











W dynamicznej przestrzeni technologii informacyjnych diagram przepływu danych (DFD) nadal stanowi podstawowy element analizy systemów. Choć pierwotnie stworzony w czasach programowania strukturalnego lat 70., przydatność wizualizacji ruchu danych przez system nie zmalała. Wręcz przeciwnie – przekształciła się. Gdy organizacje zmierzają się z modelami uczenia maszynowego, systemami przechowywania rozproszonego i strumieniami przetwarzania w czasie rzeczywistym, potrzeba mapowania torów danych stała się ważniejsza niż kiedykolwiek.
Ten przewodnik bada dostosowanie DFD do nowoczesnych środowisk obliczeniowych. Przegląda, jak tradycyjne diagramy muszą ewoluować w celu przedstawienia przepływów inteligencji sztucznej, architektur dużych danych i infrastruktur chmurowych, bez konieczności korzystania z narzędzi specyficznych dla producenta. Nacisk położony jest nadal na spójność koncepcyjną przepływu danych, bezpieczeństwa i przekształceń.
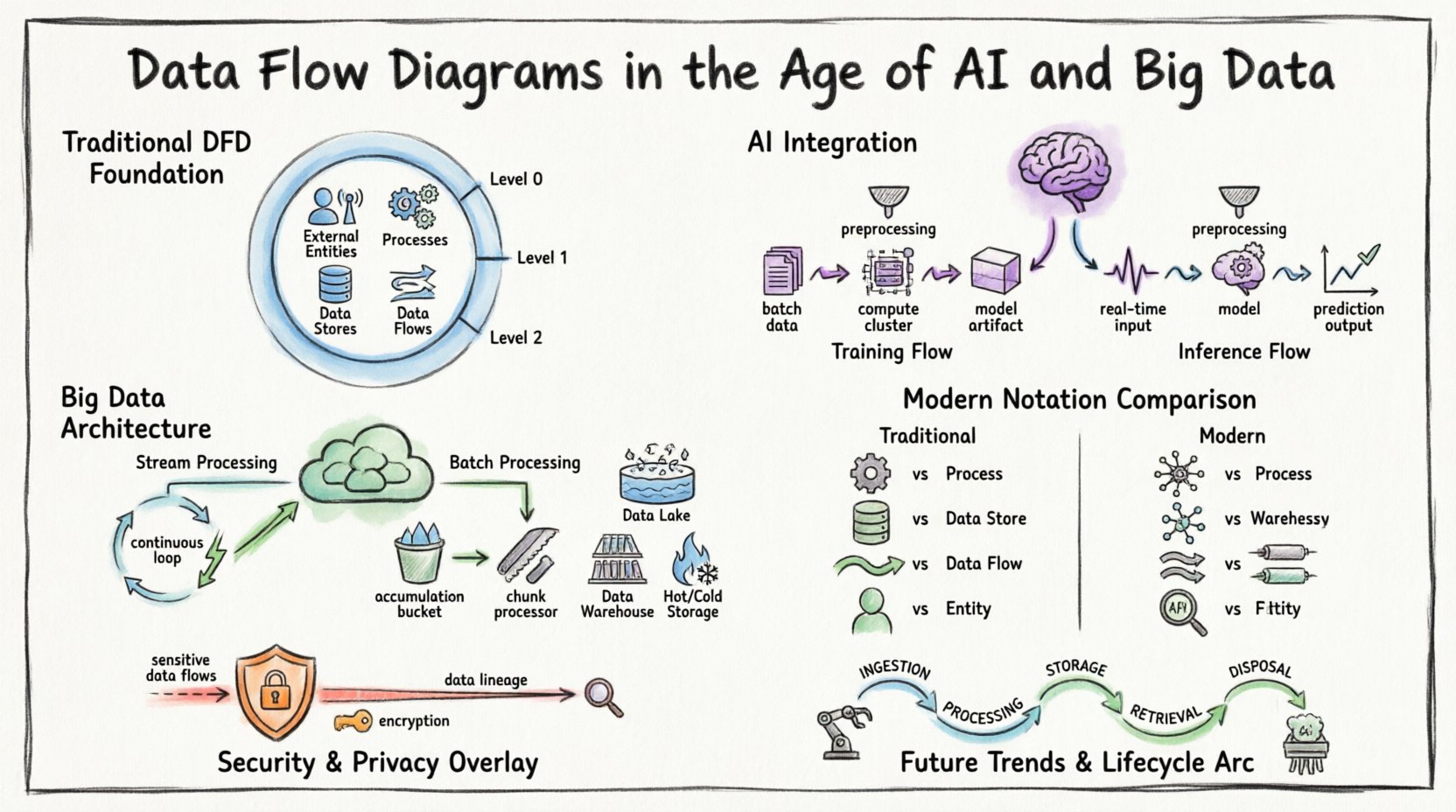
🏛️ Podstawa: zrozumienie diagramów przepływu danych
Zanim przejdziemy do złożoności współczesnych systemów, konieczne jest ustalenie podstawowej definicji. Diagram przepływu danych to graficzne przedstawienie ruchu danych przez system informacyjny. Modeluje przepływ informacji od źródeł zewnętrznych do celów oraz procesów wewnętrznych.
Kluczowe elementy definiują standardowy DFD:
- Jednostki zewnętrzne:Źródła lub miejsca docelowe poza granicami systemu (np. użytkownicy, inne systemy, czujniki).
- Procesy:Przekształcenia zmieniające dane wejściowe w dane wyjściowe.
- Magazyny danych:Repozytoria, w których dane są przechowywane do późniejszego użytku (np. bazy danych, systemy plików).
- Przepływy danych:Ruch danych między jednostkami, procesami i magazynami.
W tradycyjnych kontekstach te diagramy często rysowane były na wielu poziomach abstrakcji:
- Diagram kontekstowy (poziom 0):Pokazuje system jako pojedynczy proces oraz jego interakcje z jednostkami zewnętrznymi.
- Diagram poziomu 1:Rozdziela główny proces na główne podprocesy.
- Diagram poziomu 2:Dalsze rozkładanie wybranych podprocesów w celu uzyskania szczegółowych informacji.
Choć ta hierarchia nadal jest ważna, natura „procesu” się zmieniła. Proces nie jest już tylko zadaniem partii; często jest ciągłym usługą lub modelem predykcyjnym.
🧠 Integracja AI: modelowanie inteligencji w przepływach
Integracja sztucznej inteligencji (AI) wprowadza nowe zmienne do mapowania przepływów danych. W tradycyjnych systemach logika jest jawna. W systemach napędzanych AI logika często jest prawdopodobieństwowa. Ta różnica wymaga zmiany sposobu wizualizacji składnika „Proces” w DFD.
1. Przepływy treningowe vs. inferencyjne
Ścieżki uczenia maszynowego znacznie różnią się od standardowej logiki aplikacji. Diagram przepływu danych dla systemu AI musi rozróżniać fazę treningu i fazę wnioskowania.
- Przepływ treningowy:Zaangażowane są duże zbiory danych przemieszczające się z magazynów do klastrów obliczeniowych. Wynikiem jest ztrainowany artefakt modelu. Ten przepływ często ma charakter partii i jest intensywny pod względem zasobów.
- Przepływ wnioskowania:Zaangażowane są dane w czasie rzeczywistym lub bliskim czasowi rzeczywistemu wprowadzane do modelu w celu wygenerowania prognoz. Ten przepływ priorytetowo ma niską opóźnienie i wysoką przepustowość.
Podczas mapowania tych przepływów bardzo ważne jest zwrócenie uwagi na to, że sam model działa jak proces pudełka czarnego. Wewnętrzna logika jest ukryta, ale wymagania dotyczące danych wejściowych oraz formaty danych wyjściowych muszą być jasno zdefiniowane na schemacie.
2. Przetwarzanie danych jako proces
Zanim dane dotrą do modelu AI, ulegają istotnej transformacji. Inżynieria cech, normalizacja i czyszczenie to kluczowe kroki, które muszą być widoczne na schemacie DFD. Ignorowanie tych kroków prowadzi do niepełnego zrozumienia systemu.
- Normalizacja: Skalowanie danych w celu dopasowania do oczekiwań modelu.
- Kodowanie: Przekształcanie danych kategorycznych na wektory numeryczne.
- Wypełnianie: Obsługa brakujących wartości w przepływie danych.
Te kroki przetwarzania danych są procesami. Zużywają czas i zasoby obliczeniowe oraz wprowadzają potencjalne punkty awarii, które muszą być śledzone w przepływie danych.
🌊 Big Data: Obsługa objętości, prędkości i zróżnicowania
Architektury big data wyzwalają liniowy charakter tradycyjnych schematów DFD. Dane często przychodzą w strumieniach, znajdują się w jeziorach danych i są przetwarzane za pomocą obliczeń rozproszonych. Statyczny schemat nie może łatwo oddać dynamicznego charakteru tych środowisk.
1. Przetwarzanie strumieniowe vs. przetwarzanie partii
Nowoczesne systemy często wykorzystują podejście hybrydowe. Niektóre dane są przetwarzane w czasie rzeczywistym, podczas gdy inne są agregowane do analizy partii. Schemat DFD musi jasno odróżniać te dwa kierunki.
- Przetwarzanie strumieniowe: Dane przepływają ciągle. Schemat powinien przedstawić przepływ jako ciągłą pętlę, a nie sekwencję start-stop.
- Przetwarzanie partii: Dane gromadzą się w czasie i są przetwarzane w fragmentach. Schemat powinien odzwierciedlać punkt gromadzenia (magazyn danych) przed rozpoczęciem procesu.
2. Wizualizacja rozproszonego przechowywania danych
W bazie danych monolitycznej magazyn danych to pojedynczy pudełko. W środowisku big data przechowywanie danych jest rozproszone. Schemat DFD powinien wskazywać, że „magazyn danych” może rzeczywiście reprezentować klaster węzłów lub system przechowywania podzielonego na partycje.
- Jeziora danych:Magazynowanie danych surowych, gdzie struktura jest stosowana później.
- Magazyny danych:Strukturalne przechowywanie zoptymalizowane pod kątem zapytań.
- Pamięć gorąca vs. pamięć chłodna:Rozróżnianie między danymi często dostępnymi a danymi archiwalnymi.
To rozróżnienie jest kluczowe dla zrozumienia opóźnień. Przepływ z węzła pamięci gorącej zachowuje się inaczej niż przepływ z archiwum pamięci chłodnej.
📐 Modernizacja notacji
Aby skutecznie komunikować złożone systemy, notacja używana w schematach DFD musi się dostosować. Choć podstawowe symbole pozostają podobne, ich zastosowanie wymaga subtelności.
| Składnik | Klasyczny DFD | Nowoczesny DFD z AI/dużymi danymi |
|---|---|---|
| Proces | Jedno kroku przekształcenia | Usługa mikroserwisowa, wnioskowanie modelu lub etap potoku |
| Magazyn danych | Plik lub tabela bazy danych | Jezioro danych, rozproszony bufor lub magazyn obiektów |
| Przepływ danych | Żądanie/odpowiedź lub przekazanie pliku | Strumień zdarzeń, ładunek interfejsu API lub kolejkę komunikatów |
| Obiekt | Użytkownik lub starszy system | Urządzenie IoT, interfejs API strony trzeciej lub autonomiczny agent |
1. Architektura oparta na zdarzeniach
Wiele nowoczesnych systemów opiera się na zdarzeniach zamiast na bezpośrednich żądaniach. DFD systemu opartego na zdarzeniach używa wyzwalaczy do uruchamiania procesów. Zamiast procesu oczekującego na dane, przyjście danych wywołuje proces.
- Kolejki komunikatów: Służą jako bufor między producentami a konsumentami.
- Dzienniki zdarzeń: Niezmienne zapisy zmian stanu, które pełnią rolę magazynów danych do audytu.
Wizualizacja tych kolejek jako magazynów danych pomaga wyjaśnić problemy związane z nadciśnieniem. Jeśli proces nie nadąża z przepływem danych, kolejka rośnie. Ten ryzyko musi zostać zaznaczone.
2. Usługi mikroserwisowe i granice
Kiedy systemy dzielą się na mikroserwisy, granica systemu w DFD staje się bardziej przezroczysta. Przepływy danych często przekraczają granice usług za pomocą interfejsów API. Ważne jest oznaczenie protokołu używanego (np. REST, gRPC, GraphQL) na liniach przepływu danych, aby wskazać wymagania zgodności.
- Odnajdywanie usług: Dynamiczne routowanie przepływów danych.
- Rozdzielanie obciążenia: Rozdzielanie przepływów danych między wieloma instancjami.
🔒 Bezpieczeństwo i prywatność w przepływach danych
Bezpieczeństwo nie może być postrzegane jako drugoplanowe w diagramie przepływu danych. Ze względu na przepisy takie jak RODO i CCPA, zrozumienie, gdzie znajduje się i jak porusza się wrażliwe dane jest obowiązkowe.
1. Identyfikacja danych wrażliwych
Przepływy danych zawierające informacje osobowe (PII) lub chronione informacje medyczne (PHI) muszą być wyróżnione. Użyj różnych stylów linii lub kolorów, aby oznaczyć poufne przepływy.
- Szyfrowanie w tranzycie: Wszystkie przepływy przekraczające granice sieciowe powinny wskazywać protokoły szyfrowania (np. TLS).
- Szyfrowanie w spoczynku: Magazyny danych zawierające poufne dane muszą być oznaczone.
2. Pochodzenie danych
Zrozumienie pochodzenia danych jest kluczowe dla zgodności. DFD działa jako mapa pochodzenia na wysokim poziomie. Pokazuje, gdzie dane wchodzą do systemu i jak się zmieniają.
- Śledzenie zgody: Przepływy zawierające dane zgody użytkownika muszą być śledzone osobno.
- Prawo do usunięcia:Diagramy muszą pokazywać, gdzie dane są przechowywane, aby ułatwić żądania usunięcia.
Jeśli DFD nie pokazuje, gdzie dane są przechowywane, audyty zgodności stają się niemożliwe. Każdy magazyn danych musi mieć zdefiniowanego właściciela i politykę przechowywania.
⚙️ Wyzwania w tworzeniu nowoczesnych DFD
Tworzenie dokładnych diagramów dla złożonych systemów stawia konkretne wyzwania. Objętość danych i szybkość zmian często przewyższają wysiłki dokumentacyjne.
1. Systemy dynamiczne
Grupy automatycznego skalowania zmieniają liczbę wystąpień procesów dynamicznie. Statyczny diagram nie może tego pokazać. Diagram musi przedstawiać *możliwości* systemu, a nie tylko jego aktualny stan.
- Używaj ogólnych etykiet, takich jak „Klastery obliczeniowe”, zamiast konkretnych identyfikatorów wystąpień.
- W opisie procesu wskazuj sygnały skalowania.
2. Zarządzanie złożonością
Wraz z rozwojem systemów, DFD staje się nieczytelny. Kluczowe jest abstrahowanie. Nie mapuj każdego punktu końcowego API. Mapuj logiczne przepływy danych.
- Grupowanie: Połącz powiązane procesy w jeden nadproces.
- Łączenie: Użyj odwołań krzyżowych, aby połączyć szczegółowe poddiagramy z ogólnymi przeglądami.
3. Zależności w czasie rzeczywistym
W systemach strumieniowych kolejność operacji ma znaczenie. DFD pokazuje połączenia, ale nie zawsze czas. Uzupełnij DFD diagramami sekwencji, jeśli czas jest krytyczny.
- W opisach procesów wskazuj limity czasu i ponowne próby.
- Zaznacz, czy przepływy danych są synchroniczne czy asynchroniczne.
🚀 Przyszłe trendy: automatyzacja i samodokumentacja
Przyszłość DFD leży w automatyzacji. W miarę jak systemy stają się bardziej skupione na kodzie, diagramy powinny być generowane z bazy kodu, a nie rysowane ręcznie.
1. Infrastruktura jako kod (IaC)
Gdy infrastruktura jest definiowana w kodzie, przepływ danych jest niejawnie określony. Narzędzia mogą analizować pliki IaC w celu automatycznego generowania schematów DFD.
- Upewnij się, że diagram jest zgodny z rzeczywistą infrastrukturą.
- Używaj kontroli wersji dla definicji diagramów.
2. Ciągłe odkrywanie
Narzędzia monitorowania sieci mogą wykrywać rzeczywiste przepływy danych. Integracja tych narzędzi z oprogramowaniem do tworzenia DFD pozwala na tworzenie „żywych” diagramów, które aktualizują się wraz z zmianami wzorców ruchu.
- Wyświetl ostrzeżenie, gdy pojawią się nowe przepływy danych, które nie zostały zarejestrowane.
- Zaznacz nieużywane magazyny danych, które mogą zostać wycofane z eksploatacji.
3. Diagramowanie wspomagane przez sztuczną inteligencję
Sztuczna inteligencja może sugerować ulepszenia diagramów. Może identyfikować węzły zatkania, nadmiarowe ścieżki lub luki w zabezpieczeniach na podstawie najlepszych praktyk.
- Automatyczna weryfikacja reguł przepływu danych (np. brak bezpośredniego przepływu z bazy danych do jednostki zewnętrznej bez procesu).
- Zaproponowanie optymalnej dekompozycji procesów.
🛠️ Najlepsze praktyki wdrożenia
Aby zachować wartość DFD w kontekście nowoczesnym, przestrzegaj poniższych praktyk.
- Ujednolit notację: Upewnij się, że wszyscy członkowie zespołu używają tych samych symboli i konwencji. Spójność zmniejsza obciążenie poznawcze.
- Zdefiniuj konwencje nazewnictwa: Procesy powinny być nazwane według wzoru czasownik-przysłówek (np. „Weryfikuj dane użytkownika”). Magazyny danych powinny być nazwane jako rzeczowniki (np. „Profil użytkownika”).
- Regularnie przeglądarki: Diagram, który nie jest przeglądarki, staje się kłamstwem. Zaprojektuj przeglądy podczas planowania sprintów lub spotkań doskonalenia architektury.
- Skup się na wartości: Mapuj tylko przepływy danych niezbędne dla logiki biznesowej. Usuń nadmiarowe wewnętrzne przepływy, które nie wpływają na użytkownika końcowego.
- Dokumentuj założenia: Jeśli przepływ zakłada określoną opóźnienie lub przepustowość, zapisz to. Te założenia wpływają na projekt systemu.
🔄 Cykl życia przepływu danych
Zrozumienie cyklu życia pomaga dokładniej stworzyć diagram. Dane przechodzą przez kilka etapów:
- Zbieranie: Dane wchodzą w granice systemu. Jest to zazwyczaj najbardziej niestabilny punkt.
- Przetwarzanie: Dane są przekształcane, uzupełniane lub analizowane.
- Przechowywanie: Dane są trwale przechowywane do późniejszego użytku.
- Pobieranie:Dane są pobierane do raportowania lub działania.
- Usunięcie:Dane są archiwizowane lub usuwane zgodnie z polityką.
Każdy etap reprezentuje potencjalny proces lub magazyn w schemacie DFD. Pełny diagram uwzględnia etap usunięcia, zapewniając, że dane nie pozostają niepotrzebnie.
📊 Podsumowanie kluczowych komponentów
W celu szybkiego odnalezienia, poniżej znajduje się analiza, jak klasyczne komponenty odpowiadają nowoczesnym odpowiednikom.
| Klasyczny koncept | Nowoczesny odpowiednik | Uwaga |
|---|---|---|
| Wejście | Brama API / Pipeline pobierania danych | Uwierzytelnianie i ograniczanie szybkości |
| Wyjście | Panel monitoringu / Usługa powiadomień | Formatowanie i kanał dostarczania |
| Proces | Funkcja / Kontener / Model | Bezstanowość i skalowalność |
| Magazyn | Magazyn obiektów / Baza danych NoSQL | Podział i indeksowanie |
| Przepływ | Komunikat zdarzenia / Żądanie HTTP | Opóźnienie i niezawodność |
Poprzez dopasowanie tych koncepcji zespoły mogą tworzyć schematy, które działają jako skuteczne narzędzia komunikacji między inżynierami, naukowcami danych i stakeholderami biznesowymi. Celem nie jest doskonałość, ale jasność. Schemat, który wspomaga podejmowanie decyzji, jest skuteczny.
🔮 Ostateczne rozważania dotyczące wizualizacji przepływu danych
Zasady Diagramów Przepływu Danych są wieczne, ale ich zastosowanie wymaga dostosowania. W miarę jak dane stają się kluczowym aktywem nowoczesnych firm, zdolność do wizualizacji ich przepływu staje się strategiczną przewagą. Niezależnie od tego, czy zarządzamy prostą bazą danych, czy skomplikowanym przepływem sieci neuronowej, DFD zapewnia niezbędną strukturę do zrozumienia, zabezpieczenia i optymalizacji przepływu informacji.
Zachowanie aktualności tych metodologii zapewnia, że architektury systemów pozostają przejrzyste i utrzymywalne. Przejście od statycznej dokumentacji do dynamicznej, automatycznej wizualizacji jest nieuniknione. Zespoły, które przyjmują to przejście, odkryją, że są lepiej przygotowane do radzenia sobie z złożonością ery cyfrowej.
Skup się na danych. Śledź przepływ. Upewnij się, że logika jest poprawna. To nadal kluczowym zadaniem skutecznej architektury systemu.