











Concevoir une structure de données robuste est le pilier de tout système d’information fiable. Au cœur de cette conception se trouve le diagramme entité-association (DEA), un plan visuel qui définit la manière dont les entités de données interagissent. Toutefois, un diagramme seul ne garantit pas l’efficacité. La véritable puissance d’un DEA apparaît lorsqu’il est associé à des stratégies rigoureuses de normalisation. L’objectif est clair : atteindre un stockage sans redondance. Cela signifie éliminer les données redondantes afin de garantir l’intégrité, réduire les coûts de stockage et simplifier la maintenance.
La redondance n’est pas simplement un problème de stockage ; c’est une faille logique en attente de provoquer des incohérences. Lorsque les données sont répétées à travers plusieurs lignes ou tables sans relation stricte, les anomalies de mise à jour deviennent inévitables. Un changement dans un seul attribut peut nécessiter des mises à jour dans des dizaines d’endroits. Si l’une est oubliée, la base de données devient corrompue. Ce guide explore les mécanismes de la normalisation dans le contexte de la conception de DEA, en mettant l’accent sur l’application pratique et la pureté structurelle.
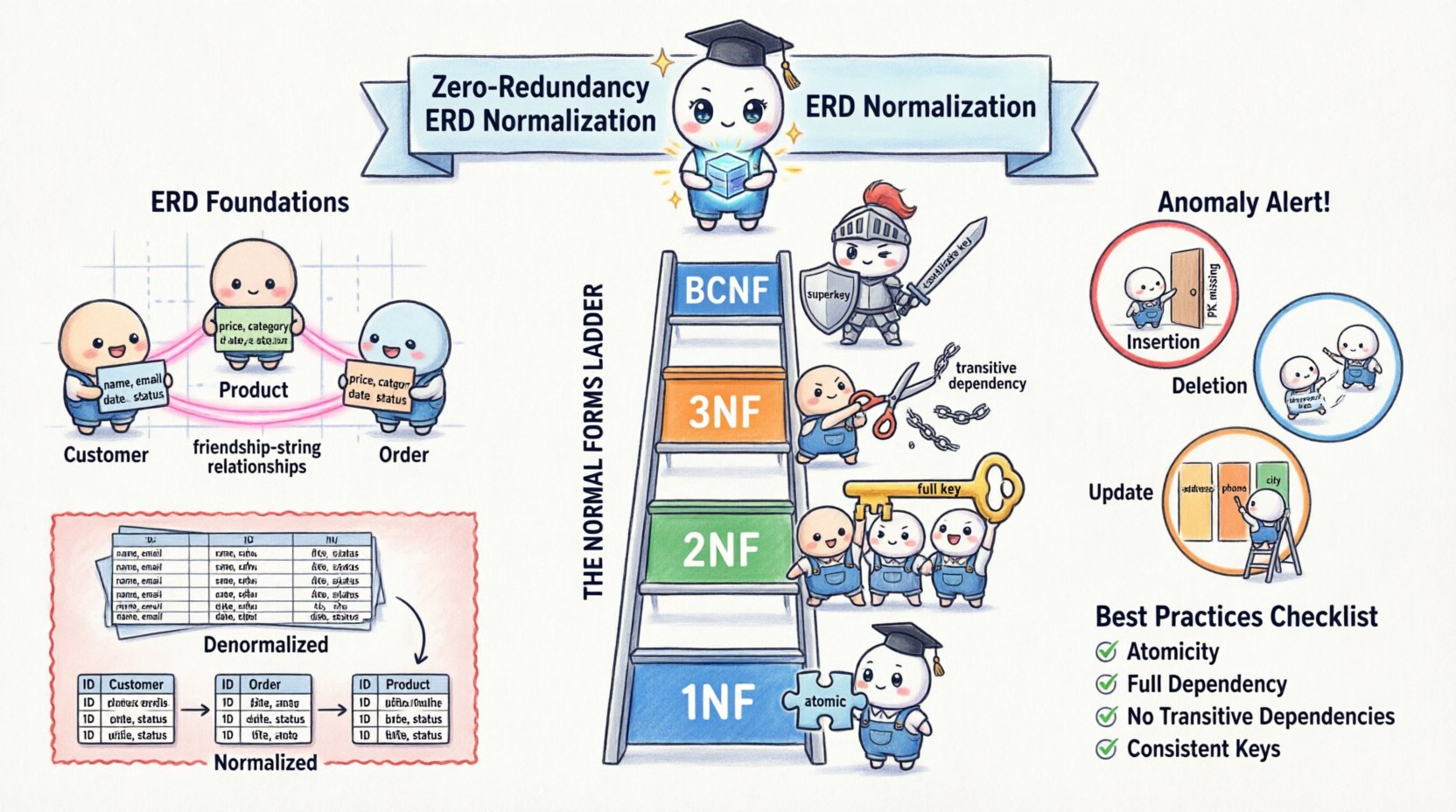
🧱 Comprendre les fondements de la modélisation des données
Avant d’appliquer les règles de normalisation, il faut comprendre les composants du diagramme entité-association. Un DEA se compose d’entités, d’attributs et de relations. Les entités représentent des objets ou des concepts, tels qu’un Client ou un Produit. Les attributs sont les propriétés qui décrivent ces entités, comme un Nom ou un Prix. Les relations définissent la manière dont les entités sont connectées, souvent à travers des clés étrangères.
La normalisation est le processus d’organisation de ces attributs afin de minimiser la redondance et les dépendances. Elle consiste à diviser les grandes tables en tables plus petites, logiquement connectées, et à définir des relations entre elles. L’objectif est d’isoler les données de sorte que chaque fait soit stocké à un seul endroit.
Pensez à la différence entre une approche dénormalisée et une approche normalisée. Dans une vue dénormalisée, une seule table pourrait contenir toutes les informations sur une commande, y compris l’adresse et le numéro de téléphone du client à chaque fois qu’une commande est passée. Si le client déménage, vous devez mettre à jour chaque enregistrement de commande. Dans une vue normalisée, l’adresse du client se trouve dans une table distincte appelée Client. La table Commande ne contient qu’une référence à l’ID du client. Cette séparation est l’essence de la non-redondance.
📉 Les risques des données non normalisées
Pourquoi la non-redondance est-elle si critique ? La réponse réside dans les types d’anomalies qui surviennent lorsque la normalisation est ignorée. Ces anomalies menacent la fiabilité de l’ensemble du système.
- Anomalies d’insertion :Vous ne pouvez pas ajouter des données pour une entité sans ajouter des données pour une autre. Par exemple, si un nouvel employé n’a pas encore été affecté à un projet, vous pourriez ne pas pouvoir enregistrer son existence si la table exige un ID de projet.
- Anomalies de suppression :La suppression des données d’une entité pourrait involontairement supprimer des données d’une autre. Si vous supprimez la dernière commande d’un client, vous pourriez perdre entièrement les informations de contact de ce client.
- Anomalies de mise à jour :C’est le problème le plus courant. Si l’adresse d’un client est stockée dans plusieurs enregistrements de commande, la mise à jour de l’adresse exige de trouver et de modifier chaque enregistrement individuellement. En cas d’échec, cela entraîne des données conflictuelles.
Atteindre la non-redondance élimine directement ces risques. En garantissant que chaque morceau d’information a une seule source, le système devient auto-correctif. Les mises à jour ont lieu une seule fois, et le changement se propage logiquement à travers les relations.
🪜 Le chemin vers les formes normales
La normalisation n’est pas une étape unique, mais une progression à travers des étapes distinctes appelées Formes Normales. Chaque forme traite des types spécifiques de redondance. Bien que les modèles théoriques s’étendent jusqu’à la Cinquième Forme Normale (5FN), la conception pratique des bases de données se concentre généralement sur les trois premières formes et la Forme Normale de Boyce-Codd (FNBC).
1️⃣ Première Forme Normale (1FN)
La première règle de la normalisation est d’assurer l’atomicité. Une table est en 1FN si elle ne contient pas de groupes répétés ou de tableaux. Chaque colonne doit contenir une seule valeur, et chaque ligne doit être unique.
- Valeurs atomiques :Un champ ne peut pas contenir une liste de valeurs. Au lieu d’une colonne nommée « Compétences » contenant « Java, SQL, Python », vous devriez créer des lignes distinctes pour chaque compétence ou une table distincte pour les compétences.
- Lignes uniques :Chaque ligne doit être distincte de toutes les autres lignes. Cela nécessite généralement une clé primaire.
Dans le contexte d’un DEA, cela signifie vérifier chaque attribut. Si un attribut décrit une propriété multivaluée, il doit être extrait. C’est l’étape fondamentale. Sans 1FN, les formes supérieures ne peuvent pas être appliquées efficacement.
2️⃣ Deuxième Forme Normale (2FN)
Une fois qu’une table est en 1FN, elle doit satisfaire les critères de la 2FN. Une table est en 2FN si elle est en 1FN et que tous les attributs non clés dépendent entièrement de la clé primaire complète.
Cette règle traite principalement les tables possédant des clés composées (clés constituées de plusieurs colonnes). Si une table possède une clé composée, chaque attribut doit dépendre de toute la clé, et non seulement d’une partie d’elle.
- Dépendance complète :Si une colonne dépend uniquement d’une partie d’une clé composée, elle doit être placée dans une table distincte.
- Dépendance partielle : Il s’agit de la redondance spécifique que la 2NF élimine. Par exemple, dans une table liant les Étudiants aux Cours, si le « Nom de l’étudiant » est stocké, il dépend uniquement de l’ID étudiant, et non de l’ID du cours. Cela crée une redondance.
Résoudre cela consiste à diviser la table. Vous créez une table Étudiant et une table Cours, avec une table d’association les reliant. Cela garantit que les détails des étudiants ne sont pas répétés pour chaque cours qu’ils suivent.
3️⃣ Troisième forme normale (3FN)
La troisième forme normale traite des dépendances transitives. Une table est en 3FN si elle est en 2FN et qu’aucun attribut non clé ne dépend d’un autre attribut non clé.
En termes simples, les attributs ne doivent pas dépendre d’autres attributs qui ne font pas partie de la clé primaire. Cela se produit souvent lorsque une colonne décrit une autre colonne plutôt que la ligne elle-même.
- Dépendance transitive : Si A détermine B, et que B détermine C, alors A détermine C. Si B n’est pas une clé, C est stocké de manière redondante.
- Exemple : Dans une table Employé, si vous stockez le « Nom du département » et le « Gérant du département », le gérant dépend du nom du département. Si le nom du département change, la colonne du gérant pourrait devenir incohérente si elle n’est pas gérée avec soin.
Pour corriger cela, déplacez les informations du département vers une table Département distincte. La table Employé ne contient alors qu’un ID de département. Cela isole les données du département, garantissant que si un département est renommé, vous le mettez à jour à un seul endroit.
4️⃣ Forme normale de Boyce-Codd (BCNF)
La BCNF est une version plus stricte de la 3FN. Elle s’applique lorsque plusieurs clés candidates existent, ou lorsque un attribut non clé détermine un autre attribut non clé d’une manière spécifique. Une table est en BCNF si, pour toute dépendance fonctionnelle X → Y, X est une superclé.
Cette forme traite des scénarios complexes où la 3FN pourrait encore permettre des anomalies. Elle garantit que chaque déterminant est une clé candidate. Bien qu’elle ne soit pas toujours nécessaire pour chaque schéma, viser la BCNF assure le plus haut niveau d’intégrité structurelle pour une redondance nulle.
🛠️ Gestion des anomalies : une vue comparative
Comprendre l’impact de la normalisation nécessite une vue claire de la manière dont les anomalies se manifestent. Le tableau ci-dessous décrit les différences entre les états normalisés et dénormalisés concernant les problèmes courants de données.
| Type d’anomalie | État dénormalisé | État normalisé (sans redondance) |
|---|---|---|
| Mise à jour | Exige de modifier les données dans plusieurs lignes. Risque élevé d’incohérence. | Exige de modifier les données dans une seule ligne. La cohérence est automatique. |
| Insertion | Peut nécessiter des données fictives pour satisfaire les contraintes de clé étrangère. | De nouvelles entités peuvent être ajoutées indépendamment, sans données non pertinentes. |
| Suppression | La suppression d’un enregistrement peut supprimer des données essentielles concernant une autre entité. | La suppression d’un enregistrement n’affecte que l’entité spécifique, préservant les autres. |
| Stockage | Utilisation élevée du stockage en raison de chaînes et de valeurs répétées. | Utilisation minimale du stockage ; les valeurs sont référencées via des identifiants. |
Comme indiqué, l’approche normalisée réduit considérablement la charge opérationnelle de la gestion des données. Le coût est un interrogatoire légèrement plus complexe, car des jointures sont nécessaires pour récupérer des informations complètes. Toutefois, cet équilibre favorise l’intégrité et la maintenabilité à long terme.
🛠️ Stratégies de mise en œuvre
Mettre en œuvre ces stratégies pendant la phase de conception du MCD est crucial. Il est bien plus facile d’éviter la redondance que de la corriger après que les données ont été chargées. Voici des étapes concrètes pour les concepteurs.
1. Identifier les dépendances fonctionnelles tôt
Avant de tracer des lignes entre les entités, listez les attributs et déterminez ce qui détermine quoi. Si vous savez qu’un attribut A détermine un attribut B, vous savez qu’ils devraient probablement résider dans la même entité, sauf si A n’est pas une clé.
- Établissez toutes les relations.
- Demandez : « Cet attribut dépend-il de la clé entière ? »
- Demandez : « Cet attribut dépend-il d’un autre attribut non clé ? »
2. Séparer les entités selon leur cycle de vie
Les entités ayant des fréquences de mise à jour différentes doivent souvent être séparées. Si une table de référence statique (comme une liste de pays) est mélangée à une table transactionnelle (comme les commandes), les données statiques créent une redondance inutile dans la table transactionnelle.
3. Utiliser des clés surrogates
Au lieu d’utiliser des données naturelles comme clé primaire, envisagez d’utiliser une clé surrogate (un identifiant unique généré par le système). Cela évite les problèmes où la clé elle-même change au fil du temps, ce qui romprait les relations dans un système normalisé.
4. Valider avec des données de test
Avant de finaliser le MCD, essayez de le peupler avec des données d’exemple. Essayez de créer les anomalies décrites précédemment. Si vous pouvez insérer un client sans commande, et supprimer une commande sans perdre le client, votre conception est probablement solide.
⚖️ Équilibrer performance et pureté
Obtenir une redondance nulle ne signifie pas maximiser le nombre de tables. Une normalisation excessive peut entraîner une dégradation des performances. Lorsqu’une requête nécessite des données provenant de dix tables différentes, le système doit effectuer dix jointures. Cela peut ralentir considérablement les opérations de lecture.
Quand dénormaliser
Il existe des raisons valables pour réintroduire intentionnellement la redondance. Cela est souvent appelé dénormalisation.
- Systèmes fortement en lecture : Dans les entrepôts de données ou les outils de reporting, la vitesse de lecture est prioritaire par rapport à la cohérence des écritures. Des colonnes prédéfinies peuvent réduire la complexité des jointures.
- Instantanés historiques : Si vous devez connaître l’adresse d’un client au moment d’une commande, vous ne pouvez pas vous fier à l’adresse actuelle dans la table Client. Vous devez stocker l’adresse dans la table Commande.
- Ajustement des performances : Si les requêtes sont constamment lentes en raison des jointures, il peut être nécessaire d’ajouter une colonne redondante mise à jour via des déclencheurs ou une logique d’application.
L’essentiel est l’intentionnalité. N’acceptez pas la redondance comme norme. Acceptez-la uniquement lorsque le gain de performance mesuré dépasse le coût de maintenance.
🔄 Révision et maintenance de votre schéma
La normalisation n’est pas une tâche ponctuelle. Les besoins métier évoluent, et les données augmentent. Un schéma normalisé il y a cinq ans pourrait nécessiter des ajustements aujourd’hui.
Audits réguliers
Programmez des revues périodiques de votre MCD. Recherchez des motifs de données répétées. Si vous trouvez la même chaîne de texte apparaissant dans plusieurs tables, investiguez pourquoi. Cela pourrait être un signe d’un défaut de conception ou d’un choix de dénormalisation délibéré qui nécessite une documentation.
Contrôle de version pour les modèles de données
Traitez votre MCD comme du code. Utilisez des systèmes de contrôle de version pour suivre les modifications. Cela vous permet de revenir en arrière si une modification introduit une redondance ou rompt des relations. Documentez les raisons de chaque modification structurelle majeure.
Formation de l’équipe
Assurez-vous que toutes les personnes impliquées dans la saisie de données ou le développement d’applications comprennent les règles de normalisation. Si les développeurs contournent le schéma pour insérer directement des données, ils peuvent réintroduire des redondances via la logique de l’application. Une documentation claire sur la raison pour laquelle le schéma est structuré de cette manière est essentielle.
📝 Résumé des meilleures pratiques
Pour maintenir un haut niveau de qualité des données et d’efficacité du stockage, respectez la liste suivante pendant votre processus de conception.
- Atomicité : Assurez-vous qu’une colonne contient une seule valeur (1NF).
- Dépendance complète : Assurez-vous que les attributs non clés dépendent de la clé primaire entière (2NF).
- Pas de dépendances transitives : Assurez-vous que les attributs non clés ne dépendent pas d’autres attributs non clés (3NF).
- Clés cohérentes : Assurez-vous que chaque déterminant est une clé candidate (BCNF).
- Documenter les décisions : Enregistrez pourquoi des redondances spécifiques ont été introduites.
- Surveiller la croissance : Surveillez les motifs de données répétées à mesure que la base de données grandit.
En suivant ces principes, vous créez un système résilient aux changements. Les données restent propres et la logique reste solide. La zéro-redondance ne concerne pas seulement l’économie d’espace disque ; elle consiste à bâtir une fondation où la vérité des données est préservée.
🚀 Réflexions finales sur l’intégrité structurelle
Le parcours vers un stockage sans redondance est un investissement dans la longévité de votre architecture de données. Bien qu’il exige une discipline pendant la phase de conception, les bénéfices se traduisent par des erreurs réduites, des coûts de maintenance plus faibles et une confiance accrue dans le système d’information.
Quand vous regardez un diagramme entité-association, ne le voyez pas seulement comme une collection de boîtes et de lignes, mais comme une carte de la vérité. Chaque ligne représente une relation nécessaire. Chaque boîte représente un fait distinct. En normalisant efficacement, vous assurez que cette carte reste précise, même au fur et à mesure que le terrain de votre entreprise évolue.
Concentrez-vous sur la logique, et non seulement sur le stockage. Laissez la structure servir les données, et non l’inverse. Avec une compréhension claire des stratégies de normalisation, vous êtes en mesure de construire des systèmes capables de résister à l’épreuve du temps et du volume de données.