











Dans l’évolution du paysage des technologies de l’information, le diagramme de flux de données (DFD) reste un élément fondamental pour l’analyse des systèmes. Bien qu’il ait été initialement conçu durant l’ère du programmation structurée des années 1970, l’utilité de visualiser le déplacement des données à travers un système n’a pas diminué. Au contraire, elle s’est transformée. Alors que les organisations doivent faire face à des modèles d’apprentissage automatique, des systèmes de stockage distribués et des flux de traitement en temps réel, la nécessité de cartographier les trajectoires des données est devenue plus critique que jamais.
Ce guide explore l’adaptation des DFD aux environnements informatiques modernes. Il examine comment les diagrammes traditionnels doivent évoluer pour représenter les flux de travail de l’intelligence artificielle, les architectures de grandes données et les infrastructures natives du cloud, sans dépendre d’outils spécifiques aux fournisseurs. L’accent reste sur l’intégrité conceptuelle du déplacement des données, de la sécurité et de la transformation.
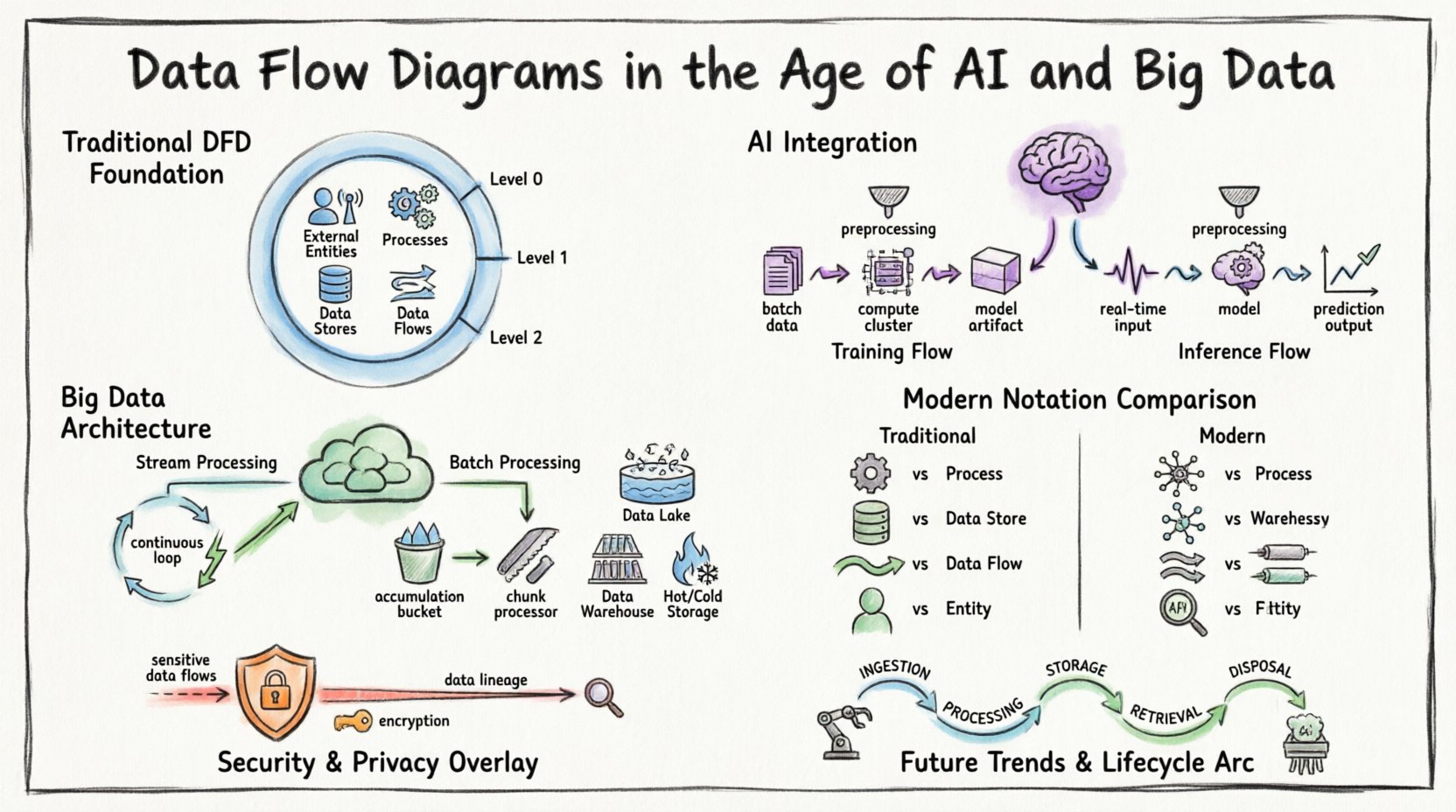
🏛️ La base : comprendre les diagrammes de flux de données
Avant d’aborder les complexités modernes, il est essentiel d’établir la définition de base. Un diagramme de flux de données est une représentation graphique du déplacement des données à travers un système d’information. Il modélise le mouvement de l’information depuis des sources externes jusqu’à des destinations et des processus internes.
Les composants clés définissent un DFD standard :
- Entités externes :Sources ou destinations situées en dehors de la frontière du système (par exemple : utilisateurs, autres systèmes, capteurs).
- Processus :Transformations qui transforment les données d’entrée en données de sortie.
- Stockages de données :Référentiels où les données sont conservées pour une utilisation ultérieure (par exemple : bases de données, systèmes de fichiers).
- Flux de données :Le déplacement des données entre les entités, les processus et les stockages.
Dans les contextes traditionnels, ces diagrammes étaient souvent tracés à plusieurs niveaux d’abstraction :
- Diagramme de contexte (Niveau 0) :Montre le système comme un seul processus et ses interactions avec les entités externes.
- Diagramme de niveau 1 :Décompose le processus principal en sous-processus majeurs.
- Diagramme de niveau 2 :Décompose davantage des sous-processus spécifiques pour obtenir un détail fin.
Bien que cette hiérarchie reste valable, la nature du « processus » a évolué. Un processus n’est plus simplement un traitement par lots ; il est souvent un service continu ou un modèle prédictif.
🧠 Intégration de l’IA : modélisation de l’intelligence dans les flux
L’intégration de l’intelligence artificielle (IA) introduit de nouvelles variables dans la cartographie des flux de données. Dans les systèmes traditionnels, la logique est explicite. Dans les systèmes pilotés par l’IA, la logique est souvent probabiliste. Cette distinction exige un changement dans la manière dont nous visualisons le composant « Processus » d’un DFD.
1. Flux d’apprentissage versus flux d’inférence
Les pipelines d’apprentissage automatique diffèrent considérablement de la logique des applications standards. Un DFD pour un système d’IA doit distinguer la phase d’apprentissage de la phase d’inférence.
- Flux d’apprentissage :Implique de grands ensembles de données qui se déplacent du stockage vers des clusters de calcul. La sortie est un artefact de modèle entraîné. Ce flux est souvent orienté par lots et intensif en ressources.
- Flux d’inférence :Implique des données en temps réel ou quasi en temps réel qui entrent dans le modèle pour générer des prédictions. Ce flux privilégie une faible latence et un haut débit.
Lors de la cartographie de ces flux, il est crucial de noter que le modèle lui-même agit comme un processus en boîte noire. La logique interne est masquée, mais les exigences d’entrée et les formats de sortie doivent être clairement définis dans le schéma.
2. Le prétraitement des données comme un processus
Avant que les données n’atteignent un modèle d’IA, elles subissent une transformation importante. L’ingénierie des caractéristiques, la normalisation et le nettoyage sont des étapes critiques qui doivent être visibles dans le DFD. Ignorer ces étapes conduit à une compréhension incomplète du système.
- Normalisation :Mise à l’échelle des données pour correspondre aux attentes du modèle.
- Encodage :Conversion des données catégorielles en vecteurs numériques.
- Imputation :Gestion des valeurs manquantes au sein du flux.
Ces étapes de prétraitement sont des processus. Elles consomment du temps et des ressources informatiques, et elles introduisent des points de défaillance potentiels qui doivent être suivis dans le flux de données.
🌊 Big Data : Gestion du volume, de la vitesse et de la variété
Les architectures big data remettent en question la nature linéaire des DFD traditionnels. Les données arrivent souvent en flux, sont stockées dans des lacs de données et sont traitées via des calculs distribués. Un schéma statique ne peut pas facilement capturer la nature dynamique de ces environnements.
1. Traitement en flux continu vs. traitement par lots
Les systèmes modernes utilisent souvent une approche hybride. Certaines données sont traitées en flux en temps réel, tandis que d’autres sont regroupées pour une analyse par lots. Le DFD doit clairement distinguer ces deux chemins.
- Traitement en flux continu :Les données circulent de manière continue. Le schéma doit représenter le pipeline sous forme de boucle continue plutôt que comme une séquence de démarrage et d’arrêt.
- Traitement par lots :Les données s’accumulent au fil du temps et sont traitées par groupes. Le schéma doit refléter le point d’accumulation (Stockage de données) avant le début du traitement.
2. Visualisation du stockage distribué
Dans une base de données monolithique, un stockage de données est une seule boîte. Dans un environnement big data, le stockage est distribué. Le DFD doit indiquer qu’un « Stockage de données » peut en réalité représenter un cluster de nœuds ou un système de stockage partitionné.
- Lacs de données :Stockage de données brutes où la structure est appliquée ultérieurement.
- Entrepôts de données :Stockage structuré optimisé pour les requêtes.
- Stockage chaud vs. stockage froid :Différencier les données fréquemment accessibles des données archivées.
Cette distinction est vitale pour comprendre la latence. Un flux provenant d’un nœud de stockage chaud se comportera différemment d’un flux provenant d’un archivage de stockage froid.
📐 Modernisation de la notation
Pour communiquer efficacement des systèmes complexes, la notation utilisée dans les DFD doit évoluer. Bien que les symboles fondamentaux restent similaires, leur application exige des nuances.
| Composant | DFD traditionnel | DFD moderne IA/Big Data |
|---|---|---|
| Processus | Étape unique de transformation | Microservice, inférence de modèle ou étape de pipeline |
| Stockage de données | Fichier ou table de base de données | Lac de données, cache distribué ou magasin d’objets |
| Flux de données | Demande/Réponse ou transfert de fichier | Flux d’événements, charge utile d’API ou file d’attente de messages |
| Entité | Utilisateur humain ou système hérité | Appareil IoT, API tierce ou agent autonome |
1. Architecture orientée événements
De nombreux systèmes modernes reposent sur les événements plutôt que sur des requêtes directes. Un DFD pour un système orienté événements utilise des déclencheurs pour initier des processus. Au lieu qu’un processus attende les données, l’arrivée des données déclenche le processus.
- Files de messages : Agissent comme des tampons entre producteurs et consommateurs.
- Journaux d’événements : Enregistrements immuables des changements d’état qui servent de stockages de données pour la vérification.
Visualiser ces files comme des stockages de données aide à clarifier les problèmes de surcharge. Si un processus ne peut pas suivre le débit entrant, la file s’agrandit. Ce risque doit être cartographié.
2. Microservices et limites
À mesure que les systèmes se divisent en microservices, la frontière du système dans un DFD devient plus poreuse. Les flux de données franchissent souvent les frontières des services via des API. Il est important de préciser le protocole utilisé (par exemple, REST, gRPC, GraphQL) sur les lignes de flux de données pour indiquer les exigences de compatibilité.
- Découverte de service : Routage dynamique des flux de données.
- Équilibrage de charge : Répartition des flux de données sur plusieurs instances.
🔒 Sécurité et confidentialité dans les flux de données
La sécurité ne peut pas être une réflexion tardive dans un diagramme de flux de données. Avec des réglementations telles que le RGPD et le CCPA, comprendre où se trouve et se déplace les données sensibles est obligatoire.
1. Identification des données sensibles
Les flux de données transportant des informations personnelles identifiables (PII) ou des informations de santé protégées (PHI) doivent être mis en évidence. Utilisez des styles de ligne ou des couleurs distincts pour indiquer les flux sensibles.
- Chiffrement en transit :Tous les flux traversant les frontières du réseau doivent indiquer les protocoles de chiffrement (par exemple, TLS).
- Chiffrement au repos :Les magasins de données contenant des données sensibles doivent être marqués.
2. Traçabilité des données
Comprendre l’origine des données est essentiel pour le respect des réglementations. Un DFD sert de carte de traçabilité de haut niveau. Il montre où les données entrent dans le système et comment elles évoluent.
- Suivi du consentement :Les flux impliquant des données de consentement utilisateur doivent être suivis séparément.
- Droit à l’effacement :Les diagrammes doivent indiquer où les données sont stockées afin de faciliter les demandes de suppression.
Si un DFD ne montre pas où les données sont stockées, les audits de conformité deviennent impossibles. Chaque magasin de données doit avoir un propriétaire défini et une politique de conservation.
⚙️ Défis liés à la création de DFD modernes
La création de diagrammes précis pour des systèmes complexes soulève des défis spécifiques. Le volume de données et la rapidité des changements dépassent souvent les efforts de documentation.
1. Systèmes dynamiques
Les groupes d’autoscaling modifient le nombre d’instances de processus de manière dynamique. Un diagramme statique ne peut pas montrer cela. Le diagramme doit représenter la *capacité* du système, et non seulement son état actuel.
- Utilisez des étiquettes génériques telles que « Cluster de calcul » plutôt que des identifiants d’instance spécifiques.
- Indiquez les déclencheurs d’ajustement dans la description du processus.
2. Gestion de la complexité
À mesure que les systèmes grandissent, les DFD deviennent illisibles. L’abstraction est essentielle. Ne mappez pas chaque point de terminaison API. Cartographiez le déplacement logique des données.
- Regroupement :Regroupez les processus connexes en un seul super-processus.
- Liaison :Utilisez des références croisées pour relier les sous-diagrammes détaillés aux aperçus de haut niveau.
3. Dépendances en temps réel
Dans les systèmes de flux, l’ordre des opérations est important. Un DFD montre la connectivité, mais pas toujours le moment. Complétez les DFD par des diagrammes de séquence si le timing est critique.
- Indiquez les délais d’attente et les nouvelles tentatives dans les descriptions des processus.
- Précisez si les flux de données sont synchrones ou asynchrones.
🚀 Tendances futures : Automatisation et auto-documentation
L’avenir des DFD réside dans l’automatisation. À mesure que les systèmes deviennent plus centrés sur le code, les diagrammes doivent être générés à partir de la base de code plutôt que dessinés manuellement.
1. Infrastructure sous code (IaC)
Lorsque l’infrastructure est définie dans du code, le flux de données est implicitement défini. Les outils peuvent analyser les fichiers IaC pour générer automatiquement des diagrammes de flux de données (DFD).
- Assurez-vous de la cohérence entre le diagramme et l’infrastructure réelle.
- Utilisez le contrôle de version pour les définitions de diagramme elles-mêmes.
2. Découverte continue
Les outils de surveillance du réseau peuvent détecter les flux de données réels. Intégrer ces outils au logiciel de diagrammes de flux de données permet des diagrammes « en temps réel » qui se mettent à jour au fur et à mesure que les modèles de trafic évoluent.
- Générez une alerte lorsque de nouveaux flux de données apparaissent sans avoir été documentés.
- Signalez les magasins de données inutilisés pouvant être mis hors service.
3. Élaboration de diagrammes assistée par l’IA
L’intelligence artificielle peut suggérer des améliorations aux diagrammes. Elle peut identifier les goulets d’étranglement, les chemins redondants ou les failles de sécurité en se basant sur les bonnes pratiques.
- Validation automatisée des règles de flux de données (par exemple, pas de flux direct depuis une base de données vers une entité externe sans processus).
- Suggestion de décomposition optimale des processus.
🛠️ Meilleures pratiques pour la mise en œuvre
Pour maintenir la valeur des DFD dans un contexte moderne, respectez les pratiques suivantes.
- Normalisez la notation :Assurez-vous que tous les membres de l’équipe utilisent les mêmes symboles et conventions. La cohérence réduit la charge cognitive.
- Définissez des conventions de nommage :Les processus doivent être nommés selon la structure Verbe-Nom (par exemple, « Valider l’entrée utilisateur »). Les magasins de données doivent être nommés comme des noms (par exemple, « Profils utilisateurs »).
- Révisez régulièrement :Un diagramme qui n’est pas revu devient une mensonge. Prévoyez des revues lors de la planification des sprints ou des réunions d’optimisation architecturale.
- Concentrez-vous sur la valeur :Cartographiez uniquement les flux de données nécessaires à la logique métier. Supprimez les flux internes redondants qui n’affectent pas l’utilisateur final.
- Documentez les hypothèses :Si un flux suppose une latence ou un débit particulier, documentez-le. Ces hypothèses influencent la conception du système.
🔄 Le cycle de vie d’un flux de données
Comprendre le cycle de vie aide à cartographier le diagramme avec précision. Les données passent par plusieurs étapes :
- Ingestion :Les données entrent dans la frontière du système. C’est souvent le point le plus instable.
- Traitement :Les données sont transformées, enrichies ou analysées.
- Stockage :Les données sont conservées pour une utilisation future.
- Récupération :Les données sont récupérées pour des rapports ou des actions.
- Élimination :Les données sont archivées ou supprimées conformément à la politique.
Chaque étape représente un processus ou un stockage potentiel dans le diagramme de flux de données. Un diagramme complet prend en compte la phase d’élimination, garantissant que les données ne restent pas inutilement.
📊 Résumé des composants clés
Pour référence rapide, voici une analyse de la manière dont les composants traditionnels correspondent aux équivalents modernes.
| Concept traditionnel | Équivalent moderne | Considération |
|---|---|---|
| Entrée | Passerelle API / Pipeline d’ingestion | Authentification et limitation de débit |
| Sortie | Tableau de bord / Service de notification | Formatage et canal de livraison |
| Processus | Fonction / Conteneur / Modèle | État sans état et mise à l’échelle |
| Stockage | Stockage d’objets / Base de données NoSQL | Partitionnement et indexation |
| Flux | Message d’événement / Demande HTTP | Latence et fiabilité |
En alignant ces concepts, les équipes peuvent créer des diagrammes qui servent d’outils de communication efficaces entre les équipes d’ingénierie, les scientifiques des données et les parties prenantes métier. L’objectif n’est pas la perfection, mais la clarté. Un diagramme qui aide à la prise de décision est un succès.
🔮 Réflexions finales sur la visualisation du flux de données
Les principes des diagrammes de flux de données sont intemporels, mais leur application nécessite une adaptation. Alors que les données deviennent l’actif central des entreprises modernes, la capacité à visualiser leur déplacement constitue un avantage stratégique. Que vous gériez une base de données simple ou un pipeline complexe de réseau de neurones, le DFD fournit la structure nécessaire pour comprendre, sécuriser et optimiser le flux d’information.
Restez à jour avec ces méthodologies afin de garantir que les architectures système restent transparentes et maintenables. Le passage de la documentation statique à une visualisation dynamique et automatisée est inévitable. Les équipes qui adoptent ce changement se trouveront mieux équipées pour faire face aux complexités de l’ère numérique.
Concentrez-vous sur les données. Suivez le flux. Assurez-vous que la logique est cohérente. Cela reste la mission fondamentale d’une conception de système efficace.