











सूचना प्रौद्योगिकी के विकासशील परिदृश्य में, डेटा प्रवाह आरेख (DFD) प्रणाली विश्लेषण के लिए एक मूल अभिलेख बना हुआ है। जबकि इसकी शुरुआत 1970 के वर्षों में संरचित प्रोग्रामिंग युग के दौरान की गई थी, एक प्रणाली के माध्यम से डेटा के गतिशीलता को दृश्याकृत करने की उपयोगिता कम नहीं हुई है। बल्कि इसका रूप बदल गया है। जैसे-जैसे संगठन मशीन लर्निंग मॉडल, वितरित स्टोरेज प्रणालियों और वास्तविक समय प्रसंस्करण प्रवाहों के सामने आते हैं, डेटा के मार्ग को नक्शा बनाने की आवश्यकता कभी नहीं इतनी महत्वपूर्ण हुई है।
यह मार्गदर्शिका डेटा प्रवाह आरेखों के आधुनिक गणना परिवेशों में अनुकूलन का अध्ययन करती है। यह यह जांचती है कि पारंपरिक आरेखों को कृत्रिम बुद्धिमत्ता के कार्यप्रवाह, बड़े डेटा आर्किटेक्चर और क्लाउड-नेटिव इंफ्रास्ट्रक्चर को दर्शाने के लिए कैसे विकसित किया जाना चाहिए, जिसमें किसी विशेष विक्रेता उपकरण पर निर्भर नहीं रहना चाहिए। ध्यान डेटा के गतिशीलता, सुरक्षा और रूपांतरण की अवधारणात्मक अखंडता पर बना रहता है।
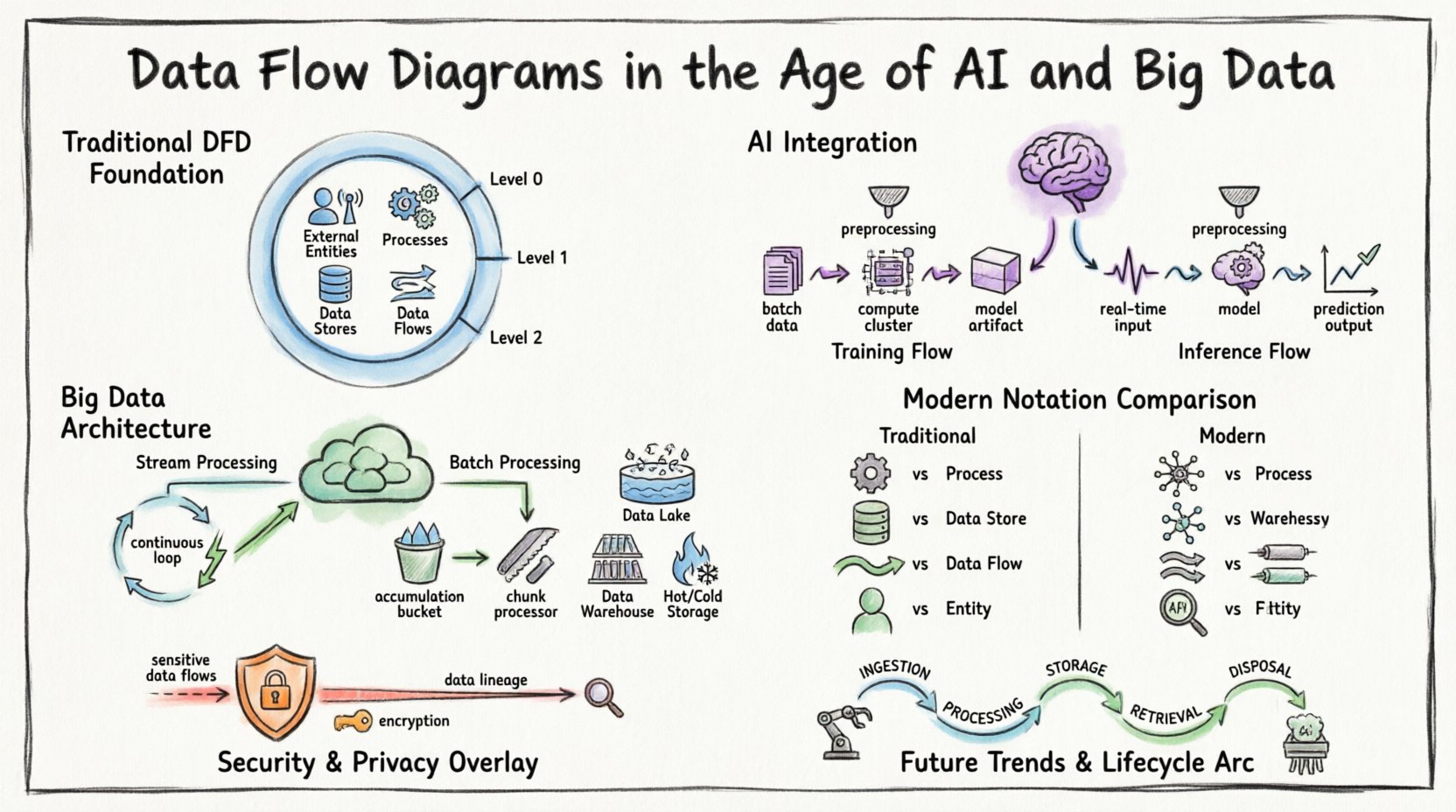
🏛️ मूलभूत बातें: डेटा प्रवाह आरेखों को समझना
आधुनिक जटिलताओं को संबोधित करने से पहले, मूल निर्वचन को स्थापित करना आवश्यक है। डेटा प्रवाह आरेख एक सूचना प्रणाली के माध्यम से डेटा के प्रवाह का एक आलेखीय प्रतिनिधित्व है। यह बाहरी स्रोतों से लक्ष्यों और आंतरिक प्रक्रियाओं तक सूचना के गतिशीलता को मॉडल करता है।
मुख्य घटक एक मानक DFD को परिभाषित करते हैं:
- बाहरी एकाधिकार:प्रणाली की सीमा के बाहर के स्रोत या गंतव्य (उदाहरण के लिए, उपयोगकर्ता, अन्य प्रणालियाँ, सेंसर)।
- प्रक्रियाएँ:इनपुट डेटा को आउटपुट डेटा में बदलने वाले रूपांतरण।
- डेटा स्टोरेज:संग्रह स्थान जहाँ डेटा बाद में उपयोग के लिए रखा जाता है (उदाहरण के लिए, डेटाबेस, फाइल प्रणाली)।
- डेटा प्रवाह:एकाधिकारों, प्रक्रियाओं और स्टोरेज के बीच डेटा की गतिशीलता।
पारंपरिक संदर्भों में, इन आरेखों को अक्सर बहुत स्तरों पर सारांशित रूप से बनाया जाता था:
- संदर्भ आरेख (स्तर 0):प्रणाली को एकल प्रक्रिया के रूप में दिखाता है और इसके बाहरी एकाधिकारों के साथ बातचीत को दर्शाता है।
- स्तर 1 आरेख:मुख्य प्रक्रिया को मुख्य उप-प्रक्रियाओं में विभाजित करता है।
- स्तर 2 आरेख:विशिष्ट उप-प्रक्रियाओं को अधिक विस्तृत विवरण के लिए आगे विभाजित करता है।
हालांकि यह पदानुक्रम अब भी वैध है, प्रक्रिया की प्रकृति बदल गई है। एक प्रक्रिया अब केवल बैच कार्य नहीं है; यह अक्सर एक निरंतर सेवा या एक पूर्वानुमान मॉडल होती है।
🧠 एआई एकीकरण: प्रवाहों में बुद्धिमत्ता का मॉडलिंग
कृत्रिम बुद्धिमत्ता (एआई) के एकीकरण से डेटा प्रवाह नक्शाकरण में नए चर आते हैं। पारंपरिक प्रणालियों में तर्क स्पष्ट होता है। एआई-आधारित प्रणालियों में, तर्क अक्सर संभाव्य होता है। इस अंतर के कारण डीएफडी के ‘प्रक्रिया’ घटक को कैसे दृश्याकृत करना है, इसमें बदलाव की आवश्यकता होती है।
1. प्रशिक्षण बनाम निष्कर्षण प्रवाह
मशीन लर्निंग पाइपलाइन मानक एप्लिकेशन तर्क से काफी अलग होती हैं। एआई प्रणाली के लिए डीएफडी में प्रशिक्षण चरण और निष्कर्षण चरण के बीच अंतर करना आवश्यक है।
- प्रशिक्षण प्रवाह:बड़े डेटासेट के स्टोरेज से गणना क्लस्टर तक जाने वाले प्रवाह को शामिल करता है। आउटपुट एक प्रशिक्षित मॉडल उत्पाद होता है। इस प्रवाह को अक्सर बैच-आधारित और संसाधन-संक्रामक माना जाता है।
- निष्कर्षण प्रवाह:वास्तविक समय या लगभग वास्तविक समय के डेटा के मॉडल में प्रवेश करके भविष्यवाणियाँ बनाने के लिए शामिल होता है। इस प्रवाह को कम लेटेंसी और उच्च थ्रूपुट की प्राथमिकता दी जाती है।
जब इन प्रवाहों को मैप करते हैं, तो यह ध्यान देना महत्वपूर्ण है कि मॉडल स्वयं एक ब्लैक बॉक्स प्रक्रिया के रूप में कार्य करता है। आंतरिक तर्क छिपा हुआ है, लेकिन आइनपुट आवश्यकताओं और आउटपुट प्रारूपों को आरेख में स्पष्ट रूप से परिभाषित करना आवश्यक है।
2. प्रक्रिया के रूप में डेटा पूर्व-प्रसंस्करण
AI मॉडल तक पहुंचने से पहले, डेटा को महत्वपूर्ण रूपांतरण के माध्यम से गुजरना पड़ता है। फीचर इंजीनियरिंग, सामान्यीकरण और सफाई महत्वपूर्ण चरण हैं जिन्हें DFD में स्पष्ट रूप से दिखाया जाना चाहिए। इन चरणों को नजरअंदाज करने से प्रणाली की समझ अधूरी हो जाती है।
- सामान्यीकरण:मॉडल की अपेक्षाओं के अनुरूप डेटा को स्केल करना।
- कोडिंग:श्रेणीबद्ध डेटा को संख्यात्मक सदिशों में बदलना।
- पूर्ति:प्रवाह के भीतर अनुपस्थित मानों का प्रबंधन करना।
इन पूर्व-प्रसंस्करण चरण प्रक्रियाएँ हैं। वे समय और गणनात्मक संसाधनों का उपयोग करती हैं, और वे डेटा प्रवाह में ट्रैक किए जाने वाले संभावित विफलता के बिंदुओं को जोड़ती हैं।
🌊 बिग डेटा: आयतन, वेग और विविधता का प्रबंधन
बिग डेटा आर्किटेक्चर पारंपरिक DFD की रेखीय प्रकृति की चुनौती खड़ी करते हैं। डेटा अक्सर स्ट्रीम में आता है, डेटा झीलों में रहता है, और वितरित गणना के माध्यम से प्रसंस्कृत किया जाता है। एक स्थिर आरेख इन परिवेशों की गतिशील प्रकृति को आसानी से नहीं दर्शा सकता है।
1. स्ट्रीमिंग बनाम बैच प्रसंस्करण
आधुनिक प्रणालियाँ अक्सर हाइब्रिड दृष्टिकोण का उपयोग करती हैं। कुछ डेटा रियल-टाइम स्ट्रीम में प्रसंस्कृत किया जाता है, जबकि अन्य डेटा बैच विश्लेषण के लिए एकत्र किया जाता है। DFD को इन दोनों मार्गों को स्पष्ट रूप से अलग करना चाहिए।
- स्ट्रीम प्रसंस्करण:डेटा निरंतर बहता है। आरेख को पाइपलाइन को एक निरंतर लूप के रूप में दर्शाना चाहिए, न कि शुरू-रुकावट अनुक्रम के रूप में।
- बैच प्रसंस्करण:डेटा समय के साथ एकत्र होता है और खंडों में प्रसंस्कृत किया जाता है। आरेख को प्रक्रिया शुरू होने से पहले संचय बिंदु (डेटा स्टोर) को दर्शाना चाहिए।
2. वितरित संग्रहण दृश्यीकरण
एक मोनोलिथिक डेटाबेस में, डेटा स्टोर एक एकल बॉक्स होता है। बिग डेटा परिवेश में, संग्रहण वितरित होता है। DFD को इंगित करना चाहिए कि एक ‘डेटा स्टोर’ वास्तव में नोड्स के एक क्लस्टर या विभाजित संग्रहण प्रणाली का प्रतिनिधित्व कर सकता है।
- डेटा झीलें:कच्चे डेटा का संग्रहण जहां संरचना बाद में लागू की जाती है।
- डेटा वेयरहाउस:प्रश्नों के लिए अनुकूलित संरचित संग्रहण।
- हॉट बनाम कोल्ड स्टोरेज:अक्सर पहुंचे जाने वाले डेटा और संग्रहीत डेटा के बीच अंतर करना।
इस अंतर को समझने के लिए महत्वपूर्ण है। एक हॉट स्टोरेज नोड से आने वाला प्रवाह एक कोल्ड स्टोरेज आर्काइव से आने वाले प्रवाह से अलग व्यवहार करेगा।
📐 नोटेशन का आधुनिकीकरण
जटिल प्रणालियों को प्रभावी ढंग से संचारित करने के लिए, DFD में उपयोग की जाने वाली नोटेशन को अनुकूलित करना आवश्यक है। जबकि मूल प्रतीक समान रहते हैं, उनके उपयोग में सूक्ष्मता की आवश्यकता होती है।
| घटक | पारंपरिक DFD | आधुनिक AI/बड़े डेटा DFD |
|---|---|---|
| प्रक्रिया | एकल रूपांतरण चरण | माइक्रोसर्विस, मॉडल निष्कर्ष या पाइपलाइन चरण |
| डेटा भंडार | फ़ाइल या डेटाबेस तालिका | डेटा झील, वितरित कैश या वस्तु भंडार |
| डेटा प्रवाह | अनुरोध/प्रतिक्रिया या फ़ाइल स्थानांतरण | घटना प्रवाह, API प्रतिबंध या संदेश भंडार |
| एकांतर | मानव उपयोगकर्ता या पुराना प्रणाली | आईओटी उपकरण, तृतीय पक्ष API या स्वतंत्र एजेंट |
1. घटना-आधारित वार्ताचक्र
अधिकांश आधुनिक प्रणालियाँ सीधे अनुरोधों के बजाय घटनाओं पर निर्भर करती हैं। घटना-आधारित प्रणाली के लिए एक DFD अनुक्रमण के लिए ट्रिगर का उपयोग करता है। एक प्रक्रिया डेटा की प्रतीक्षा करने के बजाय, डेटा के आगमन से प्रक्रिया प्रारंभ होती है।
- संदेश भंडार: उत्पादकों और उपभोक्ताओं के बीच बफर के रूप में कार्य करते हैं।
- घटना लॉग: अपरिवर्तनीय अवस्था परिवर्तनों के रिकॉर्ड जो सत्यापन के लिए डेटा भंडार के रूप में कार्य करते हैं।
इन भंडारों को डेटा भंडार के रूप में दृश्याकृत करने से बैकप्रेशर समस्याओं को स्पष्ट करने में मदद मिलती है। यदि कोई प्रक्रिया प्रवाह के साथ नहीं चल पाती है, तो भंडार बढ़ता है। इस जोखिम को नक्शा बनाना आवश्यक है।
2. माइक्रोसर्विसेज और सीमाएं
जैसे ही प्रणालियाँ माइक्रोसर्विसेज में विभाजित होती हैं, DFD में प्रणाली की सीमा अधिक छिद्रित हो जाती है। डेटा प्रवाह अक्सर APIs के माध्यम से सेवा सीमाओं को पार करते हैं। डेटा प्रवाह रेखाओं पर उपयोग किए जाने वाले प्रोटोकॉल (जैसे REST, gRPC, GraphQL) को चिह्नित करना महत्वपूर्ण है ताकि संगतता आवश्यकताएं दर्शाई जा सकें।
- सेवा खोज: डेटा प्रवाह का गतिशील मार्गदर्शन।
- लोड संतुलन: बहुत से उदाहरणों के बीच डेटा प्रवाह का वितरण।
🔒 डेटा प्रवाह में सुरक्षा और गोपनीयता
डेटा प्रवाह आरेख में सुरक्षा को बाद में सोचने के लिए नहीं छोड़ा जा सकता है। GDPR और CCPA जैसे नियमों के साथ, संवेदनशील डेटा के स्थान और गति को समझना अनिवार्य है।
1. संवेदनशील डेटा की पहचान करना
व्यक्तिगत रूप से पहचान योग्य जानकारी (PII) या सुरक्षित स्वास्थ्य सूचना (PHI) ले जाने वाले डेटा प्रवाहों को उजागर किया जाना चाहिए। संवेदनशील प्रवाहों को दर्शाने के लिए अलग-अलग रेखा शैलियों या रंगों का उपयोग करें।
- प्रवाह में एन्क्रिप्शन: सभी प्रवाहों को नेटवर्क सीमाओं को पार करते समय एन्क्रिप्शन प्रोटोकॉल (जैसे TLS) को दर्शाना चाहिए।
- आराम में एन्क्रिप्शन: संवेदनशील डेटा वाले डेटा स्टोर को चिह्नित किया जाना चाहिए।
2. डेटा उत्पत्ति
डेटा की उत्पत्ति को समझना संगति के लिए महत्वपूर्ण है। एक DFD एक उच्च स्तर के उत्पत्ति नक्शे के रूप में कार्य करता है। यह दिखाता है कि डेटा प्रणाली में कहाँ प्रवेश करता है और यह कैसे परिवर्तित होता है।
- सहमति ट्रैकिंग: उपयोगकर्ता सहमति डेटा वाले प्रवाहों को अलग से ट्रैक किया जाना चाहिए।
- मिटाने का अधिकार: डायग्राम में यह दिखाना चाहिए कि डेटा कहाँ संग्रहीत है ताकि मिटाने के अनुरोध को आसानी से किया जा सके।
यदि एक DFD यह नहीं दिखाता है कि डेटा कहाँ संग्रहीत है, तो संगति ऑडिट असंभव हो जाते हैं। प्रत्येक डेटा स्टोर का एक परिभाषित मालिक और रखरखाव नीति होनी चाहिए।
⚙️ आधुनिक DFD निर्माण में चुनौतियाँ
जटिल प्रणालियों के लिए सटीक आरेख बनाना विशिष्ट चुनौतियों को उत्पन्न करता है। डेटा की मात्रा और बदलाव की गति अक्सर दस्तावेजीकरण प्रयासों को पीछे छोड़ देती है।
1. गतिशील प्रणालियाँ
स्वचालित स्केलिंग समूह प्रक्रिया इकाइयों की संख्या को गतिशील रूप से बदलते हैं। एक स्थिर आरेख इसे नहीं दिखा सकता है। आरेख को प्रणाली की *क्षमता* का प्रतिनिधित्व करना चाहिए, केवल वर्तमान स्थिति का नहीं।
- विशिष्ट इंस्टेंस आईडी के बजाय “गणना समूह” जैसे सामान्य लेबल का उपयोग करें।
- प्रक्रिया विवरण में स्केलिंग ट्रिगर को दर्शाएं।
2. जटिलता प्रबंधन
जैसे-जैसे प्रणालियाँ बढ़ती हैं, DFDs पढ़ने योग्य नहीं हो जाते हैं। अब्स्ट्रैक्शन महत्वपूर्ण है। प्रत्येक API एंडपॉइंट को मैप न करें। तार्किक डेटा गति को मैप करें।
- समूहन: संबंधित प्रक्रियाओं को एकल सुपर-प्रक्रिया में जोड़ें।
- लिंकिंग: विस्तृत उप-आरेखों को उच्च स्तर के सारांशों से जोड़ने के लिए क्रॉस-रेफरेंस का उपयोग करें।
3. वास्तविक समय के निर्भरताएँ
स्ट्रीमिंग प्रणालियों में, क्रियाओं का क्रम महत्वपूर्ण होता है। DFD जुड़ाव दिखाता है, लेकिन हमेशा समय नहीं दिखाता है। यदि समय महत्वपूर्ण है, तो DFD को क्रम आरेखों के साथ पूरक करें।
- प्रक्रिया विवरणों में समय समाप्ति और पुनर्प्रयासों को दर्शाएं।
- ध्यान दें कि डेटा प्रवाह सिंक्रोनस या एसिंक्रोनस हैं या नहीं।
🚀 भविष्य के प्रवृत्तियाँ: स्वचालन और स्व-दस्तावेजीकरण
DFD का भविष्य स्वचालन में है। जैसे-जैसे प्रणालियाँ अधिक कोड-केंद्रित होती हैं, आरेखों को हाथ से बनाने के बजाय कोडबेस से उत्पन्न किया जाना चाहिए।
1. कोड के रूप में बुनियादी ढांचा (IaC)
जब बुनियादी ढांचा कोड में परिभाषित किया जाता है, तो डेटा प्रवाह बोधगम्य रूप से परिभाषित हो जाता है। उपकरण IaC फ़ाइलों को पार्स कर सकते हैं ताकि DFDs स्वचालित रूप से उत्पन्न किए जा सकें।
- आरेख और वास्तविक बुनियादी ढांचे के बीच संगतता सुनिश्चित करें।
- आरेख परिभाषाओं के लिए संस्करण नियंत्रण का उपयोग करें।
2. निरंतर खोज
नेटवर्क मॉनिटरिंग उपकरण वास्तविक डेटा प्रवाहों का पता लगा सकते हैं। इन उपकरणों को DFD सॉफ्टवेयर के साथ एकीकृत करने से “लाइव” आरेख बनाने में सक्षम होते हैं जो ट्रैफ़िक पैटर्न में बदलाव के साथ अपडेट होते हैं।
- जब नए डेटा प्रवाह दिखाई दें जिनका दस्तावेज़ीकरण नहीं किया गया है, तो चेतावनी दें।
- अनप्रयुक्त डेटा स्टोरेज को चिह्नित करें जिन्हें बंद किया जा सकता है।
3. एआई-सहायता वाला आरेखण
कृत्रिम बुद्धिमत्ता आरेखों में सुधार के सुझाव दे सकती है। यह बेस्ट प्रैक्टिस के आधार पर बॉटलनेक, आवश्यकता से अधिक मार्ग या सुरक्षा की कमी को पहचान सकती है।
- डेटा प्रवाह नियमों की स्वचालित पुष्टि (उदाहरण के लिए, प्रक्रिया के बिना डेटाबेस से बाहरी एकाधिकार तक सीधा प्रवाह नहीं होना चाहिए)।
- आदर्श प्रक्रिया विभाजन के सुझाव।
🛠️ कार्यान्वयन के लिए सर्वोत्तम प्रथाएं
आधुनिक संदर्भ में DFDs के मूल्य को बनाए रखने के लिए निम्नलिखित प्रथाओं का पालन करें।
- प्रतीकों को मानकीकृत करें: सुनिश्चित करें कि सभी टीम सदस्य एक ही प्रतीकों और प्रथाओं का उपयोग करें। संगतता मानसिक भार को कम करती है।
- नामकरण प्रथाओं को परिभाषित करें: प्रक्रियाओं के नाम वर्ब-नाउन संरचना में होने चाहिए (उदाहरण के लिए, “उपयोगकर्ता इनपुट की पुष्टि करें”)। डेटा स्टोरेज के नाम संज्ञाओं के रूप में होने चाहिए (उदाहरण के लिए, “उपयोगकर्ता प्रोफ़ाइल”)।
- नियमित रूप से समीक्षा करें: एक आरेख जिसकी समीक्षा नहीं की जाती है, एक झूठ बन जाता है। स्प्रिंट योजना या आर्किटेक्चर सुधार बैठकों के दौरान समीक्षा की योजना बनाएं।
- मूल्य पर ध्यान केंद्रित करें: केवल वे डेटा प्रवाह नक्शा बनाएं जो व्यावसायिक तर्क के लिए आवश्यक हों। अंतिम उपयोगकर्ता के लिए प्रभाव नहीं डालने वाले आवश्यकता से अधिक आंतरिक प्रवाह को हटा दें।
- मान्यताओं को दस्तावेज़ीकृत करें: यदि कोई प्रवाह एक निश्चित लेटेंसी या थ्रूपुट के बारे में मानता है, तो उसे दस्तावेज़ीकृत करें। इन मान्यताओं का सिस्टम डिज़ाइन पर प्रभाव पड़ता है।
🔄 डेटा प्रवाह का चक्र
चक्र को समझना आरेख को सटीक रूप से नक्शा बनाने में मदद करता है। डेटा कई चरणों से गुजरता है:
- ग्रहण: डेटा सिस्टम सीमा में प्रवेश करता है। यह अक्सर सबसे अस्थिर बिंदु होता है।
- प्रसंस्करण: डेटा को परिवर्तित, समृद्ध या विश्लेषित किया जाता है।
- स्टोरेज: डेटा भविष्य के उपयोग के लिए स्थायी रूप से संरक्षित किया जाता है।
- प्राप्त करना: डेटा रिपोर्टिंग या कार्रवाई के लिए प्राप्त किया जाता है।
- निपटान: नीति के अनुसार डेटा संग्रहीत किया जाता है या मिटा दिया जाता है।
प्रत्येक चरण डीएफडी में एक संभावित प्रक्रिया या स्टोर का प्रतिनिधित्व करता है। एक पूर्ण आरेख निपटान चरण को ध्यान में रखता है, जिससे सुनिश्चित होता है कि डेटा अनावश्यक रूप से नहीं रहता।
📊 मुख्य घटकों का सारांश
त्वरित संदर्भ के लिए, यहां पारंपरिक घटकों के आधुनिक समकक्षों के रूप में नक्शा दिया गया है।
| पारंपरिक अवधारणा | आधुनिक समकक्ष | विचार ध्यान में रखना |
|---|---|---|
| इनपुट | एपीआई गेटवे / इनग्रेशन पाइपलाइन | प्रमाणीकरण और दर सीमा |
| आउटपुट | डैशबोर्ड / सूचना सेवा | फॉर्मेटिंग और डिलीवरी चैनल |
| प्रक्रिया | फंक्शन / कंटेनर / मॉडल | राज्यहीनता और स्केलिंग |
| स्टोर | ऑब्जेक्ट स्टोर / नॉन-एसक्यूएल डीबी | पार्टीशनिंग और इंडेक्सिंग |
| फ्लो | घटना संदेश / एचटीटीपी अनुरोध | लेटेंसी और विश्वसनीयता |
इन अवधारणाओं को संरेखित करके टीमें आरेख बना सकती हैं जो इंजीनियरिंग, डेटा साइंस और व्यवसाय स्टेकहोल्डर्स के बीच प्रभावी संचार उपकरण के रूप में कार्य करते हैं। लक्ष्य पूर्णता नहीं, बल्कि स्पष्टता है। निर्णय लेने में सहायता करने वाला आरेख सफल है।
🔮 डेटा फ्लो विज़ुअलाइज़ेशन पर अंतिम विचार
डेटा फ्लो आरेख के सिद्धांत अनन्त हैं, लेकिन उनके अनुप्रयोग के लिए अनुकूलन की आवश्यकता होती है। जैसे-जैसे डेटा आधुनिक व्यवसायों की मुख्य संपत्ति बनता जा रहा है, इसकी गति को दृश्य रूप से दिखाने की क्षमता एक रणनीतिक लाभ है। चाहे एक सरल डेटाबेस का प्रबंधन करना हो या एक जटिल न्यूरल नेटवर्क पाइपलाइन, डीएफडी जानकारी के प्रवाह को समझने, सुरक्षित करने और अनुकूलित करने के लिए आवश्यक संरचना प्रदान करता है।
इन विधियों के साथ अपडेट रहने से यह सुनिश्चित होता है कि सिस्टम आर्किटेक्चर स्पष्ट और रखरखाव बने रहें। स्थिर दस्तावेजीकरण से गतिशील, स्वचालित दृश्यीकरण की ओर बदलाव अनिवार्य है। इस बदलाव को अपनाने वाली टीमें डिजिटल युग की जटिलताओं को संभालने के लिए बेहतर तरीके से तैयार पाएंगी।
डेटा पर ध्यान केंद्रित करें। प्रवाह का पालन करें। तर्क को सही रखें। यह प्रभावी सिस्टम डिजाइन का मूल निर्देश बना रहता है।