











In der Architektur komplexer Softwaresysteme ist Klarheit die Währung des Erfolgs. Bevor eine einzige Zeile Logik geschrieben wird, muss die Bewegung von Informationen verstanden werden. Hier kommt das Datenflussdiagramm (DFD) unverzichtbar ins Spiel. Ein DFD visualisiert, wie Daten in ein System eintreten, wie sie verarbeitet werden, wo sie gespeichert werden und wie sie das System verlassen. Es ist eine strukturelle Bauplanung, die das „Was“ vom „Wie“ trennt. Im Gegensatz zum Code, der spezifische Implementierungsdetails vorgibt, konzentriert sich ein DFD auf den logischen Fluss von Informationen über das gesamte Ökosystem hinweg.
Viele Teams stürzen ohne eine solide visuelle Darstellung des Datenflusses direkt ins Codieren. Dies führt zu Spaghetti-Logik, überflüssigen Datenbankabfragen und Schnittstellen, die nicht mit den Geschäftsprozessen übereinstimmen. Durch die Beherrschung der Erstellung und Interpretation von DFDs stellen Architekten sicher, dass die Grundlage des Systems seinem vorgesehenen Zweck entspricht. Diese Anleitung beschreibt die Mechanismen, Regeln und bewährten Praktiken zur Erstellung effektiver Diagramme, die die Lücke zwischen abstrakten Anforderungen und konkreter Implementierung schließen.
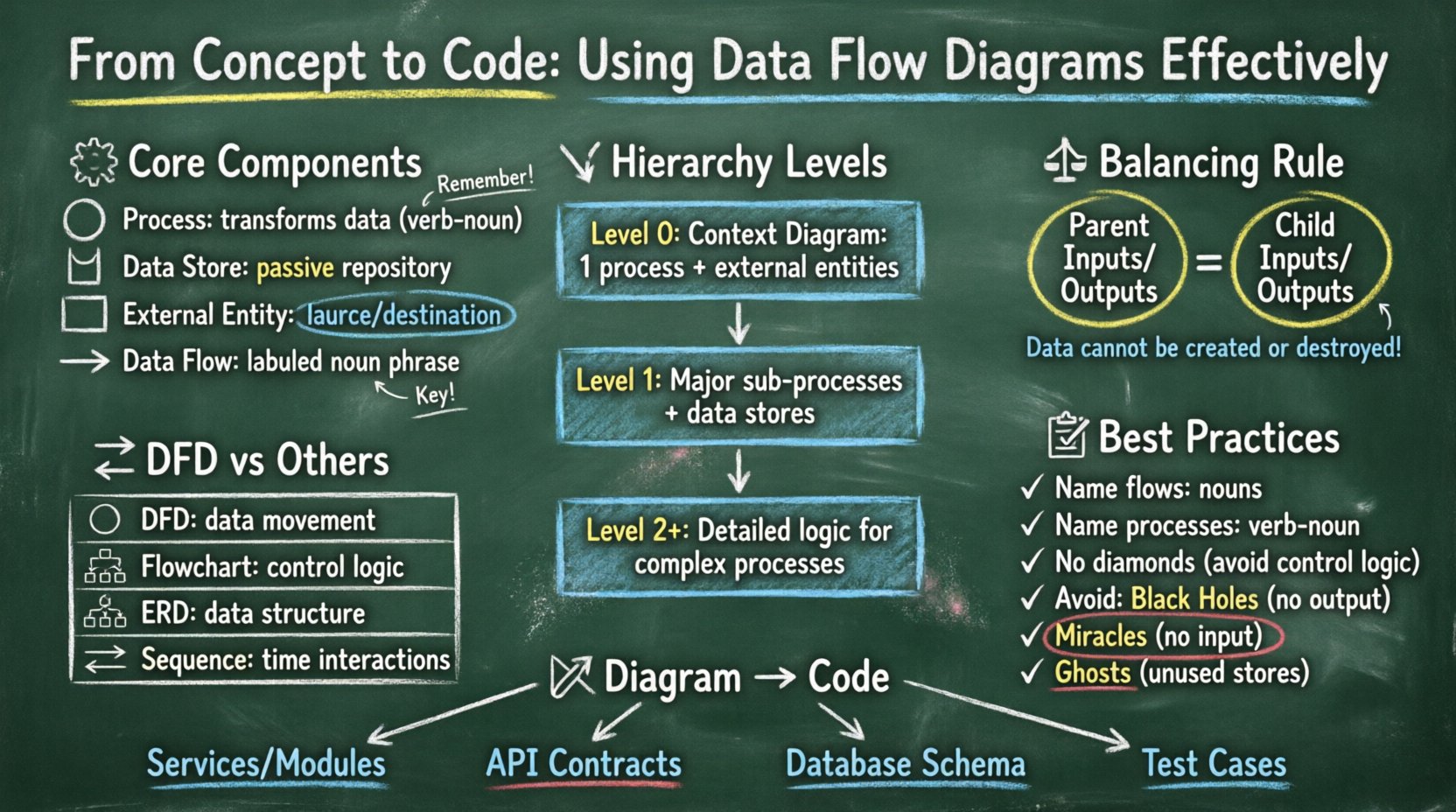
🧩 Verständnis der zentralen Komponenten eines DFD
Ein Datenflussdiagramm ist eine grafische Darstellung des Datenflusses durch ein Informationssystem. Es zeigt nicht die Steuerungsflüsse wie Schleifen oder Entscheidungszweige, sondern vielmehr die Daten selbst. Um ein gültiges Diagramm zu erstellen, muss man die vier grundlegenden Symbole verstehen, die in der Standardnotation verwendet werden.
- Prozess:Dargestellt durch einen Kreis oder ein abgerundetes Rechteck, transformiert ein Prozess eingehende Datenflüsse in ausgehende Datenflüsse. Er steht für eine Änderung, Berechnung oder Aggregation. Ein Prozess kann nicht isoliert existieren; er muss mindestens eine Eingabe und eine Ausgabe haben.
- Datenbank:Dargestellt als offenes Rechteck oder parallele Linien, steht dieses Symbol für eine Datenbank. Es handelt sich um passiven Speicher, in dem Daten zwischen Prozessen verbleiben. Beispiele sind Datenbanktabellen, flache Dateien oder in-Memory-Caches.
- Externe Entität:Auch als Terminierer bekannt, ist dies ein Rechteck, das eine Quelle oder ein Ziel von Daten außerhalb der Systemgrenzen darstellt. Es könnte ein Benutzer, ein anderes System oder ein physisches Gerät sein.
- Datenfluss:Dargestellt als Linie mit Pfeil, zeigt dies die Bewegung von Daten zwischen Komponenten an. Es steht für die Daten selbst, nicht für das physische Signal. Jeder Fluss muss eine sinnvolle Beschriftung haben, die den Inhalt beschreibt.
Das Verständnis des Unterschieds zwischen diesen Komponenten ist entscheidend. Ein häufiger Fehler besteht darin, einen Datenfluss direkt von einer externen Entität zur anderen zu zeichnen, wobei das System umgangen wird. Dies bedeutet, dass das System die Daten nicht verarbeitet, was gegen den Rahmen der Analyse verstößt. Ebenso deutet eine direkte Verbindung zwischen einer Datenbank und einer externen Entität ohne Prozess auf unbefugten Zugriff oder fehlende Kontrolle hin.
📉 Die Hierarchie der DFD-Ebenen
Datenflussdiagramme sind nicht statisch; sie sind hierarchisch aufgebaut. Dadurch kann ein System von einer hochwertigen Übersicht bis hin zu feinen Details beschrieben werden. Diese Zerlegung hilft, die Komplexität zu bewältigen, indem das System in handhabbare Teile zerlegt wird. Es gibt drei Hauptebenen der Zerlegung.
1. Kontextdiagramm (Ebene 0)
Das Kontextdiagramm bietet die höchste Abstraktionsebene. Es stellt das gesamte System als einen einzigen Prozess dar und zeigt dessen Interaktion mit externen Entitäten. Dieses Diagramm beantwortet die Frage: „Was ist das System?“ Es ist für Stakeholder nützlich, die einen schnellen Überblick benötigen, ohne in interne Details verstrickt zu werden.
- Umfang:Ein zentraler Prozess, der das gesamte System darstellt.
- Entitäten:Alle externen Quellen und Ziele.
- Flüsse:Wichtige Daten-Eingaben und -Ausgaben.
2. Ebene-1-Diagramm
Das Ebene-1-Diagramm zerlegt den einzelnen Prozess aus dem Kontextdiagramm in wesentliche Unterverarbeitungen. Dies ist die am häufigsten verwendete Ebene für die Dokumentation der Systemarchitektur. Es zeigt die wichtigsten funktionalen Bereiche des Systems auf. Jede hier identifizierte Hauptfunktion wird zu einem eigenständigen Prozessknoten.
- Umfang:Wichtige funktionale Module.
- Interaktionen:Daten bewegen sich zwischen diesen Modulen und externen Entitäten.
- Speicher:Primäre Datenbanken oder Dateisysteme werden eingeführt.
3. Ebene 2 und darunter
Ebene-2-Diagramme zerlegen spezifische Prozesse aus dem Diagramm der Ebene 1 in größere Detailgenauigkeit. Dies ist reserviert für komplexe Prozesse, die erhebliche Logik oder Datenverarbeitung beinhalten. Eine Überdekomposition auf dieser Ebene kann zu Diagrammen führen, die zu groß zum Lesen sind, daher wird Vorsicht empfohlen. In der Regel rechtfertigen nur die komplexesten Funktionen diese Tiefe.
⚖️ Das Prinzip der Balance
Eine der wichtigsten Regeln bei der Erstellung von DFDs ist die Balance. Die Balance stellt sicher, dass die Eingaben und Ausgaben eines übergeordneten Prozesses mit den Eingaben und Ausgaben seiner untergeordneten Prozesse übereinstimmen. Wenn ein übergeordneter Prozess einen Eingabestrom „Bestellanfrage“ hat, muss der untergeordnete Prozess ebenfalls eine „Bestellanfrage“ (oder eine logisch zusammengefasste Teilmenge davon) akzeptieren.
Die Verletzung dieser Regel führt zu Inkonsistenzen. Ein Entwickler, der das untergeordnete Diagramm liest, könnte eine Eingabe sehen, die das übergeordnete Diagramm als niemals auftretend beschreibt. Dies führt zu Implementierungsfehlern. Beim Zerlegen eines Prozesses müssen Sie sicherstellen:
- Alle Datenströme, die in den übergeordneten Prozess eintreten, müssen auch in die untergeordneten Prozesse eintreten.
- Alle Datenströme, die aus den untergeordneten Prozessen austreten, müssen auch aus dem übergeordneten Prozess austreten.
- Es werden keine neuen Datenströme eingeführt, ohne dass dies im Kontext des übergeordneten Prozesses gerechtfertigt ist.
- Es werden keine bestehenden Ströme bei der Zerlegung verloren.
Stellen Sie sich die Balance als ein Erhaltungsgesetz für Daten vor. Daten können innerhalb der Systemgrenzen nicht geschaffen oder zerstört werden; sie werden lediglich transformiert. Dieses Prinzip zwingt den Architekten, jede Datenmenge, die das System betritt oder verlässt, zu rechtfertigen.
🔄 DFD im Vergleich zu anderen Diagrammtechniken
Verwirrung entsteht oft zwischen DFDs, Ablaufdiagrammen und Entitäts-Beziehungs-Diagrammen (ERD). Obwohl sie alle Systeme modellieren, dienen sie unterschiedlichen Zwecken. Die Verwendung des falschen Diagramms für eine bestimmte Aufgabe kann das Designziel verschleiern.
| Diagrammtyp | Hauptfokus | Am besten geeignet für |
|---|---|---|
| Datenflussdiagramm (DFD) | Logische Bewegung von Daten | Systemanalyse, Definition von Systemgrenzen, Datenumwandlung |
| Ablaufdiagramm | Steuerfluss und Logik | Algorithmusentwurf, Entscheidungspfade, spezifische Prozesslogik |
| Entitäts-Beziehungs-Diagramm (ERD) | Datenstruktur und Beziehungen | Entwurf von Datenbank-Schemata, Datenmodellierung, Speicher-Normalisierung |
| Sequenzdiagramm | Interaktion über die Zeit | API-Aufrufe, Benutzersitzungsabläufe, zeitliche Abhängigkeiten |
Zum Beispiel, wenn Sie definieren müssen, wie ein Benutzer-Authentifizierungstoken validiert wird, könnte ein Ablaufdiagramm besser geeignet sein, um die Pass/Fail-Logik darzustellen. Wenn Sie definieren müssen, wo dieser Token gespeichert und abgerufen wird, zeigt ein DFD den Fluss zum Speicher, während ein ERD die Struktur der Speichertabelle zeigt. Ein DFD liefert die funktionale Karte, während die anderen Diagramme die strukturellen und logischen Details liefern.
🛠 Gestaltungsprinzipien und Best Practices
Ein Diagramm zu erstellen, geht nicht nur darum, Kästchen und Pfeile zu zeichnen. Es erfordert die Einhaltung von Konventionen, die sicherstellen, dass das Diagramm über die Zeit hinweg lesbar und genau bleibt. Die Einhaltung dieser Prinzipien verhindert Dokumentationsdrift, bei der das Diagramm nicht mehr mit dem Code übereinstimmt.
1. Benennungskonventionen
Beschriftungen sind der Text, der Bedeutung trägt. Ein DFD ohne klare Beschriftungen ist nutzlos. Jeder Datenfluss muss ein Substantiv-Phrasen enthalten (z. B. „Benutzer-ID“, „Transaktionsprotokoll“). Jeder Prozess muss eine Verbal-Phrasen enthalten (z. B. „Passwort überprüfen“, „Rechnung generieren“). Diese grammatische Unterscheidung hilft, die Aktion vom Inhalt zu trennen.
- Prozessnamen: Verben-Substantiv-Struktur. Vermeiden Sie Einzelwörter wie „Prozess“ oder „Logik“.
- Datenflussnamen: Substantiv-Phrasen, die das Informationspaket beschreiben.
- Datenbankspeicher-Namen: Substantiv-Phrasen, singular oder plural, die die Sammlung anzeigen (z. B. „Kundenakten“).
2. Vermeidung von Steuerlogik
Ein häufiger Fehler ist die Einbeziehung von Steuerlogik in ein DFD. DFDs beschreiben Datenbewegung, nicht Entscheidungsfindung. Sie sollten kein Diamant-Symbol zeichnen, das einen „Ja/Nein“-Zweig anzeigt. Falls eine Entscheidung vorliegt, handelt es sich um einen Prozess, der Daten filtert. Der Fluss sollte zeigen, wie die Daten in den Prozess eintreten und welche spezifischen Datentypen verlassen. Zum Beispiel zeigen Sie statt eines Zweigs zwei Flüsse: „Genehmigter Auftrag“ und „Abgelehnter Auftrag“, die von einem „Auftrag verarbeiten“-Knoten ausgehen.
3. Umgang mit Schwarzen Löchern und Wundern
Bei der Systemanalyse müssen bestimmte Anomalien vermieden werden:
- Schwarzes Loch: Ein Prozess, der Eingaben hat, aber keine Ausgaben. Dies bedeutet, dass Daten verbraucht werden, ohne dass ein Ergebnis entsteht.
- Wunder: Ein Prozess, der Ausgaben hat, aber keine Eingaben. Dies bedeutet, dass Daten aus dem Nichts entstehen.
- Geist: Ein Datenbankspeicher, der keine Datenflüsse hat. Dies zeigt an, dass ein Speicherort niemals genutzt wird.
Die Erkennung dieser Anomalien in der Entwurfsphase spart erhebliche Debugging-Zeit später. Wenn ein Prozess keine Ausgabe hat, liefert das System keinen Wert für diese Eingabe. Wenn ein Speicher keine Eingabe hat, ist er leer und irrelevant.
🔗 Vom Diagramm zum Code: Umsetzungsstrategie
Sobald das DFD abgeschlossen ist, dient es als Vertrag für das Entwicklungsteam. Die Umsetzung dieses visuellen Modells in ausführbaren Code erfordert einen systematischen Ansatz. Das Diagramm beeinflusst die Architektur, die Datenbank-Schemata und die API-Endpunkte.
1. Identifizierung von Diensten und Modulen
Jeder Prozess im Level-1-Diagramm entspricht oft einem Mikroservice, einem Modul oder einer Klasse. Zum Beispiel könnte ein Prozess namens „Steuer berechnen“ zu einer spezialisierten Funktion innerhalb eines Rechnungsmoduls werden. Ein Prozess namens „Benutzerprofil verwalten“ könnte einem Benutzerdienst zugeordnet werden. Diese Zuordnung stellt sicher, dass die Code-Struktur die Geschäftslogik widerspiegelt.
2. Definition von API-Verträgen
Datenflüsse zwischen externen Entitäten und Prozessen übersetzen sich oft in API-Anfragen und -Antworten. Wenn eine Entität „Registrierungsdaten“ an einen Prozess sendet, muss der entsprechende API-Endpunkt eine Nutzlast akzeptieren, die dieser Datenstruktur entspricht. Das DFD legt die Eingabe- und Ausgabeschemata für diese Endpunkte fest. Dies reduziert den Bedarf an iterativen Abstimmungen zwischen Frontend- und Backend-Teams.
3. Datenbank-Schemagenerierung
Datenbanken im DFD repräsentieren die Persistenzschicht. Obwohl ein DFD keine Felder oder Schlüssel zeigt, identifiziert er, welche Daten gespeichert werden müssen. „Auftragsverlauf“ impliziert eine Tabelle oder Sammlung für Aufträge. „Aktive Sitzungen“ impliziert einen Speicher für Benutzerzustände. Entwickler können das DFD nutzen, um festzulegen, welche Tabellen kritisch sind, und sicherzustellen, dass die Beziehungen zwischen Datenbanken mit dem Informationsfluss übereinstimmen.
4. Validierung und Testen
Testfälle können direkt aus den Datenflüssen abgeleitet werden. Jeder Pfeil stellt einen potenziellen Testpfad dar. „Wenn ich eine Bestellung sende, gibt das System eine Rechnung zurück?“ Diese Rückverfolgbarkeit stellt sicher, dass jeder Codezeile ein in der ursprünglichen Gestaltung definiertes Ziel dient. Sie verhindert „Feature-Creep“, bei dem Code hinzugefügt wird, der nicht im Datenfluss erscheint.
🛡 Wartungs- und Dokumentations-Lebenszyklus
Eine Darstellung ist nur so gut wie ihre Aktualität. Ein DFD, der das aktuelle System nicht widerspiegelt, wird zu technischem Schulden. Er täuscht neue Entwickler und verschleiert die eigentliche Logik. Daher ist Wartung Teil des Entwicklungslebenszyklus.
- Versionsverwaltung:Behandle den DFD wie Code. Wenn sich das System ändert, muss die Darstellung aktualisiert werden. Kennzeichne Versionen, um sie mit Software-Releases abzugleichen.
- Überprüfungszyklen:Integriere DFD-Updates in die Code-Überprüfungsprozesse. Wenn ein Entwickler einen neuen Datenfluss hinzufügt, muss er die Darstellung aktualisieren.
- Zugänglichkeit:Halte Diagramme im selben Repository oder Dokumentationssystem wie den Code. Dadurch wird sichergestellt, dass sie nicht verloren gehen, wenn das Team Werkzeuge wechselt.
- Vereinfachung:Wenn ein Diagramm zu komplex wird, überlege, es zu teilen. Eine einzige Seite mit 50 Prozessen ist schwer lesbar. Modulare Diagramme sind einfacher zu pflegen.
Regelmäßige Überprüfungen des Diagramms gegenüber dem Codebase offenbaren Diskrepanzen. Gibt es Datenspeicher im Code, die nicht im Diagramm enthalten sind? Gibt es Prozesse im Diagramm, die bereits umgeschrieben wurden? Die Behebung dieser Lücken erhält die Integrität der Systemdokumentation.
🌟 Zusammenfassung der Vorteile
Die Umsetzung eines disziplinierten Ansatzes für Datenflussdiagramme bringt greifbare Ergebnisse. Sie zwingt das Team, zuerst über Daten und nicht über Logik nachzudenken. Sie bietet eine gemeinsame Sprache für Stakeholder, die Code möglicherweise nicht verstehen, aber Geschäftsprozesse kennen. Sie dient als Kommunikationsbrücke zwischen Analysten, Architekten und Entwicklern.
Durch Einhaltung der Regeln zur Ausgewogenheit, Vermeidung von Steuerlogik und Aufrechterhaltung der Hierarchie der Ebenen können Teams Diagramme erstellen, die sowohl genau als auch nützlich sind. Der Übergang von der Idee zur Umsetzung wird reibungsloser, weil das Ziel klar abgebildet ist. Datenflüsse werden validiert, Speicherung gerechtfertigt und externe Interaktionen definiert. Dadurch wird Wiederaufwand reduziert, Unsicherheiten minimiert und ein System geschaffen, das von Grund auf robust ist.
Beginne mit dem Kontextdiagramm. Zerlege sorgfältig. Gleiche deine Flüsse aus. Halte deine Beschriftungen präzise. Und denke daran, dass das Diagramm ein lebendiges Artefakt ist, kein einmaliger Liefergegenstand. Mit diesen Praktiken wird die Komplexität moderner Systeme beherrschbar, und der Weg von der Idee zur Umsetzung bleibt klar.