











En la evolución del panorama de la tecnología de la información, el diagrama de flujo de datos (DFD) sigue siendo un elemento fundamental para el análisis de sistemas. Aunque originalmente concebido durante la era de la programación estructurada de los años 70, la utilidad de visualizar cómo los datos se mueven a través de un sistema no ha disminuido. Al contrario, ha evolucionado. A medida que las organizaciones enfrentan modelos de aprendizaje automático, sistemas de almacenamiento distribuidos y flujos de procesamiento en tiempo real, la necesidad de mapear las trayectorias de los datos se ha vuelto más crítica que nunca.
Esta guía explora la adaptación de los DFD a los entornos computacionales modernos. Examina cómo los diagramas tradicionales deben evolucionar para representar flujos de trabajo de inteligencia artificial, arquitecturas de grandes datos y infraestructuras nativas en la nube, sin depender de herramientas específicas de proveedores. El enfoque sigue centrado en la integridad conceptual del movimiento, seguridad y transformación de los datos.
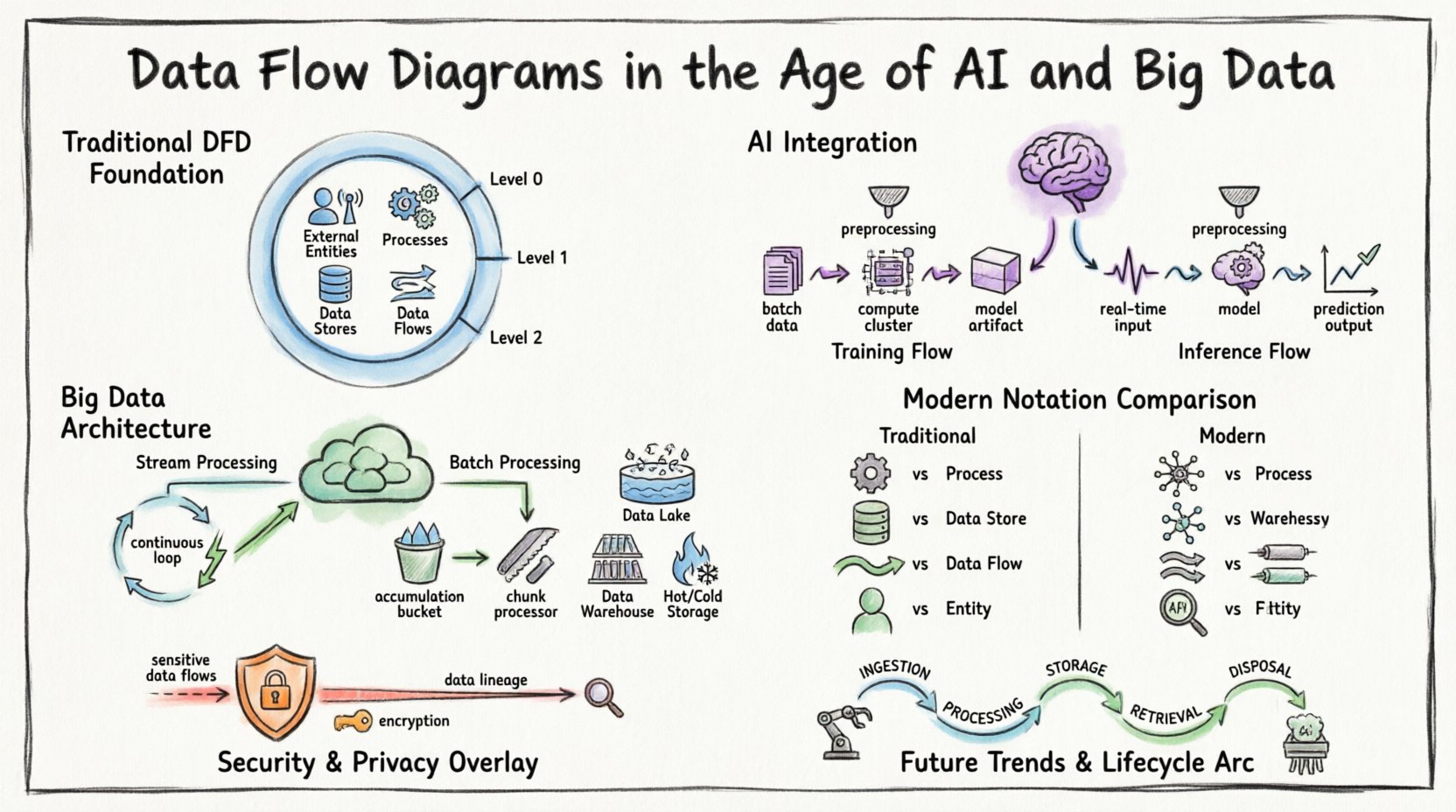
🏛️ La base: comprensión de los diagramas de flujo de datos
Antes de abordar las complejidades modernas, es esencial establecer la definición básica. Un diagrama de flujo de datos es una representación gráfica del flujo de datos a través de un sistema de información. Modela el movimiento de la información desde fuentes externas hasta destinos e procesos internos.
Los componentes clave definen un DFD estándar:
- Entidades externas:Fuentes o destinos fuera de los límites del sistema (por ejemplo, usuarios, otros sistemas, sensores).
- Procesos:Transformaciones que convierten datos de entrada en datos de salida.
- Almacenes de datos:Almacenes donde se guarda la data para su uso posterior (por ejemplo, bases de datos, sistemas de archivos).
- Flujos de datos:El movimiento de datos entre entidades, procesos y almacenes.
En contextos tradicionales, estos diagramas a menudo se dibujaban a múltiples niveles de abstracción:
- Diagrama de contexto (Nivel 0):Muestra el sistema como un único proceso y sus interacciones con entidades externas.
- Diagrama de nivel 1:Descompone el proceso principal en subprocesos principales.
- Diagrama de nivel 2:Descompone aún más subprocesos específicos para obtener detalles más finos.
Aunque esta jerarquía sigue siendo válida, la naturaleza del «proceso» ha cambiado. Un proceso ya no es solo un trabajo por lotes; a menudo es un servicio continuo o un modelo predictivo.
🧠 Integración de IA: modelado de inteligencia en flujos
La integración de la inteligencia artificial (IA) introduce nuevas variables en el mapeo de flujos de datos. En los sistemas tradicionales, la lógica es explícita. En los sistemas impulsados por IA, la lógica suele ser probabilística. Esta distinción requiere un cambio en la forma en que visualizamos el componente «proceso» de un DFD.
1. Flujos de entrenamiento frente a flujos de inferencia
Las pipelines de aprendizaje automático difieren significativamente de la lógica de aplicaciones estándar. Un DFD para un sistema de IA debe distinguir entre la fase de entrenamiento y la fase de inferencia.
- Flujo de entrenamiento:Implica grandes conjuntos de datos que se mueven desde el almacenamiento hasta clusters de computación. La salida es un artefacto de modelo entrenado. Este flujo suele ser orientado por lotes y de alto consumo de recursos.
- Flujo de inferencia:Implica datos en tiempo real o casi en tiempo real que entran en el modelo para generar predicciones. Este flujo prioriza baja latencia y alto rendimiento.
Al mapear estos flujos, es crucial tener en cuenta que el modelo en sí mismo actúa como un proceso de caja negra. La lógica interna está oculta, pero los requisitos de entrada y los formatos de salida deben definirse claramente en el diagrama.
2. Preprocesamiento de datos como un proceso
Antes de que los datos lleguen a un modelo de IA, experimentan una transformación significativa. La ingeniería de características, la normalización y la limpieza son pasos críticos que deben ser visibles en el DFD. Ignorar estos pasos conduce a una comprensión incompleta del sistema.
- Normalización: Escalar los datos para ajustarlos a las expectativas del modelo.
- Codificación: Convirtiendo datos categóricos en vectores numéricos.
- Imputación: Manejo de valores faltantes dentro del flujo.
Estos pasos de preprocesamiento son procesos. Consumen tiempo y recursos computacionales, e introducen puntos potenciales de fallo que deben rastrearse en el flujo de datos.
🌊 Big Data: Manejo de volumen, velocidad y variedad
Las arquitecturas de big data desafían la naturaleza lineal de los DFD tradicionales. Los datos a menudo llegan en flujos, se almacenan en lagos de datos y se procesan mediante computación distribuida. Un diagrama estático no puede capturar fácilmente la naturaleza dinámica de estos entornos.
1. Procesamiento por streaming frente a procesamiento por lotes
Los sistemas modernos a menudo emplean un enfoque híbrido. Algunos datos se procesan en flujos en tiempo real, mientras que otros datos se agregan para análisis por lotes. El DFD debe delimitar claramente estos dos caminos.
- Procesamiento de flujos: Los datos fluyen de forma continua. El diagrama debe representar la canalización como un bucle continuo en lugar de una secuencia de inicio y parada.
- Procesamiento por lotes: Los datos se acumulan con el tiempo y se procesan en fragmentos. El diagrama debe reflejar el punto de acumulación (almacén de datos) antes de que comience el proceso.
2. Visualización del almacenamiento distribuido
En una base de datos monolítica, un almacén de datos es una sola caja. En un entorno de big data, el almacenamiento es distribuido. El DFD debe indicar que un «almacén de datos» puede representar en realidad un clúster de nodos o un sistema de almacenamiento particionado.
- Lagos de datos: Almacenamiento de datos sin estructurar, donde se aplica la estructura posteriormente.
- Almacenes de datos: Almacenamiento estructurado optimizado para consultas.
- Almacenamiento caliente frente a almacenamiento frío: Diferenciar entre datos de acceso frecuente y datos archivados.
Esta distinción es vital para comprender la latencia. Un flujo desde un nodo de almacenamiento caliente se comportará de forma diferente que un flujo desde un archivo de almacenamiento frío.
📐 Modernización de la notación
Para comunicar eficazmente sistemas complejos, la notación utilizada en los DFD debe adaptarse. Aunque los símbolos principales permanecen similares, su aplicación requiere matiz.
| Componente | DFD tradicional | DFD moderno de IA/Big Data |
|---|---|---|
| Proceso | Paso único de transformación | Microservicio, inferencia de modelo o etapa de pipeline |
| Almacén de datos | Archivo o tabla de base de datos | Lago de datos, caché distribuida o almacén de objetos |
| Flujo de datos | Solicitud/respuesta o transferencia de archivos | Flujo de eventos, carga útil de API o cola de mensajes |
| Entidad | Usuario humano o sistema heredado | Dispositivo IoT, API de terceros o agente autónomo |
1. Arquitectura basada en eventos
Muchos sistemas modernos dependen de eventos en lugar de solicitudes directas. Un DFD para un sistema basado en eventos utiliza desencadenantes para iniciar procesos. En lugar de que un proceso espere datos, la llegada de datos desencadena el proceso.
- Colas de mensajes: Actúan como búferes entre productores y consumidores.
- Registros de eventos:Registros inmutables de cambios de estado que sirven como almacenes de datos para auditorías.
Visualizar estas colas como almacenes de datos ayuda a aclarar los problemas de retroalimentación. Si un proceso no puede mantener el ritmo del flujo entrante, la cola crece. Este riesgo debe ser mapeado.
2. Microservicios y límites
A medida que los sistemas se dividen en microservicios, el límite del sistema en un DFD se vuelve más permeable. Los flujos de datos a menudo cruzan los límites de servicio mediante APIs. Es importante etiquetar el protocolo utilizado (por ejemplo, REST, gRPC, GraphQL) en las líneas de flujo de datos para indicar los requisitos de compatibilidad.
- Descubrimiento de servicios:Enrutamiento dinámico de flujos de datos.
- Equilibrio de carga:Distribución de flujos de datos entre múltiples instancias.
🔒 Seguridad y privacidad en flujos de datos
La seguridad no puede ser una consideración posterior en un diagrama de flujo de datos. Con regulaciones como el GDPR y el CCPA, comprender dónde reside y se mueve la información sensible es obligatorio.
1. Identificación de datos sensibles
Los flujos de datos que transportan información personalmente identificable (PII) o información de salud protegida (PHI) deben resaltarse. Utilice estilos de línea o colores distintos para indicar flujos sensibles.
- Cifrado en tránsito:Todos los flujos que cruzan límites de red deben indicar los protocolos de cifrado (por ejemplo, TLS).
- Cifrado en reposo:Los almacenes de datos que contienen datos sensibles deben marcarse.
2. Línea de datos
Comprender el origen de los datos es fundamental para el cumplimiento. Un DFD actúa como un mapa de línea de datos de alto nivel. Muestra dónde entra la data en el sistema y cómo se transforma.
- Seguimiento de consentimiento:Los flujos que involucran datos de consentimiento del usuario deben rastrearse por separado.
- Derecho a la eliminación:Los diagramas deben mostrar dónde se almacena la data para facilitar las solicitudes de eliminación.
Si un DFD no muestra dónde se almacena la data, los auditorías de cumplimiento se vuelven imposibles. Cada almacén de datos debe tener un propietario definido y una política de retención.
⚙️ Desafíos en la creación de DFD modernos
Crear diagramas precisos para sistemas complejos presenta obstáculos específicos. El volumen de datos y la velocidad de cambio a menudo superan los esfuerzos de documentación.
1. Sistemas dinámicos
Los grupos de escalado automático cambian el número de instancias de procesos dinámicamente. Un diagrama estático no puede mostrar esto. El diagrama debe representar la *capacidad* del sistema, no solo su estado actual.
- Utilice etiquetas genéricas como «Cluster de cómputo» en lugar de identificadores específicos de instancias.
- Indique los desencadenantes de escalado en la descripción del proceso.
2. Gestión de la complejidad
A medida que los sistemas crecen, los DFD se vuelven ilegibles. La abstracción es clave. No mapee cada punto final de API. Mapee el movimiento lógico de datos.
- Agrupación:Combine procesos relacionados en un solo superproceso.
- Enlace:Utilice referencias cruzadas para vincular subdiagramas detallados con vistas generales de alto nivel.
3. Dependencias en tiempo real
En sistemas de streaming, el orden de las operaciones importa. Un DFD muestra conectividad, pero no siempre el tiempo. Complemente los DFD con diagramas de secuencia si el tiempo es crítico.
- Indique tiempos de espera y reintentos en las descripciones del proceso.
- Indique si los flujos de datos son síncronos o asíncronos.
🚀 Tendencias futuras: Automatización y documentación autónoma
El futuro de los DFD reside en la automatización. A medida que los sistemas se vuelven más centrados en el código, los diagramas deben generarse a partir de la base de código en lugar de dibujarse manualmente.
1. Infraestructura como código (IaC)
Cuando la infraestructura se define en código, el flujo de datos queda implícitamente definido. Las herramientas pueden analizar archivos IaC para generar diagramas de flujo de datos (DFD) automáticamente.
- Asegúrese de que haya consistencia entre el diagrama y la infraestructura real.
- Utilice control de versiones para las definiciones del diagrama en sí.
2. Descubrimiento continuo
Las herramientas de monitoreo de red pueden detectar flujos de datos reales. Integrar estas herramientas con software de DFD permite diagramas “en vivo” que se actualizan conforme cambian los patrones de tráfico.
- Genere alertas cuando aparezcan flujos de datos nuevos que no estén documentados.
- Marque los almacenes de datos no utilizados que puedan darse de baja.
3. Diagramación asistida por IA
La inteligencia artificial puede sugerir mejoras en los diagramas. Puede identificar cuellos de botella, rutas redundantes o brechas de seguridad basándose en las mejores prácticas.
- Validación automatizada de las reglas de flujo de datos (por ejemplo, no debe haber un flujo directo desde una base de datos hacia una entidad externa sin un proceso intermedio).
- Sugerencia de una descomposición óptima de los procesos.
🛠️ Mejores prácticas para la implementación
Para mantener el valor de los DFD en un contexto moderno, adhiera a las siguientes prácticas.
- Estandarice la notación:Asegúrese de que todos los miembros del equipo utilicen los mismos símbolos y convenciones. La consistencia reduce la carga cognitiva.
- Defina convenciones de nomenclatura:Los procesos deben nombrarse con estructuras verbo-nombre (por ejemplo, “Validar entrada de usuario”). Los almacenes de datos deben nombrarse como sustantivos (por ejemplo, “Perfiles de usuario”).
- Revise con regularidad:Un diagrama que no se revisa se convierte en una mentira. Programa revisiones durante las reuniones de planificación de sprints o de refinamiento arquitectónico.
- Enfóquese en el valor:Solo represente los flujos de datos necesarios para la lógica del negocio. Elimine los flujos internos redundantes que no afecten al usuario final.
- Documente las suposiciones:Si un flujo asume una latencia o rendimiento determinados, documentélo. Estas suposiciones afectan el diseño del sistema.
🔄 El ciclo de vida de un flujo de datos
Comprender el ciclo de vida ayuda a representar el diagrama con precisión. Los datos pasan por varias etapas:
- Ingesta:Los datos ingresan al límite del sistema. Este es a menudo el punto más volátil.
- Procesamiento:Los datos se transforman, enriquecen o analizan.
- Almacenamiento:Los datos se conservan para su uso futuro.
- Recuperación:Los datos se acceden para informes o acciones.
- Eliminación:Los datos se archivan o eliminan según la política.
Cada etapa representa un proceso o almacén potencial en el diagrama de flujo de datos. Un diagrama completo incluye la fase de eliminación, asegurando que los datos no permanezcan innecesariamente.
📊 Resumen de los Componentes Clave
Para referencia rápida, aquí se presenta una descripción de cómo los componentes tradicionales se corresponden con sus equivalentes modernos.
| Concepto Tradicional | Equivalente Moderno | Consideración |
|---|---|---|
| Entrada | Puerta de enlace de API / Canal de ingestión | Autenticación y límite de tasa |
| Salida | Panel de control / Servicio de notificaciones | Formateo y canal de entrega |
| Proceso | Función / Contenedor / Modelo | Inmunidad de estado y escalabilidad |
| Almacenamiento | Almacén de objetos / Base de datos NoSQL | Particionado e indexación |
| Flujo | Mensaje de evento / Solicitud HTTP | Latencia y fiabilidad |
Al alinear estos conceptos, los equipos pueden crear diagramas que sirvan como herramientas de comunicación efectivas entre ingenieros, científicos de datos y partes interesadas del negocio. El objetivo no es la perfección, sino la claridad. Un diagrama que ayuda en la toma de decisiones es exitoso.
🔮 Reflexiones Finales sobre la Visualización del Flujo de Datos
Los principios de los Diagramas de Flujo de Datos son atemporales, pero su aplicación requiere adaptación. A medida que los datos se convierten en el activo central de las empresas modernas, la capacidad de visualizar su movimiento es una ventaja estratégica. Ya sea gestionar una base de datos simple o una compleja canalización de red neuronal, el DFD proporciona la estructura necesaria para comprender, proteger y optimizar el flujo de información.
Mantenerse al día con estas metodologías garantiza que las arquitecturas de sistemas permanezcan transparentes y mantenibles. El cambio de la documentación estática a la visualización dinámica y automatizada es inevitable. Los equipos que adopten este cambio se encontrarán mejor preparados para enfrentar las complejidades de la era digital.
Enfóquese en los datos. Siga el flujo. Asegúrese de que la lógica sea coherente. Esto sigue siendo la misión fundamental del diseño eficaz de sistemas.