











システムの複雑さが増すにつれて、基盤となるデータ構造の安定性が運用信頼性の基盤となる。エンジニアリングチームが直面する最も持続的な課題の一つがスキーマのずれである。この現象は、データベーススキーマが期待される設計から逸脱したときに発生し、一貫性の欠如、破損したクエリ、予測不能なアプリケーション動作を引き起こす。しばしばデータベース管理の問題として扱われるが、根本的な原因は、エンティティ関係図(ERD)が初期段階でどのようにアーキテクチャ設計され、管理されているかに頻繁に起因する。
適切に構造化されたERDは、関係を可視化する以上の役割を果たす。それはアプリケーションロジックとデータストレージ層との間の契約として機能する。複数のサービスが共有データとやり取りするスケーラブルな環境では、この契約は成長に対応できるよう、厳密でありながら柔軟性を持つ必要がある。本ガイドは、データモデルを安定化させ、本番環境に影響を与える前にスキーマのずれを防ぐためのアーキテクチャパターンと手法を検討する。
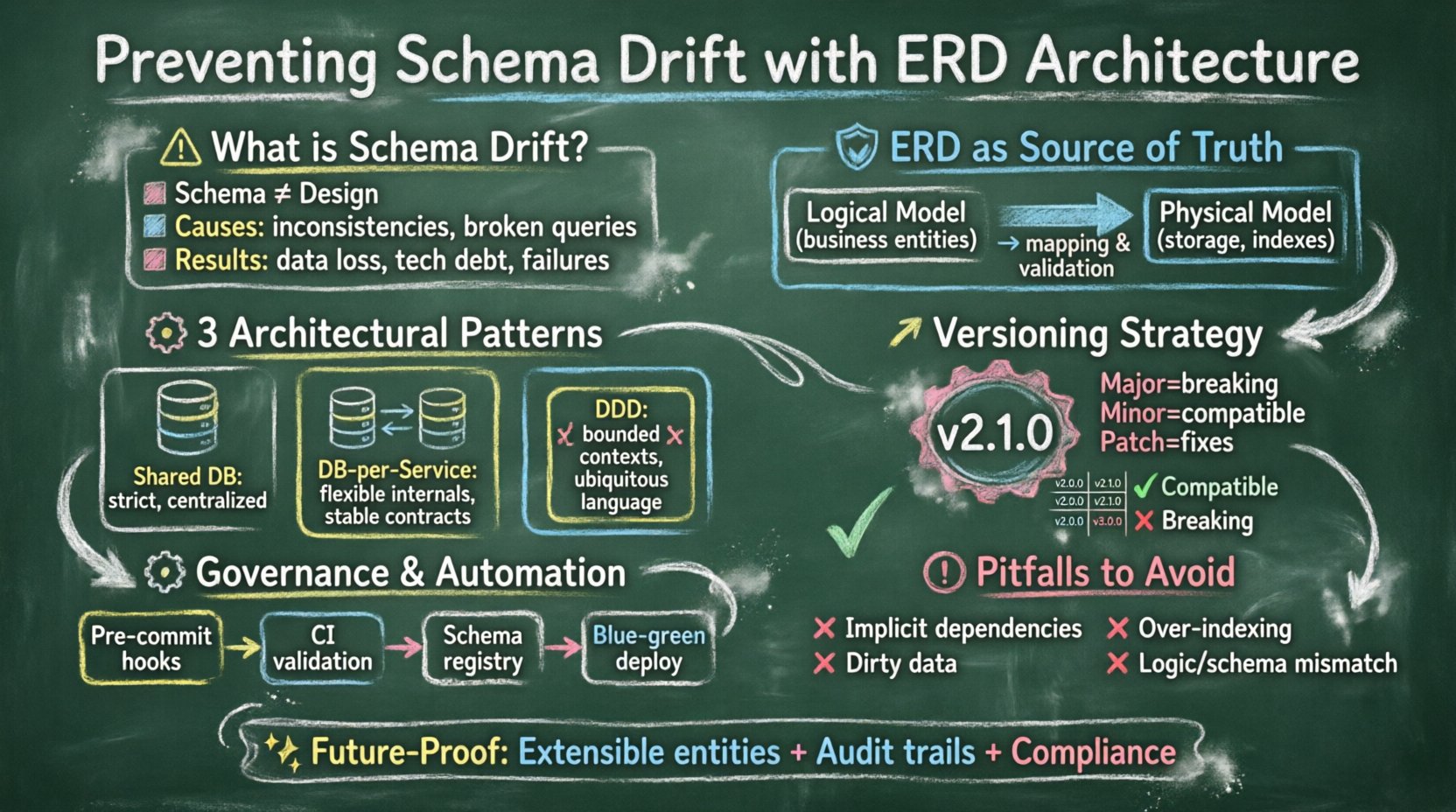
📉 分散環境におけるスキーマのずれの理解
スキーマのずれは、テーブルの更新を忘れること以上の問題である。これは、時間の経過とともにデータモデルの物理的実装が論理的定義から逸脱するシステム的な問題である。モノリシックなシステムでは、いくつかの忘れられたカラムとして現れることがある。分散型、マイクロサービスアーキテクチャでは、サービスAがサービスBが読み取れない形式でデータを書き込むという競合状態を引き起こす可能性がある。
制御されないずれの結果には、以下のものがある:
- データ整合性の喪失:制約が無視され、無効な状態が許可される。
- 技術的負債の増加:開発者は機能の開発よりもデータの問題のデバッグに多くの時間を費やす。
- サービスの障害:APIは、特定のフィールド型や存在を期待している場合に失敗する。
- 移行の複雑性:ギャップが広がるにつれて、追いつくことが難しくなる。
これを防ぐには、柔軟性を損なわずに一貫性を強制するERDに対するアーキテクチャ的アプローチが必要である。変更のルールを定義し、データモデルをバージョン管理し、図自体に対するガバナンスを確立することが含まれる。
🛡️ 基盤:ERDを真実の源泉として
ずれを防ぐための第一歩は、エンティティ関係図を静的な図から、実装を駆動する動的な文書へと引き上げることである。ERDを二次的なアーティファクトとして扱うと、ずれは避けられない。一方、ERDを主な真実の源泉として扱うことで、アーキテクチャは安定性を支える。
1. 論理的と物理的分離
柔軟性を保ちつつ安定性を確保するため、論理的データモデルと物理的実装を分離する。論理的ERDは、技術的制約を考慮せずにビジネスエンティティとその関係を記述すべきである。物理的ERDはインデックス、パーティショニング、特定のストレージタイプを扱う。
この分離により、ビジネスロジックが即時の物理的変更を強いることなく進化できる。変更がストレージ層に影響を与える前に、ビジネス要件に基づいて検証できるバッファゾーンが作られる。
2. 標準化データモデル
スケーラブルなシステムでは、複数のサービスが同じデータを理解する必要があることがよくある。標準化されたデータモデルを確立することで、すべてのサービスが同じ定義を参照することを保証する。ERDがこれらの標準化されたエンティティを定義する。
- 単一の真実の源泉:ERDは、User、Order、Inventoryなどの重要なエンティティの正確なスキーマを定義する。
- サービス契約:サービスは、臨時のクエリではなく、ERDの定義に基づいてデータを消費する。
- 標準化された命名:ERDで定義された命名規則により、異なるデータベースインスタンス間での曖昧さが防止される。
🧩 ERDの安定性のためのアーキテクチャパターン
異なるシステムアーキテクチャには、それぞれ異なるERD戦略が必要である。以下のパターンは、システムが拡大するにつれて一貫性を維持するのを助ける。
1. シェアドデータベースパターン
一部のモノリシックまたは密結合システムでは、共有データベースが使用される。ここではERDは極めて厳格でなければならない。ERDの変更には、そのデータベースにアクセスするすべてのモジュール間での調整が必要となる。
- 集中型スキーマ管理: 1つのチームがERDの更新を担当する。
- 厳格なアクセス制御: 承認されたスクリプトのみがスキーマを変更できる。
- 依存関係の追跡: ERDは、テーブル間の依存関係を明確にマッピングし、変更前の影響を特定できるようにする必要がある。
2. サービスごとのデータベースパターン
マイクロサービスアーキテクチャでは、各サービスが自らのデータを所有する。これにより直接的な結合が軽減されるが、サービス間でデータ定義が不整合になるリスクが生じる。ここでのERDアーキテクチャは、各サービスの内部ストレージではなく、サービス間のインターフェースに焦点を当てる。
- 内部の柔軟性: 各サービスは、外部インターフェースが安定している限り、内部スキーマを進化させることができる。
- 外部契約: ERDは共有契約を定義する。Service AがService Bからデータを必要とする場合、ERDは期待される構造を定義する。
- イベントソーシング: ERDはデータを運ぶイベントを定義でき、不変性とトレーサビリティを確保する。
3. ドメイン駆動設計(DDD)アプローチ
ドメイン駆動設計は、データベーススキーマをビジネスドメインと一致させる。ERDは境界付きコンテキストごとに分割される。これにより、関係のないエンティティが一つのスキーマに強制的に組み込まれる「ゴッドテーブル」問題を防ぐ。
- コンテキストマッピング: ERDは境界付きコンテキスト間の関係をマッピングする。
- ユニバーサル言語: ERD内のエンティティ名は、ビジネス用語と一致する。
- カプセル化: 内部エンティティは隠蔽される。ドメイン境界のみが公開される。
🔄 スキーマ進化のためのバージョン管理戦略
変更は避けられない。その目的は、既存の消費者を破壊せずに変更を管理することである。ERDアーキテクチャ内でスキーマをバージョン管理することは、極めて重要である。
1. スキーマのセマンティックバージョン管理
ソフトウェアコードがセマンティックバージョン管理を使用するのと同様に、データスキーマもそうすべきである。スキーマのバージョンは、Major.Minor.Patch の形式で表すことができる。
- メジャーバージョン: ブレイキングチェンジ(例:カラムの削除、型の変更)
- マイナー: 後方互換性のある追加(例:NULL許容の列を追加する)。
- パッチ: API に影響を与えない内部の修正や最適化。
2. 後方互換性のルール
ずれを防ぐため、スキーマの進化に関する厳格なルールに従ってください。以下の表は、安全な変更と安全でない変更を示しています。
| 操作 | 互換性 | 要件 |
|---|---|---|
| 新しい列を追加 | 後方互換性あり | 初期段階でNULLを許容する必要がある |
| 新しいテーブルを追加 | 後方互換性あり | 初期段階で外部キーの依存関係がないことを確認する |
| 列を削除 | 破壊的変更 | まず非推奨とし、その後削除する |
| データ型を変更 | 破壊的変更 | 完全な移行計画が必要 |
| 外部キーを追加 | 条件付き | 既存のデータが制約を満たしていることを確認する |
3. ダブル書き込みパターン
スキーマの変更が必要な場合、即時切り替えを避けましょう。データを古い構造と新しい構造の両方に書き込むダブル書き込み戦略を実装します。時間とともにトラフィックを新しい構造に移行します。この移行中は、ERDで両方のバージョンを文書化する必要があります。
- 読み取りパス: 安定したスキーマから読み取りを継続する。
- 書き込みパス: 両方のスキーマに同時に書き込む。
- 検証: 2つのスキーマ間のデータ整合性を監視する。
- 切り替え: 確認後、古いスキーマへの書き込みを停止する。
⚙️ マイグレーション管理とガバナンス
バージョン管理があっても、マイグレーションは必要である。アーキテクチャは、安全で、元に戻せる、自動化されたマイグレーションをサポートしなければならない。
1. マイグレーションスクリプトはコードとして扱う
マイグレーションはアプリケーションコードと共にバージョン管理されるべきである。ERDはこれらのスクリプトのターゲット状態として機能する。各マイグレーションファイルは、実装している特定のERDバージョンを参照すべきである。
- 冪等性: スクリプトは複数回実行しても安全であるべきである。
- ロールバック機能: すべてのアップグレードには、対応するダウングレードスクリプトが必要である。
- 原子性: 変更は可能な限りトランザクションとして扱い、部分的な更新を防ぐべきである。
2. スキーマレジストリ
環境間でERDの状態を追跡するためのスキーマレジストリを導入する。これにより、開発、ステージング、本番環境が一致していることを保証する。
- 環境の同一性: 開発環境と本番環境のずれを防ぐ。
- 承認ワークフロー: スキーマの変更は、昇格前にレビューが必要である。
- 検証: 自動チェックにより、デプロイされたスキーマが登録されたERDと一致していることを保証する。
3. ドキュメントはコードとして扱う
ドキュメントはERDそのものから生成されるべきである。これにより、図とテキスト記述が同期されたままになる。手動で作成されたドキュメントは、すぐに古くなることが多い。
- 自動生成: ツールはERDファイルからドキュメントを生成できる。
- 動的なドキュメント: ドキュメントの更新はコードレビューの一部である。
- 文脈付きのメモ: ビジネスロジックのメモをERDのメタデータに直接含める。
📝 自動化とCI/CD統合
人的ミスはスキーマのずれの主な原因です。自動化により、デプロイパイプライン中にルールを強制することで、このリスクを低減できます。
1. コミット前フック
リポジトリにコミットされる前にスキーマの変更を検証するフックを実装します。これらのフックは、現在のERD定義に対して破壊的変更がないかを確認します。
- Linting: 名前付け規則や構造ルールを強制します。
- 検証: 新しい制約が既存のデータと衝突しないことを確認します。
- レビュー: 高リスクの変更には手動での承認を必須とします。
2. 持続的インテグレーションのチェック
CIプロセス中に、テストデータベースに対してスキーマの検証を実行します。これにより、デプロイ前に問題を発見できます。
- サンドボックス環境: マイグレーションをテストするために一時的な環境にデプロイします。
- 統合テスト: スキーマに依存するクエリを実行し、機能性を確認します。
- パフォーマンスチェック: 新しいインデックスが書き込みパフォーマンスを低下させないことを確認します。
3. データのブルーグリーンデプロイ
アプリケーションのデプロイと同様に、データに対してブルーグリーン戦略を使用します。新しいバージョンが安定するまで、スキーマの2つのバージョンを並行して維持します。
- ゼロダウンタイム: スキーマの変更によってユーザーに影響がありません。
- 即時ロールバック: 問題が発生した場合、以前のスキーマバージョンに戻すことができます。
- データ同期: 遷移中において、両バージョン間でデータが一貫していることを確認します。
🚨 避けるべき一般的な落とし穴
堅固なアーキテクチャがあっても、チームは再びスキーマのずれを引き起こす落とし穴に陥ることがあります。これらの落とし穴への意識は、長期的な安定性にとって不可欠です。
1. 暗黙の依存関係
コードは、ERDに明示的に定義されていないデータ構造に依存することが多いです。カラム名をハードコードしたり、データの存在を仮定したりすると、静かに失敗する原因になります。
- 明示的な型指定:すべてのデータアクセス層で強力な型指定を使用する。
- インターフェース契約:データアクセス用に明確なインターフェースを定義する。
- リファクタリング:コードに隠れた仮定がないか定期的に監査する。
2. データ品質の無視
スキーマが完璧であっても、入力されるデータが汚れている場合はシステムは失敗する。ERDにはデータ品質を強制する制約を含めるべきである。
- チェック制約:データベースレベルで値を検証する。
- 一意制約:重複エントリを防止する。
- NULL許容なし制約:必須フィールドが常に入力されていることを保証する。
3. 過剰なインデックス化
読み取りパフォーマンスを改善するためにインデックスを追加すると、書き込みが遅くなることが多い。これにより、書き込みパスを妨げるスキーマの変更が生じる可能性がある。
- まずは測定する:インデックスを追加する前に、クエリのパフォーマンスを監視する。
- 定期的に見直す:使用されていないインデックスを削除してオーバーヘッドを削減する。
- バランスを取る:読み取りと書き込みのパフォーマンスの間に適切なバランスを見つける。
4. ロジックとスキーマの分離
アプリケーション層に実装すべきビジネスロジックをデータベースに置くことで、一貫性が失われる。ERDはロジックがどこに存在するかを示すべきである。
- データベース制約:適切な場面では、ロジックをトリガーまたはストアドプロシージャに移動する。
- 検証:アプリケーションロジックがデータベースルールを回避しないことを保証する。
- 明確さ:ERDのメモに、ロジックがどこに存在するかを記録する。
🔮 データモデルの将来対応性の確保
スケーラブルなシステムは将来に備えていなければならない。ERDのアーキテクチャは成長と変化を予測するべきである。
1. 拡張性
エンティティを拡張可能に設計する。変化する可能性のある属性には、柔軟なデータ型またはJSONカラムを使用し、コア構造は厳密に保つ。
- 属性セット:変動する属性を構造化されたマップに保存する。
- タグとラベル:動的メタデータにはキーと値のペアを使用する。
- バージョンフィールド:変更を追跡するために、エンティティにバージョン番号を含める。
2. オーディットトレール
データのすべての変更は追跡可能でなければならない。ERDには、誰がいつ何を変更したかを記録するための監査テーブルを含めるべきである。
- 履歴テーブル:レコードの変更履歴を維持する。
- 変更ログ:スキーマの変更をデータの変更とは別にログ記録する。
- アクセスログ:誰が機密データを照会したかを追跡する。
3. 合規性とセキュリティ
データモデルは規制要件に準拠しなければならない。ERDは機密データがどこに保存され、どのように保護されるかを定義すべきである。
- 暗号化:暗号化が必要なフィールドをマークする。
- 保持ポリシー:データがスキーマに保持される期間を定義する。
- アクセス制御:特定のエンティティにアクセスできる役割を定義する。
🏁 アーキテクチャの整合性についての最終的な考察
スキーマのずれを防ぐことは変更を制限することではなく、規律を持って管理することである。エンティティ関係図を中心的なアーキテクチャ資産として扱うことで、堅牢かつ適応性のあるシステムを構築できる。その鍵は、関心の分離、厳格なバージョン管理、および自動化されたガバナンスにある。
ERDが尊重されれば、データモデルはスケーラブルなアプリケーションを構築するための安定した基盤となる。これにより開発者の認知負荷が軽減され、運用リスクが最小限に抑えられ、システムが成長しても維持可能であることが保証される。図のアーキテクチャがデータの安定性を決定し、その結果としてビジネスの安定性が確保される。
これらのパターンを採用するには、プロセスとツールへの初期投資が必要である。しかし長期的なリターンとして、壊れたデータ契約を常に修正するという負担なしに、スムーズに進化するシステムが得られる。データモデルの整合性を最優先にすれば、システムも自然とそれに従う。