











В постоянно меняющейся среде информационных технологий диаграмма потоков данных (DFD) по-прежнему остаётся фундаментальным инструментом анализа систем. Хотя изначально она была разработана в эпоху структурного программирования 1970-х годов, полезность визуализации движения данных через систему не уменьшилась. Напротив, она трансформировалась. По мере того как организации сталкиваются с моделями машинного обучения, распределёнными системами хранения данных и потоками обработки в реальном времени, необходимость отслеживания траекторий данных стала более важной, чем когда-либо ранее.
В этом руководстве рассматривается адаптация DFD к современным вычислительным средам. Анализируется, как традиционные диаграммы должны эволюционировать для отображения рабочих процессов искусственного интеллекта, архитектур больших данных и инфраструктур, ориентированных на облачные технологии, без привязки к конкретным инструментам производителей. Основное внимание по-прежнему уделяется концептуальной целостности движения, безопасности и преобразования данных.
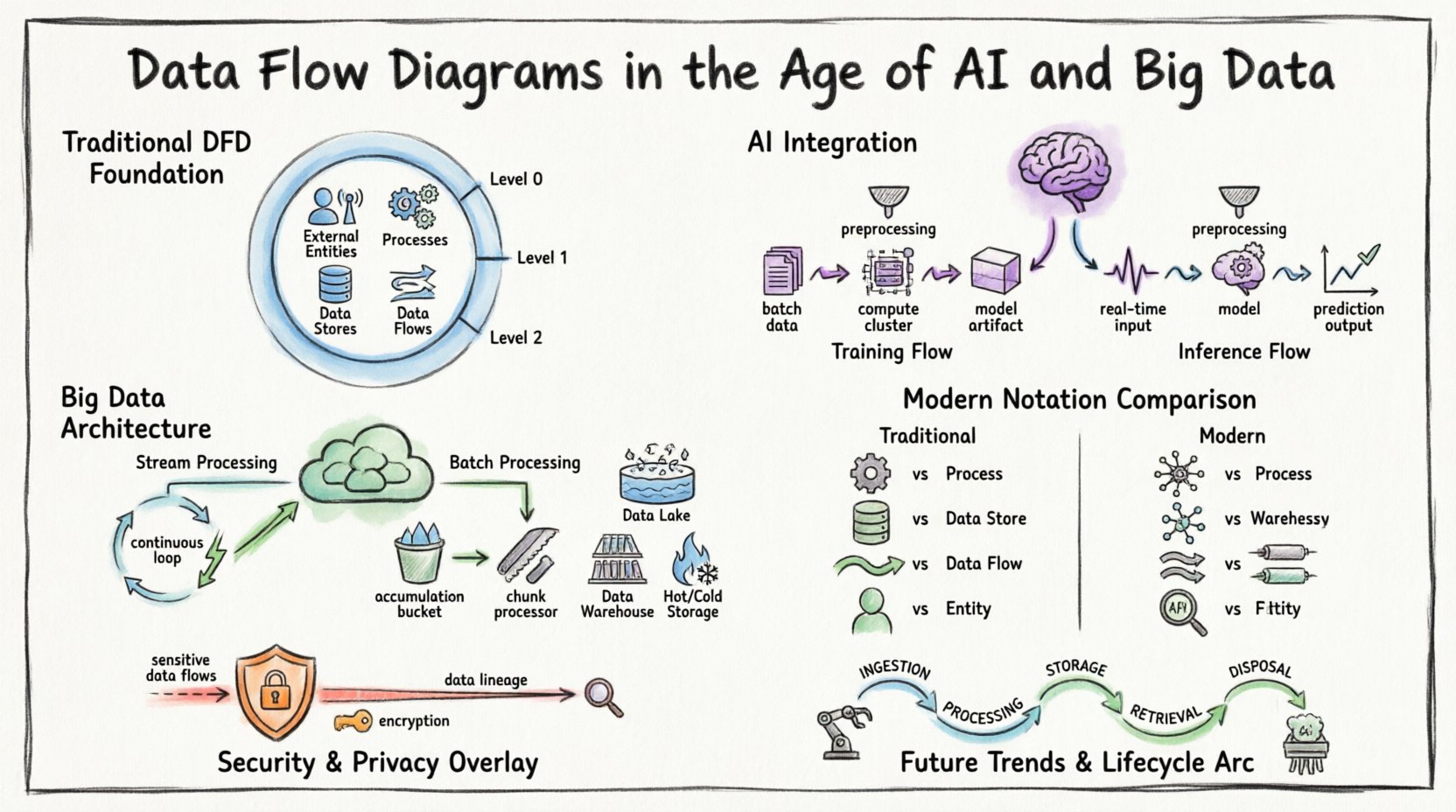
🏛️ Основа: понимание диаграмм потоков данных
Прежде чем переходить к современным сложностям, необходимо установить базовое определение. Диаграмма потоков данных — это графическое представление движения данных через информационную систему. Она моделирует перемещение информации от внешних источников к конечным точкам и внутренним процессам.
Ключевые компоненты определяют стандартную DFD:
- Внешние сущности:Источники или пункты назначения за пределами границ системы (например, пользователи, другие системы, датчики).
- Процессы:Преобразования, превращающие входные данные в выходные.
- Хранилища данных:Хранилища, где данные хранятся для последующего использования (например, базы данных, файловые системы).
- Потоки данных:Перемещение данных между сущностями, процессами и хранилищами.
В традиционных контекстах эти диаграммы часто рисовались на нескольких уровнях абстракции:
- Диаграмма контекста (уровень 0):Показывает систему как единый процесс и его взаимодействие с внешними сущностями.
- Диаграмма уровня 1:Разбивает основной процесс на основные подпроцессы.
- Диаграмма уровня 2:Дальнейшее разбиение конкретных подпроцессов для получения детального представления.
Хотя эта иерархия остаётся актуальной, природа «процесса» изменилась. Процесс больше не является просто пакетной задачей; он часто представляет собой непрерывную службу или предиктивную модель.
🧠 Интеграция ИИ: моделирование интеллекта в потоках
Интеграция искусственного интеллекта (ИИ) вносит новые переменные в картографирование потоков данных. В традиционных системах логика явная. В системах, основанных на ИИ, логика часто вероятностная. Это различие требует изменения подхода к визуализации компонента «Процесс» в DFD.
1. Потоки обучения и вывода
Потоки машинного обучения значительно отличаются от стандартной логики приложений. Диаграмма потоков данных для системы на основе ИИ должна различать фазу обучения и фазу вывода.
- Поток обучения:Включает большие наборы данных, перемещающиеся от хранилища к вычислительным кластерам. Результатом является обученная модель. Этот поток часто ориентирован на пакетную обработку и требует значительных ресурсов.
- Поток вывода:Включает данные в реальном времени или почти в реальном времени, поступающие в модель для генерации прогнозов. Этот поток ориентирован на низкую задержку и высокую пропускную способность.
При построении этих потоков крайне важно отметить, что сама модель выступает в качестве процесса «чёрного ящика». Внутренняя логика скрыта, но требования к входным данным и форматы выходных данных должны быть чётко определены на диаграмме.
2. Обработка данных как процесс
Перед тем как данные достигнут модели ИИ, они проходят значительную трансформацию. Инженерия признаков, нормализация и очистка — критически важные этапы, которые должны быть видны на диаграмме потоков данных. Игнорирование этих этапов приводит к неполному пониманию системы.
- Нормализация: Масштабирование данных для соответствия ожиданиям модели.
- Кодирование: Преобразование категориальных данных в числовые векторы.
- Восстановление: Обработка отсутствующих значений в потоке.
Эти этапы предварительной обработки являются процессами. Они требуют времени и вычислительных ресурсов, а также вводят потенциальные точки отказа, которые необходимо отслеживать в потоке данных.
🌊 Большие данные: обработка объёма, скорости и разнообразия
Архитектуры больших данных ставят под сомнение линейный характер традиционных диаграмм потоков данных. Данные часто поступают потоками, хранятся в хранилищах данных и обрабатываются с помощью распределённых вычислений. Статическая диаграмма не может легко отразить динамическую природу таких сред.
1. Потоковая обработка против пакетной обработки
Современные системы часто используют гибридный подход. Некоторые данные обрабатываются в режиме реального времени, в то время как другие данные накапливаются для пакетной аналитики. Диаграмма потоков данных должна чётко разделять эти два пути.
- Потоковая обработка: Данные поступают непрерывно. Диаграмма должна изображать конвейер в виде непрерывного цикла, а не последовательности «старт-стоп».
- Пакетная обработка: Данные накапливаются с течением времени и обрабатываются порциями. Диаграмма должна отражать точку накопления (хранилище данных) до начала процесса.
2. Визуализация распределённого хранения
В монолитной базе данных хранилище данных — это одна коробка. В среде больших данных хранение распределено. Диаграмма потоков данных должна указывать, что «хранилище данных» может на самом деле представлять собой кластер узлов или систему разделённого хранения.
- Хранилища данных: Хранение неструктурированных данных, где структура применяется позже.
- Хранилища данных: Структурированное хранение, оптимизированное для запросов.
- Горячее и холодное хранение: Различие между часто используемыми данными и архивными данными.
Это различие имеет решающее значение для понимания задержек. Поток данных с узла горячего хранения будет вести себя иначе, чем поток данных из архива холодного хранения.
📐 Современное усовершенствование нотации
Чтобы эффективно передавать сложные системы, нотация, используемая в диаграммах потоков данных, должна адаптироваться. Хотя основные символы остаются похожими, их применение требует тонкости.
| Компонент | Традиционная DFD | Современная DFD с ИИ/большими данными |
|---|---|---|
| Процесс | Одношаговая трансформация | Микросервис, вывод модели или этап обработки |
| Хранилище данных | Файл или таблица базы данных | Данные озера, распределённый кэш или объектное хранилище |
| Поток данных | Запрос/ответ или передача файла | Поток событий, нагрузка API или очередь сообщений |
| Сущность | Человек-пользователь или устаревшая система | Устройство IoT, сторонний API или автономный агент |
1. Архитектура, основанная на событиях
Многие современные системы полагаются на события, а не на прямые запросы. DFD для системы, основанной на событиях, использует триггеры для запуска процессов. Вместо того чтобы процесс ждал поступления данных, приход данных запускает процесс.
- Очереди сообщений: Выступают в качестве буферов между производителями и потребителями.
- Журналы событий: Неизменяемые записи изменений состояния, выступающие в качестве хранилищ данных для аудита.
Визуализация этих очередей как хранилищ данных помогает прояснить проблемы обратного давления. Если процесс не справляется со входящим потоком, очередь растёт. Этот риск необходимо отобразить.
2. Микросервисы и границы
По мере того как системы распадаются на микросервисы, граница системы в DFD становится более проницаемой. Потоки данных часто пересекают границы сервисов через API. Важно указывать используемый протокол (например, REST, gRPC, GraphQL) на линиях потоков данных, чтобы показать требования совместимости.
- Обнаружение сервисов:Динамическое маршрутизирование потоков данных.
- Балансировка нагрузки:Распределение потоков данных между несколькими экземплярами.
🔒 Безопасность и конфиденциальность в потоках данных
Безопасность не может быть второстепенной в диаграмме потоков данных. В условиях таких регуляций, как GDPR и CCPA, понимание того, где находятся и как перемещаются конфиденциальные данные, является обязательным.
1. Выявление конфиденциальных данных
Потоки данных, содержащие персональную информацию (PII) или защищенную медицинскую информацию (PHI), должны быть выделены. Используйте различные стили линий или цвета для обозначения чувствительных потоков.
- Шифрование в процессе передачи: Все потоки, пересекающие границы сети, должны указывать протоколы шифрования (например, TLS).
- Шифрование в состоянии покоя: Хранилища данных, содержащие чувствительную информацию, должны быть помечены.
2. Происхождение данных
Понимание происхождения данных критически важно для соблюдения требований. Диаграмма потоков данных (DFD) служит картой происхождения на высоком уровне. Она показывает, где данные поступают в систему и как они трансформируются.
- Отслеживание согласия: Потоки, затрагивающие данные согласия пользователей, должны отслеживаться отдельно.
- Право на забвение: Диаграммы должны показывать, где хранятся данные, чтобы облегчить запросы на удаление.
Если DFD не показывает, где хранятся данные, аудит соблюдения становится невозможным. У каждого хранилища данных должен быть определенный владелец и политика хранения.
⚙️ Проблемы при создании современных DFD
Создание точных диаграмм для сложных систем сопряжено с конкретными трудностями. Объем данных и скорость изменений часто опережают усилия по документированию.
1. Динамические системы
Группы автоматического масштабирования динамически изменяют количество экземпляров процессов. Статическая диаграмма не может отобразить это. Диаграмма должна отражать *возможности* системы, а не только её текущее состояние.
- Используйте общие метки, такие как «Вычислительный кластер», вместо конкретных идентификаторов экземпляров.
- Укажите триггеры масштабирования в описании процесса.
2. Управление сложностью
По мере роста систем DFD становятся непонятными. Ключевым является абстрагирование. Не отображайте каждый конечный пункт API. Отображайте логическое перемещение данных.
- Группировка: Объедините связанные процессы в один супер-процесс.
- Связывание: Используйте ссылки для связи подробных поддиаграмм с общими обзорами.
3. Реальные зависимости
В системах потоковой передачи важен порядок операций. DFD показывает соединения, но не всегда временные аспекты. Дополните DFD диаграммами последовательности, если временные параметры критичны.
- Укажите таймауты и повторные попытки в описании процессов.
- Укажите, являются ли потоки данных синхронными или асинхронными.
🚀 Будущие тенденции: автоматизация и самодокументирование
Будущее DFD лежит в автоматизации. По мере того как системы становятся более ориентированными на код, диаграммы должны генерироваться из кодовой базы, а не рисоваться вручную.
1. Инфраструктура как код (IaC)
Когда инфраструктура определяется в коде, поток данных определяется неявно. Инструменты могут анализировать файлы IaC для автоматической генерации диаграмм потоков данных (DFD).
- Обеспечьте согласованность между диаграммой и фактической инфраструктурой.
- Используйте систему контроля версий для самих определений диаграмм.
2. Непрерывное обнаружение
Инструменты мониторинга сети могут обнаруживать реальные потоки данных. Интеграция этих инструментов с программным обеспечением для диаграмм потоков данных позволяет создавать «живые» диаграммы, которые обновляются при изменении паттернов трафика.
- Выполнять оповещение при появлении новых потоков данных, которые не были документированы.
- Выделять неиспользуемые хранилища данных, которые можно отключить.
3. Диаграммирование с использованием искусственного интеллекта
Искусственный интеллект может предлагать улучшения диаграмм. Он может выявлять узкие места, избыточные пути или уязвимости в безопасности на основе лучших практик.
- Автоматическая проверка правил потока данных (например, отсутствие прямого потока от базы данных к внешнему сущности без процесса).
- Предложение оптимального разбиения процессов.
🛠️ Лучшие практики реализации
Чтобы сохранить ценность диаграмм потоков данных в современном контексте, придерживайтесь следующих практик.
- Стандартизируйте нотацию: Убедитесь, что все члены команды используют одни и те же символы и соглашения. Согласованность снижает когнитивную нагрузку.
- Определите соглашения по именованию: Процессы должны называться по шаблону глагол-существительное (например, «Проверка ввода пользователя»). Хранилища данных должны называться существительными (например, «Профили пользователей»).
- Регулярно проводите обзор: Диаграмма, которая не обновляется, становится ложью. Планируйте обзоры во время планирования спринтов или встреч по улучшению архитектуры.
- Фокусируйтесь на ценности: Отображайте только те потоки данных, которые необходимы для бизнес-логики. Удалите избыточные внутренние потоки, которые не влияют на конечного пользователя.
- Документируйте предположения: Если поток предполагает определённую задержку или пропускную способность, зафиксируйте это. Эти предположения влияют на проектирование системы.
🔄 Жизненный цикл потока данных
Понимание жизненного цикла помогает точно отобразить диаграмму. Данные проходят через несколько этапов:
- Приём: Данные входят в границы системы. Это часто наиболее нестабильная точка.
- Обработка: Данные преобразуются, обогащаются или анализируются.
- Хранение: Данные сохраняются для последующего использования.
- Извлечение: Данные извлекаются для отчетности или действий.
- Утилизация: Данные архивируются или удаляются в соответствии с политикой.
Каждая стадия представляет собой потенциальный процесс или хранилище в диаграмме потока данных. Полная диаграмма учитывает этап утилизации, обеспечивая, чтобы данные не оставались без необходимости.
📊 Обзор ключевых компонентов
Для быстрого ознакомления приведено сравнение традиционных компонентов с их современными аналогами.
| Традиционное понятие | Современный эквивалент | Учетные факторы |
|---|---|---|
| Ввод | Шлюз API / Поток приема данных | Аутентификация и ограничение скорости |
| Вывод | Панель мониторинга / Служба уведомлений | Форматирование и канал доставки |
| Процесс | Функция / Контейнер / Модель | Безсостоятельность и масштабируемость |
| Хранилище | Объектное хранилище / База данных NoSQL | Разделение и индексация |
| Поток | Событие / HTTP-запрос | Задержка и надежность |
Сопоставляя эти концепции, команды могут создавать диаграммы, которые служат эффективными инструментами коммуникации между инженерами, специалистами по данным и бизнес-заинтересованными сторонами. Цель — не идеальность, а ясность. Диаграмма, способствующая принятию решений, считается успешной.
🔮 Заключительные мысли о визуализации потока данных
Принципы диаграмм потока данных вечны, но их применение требует адаптации. По мере того как данные становятся ключевым активом современных предприятий, способность визуализировать их движение становится стратегическим преимуществом. Независимо от того, управляете ли вы простой базой данных или сложной системой нейросетевого потока, диаграмма потока данных обеспечивает необходимую структуру для понимания, защиты и оптимизации потока информации.
Следование этим методологиям гарантирует, что архитектура систем останется прозрачной и поддерживаемой. Переход от статической документации к динамическому, автоматизированному визуальному представлению неизбежен. Команды, которые примут этот переход, окажутся лучше подготовленными к решению сложностей цифровой эпохи.
Сосредоточьтесь на данных. Следите за потоком. Убедитесь, что логика сохраняется. Это остаётся основным требованием эффективного проектирования систем.