











Dans l’architecture des systèmes logiciels complexes, la clarté est la monnaie du succès. Avant d’écrire la moindre ligne de logique, il est essentiel de comprendre le déplacement des informations. C’est là que le diagramme de flux de données (DFD) devient indispensable. Un DFD visualise la manière dont les données entrent dans un système, comment elles sont transformées, où elles sont stockées et comment elles en sortent. Il s’agit d’un plan structurel qui sépare le « quoi » du « comment ». Contrairement au code, qui impose des détails d’implémentation précis, un DFD se concentre sur le flux logique des informations à travers l’ensemble de l’écosystème.
De nombreuses équipes se précipitent dans le codage sans avoir de représentation visuelle solide du déplacement des données. Cela entraîne une logique en spaghetti, des requêtes redondantes sur la base de données et des interfaces qui ne correspondent pas aux processus métiers. En maîtrisant la construction et l’interprétation des DFD, les architectes s’assurent que la fondation du système soutient son objectif initial. Ce guide détaille les mécanismes, les règles et les bonnes pratiques pour créer des diagrammes efficaces qui combleront le fossé entre les exigences abstraites et l’implémentation concrète.
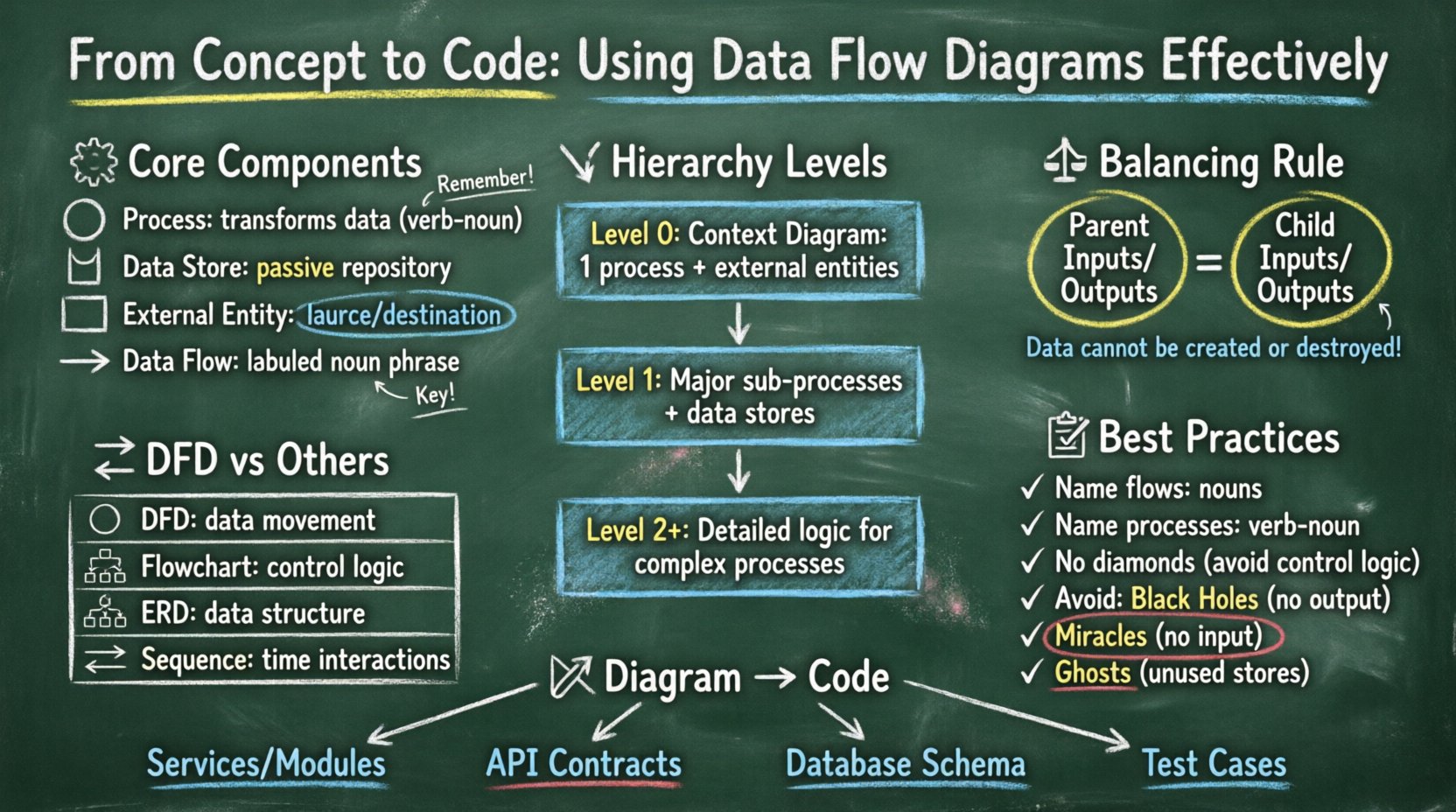
🧩 Comprendre les composants fondamentaux d’un DFD
Un diagramme de flux de données est une représentation graphique du déplacement des données à travers un système d’information. Il ne montre pas le flux de contrôle, comme les boucles ou les branches de décision, mais uniquement les données elles-mêmes. Pour construire un diagramme valide, il est nécessaire de comprendre les quatre symboles fondamentaux utilisés dans la notation standard.
- Processus :Représenté par un cercle ou un rectangle arrondi, un processus transforme les flux de données entrants en flux de données sortants. Il représente un changement, un calcul ou une agrégation. Un processus ne peut pas exister isolément ; il doit avoir au moins une entrée et une sortie.
- Stockage de données :Représenté par un rectangle ouvert ou des lignes parallèles, ce symbole représente un dépôt de données. Il s’agit d’un stockage passif où les données sont conservées entre les processus. Les exemples incluent des tables de base de données, des fichiers plats ou des caches en mémoire.
- Entité externe :Également appelée terminateur, il s’agit d’un rectangle représentant une source ou une destination de données située hors des limites du système. Il peut s’agir d’un utilisateur, d’un autre système ou d’un périphérique physique.
- Flux de données :Illustré par une ligne avec une flèche, il montre le déplacement des données entre les composants. Il représente les données elles-mêmes, et non le signal physique. Chaque flux doit être étiqueté par une mention significative décrivant son contenu.
Comprendre la distinction entre ces composants est essentiel. Par exemple, une erreur courante consiste à dessiner un flux de données directement d’une entité externe à une autre, en contournant le système. Cela implique que le système ne traite pas les données, ce qui viole le cadre de l’analyse. De même, relier un stockage de données directement à une entité externe sans processus implique un accès non autorisé ou un manque de contrôle.
📉 La hiérarchie des niveaux du DFD
Les diagrammes de flux de données ne sont pas statiques ; ils sont hiérarchiques. Cela permet de décrire un système à partir d’un aperçu de haut niveau jusqu’aux détails les plus fins. Cette décomposition aide à gérer la complexité en divisant le système en éléments gérables. Il existe trois niveaux principaux de décomposition.
1. Diagramme de contexte (niveau 0)
Le diagramme de contexte fournit le plus haut niveau d’abstraction. Il représente l’ensemble du système comme un seul processus et montre ses interactions avec les entités externes. Ce diagramme répond à la question : « Qu’est-ce que le système ? » Il est utile pour les parties prenantes qui ont besoin d’un aperçu rapide sans s’attarder aux détails internes.
- Portée :Un processus central représentant l’ensemble du système.
- Entités :Toutes les sources et destinations externes.
- Flux :Principaux flux d’entrée et de sortie de données.
2. Diagramme de niveau 1
Le diagramme de niveau 1 décompose le processus unique du diagramme de contexte en sous-processus principaux. C’est le niveau le plus couramment utilisé pour la documentation de conception du système. Il révèle les principales zones fonctionnelles du système. Chaque fonction majeure identifiée ici devient un nœud de processus distinct.
- Portée :Modules fonctionnels principaux.
- Interactions :Les données circulent entre ces modules et les entités externes.
- Stockage :Les bases de données principales ou les systèmes de fichiers sont introduits.
3. Niveau 2 et inférieur
Les diagrammes de niveau 2 décomposent des processus spécifiques du diagramme de niveau 1 en plus de détails. Cela est réservé aux processus complexes qui impliquent une logique importante ou une gestion de données. Une décomposition excessive à ce niveau peut entraîner des diagrammes trop volumineux pour être lus, il est donc conseillé de faire preuve de prudence. En général, seules les fonctions les plus complexes justifient une telle profondeur.
⚖️ Le principe d’équilibre
L’une des règles les plus critiques dans la construction des diagrammes de flux de données (DFD) est l’équilibre. L’équilibre garantit que les entrées et sorties d’un processus parent correspondent aux entrées et sorties de ses processus enfants. Si un processus parent a un flux d’entrée « Demande de commande », le processus enfant doit également accepter une « Demande de commande » (ou un sous-ensemble qui se résume logiquement à celle-ci).
Violer cette règle crée des incohérences. Un développeur lisant le diagramme enfant pourrait voir une entrée que le diagramme parent affirme n’arriver jamais. Cela entraîne des erreurs d’implémentation. Lors de la décomposition d’un processus, vous devez vous assurer que :
- Tous les flux de données entrant dans le processus parent entrent également dans les processus enfants.
- Tous les flux de données sortant des processus enfants sortent également du processus parent.
- Aucun nouveau flux de données n’est introduit sans justification dans le cadre du processus parent.
- Aucun flux existant n’est perdu lors de la décomposition.
Pensez à l’équilibre comme à une loi de conservation des données. Les données ne peuvent pas être créées ou détruites à l’intérieur des limites du système ; elles sont simplement transformées. Ce principe oblige l’architecte à justifier chaque élément de données qui entre ou sort du système.
🔄 DFD par rapport aux autres techniques de diagrammation
La confusion survient souvent entre les DFD, les organigrammes et les diagrammes Entité-Relation (ERD). Bien qu’ils modélisent tous des systèmes, ils ont des objectifs différents. Utiliser le mauvais diagramme pour une tâche spécifique peut masquer l’intention du design.
| Type de diagramme | Objectif principal | Meilleure utilisation |
|---|---|---|
| Diagramme de flux de données (DFD) | Déplacement logique des données | Analyse du système, définition des limites du système, transformation des données |
| Organigramme | Flux de contrôle et logique | Conception d’algorithmes, chemins de décision, logique spécifique des processus |
| Diagramme Entité-Relation (ERD) | Structure des données et relations | Conception du schéma de base de données, modélisation des données, normalisation du stockage |
| Diagramme de séquence | Interaction au fil du temps | Appels d’API, flux de session utilisateur, dépendances temporelles |
Par exemple, si vous devez définir comment un jeton d’authentification utilisateur est validé, un organigramme pourrait être plus adapté pour montrer la logique de réussite/échec. Si vous devez définir où ce jeton est stocké et récupéré, un DFD montre le flux vers le stockage, tandis qu’un ERD montre le schéma de la table de stockage. Un DFD fournit la carte fonctionnelle, tandis que les autres diagrammes fournissent les détails structurels et logiques.
🛠 Principes de conception et bonnes pratiques
Créer un diagramme ne consiste pas seulement à dessiner des boîtes et des flèches. Il nécessite le respect de conventions qui garantissent que le diagramme reste lisible et précis au fil du temps. Respecter ces principes empêche le décalage de la documentation, où le diagramme ne correspond plus au code.
1. Conventions de nommage
Les étiquettes sont le texte qui porte un sens. Un diagramme de flux de données sans étiquettes claires est inutile. Chaque flux de données doit comporter une expression nominale (par exemple, « ID utilisateur », « Journal des transactions »). Chaque processus doit comporter une expression verbale (par exemple, « Valider le mot de passe », « Générer une facture »). Cette distinction grammaticale aide à clarifier l’action par rapport au contenu.
- Noms des processus :Structure verbe-nom. Évitez les mots simples comme « Processus » ou « Logique ».
- Noms des flux de données :Expressions nominales décrivant le paquet d’information.
- Noms des magasins de données :Expressions nominales, au singulier ou au pluriel, indiquant la collection (par exemple, « Dossiers clients »).
2. Éviter la logique de contrôle
Une erreur courante consiste à injecter une logique de contrôle dans un DFD. Les DFD décrivent le déplacement des données, pas la prise de décision. Vous ne devez pas dessiner une forme en losange indiquant une branche « Oui/Non ». Si une décision existe, elle est un processus qui filtre les données. Le flux doit montrer les données entrant dans le processus et les types de données spécifiques en sortant. Par exemple, au lieu d’une branche, affichez deux flux : « Commande approuvée » et « Commande rejetée » sortant d’un nœud « Traiter la commande ».
3. Gérer les trous noirs et les miracles
En analyse de système, certaines anomalies doivent être évitées :
- Trou noir :Un processus qui a des entrées mais aucune sortie. Cela implique que les données sont consommées et disparaissent sans résultat.
- Miracle :Un processus qui a des sorties mais aucune entrée. Cela implique que les données sont créées à partir de rien.
- Fantôme :Un magasin de données qui n’a aucun flux de données qui y est connecté. Cela indique un emplacement de stockage qui n’est jamais utilisé.
Identifier ces anomalies pendant la phase de conception permet d’économiser un temps considérable pour le débogage ultérieur. Si un processus n’a pas de sortie, le système ne fournit aucune valeur pour cette entrée. Si un magasin n’a pas d’entrée, il est vide et sans intérêt.
🔗 Du diagramme au code : stratégie d’implémentation
Une fois le DFD finalisé, il sert de contrat pour l’équipe de développement. Traduire ce modèle visuel en code exécutable nécessite une approche systématique. Le diagramme informe l’architecture, le schéma de base de données et les points d’entrée API.
1. Identification des services et des modules
Chaque processus du diagramme de niveau 1 correspond souvent à un microservice, un module ou une classe. Par exemple, un processus nommé « Calculer la taxe » pourrait devenir une fonction dédiée au sein d’un module de facturation. Un processus nommé « Gérer le profil utilisateur » pourrait correspondre à un service Utilisateur. Ce mapping garantit que la structure du code reflète la logique métier.
2. Définition des contrats API
Les flux de données entre des entités externes et des processus se traduisent souvent par des requêtes et des réponses API. Si une entité envoie des « Données d’inscription » à un processus, le point d’entrée API correspondant doit accepter un payload correspondant à cette structure de données. Le DFD détermine les schémas d’entrée et de sortie de ces points d’entrée. Cela réduit le besoin de négociations itératives entre les équipes frontend et backend.
3. Conception du schéma de base de données
Les magasins de données dans le DFD représentent la couche de persistance. Bien qu’un DFD ne montre pas les champs ou les clés, il identifie les données qui doivent être sauvegardées. « Historique des commandes » implique une table ou une collection pour les commandes. « Sessions actives » implique un magasin pour l’état utilisateur. Les développeurs peuvent utiliser le DFD pour prioriser les tables critiques et s’assurer que les relations entre les magasins de données s’alignent avec le flux d’information.
4. Validation et tests
Les cas de test peuvent être dérivés directement des flux de données. Chaque flèche représente un chemin de test potentiel. « Si j’envoie une commande, le système renvoie-t-il une facture ? » Cette traçabilité garantit que chaque ligne de code sert un objectif défini dans la conception initiale. Elle empêche le « croissance de fonctionnalités » où du code est ajouté sans apparaître dans le flux de données.
🛡 Cycle de maintenance et de documentation
Un diagramme n’est bon que par sa mise à jour. Un DFD qui ne reflète pas le système actuel devient une dette technique. Il induit en erreur les nouveaux développeurs et masque la logique réelle. Par conséquent, la maintenance fait partie du cycle de développement.
- Gestion des versions :Traitez le DFD comme du code. Lorsque le système change, le diagramme doit être mis à jour. Marquez les versions pour correspondre aux versions logicielles.
- Cycles de revue :Intégrez les mises à jour du DFD dans les processus de revue de code. Si un développeur ajoute un nouveau flux de données, il doit mettre à jour le diagramme.
- Accessibilité :Gardez les diagrammes dans le même référentiel ou système de documentation que le code. Cela garantit qu’ils ne seront pas perdus lorsque l’équipe change d’outils.
- Simplification :Si un diagramme devient trop complexe, envisagez de le diviser. Une seule page contenant 50 processus est difficile à lire. Les diagrammes modulaires sont plus faciles à maintenir.
Auditer régulièrement le diagramme par rapport à la base de code révèle des incohérences. Y a-t-il des magasins de données dans le code qui ne figurent pas dans le diagramme ? Y a-t-il des processus dans le diagramme qui ont été refactoris ? Comblé ces écarts maintient l’intégrité de la documentation du système.
🌟 Résumé des avantages
Mettre en œuvre une approche rigoureuse des diagrammes de flux de données produit des résultats concrets. Elle oblige l’équipe à réfléchir aux données avant la logique. Elle fournit un langage commun pour les parties prenantes qui ne comprennent pas le code mais comprennent les processus métiers. Elle agit comme un pont de communication entre analystes, architectes et développeurs.
En respectant les règles d’équilibrage, en évitant la logique de contrôle et en maintenant la hiérarchie des niveaux, les équipes peuvent produire des diagrammes à la fois précis et utiles. La transition du concept au code devient plus fluide car la destination est clairement définie. Les flux de données sont validés, le stockage est justifié, et les interactions externes sont définies. Cela réduit le travail redondant, minimise l’ambiguïté et construit un système robuste par conception.
Commencez par le diagramme de contexte. Décomposez avec soin. Équilibrez vos flux. Gardez vos étiquettes précises. Et rappelez-vous que le diagramme est un artefact vivant, et non un livrable ponctuel. Avec ces pratiques, la complexité des systèmes modernes devient gérable, et le chemin de l’idée à la mise en œuvre reste clair.