











データエンジニアやシステムアーキテクトの足元で、データベースアーキテクチャの地盤が変化しつつある。数十年にわたり、エンティティ関係図(ERD)はデータ構造の設計図として機能し、複雑なシステム内での情報の流れ、接続、永続性を定義してきた。従来、これらの図を描くには細心の注意を要する手作業、深い専門知識、そして退屈な反復作業に耐える覚悟が求められた。今日、人工知能がモデリングワークフローに統合され、新たなパラダイムが登場している。この進化は単にスピードの向上にとどまらない。論理データモデルの構想、検証、維持の根本的な方法を変えるものである。
人工知能は単なる自動化の域を越え、設計プロセスにおける積極的な参加者へと進化している。自然言語処理やパターン認識を活用することで、これらの高度なシステムはビジネス要件を解釈し、構造的なスキーマに驚くほどの正確さで変換する。本ガイドは、この移行のメカニズム、開発チームに与える具体的な利点、そしてデータ整合性を損なうことなくこれらの技術を採用するための戦略的配慮について探求する。
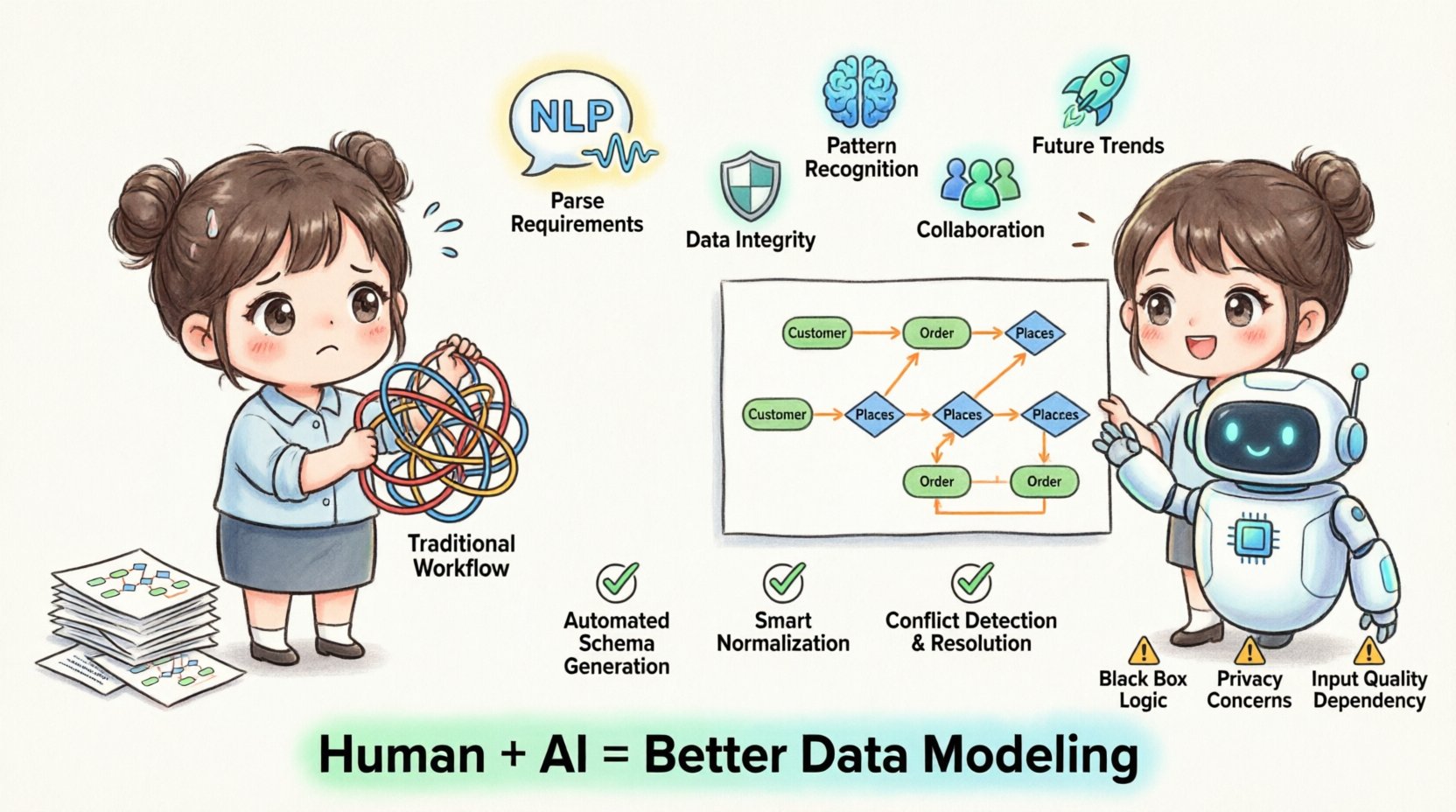
📐 伝統的なERDワークフローとその限界
未来を検討する前に、基準を理解することが不可欠である。エンティティ関係図の作成は、歴史的に線形的で人的負荷の大きいプロセスであった。アーキテクトたちは要件を収集し、エンティティを特定し、関係を定義し、データ構造を正規化していた。効果的ではあるが、このアプローチには本質的なリスクと非効率性が内在しており、システムが拡大するにつれてその問題が顕著になる。
- 高い認知負荷:複雑なスキーマを設計するには、膨大な関係論理を記憶に保持する必要がある。これにより見落としの可能性が高まる。
- バージョン管理の断片化:図ファイルはしばしば独立したアーティファクトとなり、実際のソースコードやデータベース定義から切り離される。
- 手動の正規化エラー:第三正規形(3NF)またはボイス・コッド正規形(BCNF)を確保するには、冗長性や異常の防止に常に注意を払う必要がある。
- 協働のボトルネック:複数のステークホルダーが同じ図を確認する必要があり、フィードバックループが発生し、開発が停滞する。
- 静的ドキュメント:一度描かれると、下位のアプリケーションロジックが進化するにつれて、ERDは頻繁に陳腐化する。
これらの課題は、意図された設計と実装された現実との間にギャップを生じさせる。ビジネス要件が急速に変化する場合、これは特に顕著になり、現代のアジャイル環境ではよくある状況である。
🧠 AI駆動型モデリングのメカニズム
AI駆動型ERDツールは、箱の間に線を引くだけではない。膨大なデータベースパターン、業界標準、アーキテクチャのベストプラクティスのリポジトリで訓練された機械学習モデルの基盤の上に動作する。これらのツールの裏側のメカニズムを理解することで、その信頼性を評価する助けになる。
1. 自然言語処理(NLP)による解釈
現代のシステムは、製品要件書やユーザーストーリーなどの非構造化テキストを読み込み、主要なエンティティや属性を抽出できる。AIはキーワードだけでなく、意味を解析する。たとえば、文書に「顧客注文」とある場合、システムは「顧客」と「注文」をおそらくエンティティとして識別し、言語的文脈に基づいて関係を推論する。
2. パターン認識と生成設計
エンティティが特定されると、AIは学習したパターンを適用して関係を提案する。語の意味的重みに基づいて、1対多や多対多といった一般的な基数を認識する。この生成機能により、人間による精査の出発点となるドラフトスキーマを迅速に作成できる。
3. コンテキスト理解
高度なモデルは、文書全体またはプロジェクト全体にわたってコンテキストを維持する。あるセクションで特定の属性が一意の識別子として定義されている場合、システムは別のセクションで外部キーを生成する際にその制約を記憶している。大規模プロジェクトでは、これを手動で維持するのは困難である。
⚙️ データモデリングを変革する主な機能
AIの統合により、従来のモデリングの課題を解決する特定の機能的特徴がもたらされる。これらの機能は人間の知性を補完することを目的としており、代替することを目的としていない。
- 自動スキーマ生成:テキスト仕様を直接、データベーススキーマ定義(DDL)と視覚的な図を同時に生成する。
- 知的最適化:システムは、提案されたクエリパターンに基づいて、インデックス戦略の最適化を提案する。
- 衝突検出:AIは、データベースにコミットされる前に、名前衝突や循環依存関係の可能性を検出できます。
- スマート正規化:アルゴリズムは構造を分析し、冗長性を低減しつつクエリパフォーマンスを損なわない正規化ステップを推奨します。
- レガシーマイグレーション分析:既存システムとの統合時に、AIは古いスキーマを新しい構造にマッピングし、破壊的変更を特定できます。
📊 伝統的ワークフローとAI支援ワークフローの比較
変化を可視化するために、伝統的な環境とAI統合環境におけるタスクの処理方法の以下の比較を検討してください。
| タスク | 伝統的ワークフロー | AI支援ワークフロー |
|---|---|---|
| 要件分析 | テキストからのエンティティの手動抽出 | 信頼度スコア付きのNLP抽出 |
| 関係マッピング | アーキテクトが線を引き、基数を定義する | システムが意味に基づいて関係を提案する |
| 正規化 | 3NFルールに基づいて手動でレビューする | アルゴリズムによる検証と最適化 |
| ドキュメントの更新 | 変更後、図を再描画しなければならない | スキーマ変更とリアルタイム同期 |
| エラー検出 | テストやコードレビュー中に発見される | 設計段階での予防的警告 |
この比較から、主な価値は実行から検証への努力のシフトにあることがわかります。AIが反復的な構築を担当することで、人間の専門家はアーキテクチャ戦略やビジネスロジックの整合性に集中できます。
🛡️ データ整合性と一貫性の強化
データ整合性は信頼性の高いソフトウェアの基盤です。不整合なデータは誤った分析、取引の失敗、セキュリティ上の脆弱性を引き起こします。AIツールは一貫性がありルールベースの強制層を導入します。
参照整合性チェック
ERD設計における最も一般的な誤りの一つは、誤った外部キー制約によって孤立したレコードが生成されることです。AIシステムは、すべての外部キーが参照先エンティティに対応する主キーが定義されていることを自動で検証します。また、適切な場合には複合キーの提案も行い、関係性が堅牢であることを保証します。
属性の型付けと制約
適切なデータ型を選択することは、パフォーマンスとストレージにとって重要です。AIモデルは要件に記述されたデータの性質を分析します。フィールドが「生年月日」と記述されている場合、システムはそれを単純な文字列としてモデル化するのではなく、適切な検証ルールを備えた時系列型として扱います。
標準化された命名規則
一貫性のない命名規則は混乱を招きます。「user_id」、「UserId」、「UserID」はすべて同じ概念を指す可能性があり、結合を複雑にします。AIツールはグローバルな命名戦略を強制し、生成されたすべてのエンティティがプロジェクトのコーディング規準に自動的に準拠することを保証します。
🤝 チーム協働への影響
ERDツールの進化は、チーム間の協働方法にも変化をもたらします。図が動的で共有された要件から生成される場合、ビジネスアナリスト、開発者、データアーキテクトの間の壁が低くなります。
- 単一の真実のソース: 図が元の要件にリンクされている場合、ステークホルダーはモデルを元のテキストと照合して検証できます。
- リアルタイム協働: クラウドベースのモデリングプラットフォームは、複数のユーザーが作業を上書きすることなく、同時に視覚化し、変更を提案できるようにします。
- 曖昧さの低減: AIが生成する視覚的出力は、文章による記述の曖昧さを低減します。図は通常、段落の文章よりも明確です。
- 迅速なオンボーディング: 新しいチームメンバーは、AIが生成したマップや関係性のフローを確認することで、システムアーキテクチャをより迅速に理解できます。
⚠️ 制限事項と倫理的配慮
進歩 notwithstanding、AI駆動のツールは万能ではありません。人間の監視なしに自動化システムに完全に依存することは、特定のリスクを招き、これらを管理する必要があります。
1. ブラックボックス問題
AIモデルはしばしば透明性が低いです。システムが特定の関係性を提案した場合、アーキテクトはそれを理解する必要があります。なぜ。説明可能性がなければ、重要なシステムにおけるモデルの意思決定を信頼するのは困難です。
2. 文脈的なニュアンス
AIは一般的なデータパターンに見られない、非常に特定のビジネスルールに対処しづらい場合があります。たとえば、訓練データに含まれていない場合、独自の規制準拠ルールが見過ごされる可能性があります。
3. データプライバシーとセキュリティ
クラウドベースのAIモデリングツールを使用する際、処理されるメタデータにはシステム構造に関する機密情報が含まれます。データガバナンスポリシーが尊重されていることを確認し、独自の論理が外部モデルに暴露されないようすることが不可欠です。
4. 入力品質への依存
AIモデルの出力は、入力の品質に依存します。要件文書が曖昧または矛盾している場合、生成されたERDもその欠陥を反映します。人間による検証は依然として必須のステップです。
🔮 インテリジェントデータモデリングの将来のトレンド
将来を見据えると、ERD作成におけるAIの進化は、開発ライフサイクルとのより深い統合を指向しています。以下のトレンドが、次世代のツールを規定する可能性があります。
- 予測型スキーマ進化: ツールは使用パターンを分析して、将来のスケーリング要件を予測し、パーティショニングまたはシャーディング戦略を事前に提案する。
- 自己修復型データベース: 統合システムはスキーマのずれを検出し、自動的にロールバックまたはマイグレーションスクリプトを提案する。
- クエリ対応モデリング: AIは、アプリケーションが実行する特定のクエリに基づいてERDを最適化し、単にビジネス要件に基づくものではない。
- マルチモデル対応: NoSQLやグラフデータベースがより一般的になる中で、AIはリレーショナル、ドキュメント、グラフ構造を同時にサポートするハイブリッドモデルの設計を支援する。
- DevOpsとの統合: ERDの変更はCI/CDパイプラインをトリガーし、データベースのマイグレーションがアプリケーションコードと併せてテストおよびデプロイされることを保証する。
📋 採用のためのベストプラクティス
これらの技術を導入しようとする組織は、成功を確保するために構造的なアプローチを取るべきである。統合は段階的に行い、既存のプロセスを補完することに焦点を当てるべきであり、それらを破壊することではない。
パイロットプロジェクトから始める
企業全体のアーキテクチャを一度に移行してはならない。AIモデリングツールの機能をテストするため、非重要なプロジェクトを選定する。時間の節約と出力の品質を測定する。
人間の関与を維持する
すべてのスキーマ変更に対して人間の承認を義務付けるガバナンスポリシーを確立する。AIはドラフトを提供し、アーキテクトが判断を下す。
データガバナンスに注力する
AIツールが組織のデータガバナンスフレームワークと整合していることを確認する。命名規則、セキュリティ分類、保持ポリシーはツール内で設定されるべきである。
チームの研修を行う
AIとのやり取り方法についての研修を提供する。チームメンバーは、システムに効果的にプロンプトを送信する方法、およびAIが提示する提案をどう解釈すべきかを理解する必要がある。
ずれの監視
生成された図を実際にデプロイされたデータベースと定期的に照合して監査する。これにより、AIが時間の経過とともにシステムの現実と整合した状態を保つことが保証される。
🎯 モダン開発における戦略的価値
AI駆動のERD作成への移行は、組織にとって戦略的優位性をもたらす。反復的なモデリング作業に費やす時間を削減することで、チームはイノベーションに注力できる。データ構造を迅速にプロトタイピングできる能力は、より速い実験と反復を可能にする。
さらに、これらのツールによって導入される一貫性は、技術的負債を削減する。AIが標準に準拠して生成したスキーマは、保守・拡張が容易である。この持続性は、多くのデジタルビジネスにとってデータが主要な資産となる時代において極めて重要である。
技術が成熟するにつれて、「デザイナー」と「ビルド担当者」の違いが曖昧になる可能性がある。概念的モデリングと物理的実装の境界はますます曖昧になる。この統合は、よりアジャイルで反応性の高いソフトウェア開発ライフサイクルを約束する。
🌐 結論
AIを介したエンティティ関係図(ERD)の進化は、データエンジニアリング分野における重要な発展である。この分野は手作業による図面作成から、知的な設計へと移行している。信頼性、文脈、ガバナンスに関する課題は依然として存在するが、効率性、正確性、スケーラビリティにおける潜在的な利点は非常に大きい。
アーキテクトや開発者にとっての今後の道は、これらのツールを強力なアシスタントとして受け入れることにある。人間の専門知識と機械の知能を組み合わせることで、時代の試練に耐える強固なデータアーキテクチャを構築できる。データモデリングの未来は、人間の思考を置き換えることではなく、現代のデータ環境の複雑さを理解するツールで人間を強化することにある。