











In der sich stetig verändernden Landschaft der Informationstechnologie bleibt das Datengangsdiagramm (DFD) ein grundlegendes Werkzeug für die Systemanalyse. Obwohl es ursprünglich während der Ära des strukturierten Programmierens in den 1970er Jahren entwickelt wurde, hat die Nützlichkeit der Visualisierung des Datenflusses innerhalb eines Systems nicht abgenommen. Vielmehr hat sich dieser Ansatz verändert. Da Organisationen mit maschinellen Lernmodellen, verteilten Speichersystemen und Echtzeitverarbeitungsströmen konfrontiert sind, ist die Notwendigkeit, Datenpfade zu kartieren, wichtiger denn je geworden.
Dieser Leitfaden untersucht die Anpassung von DFDs an moderne rechnerische Umgebungen. Er prüft, wie herkömmliche Diagramme sich weiterentwickeln müssen, um künstliche Intelligenz-Workflows, Big-Data-Architekturen und cloud-native Infrastrukturen darzustellen, ohne auf spezifische Anbieterwerkzeuge angewiesen zu sein. Der Fokus bleibt auf der konzeptionellen Integrität des Datenflusses, der Sicherheit und der Transformation.
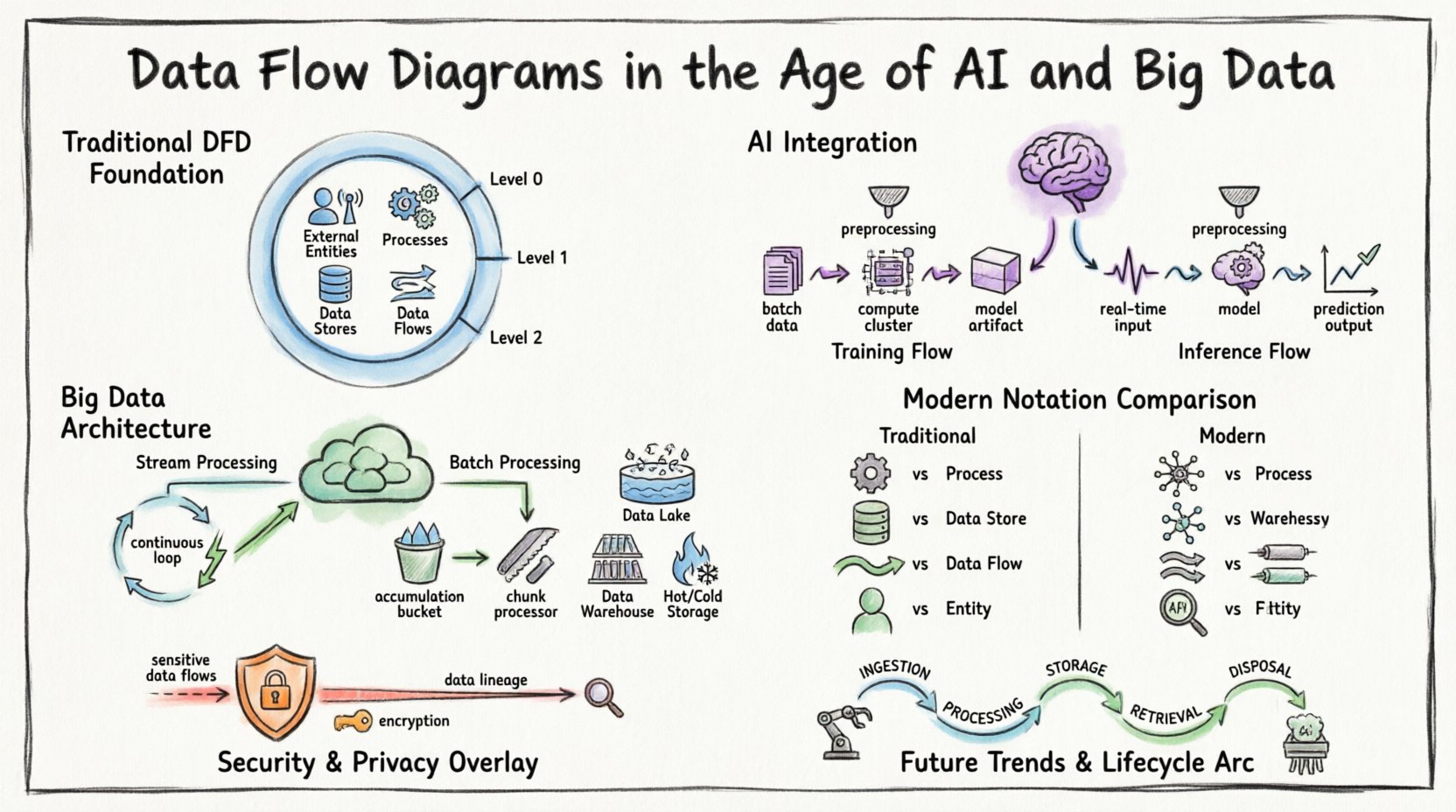
🏛️ Die Grundlage: Verständnis von Datengangsdiagrammen
Bevor man sich mit modernen Komplexitäten beschäftigt, ist es unerlässlich, die grundlegende Definition festzulegen. Ein Datengangsdiagramm ist eine grafische Darstellung des Datenflusses durch ein Informationssystem. Es modelliert die Bewegung von Informationen von externen Quellen zu Zielen und internen Prozessen.
Wichtige Komponenten definieren ein Standard-DFD:
- Externe Entitäten:Quellen oder Ziele außerhalb der Systemgrenze (z. B. Benutzer, andere Systeme, Sensoren).
- Prozesse:Transformationen, die Eingabedaten in Ausgabedaten umwandeln.
- Datenbanken:Speicherorte, an denen Daten für spätere Verwendung gehalten werden (z. B. Datenbanken, Dateisysteme).
- Datenflüsse:Die Bewegung von Daten zwischen Entitäten, Prozessen und Speichern.
In traditionellen Kontexten wurden diese Diagramme oft auf mehreren Abstraktionsstufen gezeichnet:
- Kontextdiagramm (Ebene 0):Zeigt das System als einen einzigen Prozess und seine Interaktionen mit externen Entitäten.
- Ebene-1-Diagramm:Zerlegt den Hauptprozess in wesentliche Unterverarbeitungen.
- Ebene-2-Diagramm:Weitere Zerlegung spezifischer Unterverarbeitungen für detaillierte Darstellung.
Obwohl diese Hierarchie weiterhin gültig ist, hat sich die Natur des „Prozesses“ verändert. Ein Prozess ist nicht länger nur ein Batch-Job; er ist oft ein kontinuierlicher Dienst oder ein vorhersagendes Modell.
🧠 KI-Integration: Modellierung von Intelligenz in Flüssen
Die Integration von künstlicher Intelligenz (KI) führt neue Variablen in die Datenflussdarstellung ein. In traditionellen Systemen ist die Logik explizit. In KI-getriebenen Systemen ist die Logik oft probabilistisch. Diese Unterscheidung erfordert eine Veränderung in der Art und Weise, wie wir die Komponente „Prozess“ in einem DFD visualisieren.
1. Trainings- vs. Inferenzflüsse
Maschinelles Lernpfeile unterscheiden sich erheblich von der Standardanwendungslogik. Ein DFD für ein KI-System muss zwischen der Trainingsphase und der Inferenzphase unterscheiden.
- Trainingsfluss:Beinhaltet große Datensätze, die von Speicher zu Rechenclustern fließen. Die Ausgabe ist ein trainiertes Modell. Dieser Fluss ist oft batchorientiert und ressourcenintensiv.
- Inferenzfluss:Beinhaltet Echtzeit- oder nahezu Echtzeit-Daten, die in das Modell eingegeben werden, um Vorhersagen zu generieren. Dieser Fluss legt Wert auf geringe Latenz und hohe Durchsatzgeschwindigkeit.
Beim Abbilden dieser Flüsse ist es entscheidend zu beachten, dass das Modell selbst als schwarzes Kasten-Verfahren fungiert. Die interne Logik bleibt verborgen, aber die Eingabeanforderungen und Ausgabeformate müssen im Diagramm eindeutig definiert sein.
2. Datenbereinigung als Prozess
Bevor Daten ein KI-Modell erreichen, unterliegen sie einer erheblichen Transformation. Die Merkmalsgenerierung, Normalisierung und Bereinigung sind entscheidende Schritte, die im DFD sichtbar sein müssen. Das Ignorieren dieser Schritte führt zu einem unvollständigen Systemverständnis.
- Normalisierung: Skalierung der Daten, um die Erwartungen des Modells zu erfüllen.
- Codierung: Umwandlung kategorischer Daten in numerische Vektoren.
- Imputation: Behandlung fehlender Werte innerhalb des Flusses.
Diese Vorverarbeitungsschritte sind Prozesse. Sie verbrauchen Zeit und Rechenressourcen und führen potenzielle Ausfallpunkte ein, die im Datenfluss verfolgt werden müssen.
🌊 Big Data: Umgang mit Volumen, Geschwindigkeit und Vielfalt
Big-Data-Architekturen stellen die lineare Natur traditioneller DFDs in Frage. Daten kommen oft als Ströme an, verbleiben in Data Lakes und werden über verteilte Verarbeitung verarbeitet. Ein statisches Diagramm kann die dynamische Natur dieser Umgebungen nicht leicht abbilden.
1. Streaming vs. Batch-Verarbeitung
Moderne Systeme verwenden oft einen hybriden Ansatz. Einige Daten werden in Echtzeitströmen verarbeitet, während andere Daten für die Batch-Analyse aggregiert werden. Das DFD muss diese beiden Pfade klar abgrenzen.
- Stream-Verarbeitung: Daten fließen kontinuierlich. Das Diagramm sollte die Pipeline als kontinuierlichen Kreislauf darstellen, anstatt eine Start- und Stop-Sequenz.
- Batch-Verarbeitung: Daten sammeln sich über die Zeit und werden in Teilen verarbeitet. Das Diagramm sollte den Ansammlungspunkt (Datenbank) vor Beginn des Prozesses darstellen.
2. Visualisierung verteilter Speicherung
In einer monolithischen Datenbank ist ein Datenbank-Element ein einzelnes Feld. In einer Big-Data-Umgebung ist die Speicherung verteilt. Das DFD sollte anzeigen, dass ein „Datenbank-Element“ tatsächlich einen Knotencluster oder ein partitioniertes Speichersystem darstellen kann.
- Data Lakes: Rohdatenspeicherung, bei der die Struktur später hinzugefügt wird.
- Data-Warehouses:Strukturierte Speicherung, optimiert für Abfragen.
- Heiß- vs. Kalt-Speicherung:Unterscheidung zwischen häufig zugegriffenen Daten und Archivdaten.
Diese Unterscheidung ist entscheidend für das Verständnis der Latenz. Ein Fluss von einem Hot-Speicher-Knoten verhält sich anders als ein Fluss aus einem Kalt-Speicher-Archiv.
📐 Modernisierung der Notation
Um komplexe Systeme effektiv zu kommunizieren, muss die Notation in DFDs sich anpassen. Während die Grundsymbole ähnlich bleiben, erfordert ihre Anwendung Feinheit.
| Komponente | Traditionelles DFD | Modernes AI/Big-Data-Diagramm |
|---|---|---|
| Prozess | Einzelner Transformations-Schritt | Mikroservice, Modell-Inferenz oder Pipelinestufe |
| Datenbank | Datei oder Datenbanktabelle | Data Lake, verteilter Cache oder Objektspeicher |
| Datenfluss | Anfrage/Antwort oder Dateiübertragung | Ereignisstrom, API-Payload oder Nachrichtenwarteschlange |
| Entität | Menschlicher Benutzer oder veraltete Systeme | IoT-Gerät, Drittanbieter-API oder autonomer Agent |
1. Ereignisgesteuerte Architektur
Viele moderne Systeme basieren auf Ereignissen anstelle direkter Anfragen. Ein DFD für ein ereignisgesteuertes System verwendet Auslöser, um Prozesse zu starten. Anstatt dass ein Prozess auf Daten wartet, löst die Ankunft der Daten den Prozess aus.
- Nachrichtenwarteschlangen: Funktionieren als Puffer zwischen Produzenten und Verbrauchern.
- Ereignisprotokolle: Unveränderliche Aufzeichnungen von Zustandsänderungen, die als Datenquellen für Audits dienen.
Die Darstellung dieser Warteschlangen als Datenbanken hilft, Rückdruckprobleme zu klären. Wenn ein Prozess der Zufuhr nicht folgen kann, wächst die Warteschlange. Dieses Risiko muss dokumentiert werden.
2. Mikroservices und Grenzen
Wenn Systeme in Mikroservices zerlegt werden, wird die Systemgrenze in einem DFD durchlässiger. Datenflüsse überschreiten häufig Dienstgrenzen über APIs. Es ist wichtig, das verwendete Protokoll (z. B. REST, gRPC, GraphQL) auf den Datenflusslinien anzugeben, um Kompatibilitätsanforderungen zu kennzeichnen.
- Dienstentdeckung:Dynamische Weiterleitung von Datenflüssen.
- Lastverteilung:Verteilung von Datenflüssen über mehrere Instanzen.
🔒 Sicherheit und Datenschutz in Datenflüssen
Sicherheit kann in einem Datenflussdiagramm keine Nachüberlegung sein. Bei Vorschriften wie der DSGVO und CCPA ist es zwingend erforderlich, zu verstehen, wo sensible Daten gespeichert und bewegt werden.
1. Identifizierung sensibler Daten
Datenströme, die personenbezogene Informationen (PII) oder geschützte Gesundheitsinformationen (PHI) enthalten, müssen hervorgehoben werden. Verwenden Sie unterschiedliche Linienstile oder Farben, um sensible Ströme zu kennzeichnen.
- Verschlüsselung im Transit: Alle Ströme, die Netzwerkgrenzen überschreiten, sollten Verschlüsselungsprotokolle (z. B. TLS) angeben.
- Verschlüsselung im Ruhezustand: Datenbanken, die sensible Daten enthalten, müssen gekennzeichnet werden.
2. Datenherkunft
Das Verständnis der Herkunft von Daten ist für die Einhaltung von Vorschriften entscheidend. Ein DFD dient als Karte der Datenherkunft auf hoher Ebene. Er zeigt, wo Daten in das System eintreten und wie sie sich verändern.
- Einwilligungsnachverfolgung:Ströme, die Benutzereinwilligungsdaten betreffen, müssen separat verfolgt werden.
- Recht auf Löschung:Diagramme müssen zeigen, wo Daten gespeichert werden, um Löschanfragen zu erleichtern.
Wenn ein DFD nicht zeigt, wo Daten gespeichert werden, werden Compliance-Audits unmöglich. Jeder Datenspeicher muss einen festgelegten Besitzer und eine Aufbewahrungsrichtlinie haben.
⚙️ Herausforderungen bei der Erstellung moderner DFDs
Die Erstellung genauer Diagramme für komplexe Systeme birgt spezifische Herausforderungen. Das Datenvolumen und die Geschwindigkeit der Veränderungen übertreffen oft die Dokumentationsbemühungen.
1. Dynamische Systeme
Auto-Scaling-Gruppen ändern die Anzahl der Prozessinstanzen dynamisch. Ein statisches Diagramm kann dies nicht darstellen. Das Diagramm muss die *Fähigkeit* des Systems, nicht nur den aktuellen Zustand, darstellen.
- Verwenden Sie generische Bezeichnungen wie „Rechencluster“ anstelle spezifischer Instanz-IDs.
- Geben Sie Skalierungsauslöser in der Prozessbeschreibung an.
2. Komplexitätsmanagement
Je größer die Systeme werden, desto unlesbarer werden die DFDs. Abstraktion ist entscheidend. Zeichnen Sie nicht jeden API-Endpunkt ab. Zeichnen Sie stattdessen die logische Datenbewegung auf.
- Gruppierung:Kombinieren Sie verwandte Prozesse zu einem einzigen Super-Prozess.
- Verknüpfung:Verwenden Sie Querverweise, um detaillierte Unterdigramme mit übersichtlichen Gesamtdiagrammen zu verknüpfen.
3. Echtzeitabhängigkeiten
Bei Streaming-Systemen ist die Reihenfolge der Operationen entscheidend. Ein DFD zeigt die Verbindung, aber nicht immer die zeitliche Abfolge. Ergänzen Sie DFDs bei kritischer Zeitplanung durch Ablaufdiagramme.
- Geben Sie Zeitüberschreitungen und Wiederholversuche in der Prozessbeschreibung an.
- Notieren Sie, ob Datenströme synchron oder asynchron sind.
🚀 Zukünftige Trends: Automatisierung und Selbst-Dokumentation
Die Zukunft der DFDs liegt in der Automatisierung. Da Systeme zunehmend codezentriert werden, sollten Diagramme aus dem Codebase generiert werden, anstatt manuell gezeichnet zu werden.
1. Infrastruktur als Code (IaC)
Wenn die Infrastruktur im Code definiert ist, ist der Datenfluss implizit definiert. Werkzeuge können IaC-Dateien parsen, um DFDs automatisch zu generieren.
- Stellen Sie die Konsistenz zwischen dem Diagramm und der tatsächlichen Infrastruktur sicher.
- Verwenden Sie Versionskontrolle für die Diagrammdefinitionen selbst.
2. Kontinuierliche Entdeckung
Netzwerküberwachungstools können tatsächliche Datenflüsse erkennen. Die Integration dieser Tools mit DFD-Software ermöglicht „live“ Diagramme, die sich aktualisieren, wenn sich Verkehrsstrukturen ändern.
- Warnen Sie, wenn neue Datenflüsse auftauchen, die nicht dokumentiert sind.
- Kennzeichnen Sie nicht genutzte Datenbanken, die abgeschaltet werden können.
3. KI-gestütztes Diagrammieren
Künstliche Intelligenz kann Verbesserungsvorschläge für Diagramme machen. Sie kann Engpässe, überflüssige Pfade oder Sicherheitslücken basierend auf Best Practices identifizieren.
- Automatisierte Überprüfung von Datenflussregeln (z. B. kein direkter Fluss von Datenbank zu externer Entität ohne Prozess).
- Vorschlag einer optimalen Prozessaufteilung.
🛠️ Best Practices für die Umsetzung
Um den Wert von DFDs in einem modernen Kontext zu erhalten, halten Sie sich an folgende Praktiken.
- Standardisieren Sie die Notation:Stellen Sie sicher, dass alle Teammitglieder die gleichen Symbole und Konventionen verwenden. Konsistenz reduziert die kognitive Belastung.
- Definieren Sie Namenskonventionen:Prozesse sollten mit Verben-Nomen-Strukturen benannt werden (z. B. „Benutzereingabe validieren“). Datenbanken sollten als Nomen benannt werden (z. B. „Benutzerprofile“).
- Überprüfen Sie regelmäßig:Ein Diagramm, das nicht überprüft wird, wird zu einer Lüge. Planen Sie Überprüfungen während der Sprint-Planung oder Architektur-Refinementsitzungen.
- Konzentrieren Sie sich auf den Wert:Zeichnen Sie nur Datenflüsse auf, die für die Geschäftslogik notwendig sind. Entfernen Sie überflüssige interne Flüsse, die den Endbenutzer nicht beeinflussen.
- Dokumentieren Sie Annahmen: Wenn ein Fluss eine bestimmte Latenz oder Durchsatzrate annimmt, dokumentieren Sie dies. Diese Annahmen beeinflussen die Systemarchitektur.
🔄 Der Lebenszyklus eines Datenflusses
Das Verständnis des Lebenszyklus hilft bei der genauen Abbildung des Diagramms. Daten durchlaufen mehrere Stadien:
- Aufnahme:Daten treten die Systemgrenze. Dies ist oft der volatilste Punkt.
- Verarbeitung:Daten werden transformiert, bereichert oder analysiert.
- Speicherung:Daten werden für zukünftige Verwendung persistiert.
- Abruf:Daten werden für Berichterstattung oder Aktionen abgerufen.
- Beseitigung:Daten werden gemäß Richtlinie archiviert oder gelöscht.
Jeder Phase entspricht ein potenzieller Prozess oder Speicher im DFD. Ein vollständiges Diagramm berücksichtigt die Beseitigungsphase, um sicherzustellen, dass Daten nicht unnötig verbleiben.
📊 Zusammenfassung der wichtigsten Komponenten
Zur schnellen Referenz finden Sie hier eine Aufschlüsselung, wie traditionelle Komponenten modernen Äquivalenten entsprechen.
| Traditionelles Konzept | Modernes Äquivalent | Berücksichtigung |
|---|---|---|
| Eingabe | API-Gateway / Ingestions-Pipeline | Authentifizierung und Rate Limiting |
| Ausgabe | Dashboard / Benachrichtigungsdienst | Formatierung und Zustellkanal |
| Prozess | Funktion / Container / Modell | Zustandslosigkeit und Skalierbarkeit |
| Speicher | Objektspeicher / NoSQL-Datenbank | Partitionierung und Indizierung |
| Fluss | Ereignisnachricht / HTTP-Anfrage | Latenz und Zuverlässigkeit |
Durch die Ausrichtung dieser Konzepte können Teams Diagramme erstellen, die als effektive Kommunikationsmittel für Ingenieure, Datenwissenschaftler und Geschäftspartner dienen. Das Ziel ist nicht Perfektion, sondern Klarheit. Ein Diagramm, das bei Entscheidungsprozessen hilft, ist erfolgreich.
🔮 Abschließende Gedanken zur Datenflussvisualisierung
Die Prinzipien von Datenflussdiagrammen sind zeitlos, ihre Anwendung erfordert jedoch Anpassung. Da Daten zur zentralen Ressource moderner Unternehmen werden, ist die Fähigkeit, deren Bewegung zu visualisieren, ein strategischer Vorteil. Unabhängig davon, ob ein einfacher Datenbank- oder ein komplexer Neuronales-Netz-Pipeline verwaltet wird, bietet das DFD die notwendige Struktur, um den Informationsfluss zu verstehen, zu sichern und zu optimieren.
Die aktuelle Behandlung dieser Methoden stellt sicher, dass Systemarchitekturen transparent und wartbar bleiben. Der Übergang von statischer Dokumentation zu dynamischer, automatisierter Visualisierung ist unvermeidlich. Teams, die diesen Wandel annehmen, werden feststellen, dass sie besser gerüstet sind, um die Komplexitäten des digitalen Zeitalters zu bewältigen.
Konzentrieren Sie sich auf die Daten. Verfolgen Sie den Fluss. Stellen Sie sicher, dass die Logik stimmt. Dies bleibt die zentrale Aufgabe einer effektiven Systemgestaltung.