











情報技術の進化する環境において、データフローダイアグラム(DFD)はシステム分析の基盤となる重要な文書のままである。1970年代の構造化プログラミング時代に考案された当初から、システム内のデータの流れを可視化する価値は減少していない。むしろ、その形態は変化している。組織が機械学習モデルや分散型ストレージシステム、リアルタイム処理ストリームと向き合う中で、データの経路を把握する必要性はかつてないほど重要になっている。
本ガイドは、DFDが現代の計算環境にどのように適応するかを検討する。従来の図式が、特定のベンダー製ツールに依存せずに人工知能のワークフロー、ビッグデータアーキテクチャ、クラウドネイティブインフラを表現するためにどのように進化すべきかを分析する。焦点は、データの移動、セキュリティ、変換に関する概念的整合性に置かれる。
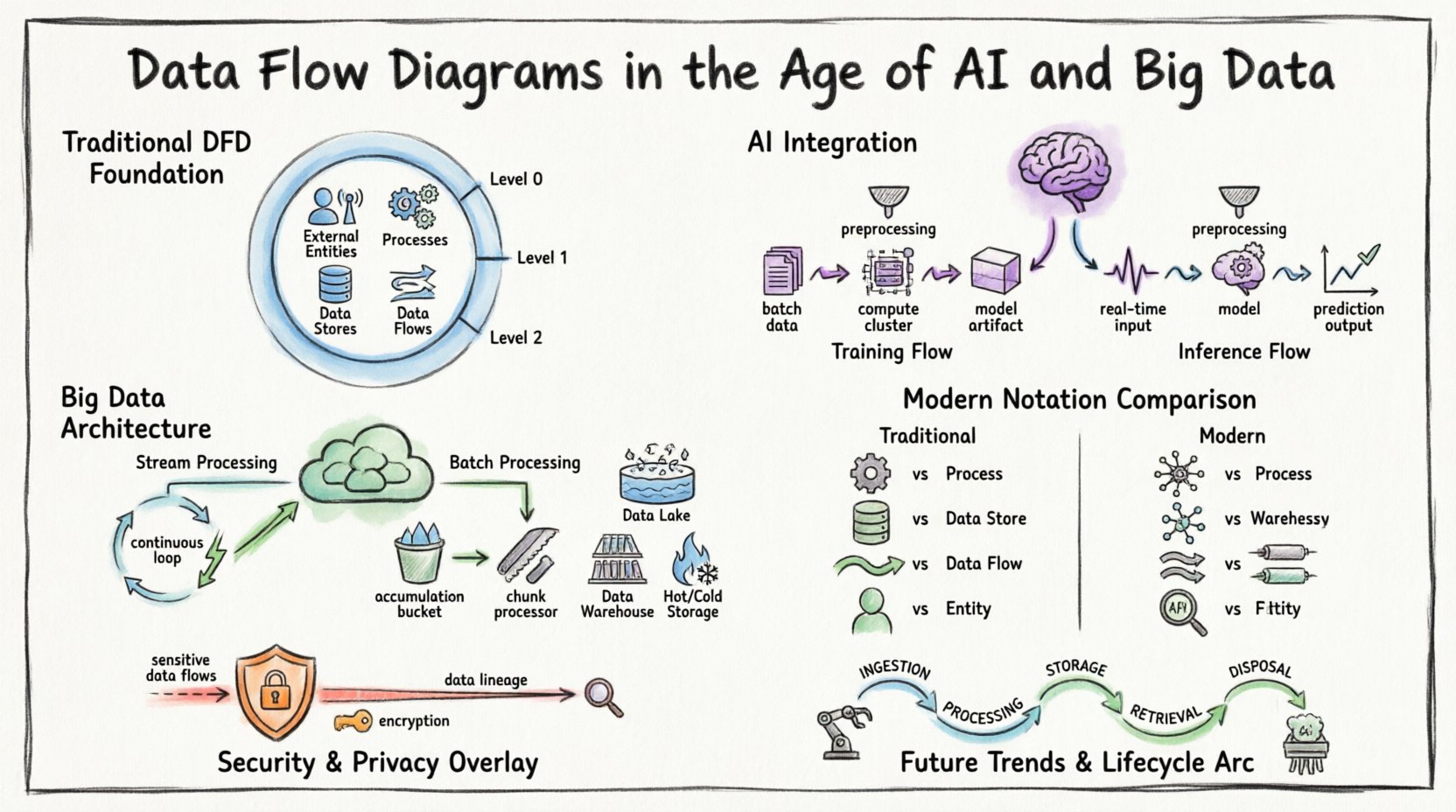
🏛️ 基礎:データフローダイアグラムの理解
現代の複雑さに取り組む前に、基本的な定義を確立することが不可欠である。データフローダイアグラムとは、情報システム内を通過するデータの流れを図式的に表現するものである。外部からの情報源から目的地および内部プロセスへの情報の移動をモデル化する。
標準的なDFDを構成する主要な要素は以下の通りである:
- 外部エンティティ:システム境界外の情報源または目的地(例:ユーザー、他のシステム、センサー)。
- プロセス:入力データを出力データに変換する変換処理。
- データストア:後続の利用のためにデータを保持するリポジトリ(例:データベース、ファイルシステム)。
- データフロー:エンティティ、プロセス、ストアの間を移動するデータ。
従来の文脈では、これらの図はしばしば複数の抽象度レベルで描かれていた:
- コンテキスト図(レベル0):システムを単一のプロセスとして示し、外部エンティティとの相互作用を描く。
- レベル1図:主プロセスを主要なサブプロセスに分解する。
- レベル2図:特定のサブプロセスをさらに分解し、詳細な情報を提示する。
この階層構造は依然として有効であるが、「プロセス」の性質は変化している。プロセスはもはや単なるバッチジョブではない。むしろ、継続的なサービスや予測モデルであることが多い。
🧠 AIの統合:フローにおける知能のモデル化
人工知能(AI)の統合は、データフローのマッピングに新たな変数をもたらす。従来のシステムでは論理が明示的であるが、AI駆動のシステムでは論理がしばしば確率的である。この違いは、DFDの「プロセス」コンポーネントをどのように可視化するかという点で、視点の転換を要求する。
1. 学習フローと推論フローの違い
機械学習パイプラインは、標準的なアプリケーション論理とは大きく異なる。AIシステムのDFDは、学習フェーズと推論フェーズを明確に区別する必要がある。
- 学習フロー:大規模なデータセットがストレージから計算クラスタへ移動する。出力は学習済みモデルのアーティファクトである。このフローはしばしばバッチ処理を想定しており、リソースを多く消費する。
- 推論フロー:リアルタイムまたはニアリアルタイムのデータがモデルに入力され、予測を生成する。このフローは低遅延と高スループットを優先する。
これらのフローをマッピングする際、モデル自体がブラックボックスプロセスとして機能することに注意することが重要です。内部の論理は隠されていますが、入力要件と出力形式は図の中で明確に定義される必要があります。
2. プロセスとしてのデータ前処理
データがAIモデルに到達する前に、大きな変換が行われます。特徴工学、正規化、クリーニングはDFDに明確に表示されるべき重要なステップです。これらのステップを無視すると、システムの理解が不完全になります。
- 正規化:モデルの期待に合わせてデータをスケーリングする。
- 符号化:カテゴリカルデータを数値ベクトルに変換する。
- 補完:フロー内の欠損値を処理する。
これらの前処理ステップはプロセスです。時間と計算リソースを消費し、データフロー内で追跡すべき潜在的な障害点をもたらします。
🌊 ビッグデータ:ボリューム、ベロシティ、バリエティの扱い
ビッグデータアーキテクチャは、従来のDFDの線形性に挑戦します。データはしばしばストリームとして到着し、データレイクに保管され、分散コンピューティングによって処理されます。静的な図では、これらの環境の動的性を容易に捉えることはできません。
1. ストリーミング処理 vs. バッチ処理
現代のシステムはしばしばハイブリッドアプローチを採用します。一部のデータはリアルタイムストリームで処理され、他のデータはバッチ分析のために集約されます。DFDはこれらの2つのパスを明確に区別しなければなりません。
- ストリーム処理:データは連続的に流れます。図は、スタート・ストップのシーケンスではなく、連続的なループとしてパイプラインを表現すべきです。
- バッチ処理:データは時間とともに蓄積され、チャンク単位で処理されます。図は、プロセス開始前に蓄積ポイント(データストア)を反映すべきです。
2. 分散ストレージの可視化
モノリシックデータベースでは、データストアは単一のボックスです。ビッグデータ環境では、ストレージは分散されています。DFDは、「データストア」が実際にはノードのクラスターやパーティショニングされたストレージシステムを表している可能性があることを示すべきです。
- データレイク:後に構造が適用される、生のデータストレージ。
- データウェアハウス:クエリ最適化された構造化ストレージ。
- ホットストレージ vs. クールストレージ:頻繁にアクセスされるデータとアーカイブデータの区別。
この区別はレイテンシを理解する上で重要です。ホットストレージノードからのフローは、クールストレージアーカイブからのフローとは異なる挙動を示します。
📐 表記の近代化
複雑なシステムを効果的に伝えるためには、DFDで使用される表記は適応しなければなりません。コアシンボルは類似したままであるものの、その適用にはニュアンスが必要です。
| コンポーネント | 伝統的なDFD | 現代のAI/ビッグデータDFD |
|---|---|---|
| プロセス | 単一の変換ステップ | マイクロサービス、モデル推論、またはパイプラインステージ |
| データストア | ファイルまたはデータベーステーブル | データレイク、分散キャッシュ、またはオブジェクトストア |
| データフロー | リクエスト/レスポンスまたはファイル転送 | イベントストリーム、APIペイロード、またはメッセージキュー |
| エンティティ | 人間ユーザーまたはレガシーシステム | IoTデバイス、サードパーティAPI、または自律エージェント |
1. イベント駆動型アーキテクチャ
多くの現代のシステムは直接的なリクエストよりもイベントに依存している。イベント駆動型システムのDFDは、プロセスを開始するためにトリガーを使用する。プロセスがデータを待つのではなく、データの到着がプロセスをトリガーする。
- メッセージキュー:プロデューサーとコンシューマーの間のバッファとして機能する。
- イベントログ:状態変更の変更不可能な記録であり、監査用のデータストアとして機能する。
これらのキューをデータストアとして可視化することで、バックプレッシャーの問題を明確にできる。プロセスが流入に追いつかない場合、キューが増大する。このリスクはマッピングする必要がある。
2. マイクロサービスと境界
システムがマイクロサービスに分割されるにつれて、DFDにおけるシステム境界はより透過的になる。データフローはしばしばAPIを介してサービス境界を越える。互換性要件を示すために、データフロー線に使用されるプロトコル(例:REST、gRPC、GraphQL)を明記することが重要である。
- サービスディスカバリ:データフローの動的ルーティング。
- ロードバランシング:複数のインスタンスにわたるデータフローの分散。
🔒 データフローにおけるセキュリティとプライバシー
データフロー図においてセキュリティを後回しにしてはならない。GDPRやCCPAなどの規制があるため、機密データがどこに存在し、どのように移動しているかを理解することは必須である。
1. 機密データの特定
個人識別情報(PII)または保護された健康情報(PHI)を含むデータフローは強調表示しなければなりません。感度の高いフローを示すために、異なる線のスタイルや色を使用してください。
- 転送中の暗号化:ネットワーク境界を越えるすべてのフローは、暗号化プロトコル(例:TLS)を示す必要があります。
- 静止状態での暗号化:機密データを含むデータストアは、マークされなければなりません。
2. データのルート(出自)
データの起源を理解することは、コンプライアンスにとって不可欠です。DFDは高レベルのルートマップとして機能します。データがシステムにどのように入力され、どのように変換されるかを示します。
- 同意の追跡:ユーザーの同意データを含むフローは、別途追跡しなければなりません。
- 消去の権利:図面は、データがどこに保存されているかを示すことで、削除リクエストの処理を容易にする必要があります。
DFDにデータがどこに保存されているかが示されていない場合、コンプライアンス監査は不可能になります。すべてのデータストアには、明確な所有者と保持ポリシーが必要です。
⚙️ モダンなDFD作成における課題
複雑なシステムに対して正確な図を描くことは、特定の課題を伴います。データの量と変化のスピードは、文書化作業をはるかに上回ることがあります。
1. 動的システム
自動スケーリンググループは、プロセスインスタンスの数を動的に変更します。静的図ではこれを示せません。図は現在の状態だけでなく、システムの*能力*を示す必要があります。
- 特定のインスタンスIDではなく、「コンピューティングクラスタ」などの汎用ラベルを使用してください。
- プロセスの説明にスケーリングのトリガーを明記してください。
2. 複雑さの管理
システムが拡大するにつれて、DFDは読みにくくなります。抽象化が鍵です。すべてのAPIエンドポイントをマッピングするべきではありません。論理的なデータ移動をマッピングしてください。
- グループ化:関連するプロセスを1つのスーパー・プロセスに統合してください。
- リンク:詳細なサブダイアグラムを高レベルの概要にリンクするために、クロスリファレンスを使用してください。
3. リアルタイム依存関係
ストリーミングシステムでは、処理の順序が重要です。DFDは接続性を示しますが、必ずしもタイミングを示すわけではありません。タイミングが重要である場合は、DFDにシーケンス図を補足してください。
- プロセスの説明にタイムアウトや再試行を明記してください。
- データフローが同期的か非同期的かを明記してください。
🚀 未来のトレンド:自動化とセルフドキュメンテーション
DFDの未来は自動化にあります。システムがますますコード中心になるにつれ、図は手動で描くのではなく、コードベースから生成されるべきです。
1. インフラストラクチャ・アズ・コード(IaC)
インフラストラクチャがコードで定義されると、データフローは暗黙的に定義される。ツールはIaCファイルを解析して、DFDを自動的に生成できる。
- 図と実際のインフラストラクチャの間に一貫性を確保する。
- 図の定義自体に対してバージョン管理を使用する。
2. コンティニュアス・ディスカバリー
ネットワーク監視ツールは実際のデータフローを検出できる。これらのツールをDFDソフトウェアと統合することで、トラフィックパターンの変化に応じて更新される「ライブ」図を実現できる。
- 文書化されていない新しいデータフローが出現したときにアラートを発する。
- 廃止できる未使用のデータストアをマークする。
3. AI補助による図示
人工知能は図の改善を提案できる。ベストプラクティスに基づいて、ボトルネック、冗長な経路、セキュリティ上の穴を特定できる。
- データフロー規則の自動検証(例:プロセスを経由せずにデータベースから外部エンティティへ直接フローするなど)。
- 最適なプロセス分解の提案。
🛠️ 実装のためのベストプラクティス
現代的な文脈でDFDの価値を維持するためには、以下の実践を守る。
- 表記の標準化:すべてのチームメンバーが同じ記号と規則を使用することを確保する。一貫性があることで認知負荷が軽減される。
- 命名規則の定義:プロセスは動詞+名詞の構造で命名する(例:「ユーザー入力を検証」)。データストアは名詞で命名する(例:「ユーザープロフィール」)。
- 定期的なレビュー:レビューされない図は嘘になる。スプリント計画やアーキテクチャの見直し会議中にレビューをスケジュールする。
- 価値に注目する:ビジネスロジックに必要なデータフローのみをマッピングする。エンドユーザーに影響しない冗長な内部フローは削除する。
- 仮定の文書化:フローが特定の遅延やスループットを想定している場合、それを文書化する。これらの仮定はシステム設計に影響を与える。
🔄 データフローのライフサイクル
ライフサイクルを理解することで、図を正確にマッピングするのに役立つ。データはいくつかの段階を経て移動する:
- インジェスト:データがシステム境界に入り込む。これはしばしば最も不安定なポイントである。
- プロセッシング:データは変換され、拡張され、または分析される。
- 保存:データは将来の利用のために永続化されます。
- 取得:データはレポート作成やアクションのためアクセスされます。
- 廃棄:データはポリシーに従ってアーカイブまたは削除されます。
各段階はDFD内の潜在的なプロセスまたはストアを表しています。完全な図は廃棄フェーズを考慮しており、データが不必要に残らないようにしています。
📊 主な構成要素の概要
迅速な参照のため、従来のコンポーネントが現代の同等物にどのように対応するかを以下に示します。
| 従来のコンセプト | 現代の同等物 | 考慮事項 |
|---|---|---|
| 入力 | APIゲートウェイ / インジェストパイプライン | 認証とレート制限 |
| 出力 | ダッシュボード / 通知サービス | フォーマット化と配信チャネル |
| プロセス | 関数 / コンテナ / モデル | 状態なしとスケーリング |
| ストア | オブジェクトストア / NoSQLデータベース | パーティショニングとインデックス化 |
| フロー | イベントメッセージ / HTTPリクエスト | レイテンシと信頼性 |
これらのコンセプトを整合させることで、エンジニアリング、データサイエンス、ビジネス関係者間で効果的なコミュニケーションツールとして機能する図をチームは作成できます。目標は完璧さではなく、明確さです。意思決定を支援する図が成功した図です。
🔮 データフロービジュアライゼーションについての最終的な考察
データフローダイアグラムの原則は時代を超えて普遍的ですが、その適用には適応が必要です。データが現代企業の核となる資産となる中で、その移動を可視化する能力は戦略的優位性です。単純なデータベースの管理から複雑なニューラルネットワークパイプラインの管理まで、DFDは情報を理解し、保護し、最適化するための必要な構造を提供します。
これらの手法を最新の状態に保つことで、システムアーキテクチャが透明性と保守性を保つことができます。静的ドキュメントから動的で自動化された可視化への移行は避けられないものです。この移行を受け入れるチームは、デジタル時代の複雑さに対処するための能力が高まるでしょう。
データに注目する。流れを追う。論理が成り立っているか確認する。これが効果的なシステム設計の核心的な使命です。