











Wraz z rosnącą złożonością systemów, stabilność podstawowych struktur danych staje się fundamentem niezawodności operacyjnej. Jednym z najtrwalszych wyzwań napotykanych przez zespoły inżynieryjne jest rozsunięcie schematu. Zjawisko to występuje, gdy schemat bazy danych odbiega od oczekiwanego projektu, co prowadzi do niezgodności, uszkodzonych zapytań i niestabilnego zachowania aplikacji. Choć często traktowane jako problem administracji baz danych, korzeń problemu często tkwi w sposobie projektowania i zarządzania diagramem relacji encji (ERD) od samego początku.
Dobrze zaprojektowany ERD robi więcej niż tylko wizualizuje relacje; działa jako umowa między logiką aplikacji a warstwą przechowywania danych. W skalowalnych środowiskach, gdzie wiele usług współdziała z udostępnionymi danymi, ta umowa musi być sztywna, ale jednocześnie wystarczająco elastyczna, by dopasować się do rozwoju. Niniejszy przewodnik omawia wzorce architektoniczne i metodyki, które stabilizują modele danych i zapobiegają rozsunięciu schematu przed jego wpływem na środowisko produkcyjne.
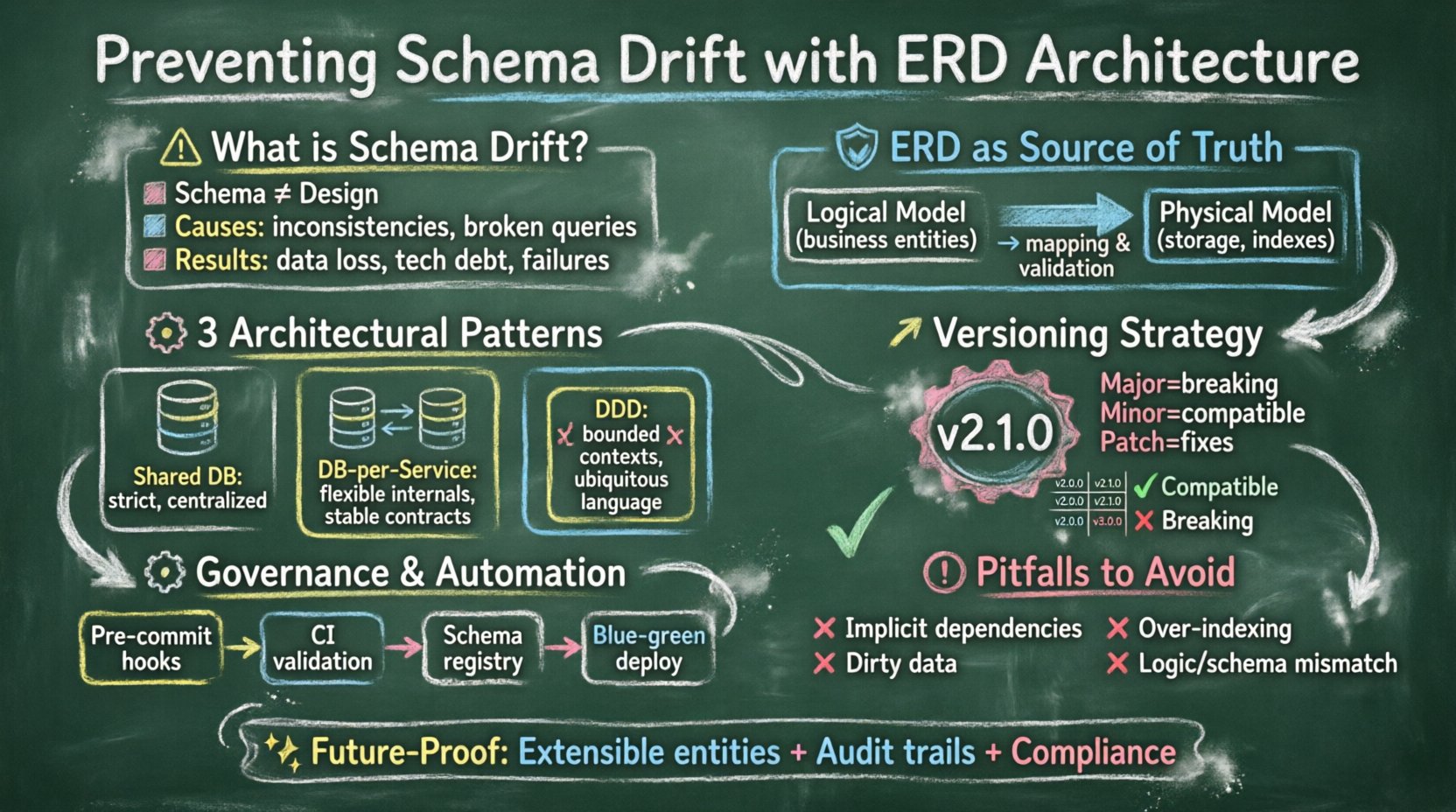
📉 Zrozumienie rozsunięcia schematu w środowiskach rozproszonych
Rozsunięcie schematu to nie tylko kwestia zapomnienia o aktualizacji tabeli. Jest to problem systemowy, w którym fizyczna realizacja modelu danych odbiega od jego definicji logicznej z upływem czasu. W systemach monolitycznych może to przejawiać się kilkoma zapomnianymi kolumnami. W rozproszonych architekturach mikroserwisów może prowadzić do warunków wyścigu, gdy Serwis A zapisuje dane w formacie, którego Serwis B nie może odczytać.
Skutki niekontrolowanego rozsunięcia obejmują:
- Utrata integralności danych:Ograniczenia są pomijane, pozwalając na nieprawidłowe stany.
- Zwiększone długi technologiczne:Programiści spędzają więcej czasu na debugowaniu problemów z danymi niż na budowaniu funkcjonalności.
- Zawieszenia usług:Interfejsy API zawodzą, gdy oczekują określonych typów pól lub ich istnienia.
- Złożoność migracji:Dogania się staje trudniejsze, gdy rozpiętość się zwiększa.
Zapobieganie temu wymaga podejścia architektonicznego do ERD, które zapewnia spójność bez ograniczania zwinności. Obejmuje to definiowanie zasad zmian, wersjonowanie modelu danych oraz ustalanie zarządzania diagramem samym w sobie.
🛡️ Podstawa: ERD jako źródło prawdy
Pierwszym krokiem zapobiegania rozsunięciu jest podniesienie diagramu relacji encji z statycznego rysunku do żyjącego dokumentu, który kieruje implementacją. Gdy ERD traktowany jest jako drugorzędny artefakt, rozsunięcie staje się nieuniknione. Gdy zaś traktowany jest jako główne źródło prawdy, architektura wspiera stabilność.
1. Oddzielenie logiczne od fizycznego
Aby zachować elastyczność, jednocześnie zapewniając stabilność, oddziel model danych logicznych od implementacji fizycznej. Logiczny ERD powinien opisywać encje biznesowe i ich relacje bez ograniczeń technicznych. Fizyczny ERD zajmuje się indeksowaniem, partycjonowaniem i konkretnymi typami przechowywania.
To oddzielenie pozwala na ewolucję logiki biznesowej bez konieczności natychmiastowych zmian fizycznych. Tworzy strefę buforową, w której zmiany mogą być weryfikowane pod kątem wymagań biznesowych przed wpływniem na warstwę przechowywania danych.
2. Kanoniczne modele danych
W skalowalnych systemach wiele usług często musi rozumieć te same dane. Ustanowienie kanonicznego modelu danych zapewnia, że wszystkie usługi odwołują się do tych samych definicji. ERD definiuje te kanoniczne encje.
- Jedno źródło prawdy:ERD definiuje dokładny schemat dla kluczowych encji, takich jak Użytkownik, Zamówienie lub Inwentarz.
- Umowy usługowe:Usługi pobierają dane na podstawie definicji ERD, a nie zapytań ad hoc.
- Standardowe nazewnictwo:Zasady nazewnictwa zdefiniowane w ERD zapobiegają niejasnościom między różnymi instancjami baz danych.
🧩 Wzorce architektoniczne dla stabilności ERD
Różne architektury systemów wymagają różnych strategii ERD. Poniższe wzorce pomagają utrzymać spójność wraz ze skalowaniem systemu.
1. Wzorzec współdzielonej bazy danych
W niektórych monolitycznych lub ściśle powiązanych systemach wykorzystywana jest współdzielona baza danych. W tym przypadku ERD musi być bardzo rygorystyczny. Zmiany w ERD wymagają koordynacji między wszystkimi modułami uzyskującymi dostęp do tej bazy danych.
- Zarządzanie schematem w sposób centralny:Jeden zespół odpowiada za aktualizacje ERD.
- Ścisłe kontrolowanie dostępu:Tylko autoryzowane skrypty mogą modyfikować schemat.
- Śledzenie zależności:ERD musi jasno odzwierciedlać zależności między tabelami, aby można było zidentyfikować skutki przed wprowadzeniem zmian.
2. Wzorzec bazy danych na usługę
W architekturach mikroserwisów każda usługa zarządza własnymi danymi. Zmniejsza to bezpośrednią zależność, ale wprowadza ryzyko niezgodnych definicji danych między usługami. Architektura ERD skupia się tutaj na interfejsie między usługami, a nie na wewnętrznym przechowywaniu danych każdej z nich.
- Wewnętrzna elastyczność:Każda usługa może rozwijać swój wewnętrzny schemat, o ile zewnętrzny interfejs pozostaje stabilny.
- Zewnętrzne umowy:ERD definiuje wspólne umowy. Jeśli usługa A potrzebuje danych z usługi B, ERD określa oczekiwaną strukturę.
- Zasoby zdarzeń:ERD może definiować zdarzenia przenoszące dane, zapewniając niezmienność i śledzenie.
3. Podejście zorientowane na domenę (DDD)
Projektowanie zorientowane na domenę dopasowuje schemat bazy danych do domen biznesowych. ERD jest dzielony na konteksty ograniczone. Zapobiega to problemowi „Boga tabeli”, gdy niepowiązane encje są wymuszane do jednego schematu.
- Mapowanie kontekstów:ERD mapuje relacje między kontekstami ograniczonymi.
- Wspólna językowość:Nazwy encji w ERD odpowiadają terminologii biznesowej.
- Ukrywanie szczegółów:Wewnętrzne encje są ukryte; widoczna jest tylko granica domeny.
🔄 Strategie wersjonowania dla ewolucji schematu
Zmiany są nieuniknione. Celem jest zarządzanie nimi bez naruszania istniejących użytkowników. Wersjonowanie schematu w architekturze ERD jest kluczowe.
1. Wersjonowanie semantyczne dla schematów
Tak jak kod oprogramowania używa wersjonowania semantycznego, tak samo powinny robić schematy danych. Wersję schematu można oznaczyć jako Major.Minor.Patch.
- Główna:Zmiany łamające zgodność (np. usunięcie kolumny, zmiana typu).
- Mniejszy: Dodatki zgodne z wsteczną kompatybilnością (np. dodanie kolumny z możliwością wartości NULL).
- Poprawka: Wewnętrzne poprawki lub optymalizacje, które nie wpływają na interfejs API.
2. Zasady kompatybilności wstecznej
Aby zapobiec rozbieżnościom, należy przestrzegać rygorystycznych zasad dotyczących ewolucji schematu. Poniższa tabela przedstawia bezpieczne i niebezpieczne zmiany.
| Działanie | Kompatybilność | Wymóg |
|---|---|---|
| Dodaj nową kolumnę | Zgodne z wsteczną kompatybilnością | Za pierwszym razem musi zezwalać na wartości NULL |
| Dodaj nową tabelę | Zgodne z wsteczną kompatybilnością | Upewnij się, że początkowo nie ma zależności kluczy obcych |
| Usuń kolumnę | Zmiana łamająca kompatybilność | Najpierw zdeprecjuj, a później usuń |
| Zmień typ danych | Zmiana łamająca kompatybilność | Wymaga pełnego planu migracji |
| Dodaj klucz obcy | Warunkowe | Upewnij się, że istniejące dane spełniają ograniczenie |
3. Wzorce zapisu podwójnego
Gdy wymagana jest zmiana schematu, unikaj natychmiastowego przejścia. Zaimplementuj strategię zapisu podwójnego, w której dane są zapisywane zarówno w starym, jak i nowym schemacie. W czasie zmienia się ruch na nowy schemat. Diagram ERD powinien dokumentować obie wersje podczas tej przejściowej fazy.
- Ścieżka odczytu: Kontynuuj odczyt z stabilnego schematu.
- Ścieżka zapisu: Zapisz jednocześnie do obu schematów.
- Weryfikacja: Monitoruj spójność danych między dwoma schematami.
- Przełączenie: Po weryfikacji zatrzymaj zapisywanie do starego schematu.
⚙️ Zarządzanie migracjami i zarządzanie
Nawet przy wersjonowaniu migracje są konieczne. Architektura musi wspierać bezpieczne, odwracalne i automatyczne migracje.
1. Skrypty migracji jako kod
Migracje powinny być wersjonowane razem z kodem aplikacji. ERD służy jako stan docelowy dla tych skryptów. Każdy plik migracji powinien odnosić się do konkretnej wersji ERD, którą realizuje.
- Idempotentność: Skrypty powinny być bezpieczne do uruchamiania wielokrotnie.
- Możliwość cofnięcia: Każde uaktualnienie musi mieć odpowiadający mu skrypt cofnięcia.
- Atomowość: Zmiany powinny być transakcyjne tam, gdzie to możliwe, aby zapobiec częściowym aktualizacjom.
2. Rejestr schematów
Zaimplementuj rejestr schematów w celu śledzenia stanu ERD w różnych środowiskach. Zapewnia to zgodność środowisk deweloperskiego, testowego i produkcyjnego.
- Zgodność środowisk: Zapobiega rozbieżnościom między środowiskiem deweloperskim a produkcyjnym.
- Przepływy zatwierdzeń: Zmiany schematu wymagają przeglądu przed promocją.
- Weryfikacja: Automatyczne sprawdzenia zapewniają, że wdrożony schemat odpowiada zarejestrowanemu ERD.
3. Dokumentacja jako kod
Dokumentacja powinna być generowana bezpośrednio z ERD. Zapewnia to synchronizację diagramów i opisów tekstowych. Dokumentacja ręczna często szybko się wygryza.
- Automatyczna generacja: Narzędzia mogą generować dokumentację z pliku ERD.
- Żywą dokumentację: Aktualizacje dokumentacji są częścią procesu przeglądu kodu.
- Uwagi kontekstowe: Włącz notatki dotyczące logiki biznesowej bezpośrednio w metadanych ERD.
📝 Automatyzacja i integracja z CI/CD
Błędy ludzkie są główną przyczyną odchylania schematu. Automatyzacja zmniejsza ten ryzyko, stosując zasady w trakcie procesu wdrażania.
1. Wtyczki przed zatwierdzeniem
Zaimplementuj wtyczki, które weryfikują zmiany schematu przed zatwierdzeniem ich w repozytorium. Te wtyczki sprawdzają zmiany naruszające, w stosunku do bieżącej definicji ERD.
- Linting: Wymuszaj zasady nazewnictwa i struktury.
- Weryfikacja: Upewnij się, że nowe ograniczenia nie konfliktują z istniejącymi danymi.
- Recenzja: Wymagaj zatwierdzenia ręcznego dla zmian o wysokim ryzyku.
2. Sprawdzanie ciągłej integracji
W trakcie procesu CI uruchom weryfikację schematu względem testowej bazy danych. To pozwala wykryć problemy przed wdrożeniem.
- Środowiska testowe (sandbox): Wdrażaj do tymczasowego środowiska w celu przetestowania migracji.
- Testy integracyjne: Uruchamiaj zapytania oparte na schemacie, aby upewnić się, że funkcjonalność działa.
- Sprawdzanie wydajności: Upewnij się, że nowe indeksy nie pogarszają wydajności zapisu.
3. Wdrażanie typu blue-green dla danych
Podobnie jak w wdrażaniu aplikacji, stosuj strategie typu blue-green dla danych. Utrzymuj dwie wersje schematu równolegle, aż nowa wersja będzie stabilna.
- Brak przestojów: Użytkownicy nie są dotknięci zmianami schematu.
- Natychmiastowe cofnięcie: Jeśli pojawią się problemy, przełącz się z powrotem do poprzedniej wersji schematu.
- Synchronizacja danych: Upewnij się, że dane są spójne między obiema wersjami podczas przejścia.
🚨 Najczęstsze pułapki do uniknięcia
Nawet przy solidnej architekturze zespoły często wpadają w pułapki, które ponownie wprowadzają odchylenie. Znajomość tych pułapek jest niezbędna dla długoterminowej stabilności.
1. Niejawne zależności
Kod często opiera się na strukturach danych, które nie są jawnie zdefiniowane w ERD. Stałe nazwy kolumn lub założenia dotyczące obecności danych prowadzą do cichych awarii.
- Jawne typowanie:Używaj silnego typowania we wszystkich warstwach dostępu do danych.
- Umowy interfejsów:Zdefiniuj jasne interfejsy dostępu do danych.
- Refaktoryzacja:Regularnie audytuj kod pod kątem implikowanych założeń.
2. Ignorowanie jakości danych
Schemat może być idealny, ale jeśli dane wprowadzane do niego są zanieczyszczone, system zawodzi. ERD powinien zawierać ograniczenia zapewniające jakość danych.
- Ograniczenia sprawdzające:Weryfikuj wartości na poziomie bazy danych.
- Ograniczenia unikalności:Zapobiegaj powtarzającym się wpisom.
- Ograniczenia niepustych pól:Upewnij się, że pola wymagane są zawsze wypełnione.
3. Nadmiarowe indeksowanie
Dodawanie indeksów w celu poprawy wydajności odczytu często spowalnia zapisy. Może to prowadzić do zmian schematu, które zakłócają ścieżkę zapisu.
- Najpierw pomiary:Monitoruj wydajność zapytań przed dodaniem indeksów.
- Regularnie przeglądaj:Usuń nieużywane indeksy, aby zmniejszyć obciążenie.
- Zrównowaga:Znajdź odpowiedni kompromis między wydajnością odczytu a zapisu.
4. Odłączenie logiki od schematu
Zastosowanie logiki biznesowej w warstwie aplikacji, która powinna znajdować się w bazie danych, prowadzi do niezgodności. ERD powinien wskazywać, gdzie znajduje się logika.
- Ograniczenia bazodanych:Przenieś logikę do wyzwalaczy lub procedur przechowywanych tam, gdzie jest to odpowiednie.
- Weryfikacja:Upewnij się, że logika aplikacji nie obejmuje reguł bazodanych.
- Jasność:Zarejestruj, gdzie znajduje się logika w notatkach ERD.
🔮 Przyszłościowe zapewnienie odporności modelu danych
Skalowalne systemy muszą być gotowe na przyszłość. Architektura ERD powinna przewidywać wzrost i zmiany.
1. Rozszerzalność
Projektuj encje tak, aby były rozszerzalne. Używaj elastycznych typów danych lub kolumn JSON dla atrybutów, które mogą się różnić, jednocześnie utrzymując sztywną strukturę podstawową.
- Zbiory atrybutów: Przechowuj zmienne atrybuty w strukturalnym mapowaniu.
- Tagi i etykiety: Używaj par klucz-wartość do dynamicznych metadanych.
- Pola wersji: Włącz numery wersji w encjach w celu śledzenia zmian.
2. Ślady audytu
Każda zmiana danych powinna być śledzona. ERD powinien zawierać tabele audytu, aby rejestrować, kto zmienił co i kiedy.
- Tabele historii: Utrzymuj historię zmian rekordów.
- Dzienniki zmian: Rejestruj zmiany schematu osobno od zmian danych.
- Dzienniki dostępu: Śledź, kto wykonywa zapytania do danych poufnych.
3. Zgodność i bezpieczeństwo
Modele danych muszą odpowiadać wymogom regulacyjnym. ERD powinien określać, gdzie przechowywane są dane poufne i jak są chronione.
- Szyfrowanie: Oznacz pola wymagające szyfrowania.
- Polityki przechowywania: Określ, jak długo dane są przechowywane w schemacie.
- Kontrola dostępu: Zdefiniuj role, które mogą uzyskać dostęp do określonych encji.
🏁 Ostateczne rozważania na temat integralności architektury
Zapobieganie rozsunięciu schematu nie polega na ograniczaniu zmian; polega na zarządzaniu nimi z dyscypliną. Traktując diagram relacji encji jako centralny element architektury, zespoły mogą budować systemy zarówno wytrzymałe, jak i elastyczne. Kluczem jest rozdzielenie odpowiedzialności, surowe wersjonowanie i automatyzacja zarządzania.
Gdy ERD jest szanowany, model danych staje się stabilną podstawą, na której można budować skalowalne aplikacje. Zmniejsza to obciążenie poznawcze dla programistów, minimalizuje ryzyko operacyjne i zapewnia, że system pozostaje utrzymywalny w miarę jego rozwoju. Architektura diagramu decyduje o stabilności danych, a w konsekwencji o stabilności działalności biznesowej.
Wprowadzenie tych wzorców wymaga początkowych inwestycji w procesy i narzędzia. Jednak długoterminowa korzyść to system, który ewoluuje zgodnie z zasadami, bez ciągłego obciążenia naprawiania uszkodzonych umów danych. Zadbaj o integralność modelu danych, a system podąży za tobą.