











W architekturze złożonych systemów oprogramowania jasność jest walutą sukcesu. Zanim zostanie napisana jedna linia logiki, musi być zrozumiały przepływ informacji. To właśnie tutaj diagram przepływu danych (DFD) staje się niezastąpiony. DFD wizualizuje sposób, w jaki dane wchodzą do systemu, jak są przetwarzane, gdzie są przechowywane i jak opuszczają system. Jest to strukturalny projekt, który oddziela „co” od „jak”. W przeciwieństwie do kodu, który określa konkretne szczegóły implementacji, DFD skupia się na logicznym przepływie informacji w całym ekosystemie.
Wiele zespołów wchodzi w kodowanie bez solidnego wizualnego przedstawienia przepływu danych. To prowadzi do złożonej logiki, nadmiarowych zapytań do bazy danych oraz interfejsów niezgodnych z procesami biznesowymi. Opanowanie budowy i interpretacji DFD zapewnia architektom, że fundament systemu wspiera jego zaplanowane przeznaczenie. Niniejszy przewodnik szczegółowo opisuje mechanizmy, zasady i najlepsze praktyki tworzenia skutecznych schematów, które zamykają lukę między abstrakcyjnymi wymaganiami a konkretną implementacją.
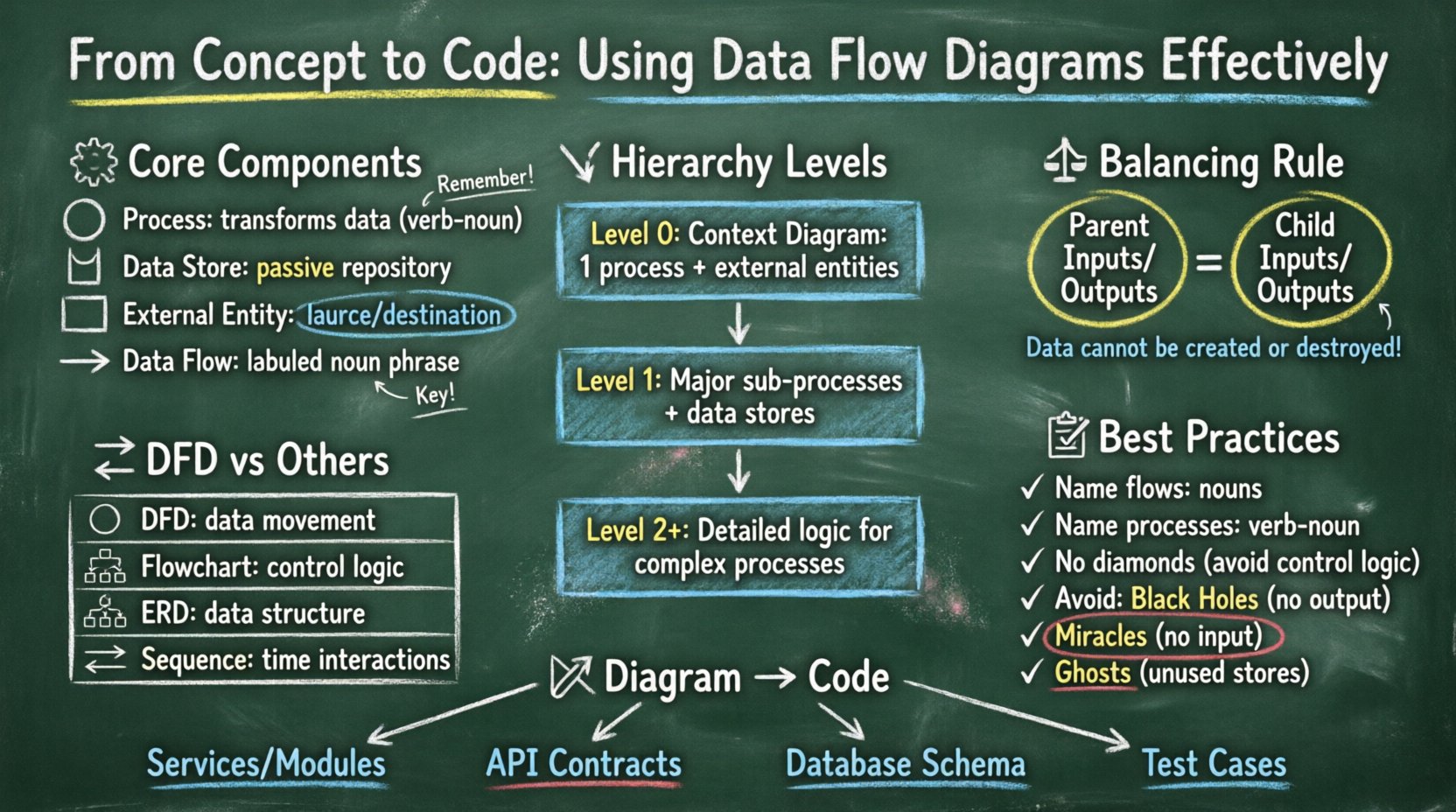
🧩 Zrozumienie podstawowych składników diagramu przepływu danych
Diagram przepływu danych to graficzne przedstawienie przepływu danych przez system informacyjny. Nie pokazuje przepływu sterowania, takiego jak pętle czy gałęzie decyzyjne, ale raczej same dane. Aby stworzyć poprawny schemat, należy zrozumieć cztery podstawowe symbole używane w standardowej notacji.
- Proces: Reprezentowany jako okrąg lub prostokąt z zaokrąglonymi rogami, proces przekształca przepływ danych wejściowych w przepływ danych wyjściowych. Reprezentuje zmianę, obliczenie lub agregację. Proces nie może istnieć samodzielnie; musi mieć co najmniej jedno wejście i jedno wyjście.
- Magazyn danych: Pokazywany jako prostokąt z otwartym końcem lub równoległe linie, ten symbol reprezentuje magazyn danych. Jest to magazyn pasywny, w którym dane spoczywają między procesami. Przykłady to tabele bazy danych, pliki tekstowe lub pamięci cache w pamięci operacyjnej.
- Zewnętrzny element: Znanym również jako końcówka, jest to prostokąt reprezentujący źródło lub miejsce docelowe danych poza granicami systemu. Może to być użytkownik, inny system lub urządzenie fizyczne.
- Przepływ danych: Ilustrowany jako linia z strzałką, pokazuje ruch danych między składnikami. Reprezentuje same dane, a nie sygnał fizyczny. Każdy przepływ musi mieć znaczący etykietę opisującą jego zawartość.
Zrozumienie różnicy między tymi składnikami jest kluczowe. Na przykład powszechnym błędem jest rysowanie przepływu danych bezpośrednio od jednego zewnętrznego elementu do drugiego, pomijając system. Oznacza to, że system nie przetwarza danych, co narusza zakres analizy. Podobnie połączenie magazynu danych bezpośrednio z zewnętrznym elementem bez procesu sugeruje nieautoryzowany dostęp lub brak kontroli.
📉 Hierarchia poziomów DFD
Diagramy przepływu danych nie są statyczne; są hierarchiczne. Pozwala to opisać system od ogólnego przeglądu po szczegółowe szczegóły. Ta dekompozycja pomaga zarządzać złożonością, dzieląc system na obszary łatwe do zarządzania. Istnieją trzy główne poziomy dekompozycji.
1. Diagram kontekstowy (poziom 0)
Diagram kontekstowy zapewnia najwyższy poziom abstrakcji. Pokazuje cały system jako pojedynczy proces i przedstawia jego interakcje z zewnętrznymi elementami. Ten schemat odpowiada na pytanie: „Co to jest system?”. Jest przydatny dla stakeholderów, którzy potrzebują szybkiego przeglądu bez zagłębiania się w szczegóły wewnętrzne.
- Zakres: Jeden centralny proces reprezentujący cały system.
- Elementy: Wszystkie zewnętrzne źródła i miejsca docelowe.
- Przepływy: Główne wejścia i wyjścia danych.
2. Diagram poziomu 1
Diagram poziomu 1 dekomponuje pojedynczy proces z diagramu kontekstowego na główne podprocesy. Jest to najbardziej powszechny poziom używany do dokumentacji projektu systemu. Ujawnia główne obszary funkcjonalne systemu. Każda główna funkcja zidentyfikowana tutaj staje się odrębnym węzłem procesu.
- Zakres: Główne moduły funkcjonalne.
- Interakcje: Dane przepływają między tymi modułami a zewnętrznymi elementami.
- Przechowywanie:Wprowadzane są główne bazy danych lub systemy plików.
3. Poziom 2 i niżej
Diagramy poziomu 2 rozkładają konkretne procesy z diagramu poziomu 1 na większą szczegółowość. Jest to przeznaczone dla złożonych procesów, które obejmują istotną logikę lub przetwarzanie danych. Nadmierna dekompozycja na tym poziomie może prowadzić do diagramów, które są zbyt duże, aby można je było czytać, dlatego należy zachować ostrożność. Zazwyczaj tylko najbardziej złożone funkcje zasługują na taką głębię.
⚖️ Zasada zrównoważenia
Jednym z najważniejszych zasad w budowaniu diagramów przepływu danych (DFD) jest zrównoważenie. Zrównoważenie zapewnia, że wejścia i wyjścia procesu nadrzędnego odpowiadają wejściom i wyjściom jego procesów potomnych. Jeśli proces nadrzędny ma przepływ wejściowy „Żądanie zamówienia”, proces potomny również musi przyjąć „Żądanie zamówienia” (lub podzbiór, który logicznie sumuje się do niego).
Naruszanie tej zasady powoduje niezgodności. Programista czytający diagram potomny może zobaczyć wejście, które diagram nadrzędny mówi, że nigdy nie występuje. To prowadzi do błędów w implementacji. Podczas dekompozycji procesu należy upewnić się, że:
- Wszystkie przepływy danych wejściowych do procesu nadrzędnego również wechodzą do procesów potomnych.
- Wszystkie przepływy danych wyjściowe z procesów potomnych również opuszczają proces nadrzędny.
- Nie wprowadza się nowych przepływów danych bez uzasadnienia w zakresie procesu nadrzędnego.
- Nie tracimy istniejących przepływów danych podczas dekompozycji.
Traktuj zrównoważenie jak prawo zachowania danych. Dane nie mogą być tworzone ani niszczone w granicach systemu; są jedynie przekształcane. Ta zasada zmusza architekta do uzasadnienia każdego fragmentu danych, który wchodzi do systemu lub go opuszcza.
🔄 DFD w porównaniu z innymi technikami diagramowania
Często pojawia się zamieszanie między diagramami przepływu danych (DFD), schematami blokowymi i diagramami encji-związków (ERD). Choć wszystkie one modelują systemy, mają różne cele. Używanie nieodpowiedniego diagramu do konkretnej zadania może zasłonić intencję projektową.
| Typ diagramu | Główny obszar zainteresowania | Najlepiej używane do |
|---|---|---|
| Diagram przepływu danych (DFD) | Logiczny przepływ danych | Analiza systemu, definiowanie granic systemu, przekształcanie danych |
| Schemat blokowy | Przepływ sterowania i logika | Projektowanie algorytmów, ścieżki decyzyjne, konkretne logiki procesów |
| Diagram encji-związków (ERD) | Struktura danych i relacje | Projektowanie schematu bazy danych, modelowanie danych, normalizacja przechowywania |
| Diagram sekwencji | Interakcja w czasie | Wywołania interfejsu API, przepływy sesji użytkownika, zależności czasowe |
Na przykład, jeśli chcesz określić, jak jest weryfikowany token uwierzytelniający użytkownika, schemat blokowy może być lepszy do pokazania logiki sukcesu/porażki. Jeśli chcesz określić, gdzie ten token jest przechowywany i pobierany, DFD pokazuje przepływ do magazynu, podczas gdy ERD pokazuje schemat tabeli przechowywania. DFD dostarcza mapę funkcjonalną, podczas gdy inne diagramy dostarczają szczegółów strukturalnych i logicznych.
🛠 Zasady projektowania i najlepsze praktyki
Tworzenie diagramu to nie tylko rysowanie pudełek i strzałek. Wymaga ono przestrzegania zasad, które zapewniają czytelność i dokładność diagramu w czasie. Przestrzeganie tych zasad zapobiega rozbieżności dokumentacji, gdy diagram przestaje odpowiadać kodowi.
1. Zasady nazewnictwa
Etykiety to tekst, który niesie znaczenie. Diagram DFD bez jasnych etykiet jest bezużyteczny. Każdy przepływ danych musi mieć frazę rzeczownikową (np. „ID użytkownika”, „Dziennik transakcji”). Każdy proces musi mieć frazę czasownikową (np. „Weryfikuj hasło”, „Generuj fakturę”). Ta różnica gramatyczna pomaga rozróżnić działanie od treści.
- Nazwy procesów:Struktura czasownik-rzeczownik. Unikaj pojedynczych słów takich jak „Proces” lub „Logika”.
- Nazwy przepływów danych:Frazy rzeczownikowe opisujące pakiet informacji.
- Nazwy magazynów danych:Frazy rzeczownikowe, liczba pojedyncza lub mnoga, wskazujące na zbiór (np. „Dane klientów”).
2. Unikanie logiki sterowania
Powszechnym błędem jest wprowadzanie logiki sterowania do diagramu DFD. Diagramy DFD opisują przepływ danych, a nie podejmowanie decyzji. Nie powinno się rysować kształtu diamentu oznaczającego gałąź „Tak/Nie”. Jeśli decyzja istnieje, to proces filtrujący dane. Przepływ powinien pokazywać dane wejściowe do procesu oraz konkretne typy danych wyjściowych. Na przykład zamiast gałęzi pokazuj dwa przepływy: „Zatwierdzony zamówienie” i „Odrzucone zamówienie” wychodzące z węzła „Przetwarzanie zamówienia”.
3. Zarządzanie czarnymi dziurami i cudami
W analizie systemu należy unikać pewnych anomalii:
- Czarna dziura:Proces mający dane wejściowe, ale brak danych wyjściowych. Oznacza to, że dane są zużywane i znikają bez rezultatu.
- Cud:Proces mający dane wyjściowe, ale brak danych wejściowych. Oznacza to, że dane powstają z niczego.
- Przyzak:Magazyn danych, do którego nie ma żadnych przepływów danych. Wskazuje na lokalizację przechowywania, która nigdy nie jest używana.
Identyfikacja tych anomalii w fazie projektowania oszczędza znaczny czas debugowania później. Jeśli proces nie ma wyjścia, system nie generuje wartości dla tego wejścia. Jeśli magazyn nie ma wejścia, jest pusty i nieistotny.
🔗 Od diagramu do kodu: strategia wdrożenia
Po finalizacji diagramu DFD staje się umową dla zespołu programistów. Przekształcenie tego modelu wizualnego w wykonywalny kod wymaga systematycznego podejścia. Diagram informuje o architekturze, schemacie bazy danych oraz punktach końcowych interfejsu API.
1. Identyfikacja usług i modułów
Każdy proces na diagramie poziomu 1 często odpowiada mikroserwicji, modułowi lub klasie. Na przykład proces o nazwie „Oblicz podatek” może stać się dedykowaną funkcją w module rozliczeń. Proces o nazwie „Zarządzaj profilem użytkownika” może odpowiadać usłudze użytkownika. To mapowanie zapewnia, że struktura kodu odzwierciedla logikę biznesową.
2. Definiowanie kontraktów interfejsu API
Przepływy danych między zewnętrznymi jednostkami a procesami często przekładają się na żądania i odpowiedzi interfejsu API. Jeśli jednostka wysyła „Dane rejestracyjne” do procesu, odpowiedni punkt końcowy interfejsu API musi akceptować dane zgodne z tą strukturą. Diagram DFD określa schematy wejściowe i wyjściowe dla tych punktów końcowych. Zmniejsza to potrzebę iteracyjnych negocjacji między zespołami frontendu i backendu.
3. Projektowanie schematu bazy danych
Magazyny danych w diagramie DFD reprezentują warstwę trwałości. Choć diagram DFD nie pokazuje pól ani kluczy, wskazuje, jakie dane muszą zostać zapisane. „Historia zamówień” oznacza tabelę lub kolekcję dla zamówień. „Aktywne sesje” oznacza magazyn stanu użytkownika. Deweloperzy mogą wykorzystać diagram DFD do priorytetyzacji krytycznych tabel i zapewnienia, że relacje między magazynami danych są zgodne z przepływem informacji.
4. Weryfikacja i testowanie
Przypadki testowe mogą być bezpośrednio wyprowadzone z przepływów danych. Każdy strzałka reprezentuje potencjalną ścieżkę testową. „Jeśli prześlę Zamówienie, czy System zwraca Fakturę?” Takie śledzenie zapewnia, że każdy wiersz kodu ma cel określony w początkowym projekcie. Zapobiega to „przeciążeniu funkcjonalności”, gdy do kodu dodawane są elementy, które nie pojawiają się w przepływach danych.
🛡 Cykl utrzymania i dokumentacji
Diagram jest tak dobry, jak jego aktualność. DFD, który nie odzwierciedla obecnej systemu, staje się długiem technicznym. Prowadzi nowych programistów w błąd i zakłóca zrozumienie rzeczywistej logiki. Dlatego utrzymanie diagramu jest częścią cyklu rozwoju oprogramowania.
- Wersjonowanie:Traktuj DFD jak kod. Gdy system ulega zmianie, diagram musi zostać zaktualizowany. Oznacz wersje, aby odpowiadały wydaniom oprogramowania.
- Cykle przeglądu:Włącz aktualizacje DFD do procesów przeglądu kodu. Jeśli programista dodaje nowy przepływ danych, musi zaktualizować diagram.
- Dostępność:Przechowuj diagramy w tym samym repozytorium lub systemie dokumentacji co kod. Zapewnia to, że nie zostaną utracone, gdy zespół zmienia narzędzia.
- Uproszczenie:Jeśli diagram staje się zbyt skomplikowany, rozważ jego podział. Strona zawierająca 50 procesów jest trudna do odczytania. Diagramy modułowe są łatwiejsze do utrzymania.
Regularna kontrola diagramu pod kątem kodu ujawnia rozbieżności. Czy w kodzie istnieją magazyny danych, które nie znajdują się na diagramie? Czy na diagramie są procesy, które zostały przepisane? Usunięcie tych luk zapewnia integralność dokumentacji systemu.
🌟 Podsumowanie korzyści
Wprowadzenie dyscyplinowanego podejścia do diagramów przepływu danych przynosi wyraźne rezultaty. Zmusza zespół do myślenia o danych przed logiką. Stanowi wspólny język dla stakeholderów, którzy mogą nie rozumieć kodu, ale rozumieją procesy biznesowe. Jest mostem komunikacyjnym między analitykami, architektami i programistami.
Przestrzeganie zasad równowagi, unikanie logiki sterującej oraz utrzymanie hierarchii poziomów pozwala zespołom tworzyć diagramy zarówno dokładne, jak i użyteczne. Przejście od koncepcji do kodu staje się płynniejsze, ponieważ cel jest jasno zaznaczony. Przepływy danych są weryfikowane, przechowywanie jest uzasadnione, a interakcje zewnętrzne są zdefiniowane. To zmniejsza ponowne prace, minimalizuje niepewność i buduje system, który jest odporny już na etapie projektowania.
Zacznij od diagramu kontekstowego. Rozłóż z ostrożnością. Zrównowaguj swoje przepływy. Zachowaj precyzję etykiet. I pamiętaj, że diagram to żywy artefakt, a nie jednorazowy produkt. Dzięki tym praktykom złożoność nowoczesnych systemów staje się zarządzalna, a droga od pomysłu do wdrożenia pozostaje jasna.