











堅牢なデータ構造を設計することは、信頼性の高い情報システムの基盤である。この設計の中心には、データエンティティの相互作用を定義する視覚的なブループリントであるエンティティ関係図(ERD)がある。しかし、図だけでは効率性を保証するものではない。ERDの真の力を発揮するのは、厳格な正規化戦略と組み合わせたときである。目標は明確だ:ゼロ冗長性ストレージを達成する。これは重複データを排除し、整合性を確保し、ストレージコストを削減し、保守を簡素化することを意味する。
冗長性は単なるストレージの問題ではない。それは整合性の乱れを引き起こす可能性を秘めた論理的な欠陥である。データが厳密な関係を持たずに複数の行やテーブルに重複して存在する場合、更新異常は避けられない。1つの属性の変更が数十か所での更新を必要とするかもしれない。1か所でも見落とせば、データベースは破損してしまう。このガイドでは、ERD設計の文脈の中で正規化のメカニズムを検討し、実用的な応用と構造的純粋性に焦点を当てる。
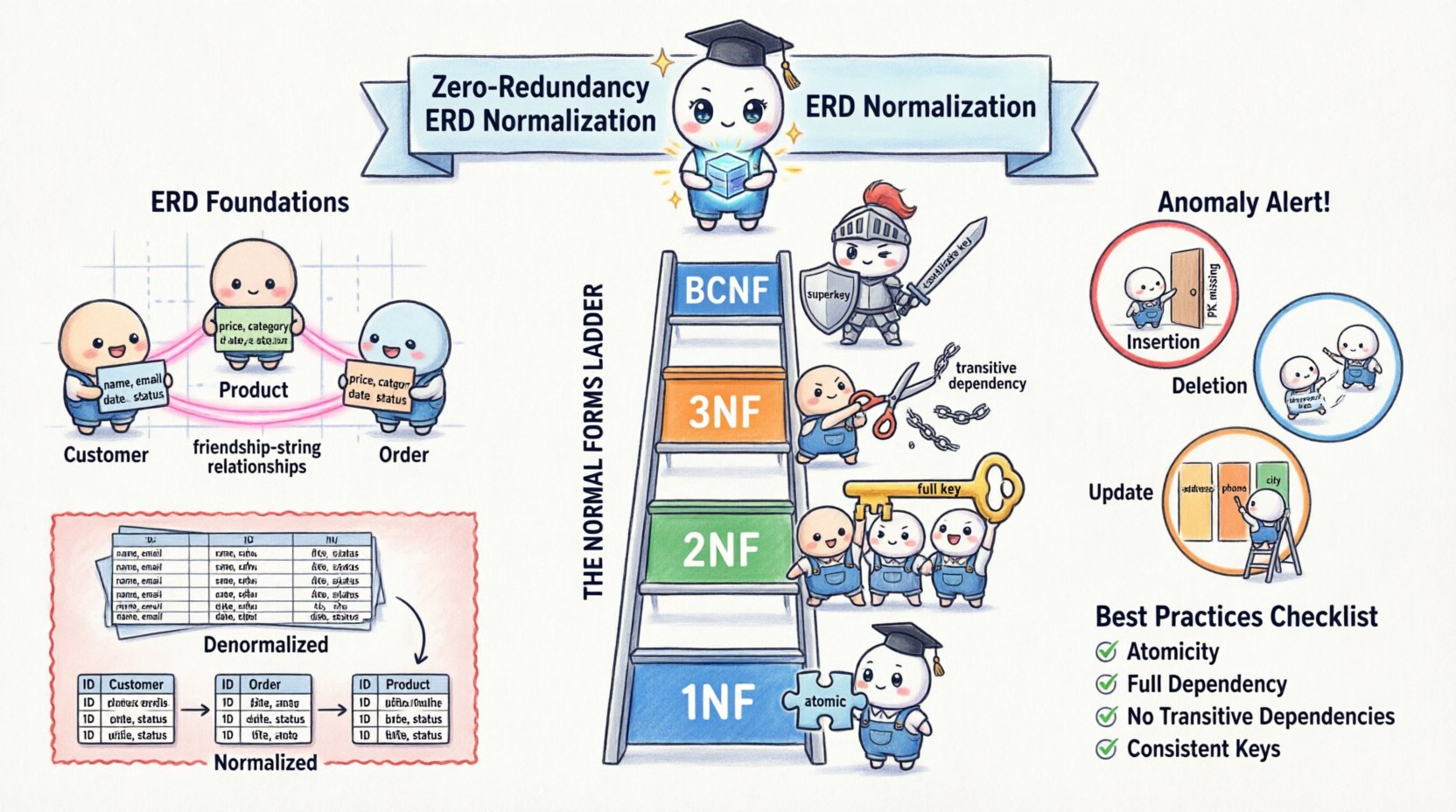
🧱 データモデリングの基盤を理解する
正規化ルールを適用する前に、エンティティ関係図の構成要素を理解する必要がある。ERDはエンティティ、属性、関係から構成される。エンティティは、顧客や製品といったオブジェクトや概念を表す。属性は、名前や価格といったエンティティを説明する性質である。関係は、外部キーを通じてエンティティがどのように接続されるかを定義する。
正規化とは、冗長性と依存関係を最小限に抑えるためにこれらの属性を整理するプロセスである。大きなテーブルをより小さな、論理的に関連したテーブルに分割し、それらの間の関係を定義する。目的は、各事実が唯一の場所に格納されるようにデータを分離することである。
非正規化アプローチと正規化アプローチの違いを検討してみよう。非正規化の視点では、注文ごとに顧客の住所や電話番号を含むすべての情報を1つのテーブルに保持する可能性がある。顧客が引っ越した場合、すべての注文記録を更新しなければならない。一方、正規化されたビューでは、顧客の住所は別個の顧客テーブルに存在する。注文テーブルは顧客IDへの参照だけを保持する。この分離こそがゼロ冗長性の本質である。
📉 非正規化データのリスク
なぜゼロ冗長性がこれほど重要なのか?その答えは、正規化を無視したときに発生する異常の種類にある。これらの異常は、システム全体の信頼性を脅かす。
- 挿入異常:あるエンティティのデータを追加するには、別のエンティティのデータを追加しなければならない。たとえば、新しい従業員がまだプロジェクトに割り当てられていない場合、テーブルがプロジェクトIDを必須としているなら、その従業員の存在を記録できなくなるかもしれない。
- 削除異常:あるエンティティのデータを削除すると、意図せず別のエンティティのデータも削除してしまう可能性がある。顧客の最後の注文を削除した場合、その顧客の連絡先情報が完全に失われる可能性がある。
- 更新異常:これは最も一般的な問題である。顧客の住所が複数の注文記録に保存されている場合、住所を更新するにはすべての記録を検索し、それぞれを変更しなければならない。これを怠ると、矛盾したデータが生じる。
ゼロ冗長性を達成することで、これらのリスクを直接軽減できる。各情報が唯一の場所に格納されることを保証することで、システムは自己修正可能になる。更新は一度だけ行われ、変更は関係を通じて論理的に伝播する。
🪜 正規形への道
正規化は単一のステップではなく、異なる段階である正規形と呼ばれるプロセスを経て進むものである。各正規形は特定の種類の冗長性に対処する。理論的には第五正規形(5NF)まで存在するが、実際のデータベース設計では通常、第一~第三正規形およびボーイス・コッド正規形(BCNF)に焦点を当てる。
1️⃣ 第一正規形(1NF)
正規化の第一のルールは、原子性を確保することである。テーブルが1NFにあるとは、繰り返しグループや配列を含まないことを意味する。すべての列は単一の値を保持し、すべての行は一意でなければならない。
- 原子値:フィールドは値のリストを含めることはできない。たとえば「スキル」という列に「Java、SQL、Python」と記録するのではなく、各スキルごとに別々の行を設けるか、スキル専用の別テーブルを用意すべきである。
- 一意の行:すべての行は他のすべての行と区別可能でなければならない。これは通常、主キーの存在を要する。
ERDの文脈では、すべての属性を確認することを意味する。属性が多値の性質を表している場合、それを抽出しなければならない。これが基盤となるステップである。1NFがなければ、上位の正規形は効果的に適用できない。
2️⃣ 第二正規形(2NF)
テーブルが1NFにあれば、2NFの基準を満たさなければならない。テーブルが2NFにあるとは、1NFにあり、かつすべての非キー属性が主キー全体に完全に依存していることを意味する。
このルールは主に複合キー(複数の列からなるキー)を持つテーブルに適用される。テーブルに複合キーがある場合、すべての属性はキー全体に依存しなければならず、キーの一部だけに依存してはならない。
- 完全依存:列が複合キーの一部だけに依存している場合、それは別のテーブルに属すべきである。
- 部分関数従属: これは2NFが排除する特定の冗長性です。たとえば、学生とコースをリンクするテーブルにおいて、「学生名」を保存している場合、それはコースIDではなく学生IDにのみ依存します。これにより冗長性が生じます。
この問題を解決するには、テーブルを分割します。学生テーブルとコーステーブルを作成し、それらをリンクする結合テーブルを設けます。これにより、学生の詳細が受講するすべてのコースごとに繰り返されることを防ぎます。
3️⃣ 第三正規形(3NF)
第三正規形は推移的依存関係を取り扱います。テーブルが2NFにあり、かつ非キー属性が他の非キー属性に依存していない場合、そのテーブルは3NFにあります。
より簡単に言えば、属性は主キーの一部でない他の属性に依存してはいけません。これは、ある列が行自体ではなく、別の列を説明している場合によく起こります。
- 推移的依存関係: AがBを決定し、BがCを決定するならば、AはCを決定する。Bがキーでない場合、Cは重複して保存される。
- 例: 従業員テーブルにおいて、「部門名」と「部門マネージャー」を保存している場合、マネージャーは部門名に依存します。部門名が変更された場合、適切に管理しなければマネージャー列が整合性を失う可能性があります。
これを修正するには、部門情報を別々の部門テーブルに移動します。従業員テーブルはその後、部門IDのみを保持します。これにより部門データが分離され、部門名が変更された場合、1か所で更新すれば済みます。
4️⃣ ボイス・コッド正規形(BCNF)
BCNFは3NFよりも厳格なバージョンです。複数の候補キーがある場合や、非キー属性が特定の方法で他の非キー属性を決定する場合に適用されます。すべての関数的依存関係X → Yについて、Xがスーパーキーである場合、テーブルはBCNFにあります。
この形態は、3NFでも依然として異常が許される複雑な状況に対処します。すべての決定要因が候補キーであることを保証します。すべてのスキーマに必ずしも必要とは限りませんが、BCNFを目指すことで、ゼロ冗長性のための最高レベルの構造的整合性が得られます。
🛠️ 異常の対処:比較的視点
正規化の影響を理解するには、異常がどのように現れるかを明確に把握することが必要です。以下の表は、一般的なデータ問題に関して、正規化された状態と非正規化された状態の違いを示しています。
| 異常の種類 | 非正規化状態 | 正規化状態(ゼロ冗長性) |
|---|---|---|
| 更新 | 複数の行のデータを変更する必要があります。整合性のリスクが高くなります。 | 1行のデータを変更するだけで済みます。整合性が自動的に保たれます。 |
| 挿入 | 外部キー制約を満たすためにダミーデータが必要になる場合があります。 | 関係のないデータを含まずに、新しいエンティティを独立して追加できます。 |
| 削除 | レコードを削除すると、別のエンティティに関する重要なデータが削除される可能性があります。 | レコードを削除しても、特定のエンティティにのみ影響し、他のエンティティは保持されます。 |
| ストレージ | 繰り返しの文字列や値による高いストレージ使用量。 | 最小限のストレージ使用量。値はID経由で参照される。 |
示した通り、正規化アプローチはデータ管理の運用負荷を著しく低減する。コストとして、情報の完全な取得には結合が必要なため、クエリの複雑さが多少増す。しかし、そのトレードオフは整合性と長期的な保守性を優先するものである。
🛠️ 実装のための戦略
ERD設計段階でこれらの戦略を実装することは非常に重要である。データが入力された後に冗長性を修正するよりも、事前に防止する方がはるかに容易である。ここではデザイナー向けの実行可能なステップを提示する。
1. 機能的依存関係を早期に特定する
エンティティ間の線を引く前に、属性をリストアップし、何が何を決定するかを確認する。属性Aが属性Bを決定することを把握している場合、Aがキーでない限り、それらは同じエンティティに配置すべきであるとわかる。
- すべての関係を明確に図示する。
- 尋ねる:「この属性は全体のキーに依存しているか?」
- 尋ねる:「この属性は他の非キー属性に依存しているか?」
2. ライフサイクルに基づいてエンティティを分離する
更新頻度が異なるエンティティはしばしば分離すべきである。静的参照テーブル(国リストなど)がトランザクションテーブル(注文など)と混在すると、静的データがトランザクションテーブルに不要な冗長性を生じる。
3. サロゲートキーを使用する
自然データを主キーとして使用する代わりに、システムによって生成される一意の識別子(サロゲートキー)を使用することを検討する。これにより、キー自体が時間とともに変化する問題を防ぎ、正規化システム内の関係性が破綻するのを回避できる。
4. テストデータで検証する
ERDを最終化する前に、サンプルデータで埋め込んでみる。以前に説明した異常を再現できるか試みる。注文がなくても顧客を正常に挿入でき、注文を削除しても顧客が失われない場合、設計はおそらく適切である。
⚖️ パフォーマンスと純粋性のバランス
ゼロ冗長性を達成することは、テーブル数を最大化することではない。過度な正規化はパフォーマンスの低下を引き起こす可能性がある。クエリが10の異なるテーブルからのデータを必要とする場合、システムは10回の結合を実行しなければならない。これは読み取り操作を著しく遅くする可能性がある。
デノーマライズするタイミング
意図的に冗長性を再導入する正当な理由がある。これはしばしばデノーマライズと呼ばれる。
- 読み込みが重いシステム:データウェアハウスやレポートツールでは、書き込みの整合性よりも読み取り速度が優先される。事前に計算された列を使用することで、結合の複雑さを軽減できる。
- 歴史的スナップショット:注文時における顧客の住所を知りたい場合、Customerテーブルの現在の住所に頼ることはできない。注文テーブルに住所を保存する必要がある。
- パフォーマンスチューニング:結合によってクエリが常に遅い場合、トリガーまたはアプリケーションロジックで更新される冗長な列を追加する必要があるかもしれない。
重要なのは意図性である。冗長性をデフォルトとして受け入れてはならない。メンテナンスコストを上回る測定可能なパフォーマンス上の利点がある場合にのみ、それを許容すべきである。
🔄 スキーマのレビューと維持
正規化は一度きりの作業ではない。ビジネス要件は変化し、データは増大する。5年前に正規化されたスキーマが、今日では調整が必要になる可能性がある。
定期的な監査
ERDの定期的なレビューをスケジュールする。繰り返しデータのパターンを確認する。同じテキスト文字列が複数のテーブルに現れる場合、その理由を調査する。これは設計上の欠陥の兆候であるか、文書化が必要な意図的なデノーマライズの選択である可能性がある。
データモデルのバージョン管理
ERDをコードとして扱いましょう。変更を追跡するためにバージョン管理システムを使用してください。変更によって重複が生じたり関係性が破損したりした場合、元に戻すことができます。すべての主要な構造的変更の理由を文書化することが重要です。
チームの教育
データ入力やアプリケーション開発に関与するすべての人が正規化のルールを理解していることを確認してください。開発者がスキーマを無視して直接データを挿入すると、アプリケーションロジックによって再び重複が生じる可能性があります。スキーマがこのような構造になっている理由を明確に文書化することが不可欠です。
📝 最良の実践方法の要約
データ品質とストレージ効率の高い水準を維持するため、設計プロセス中に以下のチェックリストに従ってください。
- 原子性: 各カラムが単一の値を保持していることを確認する(1NF)。
- 完全依存: 非キー属性が主キー全体に依存していることを確認する(2NF)。
- 推移的依存なし: 非キー属性が他の非キー属性に依存しないことを確認する(3NF)。
- 一貫したキー: すべての決定要因が候補キーであることを確認する(BCNF)。
- 意思決定の記録: 特定の重複が導入された理由を記録する。
- 成長の監視: データベースがスケーリングするにつれて、繰り返しデータのパターンを監視する。
これらの原則に従うことで、変化に強いシステムを構築できます。データはクリーンな状態を保ち、論理は健全なままです。ゼロ重複はディスク容量を節約するだけの話ではなく、データの真実性を守る基盤を構築することにあります。
🚀 構造的整合性についての最終的な考察
ゼロ重複ストレージへの道は、データアーキテクチャの持続可能性への投資です。設計段階での厳格な規律が求められますが、その報酬はエラーの削減、保守コストの低下、情報システムに対する信頼の向上として得られます。
エンティティ関係図を見たとき、単なるボックスと線の集まりではなく、真実の地図として捉えてください。すべての線は必然的な関係を表し、すべてのボックスは明確な事実を表しています。適切に正規化することで、ビジネスの環境が変化してもこの地図が正確なまま保たれることを確実にできます。
ストレージだけではなく、論理に注目してください。構造がデータを支えるものにし、逆はしないようにしましょう。正規化戦略を明確に理解することで、時間とデータ量の両方の試練に耐えるシステムを構築できるようになります。