











レガシーシステムをマイクロサービスアーキテクチャに近代化することは、技術的および組織的な課題に満ちた道のりです。多くのチームがコードのリファクタリングやコンテナ化に注力する一方で、大きな障害となるのはしばしばデータ層です。特に、従来のエンティティ関係図(ERD)モデルは、分散システムへの移行時に深刻な制約となることがあります。 📉
モノリシックなアプリケーションを設計する際、データモデルは中央集権化されます。ERDは、正規化されたテーブルが外部キーでリンクされた単一の真実の源を表します。これは単一のデータベースインスタンスでは効果的です。しかし、マイクロサービスは自律性を必要とします。モノリシックなERD構造を分散アーキテクチャに強制すると、システムを分割する利点を相殺するような強い結合が生じます。 🚧
このガイドでは、従来のERDの考え方があらゆるマイクロサービスの採用を妨げる理由を検証し、データモデリング戦略を移行するための実用的なロードマップを提供します。分散データ管理、整合性モデル、ドメイン駆動設計の原則と整合する可視化技術についても取り上げます。 🗺️
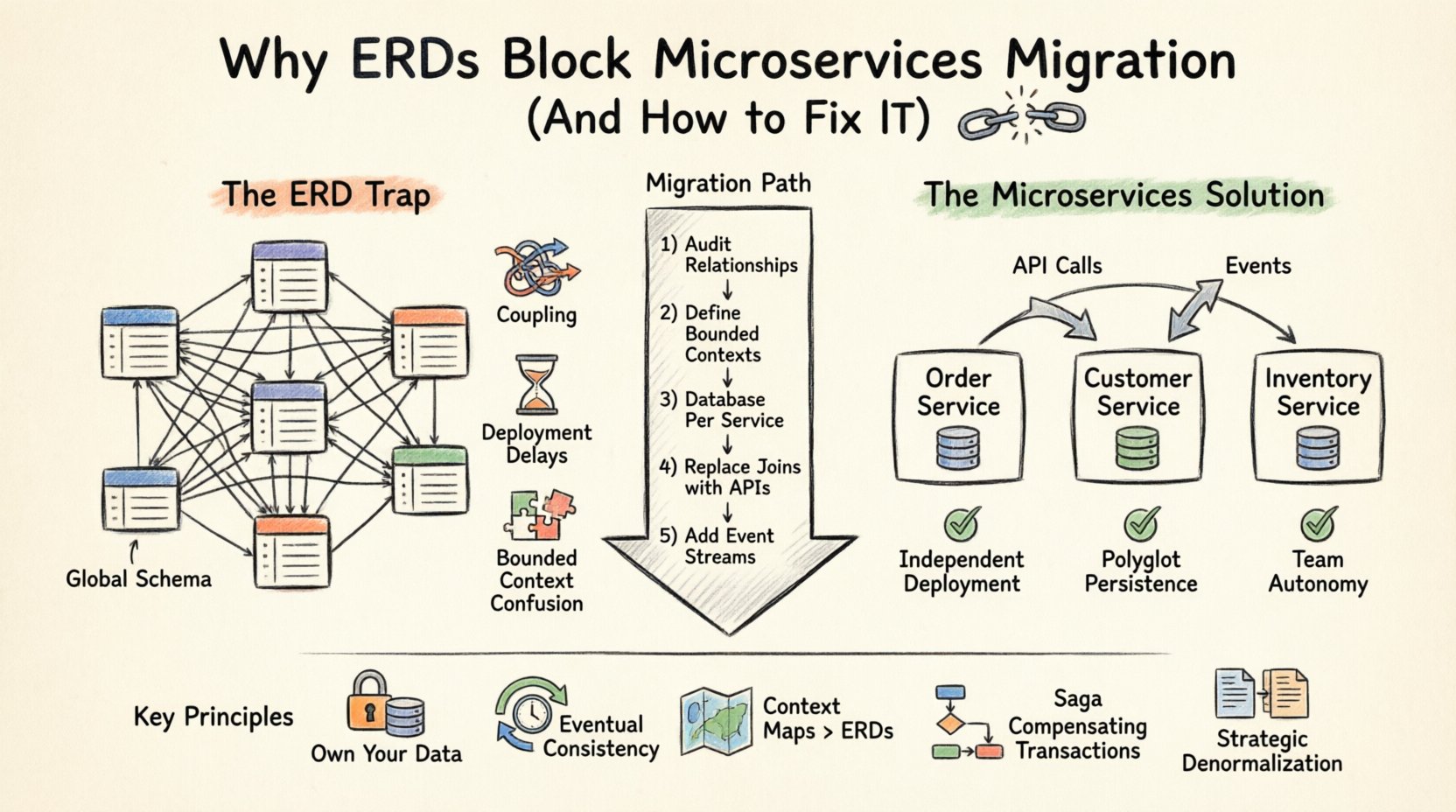
分散システムにおけるERDの罠を理解する 🧩
エンティティ関係図(ERD)は、データベースの論理構造を視覚的に表現したものです。エンティティ(テーブル)、属性(カラム)、関係(外部キー)を定義します。モノリシックな環境では、この中央集権化が強みです。ACIDトランザクションを通じてデータの整合性を保証し、アプリケーション全体にわたるクエリを簡素化します。
しかし、マイクロサービスアーキテクチャはサービスの独立性という原則に基づいています。各サービスは自らのデータを所有し、APIを介してのみ公開すべきです。複数のサービスにまたがる共有ERDを維持すると、所有権の境界を侵害することになります。これにより以下の問題が生じます:
- グローバルなスキーマ依存性: サービスAがデータベースレベルでサービスBのデータを直接結合する必要がある場合、両者はもはや独立していません。サービスBのスキーマの変更は、サービスAを破壊します。
- トランザクション境界:複数のデータベースにまたがるACIDトランザクションは複雑で、パフォーマンスに負担がかかります。分散トランザクションは、ロック競合や遅延の急増を引き起こすことがよくあります。
- デプロイの結合: データモデルが共有されている場合、サービスを独立してデプロイできません。チーム間でスキーマ変更を調整する必要があり、リリースサイクルが遅くなります。
- バウンデッドコンテキストの混乱: 異なるサービスが同じエンティティを異なるように解釈する可能性があります。ERDは単一の定義を強制し、ドメイン固有のニュアンスを無視します。
結合の問題:外部キーと結合 🔗
移行中に最もよく見られる誤りの一つは、アプリケーションコードを分割しながらも、既存のデータベーススキーマをそのまま維持しようとする点です。これにより共有データベースのアンチパターンという状況が生じます。この状況では、複数のサービスが同じデータベースインスタンスに接続し、外部キーに依存して関係を維持しようとします。
この構造は有効なERD構造に見えますが、実際には隠れたモノリスです。なぜこのアプローチがマイクロサービス環境で失敗するのかを以下に示します:
- ネットワーク遅延: データベースがネットワーク内にあっても、サービス間のクエリはネットワークホップを引き起こし、ローカルクエリと比べてパフォーマンスを低下させます。
- 単一障害点: データベースがダウンすれば、すべてのサービスがダウンします。マイクロサービスは、分離によってレジリエンスを実現することを目指しています。
- セキュリティリスク: 他のデータに直接アクセスすべきでないサービスでも、データベースの接続文字列を通じてアクセスできてしまいます。APIは制御されたインターフェースを提供しますが、直接のDBアクセスはそうではありません。
- 技術のロックイン: すべてのサービスが同じデータベース技術を使用しなければなりません。マイクロサービスでは、異なるサービスがそれぞれのニーズに最も適したデータストアを使用できるポリグロット永続化を可能にします。
これを修正するには、サービス境界を越えたSQL結合から離れなければなりません。代わりに、APIの組み合わせまたはイベント駆動型のデータ同期を使用すべきです。 🔄
サービスごとのデータベース:黄金の法則 🏦
マイクロサービスのデータアーキテクチャにおける基盤となるパターンはサービスごとのデータベース。各サービスは独自のデータベーススキーマを所有します。他のサービスはこのデータベースに直接アクセスすることは許可されていません。通信はサービスの公開APIを介して厳密に行われます。
この変化は、データをどのように可視化するかという根本的な変化を要求します。もはや、システム全体に対して1つの巨大なERDを描くことはできません。代わりに、各サービスごとに小さなERDを複数作成します。 📄
| 側面 | モノリシックなERD | マイクロサービスモデル |
|---|---|---|
| スキーマの範囲 | グローバル/統合型 | ローカル/サービス固有 |
| 関係性 | 外部キー | API呼び出し/イベント |
| 整合性 | 強力(ACID) | 最終的(BASE) |
| デプロイメント | 結合されている | 独立している |
共有トランザクションなしで整合性を管理する 🤝
データベースを分離すると、Service AとService Bの両方を同時に更新する単一のトランザクションを実行する能力を失います。モノリシックなシステムでは、アカウントAからアカウントBに資金を移動するためにデータベーストランザクションを使用するかもしれません。マイクロサービスでは、これらのアカウントが異なるサービスに属している可能性があります。
分散システム間で即時整合性を保証できないため、次を採用しなければなりません最終整合性。これは、システムが時間とともに整合性のある状態に達するということですが、ユーザーがボタンをクリックした瞬間に必ずしもそうなるわけではありません。
サーガの実装
複数のサービスにまたがる複雑なワークフローを処理するには、サーガパターン。サーガとは、各トランザクションが単一のサービス内のデータベースを更新するローカルトランザクションの連鎖です。ステップが失敗した場合、サーガは以前のステップで行った変更を元に戻すための補償トランザクションを実行します。
- コーディネーション: サービスはイベントを発行し、他のサービスでのアクションをトリガーする。中央の調整役は存在しない。
- オーケストレーション: 中央の調整サービスがワークフローを管理し、他のサービスに何をすべきかを指示する。
このアプローチは、共有ロックや分散トランザクションを必要とせずにデータの整合性を確保する。実装に複雑性を加えるが、システムの健全性を維持するために不可欠である。 🛡️
ERDを使わずにデータを可視化する:コンテキストマップ 🗺️
伝統的なERDを放棄した場合、データアーキテクチャを可視化するために何を使うのか?その答えは、ドメイン駆動設計(DDD)のコンテキストマップ 一方、ERDはテーブルとカラムに注目するが、コンテキストマップは境界付きコンテキストと関係性に注目する。
テーブルの間に線を引くのではなく、サービスの間に線を引く。データがそれらの間でどのように流れているかを定義する。
- カスタマーサプライヤー: 1つのサービスが別のサービスにデータを提供する。提供者は契約を定義する。
- コンフォーミスト: 消費側のサービスは提供側のモデルに合わせて変更しなければならない。
- オープンホストサービス: サービスがオープンプロトコルを通じてデータを公開する。
- 別々の道: 両方のサービスが独自のモデルを独立して進化させる。
この可視化の変化により、チームはなぜデータが重複しているのかを理解できる。モノリスでは重複は悪いことだが、マイクロサービスでは、サービスを分離するために重複がしばしば特徴となる。例えば、注文サービスは、顧客名注文を表示するたびにネットワーク呼び出しを避けるために、スナップショットを保存する可能性がある。このトレードオフはパフォーマンスのために許容できる。
移行ステップ:ERDから分散データへ 🚀
中央集権的なERDから分散データモデルへの移行は一度きりの出来事ではない。段階的なプロセスである。移行を管理するための推奨アプローチを以下に示す。
ステップ1:既存のデータ関係の監査
何を分割するかの前に、現在のERDのすべての関係を文書化する。どのテーブルが読み取り重視か、書き込み重視か、頻繁に結合されるかを特定する。この分析により、エンティティを論理的なサービス境界にグループ化できる。 📊
ステップ2:境界付きコンテキストの定義
技術的依存関係よりもビジネスドメインに基づいてエンティティをグループ化してください。たとえば、製品カタログは、在庫管理システムとは異なります。どちらも製品IDフィールドを使用している場合でもです。境界がチーム構造と一致していることを確認してください(コンウェイの法則)。
ステップ3:サービスごとのデータベースの実装
各サービスに対して新しいデータベースインスタンスを作成してください。モノリシックデータベースから関連データを移行します。すべてをすぐに移動する必要はありません。サービスが機能するために必要なコアデータから始めましょう。 🏗️
ステップ4:JOINをAPI呼び出しに置き換えます
クエリを再設計してください。Orders, Customers を JOINする代わりに、コードはカスタマーアプリケーションインターフェースを呼び出して詳細を取得するようにしてください。これにより遅延が発生する可能性があるため、適切な場面ではキャッシュ戦略や非正規化を検討してください。
ステップ5:イベントストリームの導入
リアルタイム更新のために、イベントバスを実装してください。1つのサービスでエンティティが変更されたら、イベントを発行します。他のサービスはこれらのイベントに購読することで、データのローカルコピーを更新できます。これにより、直接的な結合なしに最終的な整合性を保証できます。
移行中の一般的な落とし穴 ⚠️
計画があっても、チームは移行中にしばしばつまずきます。これらの一般的な問題に注意してください。
- 過度な分割:データフローを理解する前にサービスを分割しないでください。早すぎる分割は、準備ができていない段階で分散型の複雑性を引き起こす可能性があります。
- データ所有権を無視する:複数のチームが同じデータエンティティの所有権を主張すると、衝突が生じます。各サービスに明確な所有権を割り当ててください。
- 過剰な正規化:分散システムでは、ページをレンダリングするために必要なAPI呼び出しの数を減らすために、非正規化がしばしば好まれます。
- ネットワークへの依存:ネットワークが完璧であると仮定してはいけません。サービス間通信にはタイムアウト、再試行、回路遮断器を実装してください。
組織の整合性 🤝
データアーキテクチャは技術的なものだけでなく、組織的なものです。分散型データモデルでは、チームが異なる方法でコミュニケーションを取る必要があります。モノリスでは開発者は共有のホワイトボード(データベース)を介して話します。マイクロサービスでは、API契約を介して話します。
チームが中央のガバナンスボードに相談せずにデータベーススキーマを変更できるようにしてください。この自律性こそが、独立したデプロイのスピードを維持する唯一の方法です。すべてのスキーマ変更を承認する中央チームを導入すると、排除しようとしていたボトルネックが再び発生します。 👥
データ戦略の最終的な考察 🧭
従来のエンティティ関係図(ERD)から離れるのは大きな一歩です。これには、からへのマインドセットの変化が必要です。制約を通じたデータ整合性 へと アプリケーションロジックおよびイベントを通じたデータ整合性。ERDはリレーショナルデータベースのためのツールであり、分散システムの設計図ではありません。
サービスごとのデータベースパターンを採用し、イベント駆動型アーキテクチャを活用し、バウンデッドコンテキストに注目することで、移行を遅らせる結合を回避できます。目標は既存のデータモデルを破壊することではなく、独立したスケーリングとレジリエンスをサポートする構造へと進化させることです。
整合性はスケールであることを思い出してください。すべての場所で強い整合性が必要なわけではありません。システムのどの部分が厳密な正確性を必要とし、どの部分が最終的に整合性を許容できるかを特定しましょう。この現実的な姿勢が、過剰な設計を避ける助けになります。
まず現在の図面を精査しましょう。サービス境界をまたぐ結合を特定します。その特定のエンティティの移行を計画します。小さなステップを踏み、結果を検証してください。そして常にビジネスドメインをデータ設計の中心に据えてください。 🎯
主な教訓 📝
- 結合を防ぐために、サービス間でデータベースを共有しないようにしましょう。
- サービス間のデータに対して、SQL結合の代わりにAPIコンポジションを使用しましょう。
- 可用性とパーティション耐性を得るために、最終的整合性を受け入れましょう。
- グローバルなERDではなく、コンテキストマップを使ってデータを可視化しましょう。
- 個々のサービスチームに明確なデータ所有権を割り当てましょう。
- パフォーマンス最適化として、データの重複を計画しましょう。
これらの原則に従うことで、ERDが新しいアーキテクチャの制限を決定させることなく、データ移行の複雑さを乗り越えることができます。前進する道は分散型で、去中心化され、スケーラビリティを目的として設計されています。 🚀