











在人工智慧(AI)與機器學習(ML)的時代,組織不再僅僅是建構應用程式,而是打造能夠學習、適應並即時提供洞察的智慧系統。這項轉型的核心在於AI雲端架構——一個強大且專為特定目的設計的框架,能夠支援AI/ML工作負載的開發、訓練、部署與管理,並具備可擴展性。
本全面指南探討了AI雲端架構的本質、核心組件、策略性應用案例、實作最佳實務、關鍵概念與部署模式,賦能企業充分發揮雲端中人工智慧的全部潛力。
🔷 什麼是AI雲端架構?
AI雲端架構是基於雲端、可擴展基礎設施的結構設計,包含運算、儲存與網路資源,專為支援人工智慧與機器學習工作負載而優化。它作為建構、訓練、部署與管理AI模型的高效且安全的骨幹。
✅ 定義:它是一套框架,包含基礎設施、資料管理與編排,使AI/ML模型得以大規模地建構、訓練與部署。
此架構利用專用硬體,例如GPU(圖形處理單元)與TPU(張量處理單元),整合強健的資料流程,並運用微服務與容器編排技術,以提供智慧、即時回應且可擴展的應用程式。
🧱 AI雲端架構的核心層
一個設計良好的AI雲端架構包含五個基礎層:
| 層 | 描述 |
|---|---|
| 1. 基礎設施層 | 提供高效率運算(GPU/TPU)、可擴展網路與具韌性的儲存。支援大規模模型訓練所需的平行運算。 |
| 2. 資料流程層 | 管理來自多樣來源(物聯網、資料庫、API)的高頻率、大量資料的擷取、預處理、轉換與儲存。 |
| 3. AI/ML模型層 | 存放使用TensorFlow、PyTorch或scikit-learn等框架開發的機器學習模型——包含預先訓練與客製化模型。 |
| 4. 編排與MLOps層 | 透過CI/CD流程、版本控制、監控與重新訓練工作流程,自動化模型的生命周期。建構於Kubernetes、Argo或雲端原生MLOps工具等平台之上。 |
| 5. 應用程式與服務層 | 透過 API、網路服務、行動應用程式或邊緣裝置提供人工智慧功能。支援即時推論與批次預測。 |
這些層次協同運作,從資料到決策過程建立無縫的流程。
⚙️ 人工智慧雲架構的關鍵組件
為了充分發揮雲端人工智慧的全部潛力,必須整合若干關鍵組件:
-
Kubernetes (K8s):容器編排的實際標準,支援人工智慧微服務的動態擴展與管理。
-
無伺服器運算:非常適合人工智慧推論工作負載,支援自動擴展與按使用量計費(例如 AWS Lambda、Azure Functions)。
-
高性能儲存:以 SSD 為基礎的區塊儲存與物件儲存(例如 S3、雲端儲存),用於快速存取訓練資料集。
-
資料湖與資料倉儲:集中式儲存庫(例如 Amazon S3、Snowflake、Delta Lake),以原始形式儲存結構化與非結構化資料。
-
模型服務平台:如 TensorFlow Serving、TorchServe 或雲端管理解決方案(例如 SageMaker 端點)等工具,用於低延遲推論。
-
監控與可觀察性:即時追蹤模型效能、偏移檢測、延遲與系統健康狀態。
這些組件確保人工智慧生命週期中具備韌性、可擴展性與營運效率。
📌 何時使用人工智慧雲架構
人工智慧雲架構並非萬能解方,但在特定條件下變得至關重要:
✅ 高需求工作負載
當您的組織執行資源密集型的人工智慧訓練工作——例如大型語言模型(LLMs)、電腦視覺系統或強化學習代理——您需要可擴展的 GPU/TPU 群組,以處理數百 TB 的資料與數百萬個參數。
💡 範例:訓練一個擁有 1000 億參數的語言模型,需要數百張 GPU 與分散式運算——僅有雲端規模的基礎架構才可實現。
✅ 即時智慧
針對需要立即回應的應用,例如詐欺偵測、自駕車輛或即時推薦引擎,需在「邊緣至關重要。
🌐 邊緣人工智慧:將推論移近資料來源(例如物聯網感測器、智慧型手機)可降低延遲並減少頻寬使用。
✅ 混合雲/多雲彈性
具有嚴格法規要求或舊有系統的企業可從以下方案中受益混合雲或多雲策略,在該策略下,人工智慧工作負載可靈活地在本地資料中心、公有雲(AWS、Azure、GCP)與私有雲之間移動,同時確保合規性與資料主權。
🔐 使用案例:一家醫療機構在本地訓練模型(以符合HIPAA規範),但將推論部署於公有雲以實現可擴展性。
🛠️ 如何建立與實踐人工智慧雲架構
實施人工智慧雲架構需要有結構性且分階段的方法。請遵循以下五個步驟:
1. 建立安全的資料基礎
-
建立資料湖或資料倉儲,具備接收即時資料流與批次資料的能力。
-
實施資料治理、資料血緣追蹤與存取控制。
-
使用 Apache Kafka、AWS Glue 或 Google Dataflow 等工具進行即時資料擷取。
2. 選擇合適的雲端基礎架構
選擇專為人工智慧設計的雲端服務提供商與服務:
-
AWS:SageMaker、EC2 GPU實例(P4、G5)、S3
-
Azure:Azure ML、GPU虛擬機、Blob儲存體、Databricks
-
GCP: Vertex AI、TPU群集、BigQuery、Cloud Storage
🎯 提示: 建議選擇 GPU/TPU優化實例 訓練期間;轉換為 彈性執行個體 或 無伺服器 以節省推論期間的費用。
3. 實施MLOps實務
自動化整個AI生命週期:
-
資料、程式碼與模型的版本控制(使用DVC、MLflow或Git)。
-
用於模型重新訓練與部署的CI/CD管道。
-
監控模型效能下降、資料偏移與偏差。
🔄 MLOps = AI的DevOps — 確保可重現性、可靠性與可追蹤性。
4. 優化效能與成本
-
使用 自動擴展群組 根據需求調整運算資源。
-
善用 彈性執行個體 與 可中斷的虛擬機 用於非關鍵的訓練工作。
-
使用資料壓縮, 快取,以及分層儲存以降低成本。
5. 嵌入治理與道德人工智慧
從第一天起就整合安全性與合規性:
-
加密靜態資料與傳輸中資料。
-
實施基於角色的存取控制(RBAC)。
-
監控模型偏見、公平性與可解釋性(XAI)。
-
確保遵守如GDPR、CCPA、HIPAA等法規。
🛡️ 主動治理可防止高昂的失敗與聲譽損傷。
🔑 人工智慧雲端架構中的關鍵概念
理解這些基礎概念對於設計有效的AI系統至關重要:
| 概念 | 說明 |
|---|---|
| MLOps(機器學習運營) | 結合機器學習、DevOps與資料工程的一門學科,用以自動化並簡化模型生命週期。 |
| 資料引力 | 在網路間移動龐大資料集的挑戰。解決方案:將運算資源置於資料附近(例如本地部署或區域雲端區域)。 |
| 模型服務/推論 | 將訓練完成的模型部署以進行預測的過程。可為即時(API)或批次(排程工作)。 |
| 邊緣人工智慧 | 直接在邊緣裝置(攝影機、感測器、手機)上運行人工智慧模型,以降低延遲與頻寬需求。 |
| 可擴展性與成本最佳化 | 利用自動擴展、搶購執行個體與高效儲存來管理變動的工作負載,並降低雲端支出。 |
這些原則引導建築師打造具韌性、高效且面向未來的設計。
🌐 常見的部署模式
根據您的業務需求選擇合適的部署模式:
| 模式 | 優點 | 缺點 | 最適合 |
|---|---|---|---|
| 公有雲 | 快速部署、無限擴展性、豐富的人工智能服務(SageMaker、Vertex AI) | 潛在的資料主權問題 | 新創公司、創新團隊、可擴展的人工智能應用 |
| 私有雲 | 完全掌控、增強的安全性、合規性 | 高設置成本、擴展性有限 | 金融機構、政府機構 |
| 混合雲 | 平衡安全性與彈性;允許工作負載在本地與雲端之間移動 | 複雜的整合 | 具備傳統系統與嚴格合規需求的企業 |
| 多雲 | 避免供應商鎖定,支援選擇最佳服務 | 管理複雜度增加 | 追求冗餘與成本效益的大型企業 |
🔄 趨勢: 大多數企業採用 混合/多雲 策略以平衡敏捷性、安全性與成本。
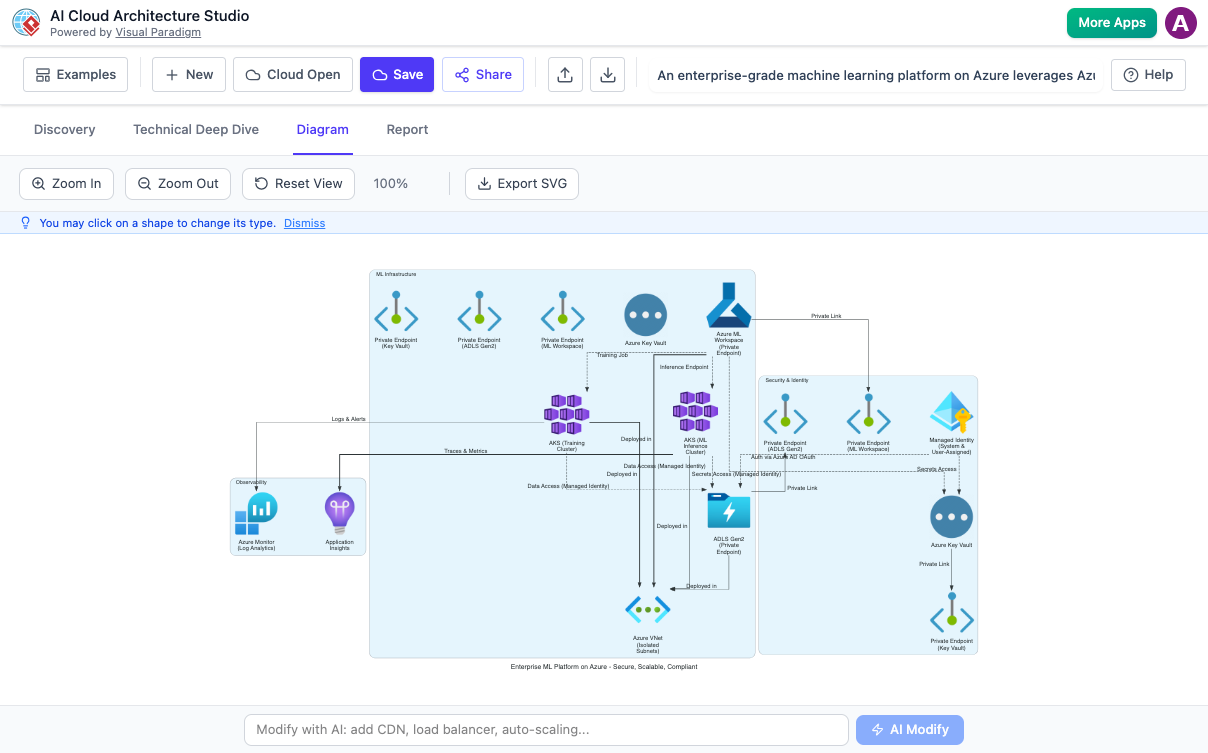
🛠️ Visual Paradigm 的 AI 雲端架構工作室:改變遊戲規則的工具
隨著人工智慧系統變得越來越複雜,視覺化建模變得不可或缺。進入 Visual Paradigm 的 AI 雲端架構工作室—一款尖端工具,專為簡化並加速 AI 驅動的雲端架構設計而設計。
🌟 特色與功能:
-
AI 驅動的建模:可從自然語言提示生成架構圖。
-
多雲端支援:支援 AWS、Azure、GCP 及混合環境的設計。
-
整合的 MLOps 工作流程:可視化 CI/CD 管道、模型版本控制與監控。
-
即時協作:團隊可即時共同設計並標註架構。
-
自動文件化:自動產生技術文件、合規報告與部署計畫。
📚 資源:
- AI 雲端架構工作室 – Visual Paradigm:Visual Paradigm AI 雲端架構工作室的官方功能概覽,詳細說明其功能、多雲端支援,以及與 AI 驅動工作流程的整合。
- 革新雲端設計:深入探討 Visual Paradigm 的 AI 雲端架構工作室:對該工具 AI 能力、工作流程及企業雲端架構中實際應用的全面分析。
- AI 雲端架構工作室發布公告:Visual Paradigm 官方發布的版本說明,宣布該工具將於 2026 年 2 月推出,包含主要功能與初始可用性資訊。
- AI 雲端架構工作室 – Visual Paradigm AI 門戶:專為存取 AI 雲端架構工作室而設的網路門戶,提供即時示範、教學影片與使用者指南。
- AI 雲端架構工作室 – Visual Paradigm 的 AI 工具箱:AI 驅動建模工具的中央集散中心,包含對雲端架構工作室及相關 AI 功能的存取。