











डेटाबेस आर्किटेक्चर का मैदान डेटा इंजीनियरों और सिस्टम आर्किटेक्ट्स के पैरों के नीचे बदल रहा है। दशकों तक, एंटिटी रिलेशनशिप डायग्राम (ERD) डेटा संरचनाओं के लिए नींव के रूप में काम करता रहा है, जो जटिल प्रणालियों के भीतर जानकारी के प्रवाह, जुड़ाव और अस्तित्व को परिभाषित करता है। पारंपरिक रूप से, इन डायग्रामों को बनाने में ध्यान से हाथ से काम करने की आवश्यकता होती थी, गहन क्षेत्र ज्ञान की आवश्यकता होती थी, और थकाऊ चक्रों को सहने की तैयारी रहती थी। आज, मॉडलिंग के कार्यप्रणाली में कृत्रिम बुद्धिमत्ता के एकीकरण से एक नया ढांचा आ रहा है। यह विकास केवल गति के बारे में नहीं है; यह तर्कसंगत डेटा मॉडलों के विचार, मान्यता और रखरखाव के तरीके को मूल रूप से बदलने के बारे में है।
कृत्रिम बुद्धिमत्ता सरल स्वचालन से आगे बढ़कर डिजाइन प्रक्रिया में सक्रिय भागीदार बन रही है। प्राकृतिक भाषा प्रसंस्करण और पैटर्न पहचान का उपयोग करके, ये उन्नत प्रणालियाँ व्यापार आवश्यकताओं को समझती हैं और उन्हें अद्भुत सटीकता के साथ संरचनात्मक स्कीमा में बदल देती हैं। यह मार्गदर्शिका इस संक्रमण के तकनीकी तत्वों, विकास टीमों के लिए भावी लाभों और डेटा अखंडता को नुकसान न पहुंचाते हुए इन तकनीकों को अपनाने के लिए आवश्यक रणनीतिक विचारों का अध्ययन करती है।
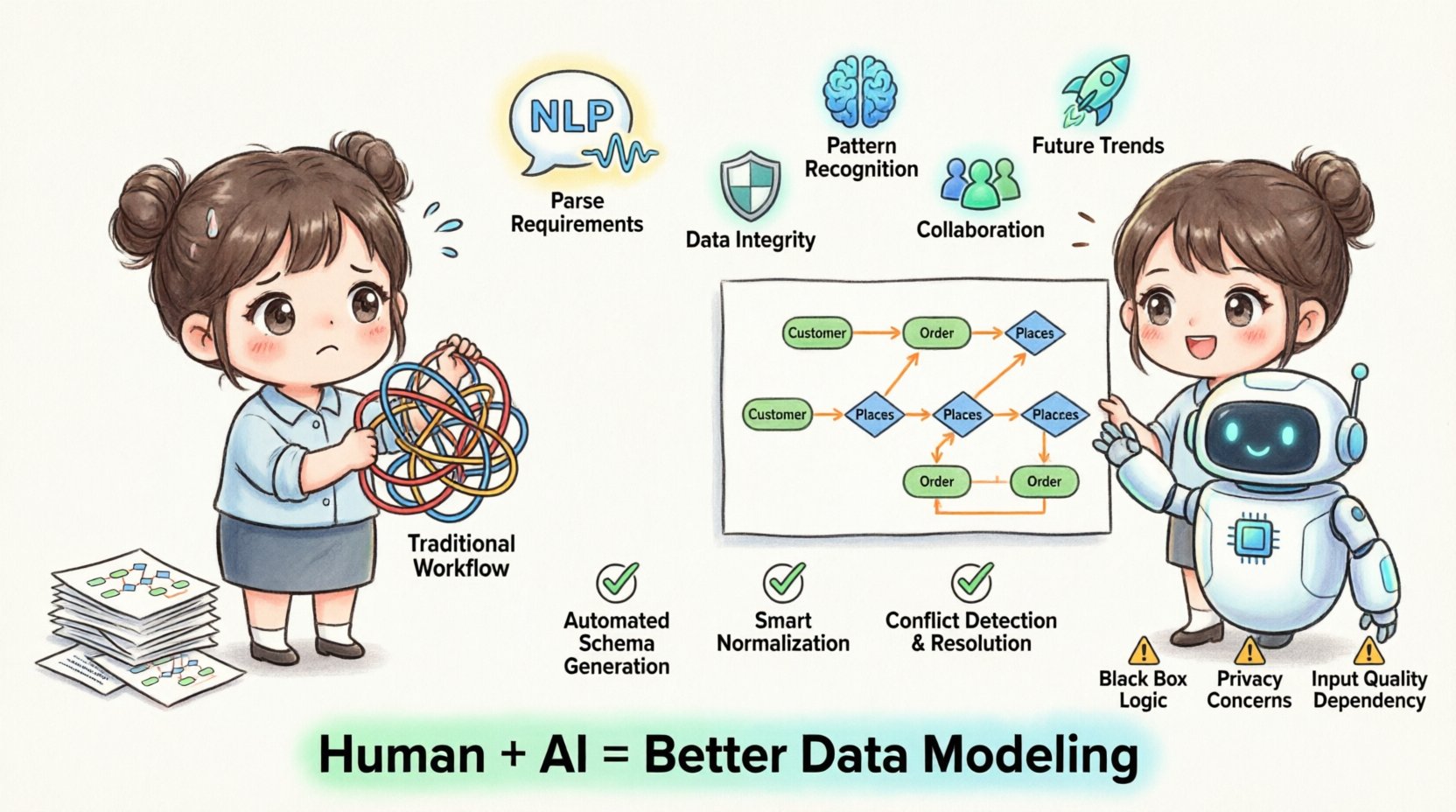
📐 पारंपरिक ERD कार्यप्रणाली और इसकी सीमाएं
भविष्य का अध्ययन करने से पहले, आधारभूत स्तर को समझना आवश्यक है। एंटिटी रिलेशनशिप डायग्राम के निर्माण का इतिहास में एक रेखीय, श्रम-भारी प्रक्रिया रही है। आर्किटेक्ट्स आवश्यकताओं को एकत्र करते थे, एंटिटी को पहचानते थे, संबंधों को परिभाषित करते थे, और डेटा संरचना को सामान्यीकृत करते थे। हालांकि यह तरीका प्रभावी रहा है, लेकिन इस प्रक्रिया में आंतरिक जोखिम और अक्षमताएं हैं जो प्रणालियों के पैमाने में बढ़ने पर और अधिक स्पष्ट हो जाती हैं।
- उच्च संज्ञानात्मक भार:जटिल स्कीमा डिजाइन करने के लिए स्मृति में विशाल मात्रा में संबंधात्मक तर्क को धारण करने की आवश्यकता होती है। इससे अनदेखी की संभावना बढ़ जाती है।
- संस्करण नियंत्रण का विघटन:डायग्राम फाइलें अक्सर अलग-अलग वस्तुएं बन जाती हैं, जो वास्तविक स्रोत कोड या डेटाबेस परिभाषाओं से अलग हो जाती हैं।
- हाथ से सामान्यीकरण त्रुटियां:तृतीय सामान्य रूप (3NF) या बॉयस-कॉड सामान्य रूप (BCNF) सुनिश्चित करने के लिए अतिरिक्तता और असामान्यताओं के खिलाफ निरंतर चौकसी की आवश्यकता होती है।
- सहयोग के बाधाएं:बहुत से हितधारकों को अक्सर एक ही डायग्राम की समीक्षा करने की आवश्यकता होती है, जिससे विकास को रोकने वाले फीडबैक लूप बनते हैं।
- स्थिर दस्तावेजीकरण:एक बार बनाने के बाद, ERD अक्सर तब अप्रासंगिक हो जाते हैं जब आधारभूत एप्लिकेशन तर्क विकसित होता है।
इन चुनौतियों के कारण इच्छित डिजाइन और कार्यान्वित वास्तविकता के बीच एक अंतर बन जाता है। जब व्यापार आवश्यकताएं तेजी से बदलती हैं, तो यह अंतर और बढ़ जाता है, जो आधुनिक एजाइल परिदृश्यों में एक सामान्य परिदृश्य है।
🧠 कृत्रिम बुद्धिमत्ता संचालित मॉडलिंग के तरीके
कृत्रिम बुद्धिमत्ता संचालित ERD उपकरण सिर्फ बॉक्सों के बीच रेखाएं खींचते हैं। वे विशाल डेटाबेस पैटर्न, उद्योग मानकों और आर्किटेक्चरल बेस्ट प्रैक्टिस के भंडार पर प्रशिक्षित मशीन लर्निंग मॉडलों पर आधारित काम करते हैं। इन उपकरणों की विश्वसनीयता का आकलन करने के लिए इनके आधारभूत तरीकों को समझना महत्वपूर्ण है।
1. प्राकृतिक भाषा प्रसंस्करण (NLP) व्याख्या
आधुनिक प्रणालियाँ असंरचित पाठ, जैसे उत्पाद आवश्यकता दस्तावेज या उपयोगकर्ता कहानियां, को स्वीकार कर सकती हैं और मुख्य एंटिटी और गुणों को निकाल सकती हैं। AI शब्दावली के बजाय अर्थ को समझती है। उदाहरण के लिए, यदि कोई दस्तावेज “ग्राहक आदेश” का उल्लेख करता है, तो प्रणाली “ग्राहक” और “आदेश” को संभावित एंटिटी के रूप में पहचानती है और भाषाई संदर्भ पर आधारित संबंध का अनुमान लगाती है।
2. पैटर्न पहचान और जनरेटिव डिजाइन
एंटिटी की पहचान करने के बाद, AI सीखे गए पैटर्न का उपयोग करके संबंधों के सुझाव देती है। यह शब्दों के अर्थपूर्ण भार पर आधारित आम कार्डिनैलिटी, जैसे एक से बहुत या बहुत से बहुत, को पहचानती है। इस जनरेटिव क्षमता के कारण एक ड्राफ्ट स्कीमा का त्वरित निर्माण संभव होता है, जो मानव द्वारा सुधार के लिए आधार बनता है।
3. संदर्भ समझ
उन्नत मॉडल पूरे दस्तावेज या प्रोजेक्ट में संदर्भ बनाए रखते हैं। यदि किसी विशेष लक्षण को एक खंड में अद्वितीय पहचानकर्ता के रूप में परिभाषित किया गया है, तो प्रणाली दूसरे खंड में विदेशी कुंजियों के निर्माण के समय इस सीमा को याद रखती है। बड़े पैमाने पर प्रोजेक्ट में इस संगतता को हाथ से बनाए रखना मुश्किल होता है।
⚙️ डेटा मॉडलिंग को बदल रही मुख्य क्षमताएं
कृत्रिम बुद्धिमत्ता के एकीकरण से विशिष्ट कार्यात्मक क्षमताएं आती हैं जो पारंपरिक मॉडलिंग की समस्याओं को हल करती हैं। इन विशेषताओं को मानव बुद्धिमत्ता को बढ़ाने के लिए बनाया गया है, न कि उसके स्थान पर लेने के लिए।
- स्वचालित स्कीमा निर्माण:पाठात्मक विवरणों को सीधे डेटाबेस स्कीमा परिभाषाओं (DDL) और दृश्य डायग्रामों में बदल दें, एक साथ।
- बुद्धिमान सुधार:प्रस्तावित प्रश्न पैटर्न के आधार पर प्रणाली इंडेक्सिंग रणनीतियों के लिए अनुकूलन सुझाती है।
- संघर्ष निर्देशन:AI संभावित नामकरण संघर्षों या चक्रीय निर्भरताओं को डेटाबेस में समर्पित करने से पहले चेतावनी दे सकता है।
- स्मार्ट सामान्यीकरण:एल्गोरिदम संरचना का विश्लेषण करते हैं ताकि अतिरिक्त बाधाओं को कम किए बिना प्रश्न प्रदर्शन में कमी न हो, उसके लिए सामान्यीकरण चरणों की सिफारिश करें।
- पुराने प्रणाली स्थानांतरण विश्लेषण: मौजूदा प्रणालियों के साथ एकीकरण करते समय, AI पुराने स्कीमा को नए संरचनाओं में मैप कर सकता है, तोड़ने वाले परिवर्तनों को पहचान सकता है।
📊 पारंपरिक बनाम AI-सहायता वाले कार्य प्रवाह की तुलना
परिवर्तन को देखने के लिए, एक पारंपरिक वातावरण बनाम AI-एकीकृत वातावरण में कार्यों के हाथापाई के निम्नलिखित तुलना पर विचार करें।
| कार्य | पारंपरिक कार्य प्रवाह | AI-सहायता वाला कार्य प्रवाह |
|---|---|---|
| आवश्यकता विश्लेषण | पाठ से एंटिटीज का हस्ताक्षरित निकास | विश्वास अंकन के साथ NLP निकास |
| संबंध मैपिंग | संरचनाकार रेखाएं खींचता है और कार्डिनैलिटी को परिभाषित करता है | प्रणाली अर्थशास्त्र पर आधारित संबंधों की सिफारिश करती है |
| सामान्यीकरण | 3NF नियमों के खिलाफ हस्ताक्षरित समीक्षा | एल्गोरिदमिक प्रमाणीकरण और अनुकूलन |
| दस्तावेज़ अद्यतन | परिवर्तन के बाद आरेख को फिर से खींचना होगा | स्कीमा परिवर्तनों के साथ लाइव सिंक |
| त्रुटि पता लगाना | परीक्षण या कोड समीक्षा के दौरान पाया गया | डिज़ाइन चरण के दौरान सक्रिय चेतावनियां |
इस तुलना से यह स्पष्ट होता है कि मुख्य मूल्य कार्यान्वयन से मान्यता तक बल बदलने में है। AI दोहराए जाने वाले निर्माण का ध्यान रखता है, जिससे मानव विशेषज्ञ संरचनात्मक रणनीति और व्यापार तर्क के अनुरूपता पर ध्यान केंद्रित कर सकता है।
🛡️ डेटा अखंडता और सुसंगतता में सुधार
डेटा अखंडता विश्वसनीय सॉफ्टवेयर की नींव है। असंगत डेटा दोषपूर्ण विश्लेषण, असफल लेनदेन और सुरक्षा कमजोरियों को जन्म देता है। AI उपकरण एक निरंतर और नियम-आधारित अनुपालन की परत लाते हैं।
संदर्भात्मक अखंडता जांच
ERD डिज़ाइन में सबसे आम त्रुटियों में से एक गलत विदेशी कुंजी प्रतिबंधों के कारण अनाथ रिकॉर्ड का निर्माण है। AI प्रणालियाँ स्वचालित रूप से जांचती हैं कि प्रत्येक विदेशी कुंजी के लिए संदर्भित एकता में संगत प्राथमिक कुंजी परिभाषित है या नहीं। वे उचित स्थितियों में संयुक्त कुंजियों की सिफारिश भी कर सकती हैं, जिससे संबंध सुदृढ़ बने रहें।
लक्षण प्रकारीकरण और सीमाएँ
सही डेटा प्रकार का चयन प्रदर्शन और भंडारण के लिए महत्वपूर्ण है। AI मॉडल आवश्यकताओं में वर्णित डेटा की प्रकृति का विश्लेषण करते हैं। यदि किसी फ़ील्ड का वर्णन “जन्म की तारीख” के रूप में किया गया है, तो प्रणाली सुनिश्चित करती है कि इसे साधारण स्ट्रिंग के रूप में मॉडल नहीं किया जाता है, बल्कि उपयुक्त सत्यापन नियमों के साथ समयानुक्रमिक प्रकार के रूप में मॉडल किया जाता है।
मानकीकृत नामकरण प्रथाएँ
असंगत नामकरण प्रथाएँ भ्रम पैदा करती हैं। “user_id”, “UserId” और “UserID” सभी एक ही अवधारणा को संदर्भित कर सकते हैं, जिससे जॉइन करना कठिन हो जाता है। AI उपकरण एक वैश्विक नामकरण रणनीति को लागू करते हैं, जिससे सुनिश्चित होता है कि सभी उत्पादित एकताएँ स्वचालित रूप से प्रोजेक्ट के कोडिंग मानकों का पालन करती हैं।
🤝 टीम सहयोग पर प्रभाव
ERD उपकरणों के विकास ने टीमों के सहयोग के तरीके को भी बदल दिया है। जब आरेख गतिशील होते हैं और साझा आवश्यकताओं से उत्पन्न होते हैं, तो व्यवसाय विश्लेषकों, डेवलपर्स और डेटा वार्डों के बीच बाधा कम हो जाती है।
- एकमात्र सत्य का स्रोत: जब आरेख स्रोत आवश्यकताओं से जुड़ा होता है, तो हितधारक मॉडल की मूल पाठ के विरुद्ध पुष्टि कर सकते हैं।
- वास्तविक समय सहयोग: क्लाउड-आधारित मॉडलिंग प्लेटफॉर्म बहुत से उपयोगकर्ताओं को एक साथ देखने और परिवर्तन सुझाने की अनुमति देते हैं बिना एक दूसरे के कार्य को ओवरराइट किए।
- अस्पष्टता कम होना: AI द्वारा उत्पन्न दृश्य निर्देशों में अस्पष्टता को कम करते हैं। एक आरेख अक्सर एक पैराग्राफ टेक्स्ट से स्पष्ट होता है।
- त्वरित ओनबोर्डिंग: नए टीम सदस्य AI द्वारा उत्पन्न नक्शों और संबंध प्रवाह की समीक्षा करके सिस्टम आर्किटेक्चर को तेजी से समझ सकते हैं।
⚠️ सीमाएँ और नैतिक विचार
उन्नति के बावजूद, AI-आधारित उपकरण एक सोने की गोली नहीं हैं। मानव निगरानी के बिना स्वचालित प्रणालियों पर निर्भर रहने से विशिष्ट जोखिम आते हैं जिन्हें प्रबंधित करने की आवश्यकता होती है।
1. काला डिब्बा समस्या
AI मॉडल अक्सर पारदर्शी नहीं होते हैं। यदि प्रणाली किसी विशिष्ट संबंध की सिफारिश करती है, तो वार्ड को समझने की आवश्यकता होती हैक्यों। व्याख्यात्मकता के बिना, महत्वपूर्ण प्रणालियों में मॉडल के निर्णयों पर भरोसा करना कठिन होता है।
2. संदर्भिक बातचीत
AI को उच्च विशिष्ट व्यावसायिक नियमों के साथ कठिनाई हो सकती है जो सामान्य डेटा पैटर्न में आम नहीं होते हैं। उदाहरण के लिए, यदि कोई विशिष्ट नियामक सुसंगतता नियम प्रशिक्षण डेटा में नहीं दिखता है, तो उसे छोड़ दिया जा सकता है।
3. डेटा गोपनीयता और सुरक्षा
जब क्लाउड-आधारित AI मॉडलिंग उपकरणों का उपयोग करते हैं, तो प्रक्रिया के दौरान डेटा में प्रणाली के संरचना के संबंध में संवेदनशील जानकारी शामिल होती है। यह आवश्यक है कि सुनिश्चित किया जाए कि डेटा शासन नीतियों का सम्मान किया जाए और स्वामित्व वाली तर्क बाहरी मॉडलों के सामने न खुले।
4. इनपुट गुणवत्ता पर निर्भरता
AI मॉडल का आउटपुट केवल इनपुट के बराबर अच्छा होता है। यदि आवश्यकता दस्तावेज धुंधला या विरोधाभासी है, तो उत्पादित ERD उन दोषों को दर्शाएगा। मानव जांच एक आवश्यक चरण बनी रहती है।
🔮 स्मार्ट डेटा मॉडलिंग में भविष्य के प्रवृत्तियाँ
आगे बढ़ते हुए, ERD निर्माण में AI का मार्ग विकास चक्र के साथ गहरी एकीकरण की ओर इशारा करता है। निम्नलिखित प्रवृत्तियाँ अगली पीढ़ी के उपकरणों को परिभाषित करने की संभावना है।
- पूर्वानुमानित स्कीमा विकास: उपकरण उपयोग के पैटर्न का विश्लेषण करेंगे ताकि भविष्य की स्केलिंग आवश्यकताओं का अनुमान लगाया जा सके और सक्रिय रूप से पार्टीशनिंग या शार्डिंग रणनीतियों की सिफारिश की जा सके।
- सेल्फ-हीलिंग डेटाबेस: एकीकृत प्रणालियाँ स्कीमा ड्रिफ्ट का पता लगाएंगी और स्वचालित रूप से रोलबैक या माइग्रेशन स्क्रिप्ट्स की सिफारिश करेंगी।
- प्रश्न-संवेदनशील मॉडलिंग: एआई एप्लिकेशन द्वारा चलाए जाने वाले विशिष्ट प्रश्नों के आधार पर ईआरडी को अनुकूलित करेगा, केवल व्यापार आवश्यकताओं के बजाय।
- मल्टी-मॉडल समर्थन: जैसे-जैसे नो-एसक्यूएल और ग्राफ डेटाबेस अधिक सामान्य होते हैं, एआई हाइब्रिड मॉडल डिज़ाइन में सहायता करेगी जो संबंधित, दस्तावेज़ और ग्राफ संरचनाओं को एक साथ समर्थन करती हैं।
- डेवोप्स के साथ एकीकरण: ईआरडी में परिवर्तन सीआई/सीडी पाइपलाइन को ट्रिगर करेंगे, जिससे यह सुनिश्चित होगा कि डेटाबेस माइग्रेशन को एप्लिकेशन कोड के साथ ही परीक्षण और डेप्लॉय किया जाए।
📋 अपनाने के लिए सर्वोत्तम प्रथाएं
इन तकनीकों को अपनाने वाली संगठनों को सफलता सुनिश्चित करने के लिए एक संरचित दृष्टिकोण अपनाना चाहिए। एकीकरण धीरे-धीरे होना चाहिए, जिसमें मौजूदा प्रक्रियाओं को बढ़ावा देने पर ध्यान केंद्रित करना चाहिए, उन्हें बाधित करने के बजाय।
पायलट परियोजनाओं से शुरुआत करें
पूरी एंटरप्राइज आर्किटेक्चर को एक ही बार में माइग्रेट न करें। एआई मॉडलिंग टूल्स की क्षमता का परीक्षण करने के लिए एक गैर-महत्वपूर्ण परियोजना चुनें। समय बचाने और आउटपुट की गुणवत्ता को मापें।
मानव-के-लूप में बने रहें
एक गवर्नेंस पॉलिसी स्थापित करें जिसमें सभी स्कीमा परिवर्तनों पर मानव सहमति आवश्यक हो। एआई ड्राफ्ट प्रदान करता है; वास्तुकार निर्णय लेता है।
डेटा गवर्नेंस पर ध्यान केंद्रित करें
यह सुनिश्चित करें कि एआई टूल संगठन के डेटा गवर्नेंस फ्रेमवर्क के अनुरूप हो। नामकरण प्रणाली, सुरक्षा वर्गीकरण और रखरखाव नीतियों को टूल के भीतर कॉन्फ़िगर किया जाना चाहिए।
टीम को प्रशिक्षित करें
एआई के साथ बातचीत करने के तरीके पर प्रशिक्षण प्रदान करें। टीम सदस्यों को समझना चाहिए कि प्रणाली को कैसे प्रभावी ढंग से प्रॉम्प्ट किया जाए और यह कैसे सुझाव देती है।
ड्रिफ्ट के लिए निगरानी करें
नियमित रूप से उत्पन्न आरेखों की वास्तविक डेप्लॉय किए गए डेटाबेस के खिलाफ समीक्षा करें। इससे यह सुनिश्चित होता है कि एआई समय के साथ प्रणाली के वास्तविकता के साथ समान रहती है।
🎯 आधुनिक विकास के लिए रणनीतिक मूल्य
एआई-चालित ईआरडी निर्माण की ओर बढ़ना संगठनों के लिए एक रणनीतिक लाभ का प्रतिनिधित्व करता है। बोरिंग मॉडलिंग कार्यों पर बिताए गए समय को कम करके, टीमें नवाचार पर ध्यान केंद्रित कर सकती हैं। डेटा संरचनाओं के त्वरित प्रोटोटाइपिंग की क्षमता त्वरित प्रयोग और आवर्धन की अनुमति देती है।
इसके अलावा, इन उपकरणों द्वारा पेश की गई सुसंगतता तकनीकी देनदारी को कम करती है। मानकों का पालन करते हुए एआई द्वारा उत्पन्न स्कीमा बनाए रखने और विस्तार करने में आसान होते हैं। यह दीर्घायु एक ऐसे युग में महत्वपूर्ण है जहां डेटा अधिकांश डिजिटल व्यवसायों की प्राथमिक संपत्ति है।
जैसे-जैसे तकनीक परिपक्व होती है, ‘डिज़ाइनर’ और ‘बिल्डर’ के बीच का अंतर धुंधला हो सकता है। अवधारणात्मक मॉडलिंग और भौतिक कार्यान्वयन के बीच की रेखा बढ़ती तरीके से भेदभावहीन हो जाएगी। इस संगम की ओर एक अधिक लचीली और प्रतिक्रियाशील सॉफ्टवेयर विकास जीवन चक्र की गारंटी है।
🌐 निष्कर्ष
एआई के माध्यम से एंटिटी रिलेशनशिप डायग्राम के विकास डेटा इंजीनियरिंग के क्षेत्र में एक महत्वपूर्ण विकास है। इससे विषय को हस्तलिखित ड्राफ्टिंग से बुद्धिमान डिज़ाइन की ओर ले जाता है। भरोसे, संदर्भ और गवर्नेंस से संबंधित चुनौतियाँ बनी रहती हैं, लेकिन दक्षता, सटीकता और स्केलेबिलिटी के लिए संभावित लाभ बहुत बड़े हैं।
वास्तुकारों और डेवलपर्स के लिए भविष्य की ओर बढ़ने का रास्ता इन उपकरणों को शक्तिशाली सहायक के रूप में स्वीकार करने में है। मानव विशेषज्ञता और मशीन बुद्धिमत्ता को मिलाकर, टीमें ऐसी टिकाऊ डेटा आर्किटेक्चर बना सकती हैं जो समय के परीक्षण को सहन कर सकें। डेटा मॉडलिंग का भविष्य मानव मस्तिष्क को बदलने के बारे में नहीं है, बल्कि उसे आधुनिक डेटा परिदृश्य की जटिलता को समझने वाले उपकरणों से सशक्त बनाने के बारे में है।