中的關鍵教訓:
- 文件即程式碼: ERD 不是獨立的產物;它是程式碼庫的一部分。它必須經歷與應用邏輯相同的版本控制和審查流程。
- 架構偏移檢測: 我們實施了自動化工具,將實際運行的資料庫架構與版本化的 ERD 進行比對。任何偏差都會立即觸發警告。
- 恢復測試: 我們現在每季度在沙盒環境中執行恢復演練。這確保了 ERD 能準確反映恢復路徑。
- 約束放寬: 我們調整了還原腳本,使其在初始資料載入期間暫時停用外鍵約束,僅在所有資料驗證完成後再重新啟用。
ERD 維護的最佳實務 📝
為避免未來再次延遲,我們已採用一組維護實體關係圖的最佳實務。這些步驟確保藍圖在系統整個生命周期中始終保持有效。
1. 圖表的版本控制
將 ERD 檔案與原始碼存放在同一程式碼倉庫中。每次發行都應加上對應的圖表版本標籤。這讓工程師能在任何時刻取得架構的精確狀態。
2. 自動化生成
只要有可能,應直接從資料庫架構生成 ERD,而非手動繪製。這能降低人為錯誤的機率,並確保圖表始終與實際情況一致。
3. 定期審查
每季安排一次 ERD 審查。將圖表與生產環境進行比對,並記錄任何在標準部署流程之外所做的變更。
4. 包含資料遷移註解
ERD 不僅應顯示表格,還應呈現資料的歷史。以註解標示可能孤立或過時的資料。這讓恢復團隊能預期到異常情況。
5. 在 Sprint 規劃期間審查
當新功能需要資料庫變更時,ERD 必須在同一張工單中更新。不得允許在沒有相應圖表更新的情況下部署架構變更。
技術錯誤中的人性因素 🧑💻
很容易將責任歸咎於圖表或腳本,但根本原因往往是溝通斷層。新增欄位的開發人員未更新圖表,審查程式碼的工程師也未檢查架構文件。
技術流程的強度取決於執行它的人。我們引入了部署清單,其中包含架構驗證步驟。每次部署都必須包含一份差異報告,顯示資料庫結構的變更。這迫使架構變更的透明化。
關於韌性的最終思考 🏗️
災難恢復衡量的是我們的準備程度,而不僅僅是反應速度。三小時的延遲只是更大問題的症狀:設計與實現之間的脫節。透過將實體關係圖視為我們基礎設施中一個活生生的組成部分,我們可以顯著縮短恢復時間。
資料完整性不是一個功能,而是一項基礎。當這項基礎出現裂痕時,整個結構都面臨風險。確保我們的藍圖準確無誤,是打造韌性架構的第一步。我們必須投入與程式碼開發同等的時間來進行文件編寫。
可執行事項摘要 ✅
- 審核現有ERD:立即將所有文件與實際資料結構進行比對。
- 更新指令碼:修改災難復原指令碼,使其能妥善處理約束違規情況。
- 訓練團隊:確保所有工程師都理解資料結構文件的重要性。
- 自動化檢查:導入能警示資料結構偏移的工具。
- 模擬故障:定期進行災難復原演練,以測試文件的準確性。
遵循這些做法,我們可以確保未來的事件能在數分鐘內解決,而非數小時。準確性的成本遠低於修正錯誤的成本。