











Создание надежной структуры данных — основа любой надежной информационной системы. В центре этого проектирования находится диаграмма сущность-связь (ERD), визуальный чертеж, определяющий, как взаимодействуют данные сущности. Однако сама диаграмма не гарантирует эффективность. Подлинная сила ERD проявляется при сочетании с строгими стратегиями нормализации. Цель ясна: достичь хранения без избыточности. Это означает устранение дублирующих данных для обеспечения целостности, снижения затрат на хранение и упрощения обслуживания.
Избыточность — это не просто проблема хранения; это логическая ошибка, способная вызвать несогласованность. Когда данные повторяются в нескольких строках или таблицах без строгой связи, аномалии обновления неизбежны. Изменение одного атрибута может потребовать обновления десятков записей. Если одна из них будет пропущена, база данных станет поврежденной. Этот гид исследует механизмы нормализации в контексте проектирования ERD, делая акцент на практическом применении и структурной чистоте.
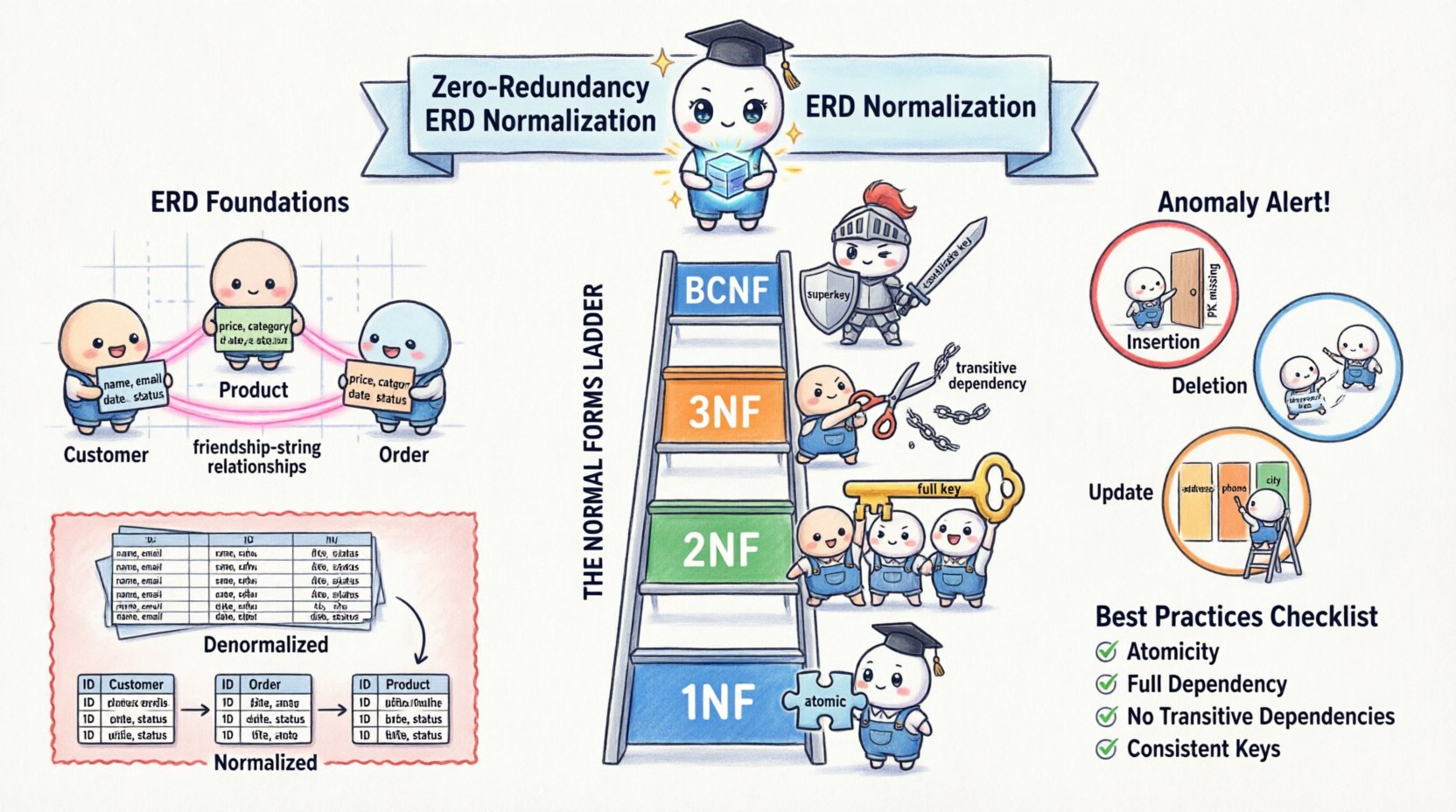
🧱 Понимание основ моделирования данных
Прежде чем применять правила нормализации, необходимо понимать компоненты диаграммы сущность-связь. ERD состоит из сущностей, атрибутов и связей. Сущности представляют объекты или понятия, такие как Клиент или Продукт. Атрибуты — это свойства, описывающие эти сущности, например, Имя или Цена. Связи определяют, как сущности связаны между собой, часто с помощью внешних ключей.
Нормализация — это процесс организации этих атрибутов с целью минимизации избыточности и зависимости. Она включает разделение больших таблиц на более мелкие, логически связанные, и определение связей между ними. Цель — изолировать данные так, чтобы каждый факт хранился только в одном месте.
Рассмотрим разницу между денормализованным и нормализованным подходом. В денормализованном виде одна таблица может содержать всю информацию об заказе, включая адрес и номер телефона клиента каждый раз при оформлении заказа. Если клиент переезжает, необходимо обновить каждую запись заказа. В нормализованном виде адрес клиента хранится в отдельной таблице Клиенты. Таблица Заказы содержит лишь ссылку на идентификатор клиента. Эта изоляция и есть суть хранения без избыточности.
📉 Риски не нормализованных данных
Почему хранение без избыточности так критично? Ответ кроется в типах аномалий, возникающих при игнорировании нормализации. Эти аномалии угрожают надежности всей системы.
- Аномалии вставки:Вы не можете добавить данные для одной сущности, не добавив данные для другой. Например, если новый сотрудник еще не назначен на проект, вы можете не иметь возможности зафиксировать его существование, если таблица требует идентификатор проекта.
- Аномалии удаления:Удаление данных для одной сущности может случайно привести к потере данных другой. Если вы удалите последний заказ клиента, вы можете полностью потерять контактную информацию этого клиента.
- Аномалии обновления:Это наиболее распространенная проблема. Если адрес клиента хранится в нескольких записях заказов, обновление адреса требует поиска и изменения каждой записи. При неудаче возникают противоречивые данные.
Достижение хранения без избыточности напрямую снижает эти риски. Обеспечивая, что каждая часть информации хранится только в одном месте, система становится самокорректирующейся. Обновления происходят один раз, и изменение логически распространяется через связи.
🪜 Путь к нормальным формам
Нормализация — это не один шаг, а последовательное движение через отдельные этапы, называемые нормальными формами. Каждая форма решает определенные типы избыточности. Хотя теоретические модели охватывают пятую нормальную форму (5NF), на практике проектирование баз данных обычно фокусируется на первых трех формах и форме Бойса-Кодда (BCNF).
1️⃣ Первая нормальная форма (1NF)
Первое правило нормализации — обеспечить атомарность. Таблица находится в 1NF, если она не содержит повторяющихся групп или массивов. Каждый столбец должен содержать одно значение, а каждая строка должна быть уникальной.
- Атомарные значения:Поле не может содержать список значений. Вместо столбца с названием «Навыки», содержащего «Java, SQL, Python», следует создать отдельные строки для каждого навыка или отдельную таблицу для навыков.
- Уникальные строки:Каждая строка должна быть отличима от каждой другой строки. Обычно это требует наличия первичного ключа.
В контексте ERD это означает проверку каждого атрибута. Если атрибут описывает многозначное свойство, он должен быть извлечен. Это фундаментальный шаг. Без 1NF более высокие формы не могут быть эффективно применены.
2️⃣ Вторая нормальная форма (2NF)
Как только таблица находится в 1NF, она должна соответствовать критериям 2NF. Таблица находится во 2NF, если она находится в 1NF и все не ключевые атрибуты полностью зависят от всего первичного ключа.
Это правило в первую очередь касается таблиц с составными ключами (ключами, состоящими из нескольких столбцов). Если таблица имеет составной ключ, каждый атрибут должен зависеть от всего ключа, а не только от его части.
- Полная зависимость:Если столбец зависит только от одной части составного ключа, он должен находиться в отдельной таблице.
- Частичная зависимость: Это конкретная избыточность, которую устраняет 2НФ. Например, в таблице, связывающей студентов с курсами, если хранится «Имя студента», оно зависит только от идентификатора студента, а не от идентификатора курса. Это приводит к избыточности.
Устранение этого требует разделения таблицы. Вы создаете таблицу «Студент» и таблицу «Курс», соединяя их таблицей-связью. Это гарантирует, что данные о студенте не будут повторяться для каждого курса, который он проходит.
3️⃣ Третья нормальная форма (3НФ)
Третья нормальная форма имеет дело с транзитивными зависимостями. Таблица находится в 3НФ, если она находится в 2НФ и ни один неключевой атрибут не зависит от другого неключевого атрибута.
Проще говоря, атрибуты не должны зависеть от других атрибутов, которые не являются частью первичного ключа. Это часто происходит, когда столбец описывает другой столбец, а не саму строку.
- Транзитивная зависимость: Если A определяет B, а B определяет C, то A определяет C. Если B не является ключом, то C хранится избыточно.
- Пример: В таблице «Сотрудник» если хранятся «Название отдела» и «Руководитель отдела», то руководитель зависит от названия отдела. Если название отдела изменится, столбец «Руководитель» может стать несогласованным, если не управлять этим внимательно.
Чтобы исправить это, перенесите информацию об отделе в отдельную таблицу «Отдел». Таблица «Сотрудник» будет хранить только идентификатор отдела. Это изолирует данные об отделе, гарантируя, что при переименовании отдела вы обновите его в одном месте.
4️⃣ Форма Бойса-Кодда (ФБК)
ФБК — более строгая версия 3НФ. Она применяется, когда существует несколько кандидатских ключей или когда неключевой атрибут определяет другой неключевой атрибут определённым образом. Таблица находится в ФБК, если для каждого функционального зависимости X → Y, X является суперключом.
Эта форма решает сложные сценарии, при которых 3НФ всё ещё может допускать аномалии. Она гарантирует, что каждый определяющий элемент является кандидатским ключом. Хотя не всегда необходимо для каждой схемы, стремление к ФБК обеспечивает наивысший уровень структурной целостности при отсутствии избыточности.
🛠️ Обработка аномалий: сравнительный обзор
Понимание влияния нормализации требует чёткого представления о том, как проявляются аномалии. В таблице ниже описаны различия между нормализованным и денормализованным состоянием в отношении распространённых проблем с данными.
| Тип аномалии | Состояние денормализации | Нормализованное состояние (без избыточности) |
|---|---|---|
| Обновление | Требует изменения данных в нескольких строках. Высокий риск несогласованности. | Требует изменения данных в одной строке. Согласованность обеспечивается автоматически. |
| Вставка | Может потребовать ввод временных данных для удовлетворения ограничений внешнего ключа. | Новые сущности можно добавлять независимо, не вводя нерелевантные данные. |
| Удаление | Удаление записи может привести к потере важных данных о другой сущности. | Удаление записи влияет только на конкретную сущность, сохраняя остальные. |
| Хранение | Высокое использование памяти из-за повторяющихся строк и значений. | Минимальное использование хранилища; значения ссылаются через идентификаторы. |
Как показано, нормализованный подход значительно снижает эксплуатационные издержки управления данными. Стоимость — незначительно более сложный запрос, поскольку для получения полной информации требуются соединения. Однако компромисс в пользу целостности и долгосрочной поддерживаемости.
🛠️ Стратегии реализации
Реализация этих стратегий на этапе проектирования ERD критически важна. Гораздо проще предотвратить избыточность, чем исправлять её после заполнения данных. Вот практические шаги для проектировщиков.
1. Выявляйте функциональные зависимости на ранних этапах
Прежде чем проводить линии между сущностями, перечислите атрибуты и определите, что определяет что. Если вы знаете, что атрибут A определяет атрибут B, вы понимаете, что они, скорее всего, должны находиться в одной и той же сущности, если A не является ключом.
- Создайте схему всех связей.
- Спросите: «Зависит ли этот атрибут от всего ключа?»
- Спросите: «Зависит ли этот атрибут от другого атрибута, не являющегося ключом?»
2. Разделяйте сущности по жизненному циклу
Сущности с разной частотой обновления часто следует разделять. Если статическая таблица справочников (например, список стран) смешана с транзакционной таблицей (например, заказы), статические данные создают избыточность в транзакционной таблице.
3. Используйте заменяющие ключи
Вместо использования естественных данных в качестве первичного ключа рассмотрите возможность использования заменяющего ключа (уникальный идентификатор, генерируемый системой). Это предотвращает проблемы, когда сам ключ со временем изменяется, что нарушит связи в нормализованной системе.
4. Проверяйте с помощью тестовых данных
Перед окончательным утверждением ERD попробуйте заполнить его образцовыми данными. Попробуйте создать аномалии, описанные ранее. Если вы можете успешно вставить клиента без заказа и удалить заказ, не потеряв клиента, ваша схема, вероятно, корректна.
⚖️ Баланс производительности и чистоты
Достижение нулевой избыточности не означает максимизацию количества таблиц. Избыточная нормализация может привести к снижению производительности. Когда запрос требует данных из десяти разных таблиц, система должна выполнить десять соединений. Это может значительно замедлить операции чтения.
Когда следует денормализовать
Существуют обоснованные причины для преднамеренного возвращения избыточности. Это часто называют денормализацией.
- Системы с высокой нагрузкой на чтение: В хранилищах данных или инструментах отчетности скорость чтения имеет приоритет перед согласованностью записи. Предварительно вычисленные столбцы могут снизить сложность соединений.
- Исторические снимки: Если вам нужно знать, какой адрес у клиента был на момент заказа, вы не можете полагаться на текущий адрес в таблице Клиенты. Вам необходимо хранить адрес в таблице Заказы.
- Настройка производительности: Если запросы постоянно медленные из-за соединений, может потребоваться добавление избыточного столбца, который обновляется через триггеры или логику приложения.
Ключевым является осознанность. Не принимайте избыточность как стандарт. Принимайте её только тогда, когда измеримый выигрыш в производительности превышает стоимость поддержки.
🔄 Проверка и поддержка вашей схемы
Нормализация — это не разовое задание. Требования бизнеса меняются, данные растут. Схема, нормализованная пять лет назад, сегодня может потребовать корректировки.
Регулярные аудиты
Планируйте периодические проверки вашей ERD. Ищите шаблоны повторяющихся данных. Если вы обнаружите, что один и тот же текстовый фрагмент появляется в нескольких таблицах, выясните причину. Это может быть признаком ошибки проектирования или сознательного решения о денормализации, которое требует документирования.
Контроль версий для моделей данных
Воспринимайте ваш диаграмму отношений сущностей как код. Используйте системы контроля версий для отслеживания изменений. Это позволяет откатиться, если изменение приведет к избыточности или нарушит связи. Документируйте обоснование каждого крупного структурного изменения.
Обучение команды
Убедитесь, что каждый, кто участвует в вводе данных или разработке приложений, понимает правила нормализации. Если разработчики обходят схему и вставляют данные напрямую, они могут снова ввести избыточность через логику приложения. Четкая документация о том, почему схема устроена именно так, является обязательной.
📝 Обзор лучших практик
Чтобы поддерживать высокий уровень качества данных и эффективности хранения, придерживайтесь следующего чек-листа на этапе проектирования.
- Атомарность: Убедитесь, что каждый столбец содержит одно значение (1НФ).
- Полная зависимость: Убедитесь, что не ключевые атрибуты зависят от всего первичного ключа (2НФ).
- Отсутствие транзитивных зависимостей: Убедитесь, что не ключевые атрибуты не зависят от других не ключевых атрибутов (3НФ).
- Согласованные ключи: Убедитесь, что каждый определяющий элемент является кандидатским ключом (НФ Бойса-Кодда).
- Документирование решений: Записывайте, почему были введены конкретные избыточности.
- Контроль роста: Следите за паттернами повторяющихся данных по мере масштабирования базы данных.
Следуя этим принципам, вы создаете систему, устойчивую к изменениям. Данные остаются чистыми, а логика — надежной. Нулевая избыточность — это не просто экономия места на диске; это построение основы, где сохраняется истинность данных.
🚀 Заключительные мысли о структурной целостности
Путь к хранению без избыточности — это вложение в долговечность вашей архитектуры данных. Хотя это требует дисциплины на этапе проектирования, плоды проявляются в меньшем количестве ошибок, снижении затрат на обслуживание и повышении доверия к информационной системе.
Когда вы смотрите на диаграмму отношений сущностей, воспринимайте её не просто как набор прямоугольников и линий, а как карту истины. Каждая линия представляет необходимую связь. Каждый прямоугольник — отдельный факт. Эффективная нормализация гарантирует, что эта карта остаётся точной, даже когда меняется ландшафт вашего бизнеса.
Сосредоточьтесь на логике, а не только на хранении. Пусть структура служит данным, а не наоборот. Обладая чётким пониманием стратегий нормализации, вы сможете создавать системы, способные выдержать испытание временем и объёмом данных.