











Na paisagem em evolução da tecnologia da informação, o Diagrama de Fluxo de Dados (DFD) permanece um artefato fundamental para a análise de sistemas. Embora originalmente concebido durante a era da programação estruturada dos anos 1970, a utilidade de visualizar como os dados se movem através de um sistema não diminuiu. Pelo contrário, ela se transformou. À medida que as organizações lidam com modelos de aprendizado de máquina, sistemas de armazenamento distribuídos e fluxos de processamento em tempo real, a necessidade de mapear as trajetórias dos dados tornou-se mais crítica do que nunca.
Este guia explora a adaptação dos DFDs aos ambientes computacionais modernos. Ele examina como os diagramas tradicionais devem evoluir para representar fluxos de trabalho de inteligência artificial, arquiteturas de grandes dados e infraestruturas nativas em nuvem, sem depender de ferramentas específicas de fornecedores. O foco permanece na integridade conceitual do movimento, segurança e transformação dos dados.
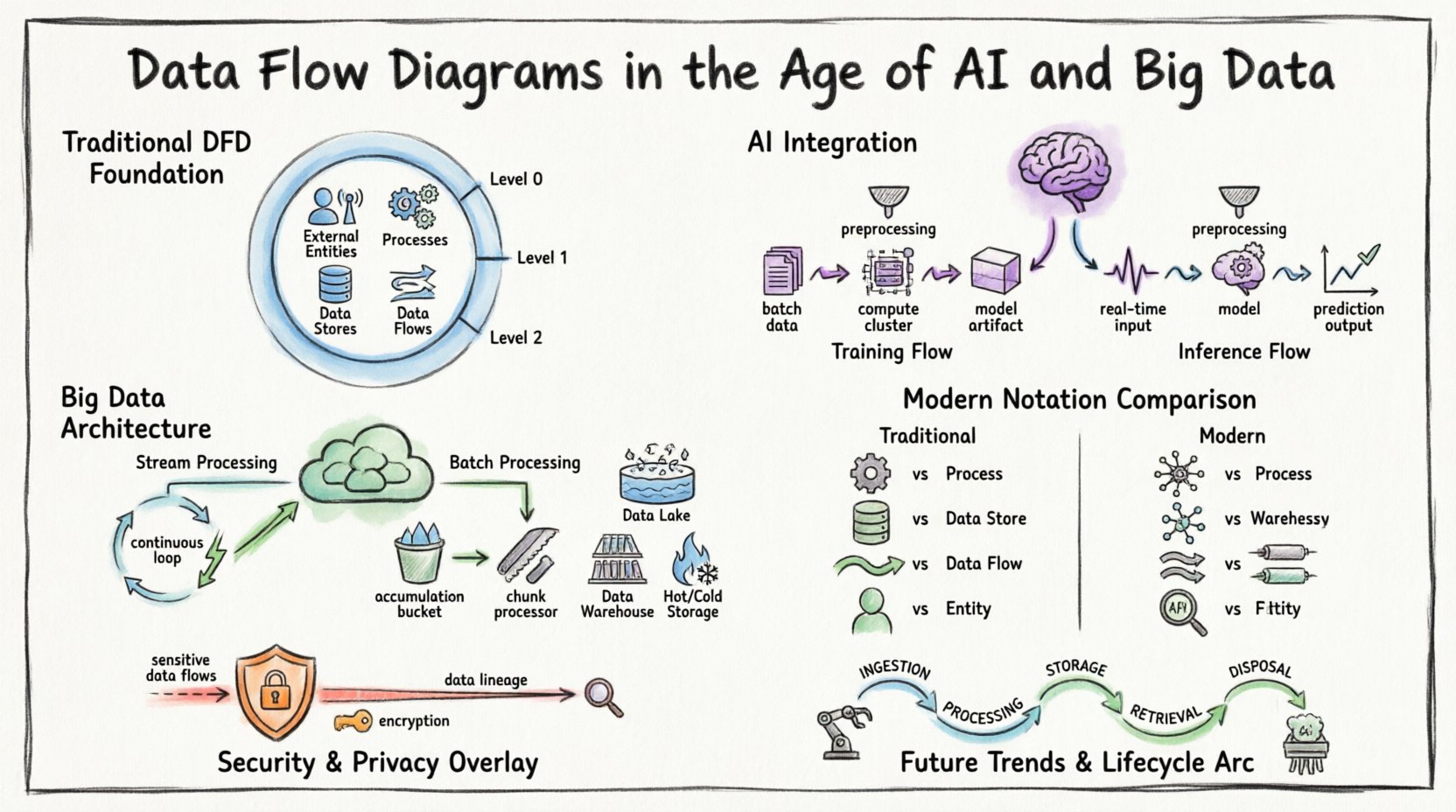
🏛️ A Base: Compreendendo os Diagramas de Fluxo de Dados
Antes de abordar as complexidades modernas, é essencial estabelecer a definição básica. Um Diagrama de Fluxo de Dados é uma representação gráfica do fluxo de dados através de um sistema de informação. Ele modela o movimento da informação proveniente de fontes externas até destinos e processos internos.
Os componentes principais definem um DFD padrão:
- Entidades Externas:Fontes ou destinos fora da fronteira do sistema (por exemplo, usuários, outros sistemas, sensores).
- Processos:Transformações que alteram dados de entrada em dados de saída.
- Armazenamentos de Dados:Repositórios onde os dados são armazenados para uso posterior (por exemplo, bancos de dados, sistemas de arquivos).
- Fluxos de Dados:O movimento de dados entre entidades, processos e armazenamentos.
Em contextos tradicionais, esses diagramas eram frequentemente desenhados em múltiplos níveis de abstração:
- Diagrama de Contexto (Nível 0):Mostra o sistema como um único processo e suas interações com entidades externas.
- Diagrama de Nível 1:Decompõe o processo principal em sub-processos principais.
- Diagrama de Nível 2:Decompõe ainda mais sub-processos específicos para detalhes granulares.
Embora essa hierarquia permaneça válida, a natureza do “processo” mudou. Um processo já não é apenas um trabalho em lote; muitas vezes é um serviço contínuo ou um modelo preditivo.
🧠 Integração de IA: Modelando Inteligência nos Fluxos
A integração da Inteligência Artificial (IA) introduz novas variáveis no mapeamento de fluxos de dados. Em sistemas tradicionais, a lógica é explícita. Em sistemas impulsionados por IA, a lógica é frequentemente probabilística. Essa distinção exige uma mudança na forma como visualizamos o componente “Processo” de um DFD.
1. Fluxos de Treinamento vs. Fluxos de Inferência
As pipelines de aprendizado de máquina diferem significativamente da lógica de aplicativos padrão. Um DFD para um sistema de IA deve distinguir entre a fase de treinamento e a fase de inferência.
- Fluxo de Treinamento:Envolve grandes conjuntos de dados que se movem do armazenamento para clusters de computação. A saída é um artefato de modelo treinado. Esse fluxo é frequentemente orientado por lote e intensivo em recursos.
- Fluxo de Inferência:Envolve dados em tempo real ou quase em tempo real entrando no modelo para gerar previsões. Esse fluxo prioriza baixa latência e alta taxa de transferência.
Ao mapear esses fluxos, é crucial observar que o próprio modelo atua como um processo caixa-preta. A lógica interna permanece oculta, mas os requisitos de entrada e os formatos de saída devem ser claramente definidos no diagrama.
2. Pré-processamento de dados como um processo
Antes que os dados cheguem a um modelo de IA, eles passam por uma transformação significativa. Engenharia de características, normalização e limpeza são etapas críticas que devem ser visíveis no DFD. Ignorar essas etapas leva a uma compreensão incompleta do sistema.
- Normalização: Escalonamento dos dados para atender às expectativas do modelo.
- Codificação: Convertendo dados categóricos em vetores numéricos.
- Imputação: Lidando com valores ausentes dentro do fluxo.
Essas etapas de pré-processamento são processos. Elas consomem tempo e recursos computacionais, e introduzem pontos potenciais de falha que devem ser rastreados no fluxo de dados.
🌊 Big Data: Lidando com Volume, Velocidade e Variedade
Arquiteturas de big data desafiam a natureza linear dos DFDs tradicionais. Os dados frequentemente chegam em fluxos, ficam armazenados em lagos de dados e são processados por meio de computação distribuída. Um diagrama estático não consegue facilmente capturar a natureza dinâmica desses ambientes.
1. Processamento em Streaming vs. Processamento em Lote
Sistemas modernos frequentemente utilizam uma abordagem híbrida. Algumas informações são processadas em fluxos em tempo real, enquanto outras são agregadas para análise em lote. O DFD deve demarcar claramente essas duas rotas.
- Processamento em Streaming: Os dados fluem continuamente. O diagrama deve representar a pipeline como um loop contínuo, em vez de uma sequência de início e parada.
- Processamento em Lote: Os dados se acumulam ao longo do tempo e são processados em partes. O diagrama deve refletir o ponto de acumulação (Armazenamento de Dados) antes do início do processo.
2. Visualização de Armazenamento Distribuído
Em um banco de dados monolítico, um armazenamento de dados é uma única caixa. Em um ambiente de big data, o armazenamento é distribuído. O DFD deve indicar que um ‘Armazenamento de Dados’ pode, na verdade, representar um cluster de nós ou um sistema de armazenamento particionado.
- Lagos de Dados: Armazenamento de dados brutos onde a estrutura é aplicada posteriormente.
- Data Warehouses (Armazéns de Dados): Armazenamento estruturado otimizado para consultas.
- Armazenamento Quente vs. Armazenamento Frio: Diferenciar entre dados frequentemente acessados e dados arquivados.
Essa distinção é vital para entender a latência. Um fluxo proveniente de um nó de armazenamento quente se comportará de forma diferente de um fluxo proveniente de um arquivo de armazenamento frio.
📐 Modernização da Notação
Para comunicar efetivamente sistemas complexos, a notação usada nos DFDs deve se adaptar. Embora os símbolos principais permaneçam semelhantes, sua aplicação exige nuances.
| Componente | DFD Tradicional | DFD Moderno de IA/Big Data |
|---|---|---|
| Processo | Etapa única de transformação | Microserviço, Inferência de Modelo ou Etapa de Pipeline |
| Armazenamento de Dados | Arquivo ou Tabela de Banco de Dados | Data Lake, Cache Distribuído ou Armazenamento de Objetos |
| Fluxo de Dados | Solicitação/Resposta ou Transferência de Arquivo | Fluxo de Eventos, Payload da API ou Fila de Mensagens |
| Entidade | Usuário Humano ou Sistema Legado | Dispositivo IoT, API de Terceiros ou Agente Autônomo |
1. Arquitetura Orientada a Eventos
Muitos sistemas modernos dependem de eventos em vez de solicitações diretas. Um DFD para um sistema orientado a eventos utiliza gatilhos para iniciar processos. Em vez de um processo esperar por dados, a chegada dos dados dispara o processo.
- Filas de Mensagens: Atuam como buffers entre produtores e consumidores.
- Logs de Eventos: Registros imutáveis das mudanças de estado que servem como armazenamentos de dados para auditoria.
Visualizar essas filas como armazenamentos de dados ajuda a esclarecer problemas de backpressure. Se um processo não consegue acompanhar a entrada de dados, a fila cresce. Esse risco deve ser mapeado.
2. Microserviços e Fronteiras
À medida que os sistemas se dividem em microserviços, a fronteira do sistema em um DFD torna-se mais porosa. Os fluxos de dados frequentemente cruzam as fronteiras dos serviços por meio de APIs. É importante rotular o protocolo usado (por exemplo, REST, gRPC, GraphQL) nas linhas de fluxo de dados para indicar requisitos de compatibilidade.
- Descoberta de Serviços: Roteamento dinâmico de fluxos de dados.
- Balanceamento de Carga: Distribuição de fluxos de dados entre múltiplas instâncias.
🔒 Segurança e Privacidade nos Fluxos de Dados
A segurança não pode ser uma consideração posterior em um diagrama de fluxo de dados. Com regulamentações como o GDPR e o CCPA, entender onde os dados sensíveis residem e se movem é obrigatório.
1. Identificação de Dados Sensíveis
Os fluxos de dados que transportam Informações Pessoalmente Identificáveis (PII) ou Informações de Saúde Protegidas (PHI) devem ser destacados. Use estilos de linha ou cores distintas para indicar fluxos sensíveis.
- Criptografia em Trânsito:Todos os fluxos que cruzam fronteiras de rede devem indicar protocolos de criptografia (por exemplo, TLS).
- Criptografia em Repouso:Os armazenamentos de dados que contêm dados sensíveis devem ser marcados.
2. Linhagem de Dados
Compreender a origem dos dados é essencial para a conformidade. Um DFD serve como um mapa de linhagem de alto nível. Mostra onde os dados entram no sistema e como se transformam.
- Rastreamento de Consentimento:Os fluxos que envolvem dados de consentimento do usuário devem ser rastreados separadamente.
- Direito à Eliminação:Os diagramas devem mostrar onde os dados são armazenados para facilitar solicitações de exclusão.
Se um DFD não mostrar onde os dados são armazenados, auditorias de conformidade tornam-se impossíveis. Cada armazenamento de dados deve ter um proprietário definido e uma política de retenção.
⚙️ Desafios na Criação de DFDs Modernos
Criar diagramas precisos para sistemas complexos apresenta obstáculos específicos. O volume de dados e a velocidade das mudanças frequentemente superam os esforços de documentação.
1. Sistemas Dinâmicos
Grupos de autoescala alteram dinamicamente o número de instâncias de processos. Um diagrama estático não pode mostrar isso. O diagrama deve representar a *capacidade* do sistema, e não apenas o estado atual.
- Use rótulos genéricos como ‘Cluster de Computação’ em vez de IDs específicos de instâncias.
- Indique os gatilhos de escalonamento na descrição do processo.
2. Gestão da Complexidade
À medida que os sistemas crescem, os DFDs tornam-se ilegíveis. A abstração é essencial. Não mapeie cada ponto final da API. Mapeie o movimento lógico dos dados.
- Agrupamento:Combine processos relacionados em um único superprocesso.
- Vinculação:Use referências cruzadas para vincular subdiagramas detalhados a visões gerais de alto nível.
3. Dependências em Tempo Real
Em sistemas de streaming, a ordem das operações importa. Um DFD mostra conectividade, mas nem sempre o tempo. Complemente os DFDs com diagramas de sequência se o tempo for crítico.
- Indique tempos limite e tentativas novamente nas descrições dos processos.
- Observe se os fluxos de dados são síncronos ou assíncronos.
🚀 Tendências Futuras: Automação e Auto-documentação
O futuro dos DFDs reside na automação. À medida que os sistemas se tornam mais centrados em código, os diagramas deveriam ser gerados a partir da base de código, em vez de serem desenhados manualmente.
1. Infraestrutura como Código (IaC)
Quando a infraestrutura é definida em código, o fluxo de dados é implicitamente definido. Ferramentas podem analisar arquivos IaC para gerar diagramas de fluxo de dados (DFD) automaticamente.
- Garanta a consistência entre o diagrama e a infraestrutura real.
- Use controle de versão para as próprias definições do diagrama.
2. Descoberta Contínua
Ferramentas de monitoramento de rede podem detectar fluxos de dados reais. Integrar essas ferramentas com software de DFD permite diagramas “ao vivo” que se atualizam conforme os padrões de tráfego mudam.
- Aviso quando novos fluxos de dados aparecerem que não foram documentados.
- Sinalize armazenamentos de dados não utilizados que podem ser desativados.
3. Diagramação com Auxílio de IA
Inteligência Artificial pode sugerir melhorias para diagramas. Ela pode identificar gargalos, caminhos redundantes ou falhas de segurança com base em melhores práticas.
- Validação automática de regras de fluxo de dados (por exemplo, nenhum fluxo direto de banco de dados para entidade externa sem um processo).
- Sugestão de decomposição de processos ótimos.
🛠️ Melhores Práticas para Implementação
Para manter o valor dos DFDs em um contexto moderno, adira às seguintes práticas.
- Padronize a Notação:Garanta que todos os membros da equipe usem os mesmos símbolos e convenções. A consistência reduz a carga cognitiva.
- Defina Convenções de Nomeação:Os processos devem ser nomeados com estruturas Verbo-Nome (por exemplo, “Validar Entrada do Usuário”). Armazenamentos de dados devem ser nomeados como substantivos (por exemplo, “Perfis de Usuário”).
- Revise Regularmente:Um diagrama que não é revisado torna-se uma mentira. Agende revisões durante a planejamento de sprint ou reuniões de aprimoramento de arquitetura.
- Foque no Valor:Mapeie apenas os fluxos de dados necessários para a lógica de negócios. Remova fluxos internos redundantes que não afetam o usuário final.
- Documente Suposições:Se um fluxo assume uma latência ou throughput específicos, documente isso. Essas suposições afetam o design do sistema.
🔄 O Ciclo de Vida de um Fluxo de Dados
Compreender o ciclo de vida ajuda a mapear o diagrama com precisão. Os dados passam por várias etapas:
- Ingestão:Os dados entram na fronteira do sistema. Este é frequentemente o ponto mais volátil.
- Processamento:Os dados são transformados, enriquecidos ou analisados.
- Armazenamento: Os dados são persistidos para uso futuro.
- Recuperação: Os dados são acessados para relatórios ou ações.
- Eliminação: Os dados são arquivados ou excluídos de acordo com a política.
Cada fase representa um processo ou armazenamento potencial no DFD. Um diagrama completo considera a fase de eliminação, garantindo que os dados não permaneçam desnecessariamente.
📊 Resumo dos Componentes Principais
Para referência rápida, aqui está uma análise de como os componentes tradicionais se relacionam com equivalentes modernos.
| Conceito Tradicional | Equivalente Moderno | Consideração |
|---|---|---|
| Entrada | Gateway de API / Pipeline de Ingestão | Autenticação e Limitação de Taxa |
| Saída | Painel / Serviço de Notificação | Formatação e Canal de Entrega |
| Processo | Função / Container / Modelo | Estado e Escalabilidade |
| Armazenamento | Armazenamento de Objetos / Banco de Dados NoSQL | Particionamento e Indexação |
| Fluxo | Mensagem de Evento / Requisição HTTP | Latência e Confiabilidade |
Ao alinhar esses conceitos, as equipes podem criar diagramas que servem como ferramentas eficazes de comunicação entre engenheiros, cientistas de dados e partes interessadas do negócio. O objetivo não é a perfeição, mas a clareza. Um diagrama que auxilia na tomada de decisões é bem-sucedido.
🔮 Pensamentos Finais sobre a Visualização de Fluxo de Dados
Os princípios dos Diagramas de Fluxo de Dados são atemporais, mas sua aplicação exige adaptação. À medida que os dados se tornam o ativo central das empresas modernas, a capacidade de visualizar seu movimento é uma vantagem estratégica. Seja gerenciando um banco de dados simples ou um pipeline complexo de rede neural, o DFD fornece a estrutura necessária para compreender, proteger e otimizar o fluxo de informações.
Permanecer atualizado com essas metodologias garante que as arquiteturas de sistemas permaneçam transparentes e passíveis de manutenção. A transição da documentação estática para visualizações dinâmicas e automatizadas é inevitável. Equipes que adotarem essa transição se encontrarão melhor preparadas para lidar com as complexidades da era digital.
Concentre-se nos dados. Siga o fluxo. Garanta que a lógica seja consistente. Isso permanece a missão central do design eficaz de sistemas.