











Diagram przepływu danych (DFD) pełni rolę podstawowego przedstawienia wizualnego w analizie i projektowaniu systemów. Ilustruje przepływ informacji przez system, podkreślając sposób przemieszczania się danych od wejścia do wyjścia. W przeciwieństwie do schematów blokowych skupiających się na logice sterowania, DFD skupia się na przepływie danych. Niniejszy przewodnik przedstawia metodologię tworzenia dokładnych diagramów bez potrzeby korzystania z określonych narzędzi własnościowych. Proces ten wymaga jasnego myślenia oraz przestrzegania ustalonych standardów notacji.
🧐 Zrozumienie podstawowego celu
Zanim narysuje się linie i kształty, należy zrozumieć cel. DFD modeluje wymagania funkcjonalne systemu. Pokazuje, co system robi, a niekoniecznie jak jest fizycznie zrealizowany. Ta różnica jest kluczowa dla analityków. Pozwala stakeholderom zweryfikować logikę procesów biznesowych bez zagłębiania się w szczegółowe aspekty implementacji technicznej.
Diagram pomaga w identyfikacji:
- Skąd dane pochodzą w obrębie granic systemu.
- Jak dane są przekształcane w użyteczną informację.
- Gdzie dane są przechowywane do późniejszego pobrania.
- Gdzie dane opuszczają system i są przekazywane osobom zewnętrznych.
Poprzez wizualizację tych elementów zespoły mogą wczesnie wykrywać zatory, nadmiarowość lub brakujące ścieżki danych w cyklu rozwoju systemu. Jest on przekładem komunikacyjnym między zespołami technicznymi a użytkownikami biznesowymi.
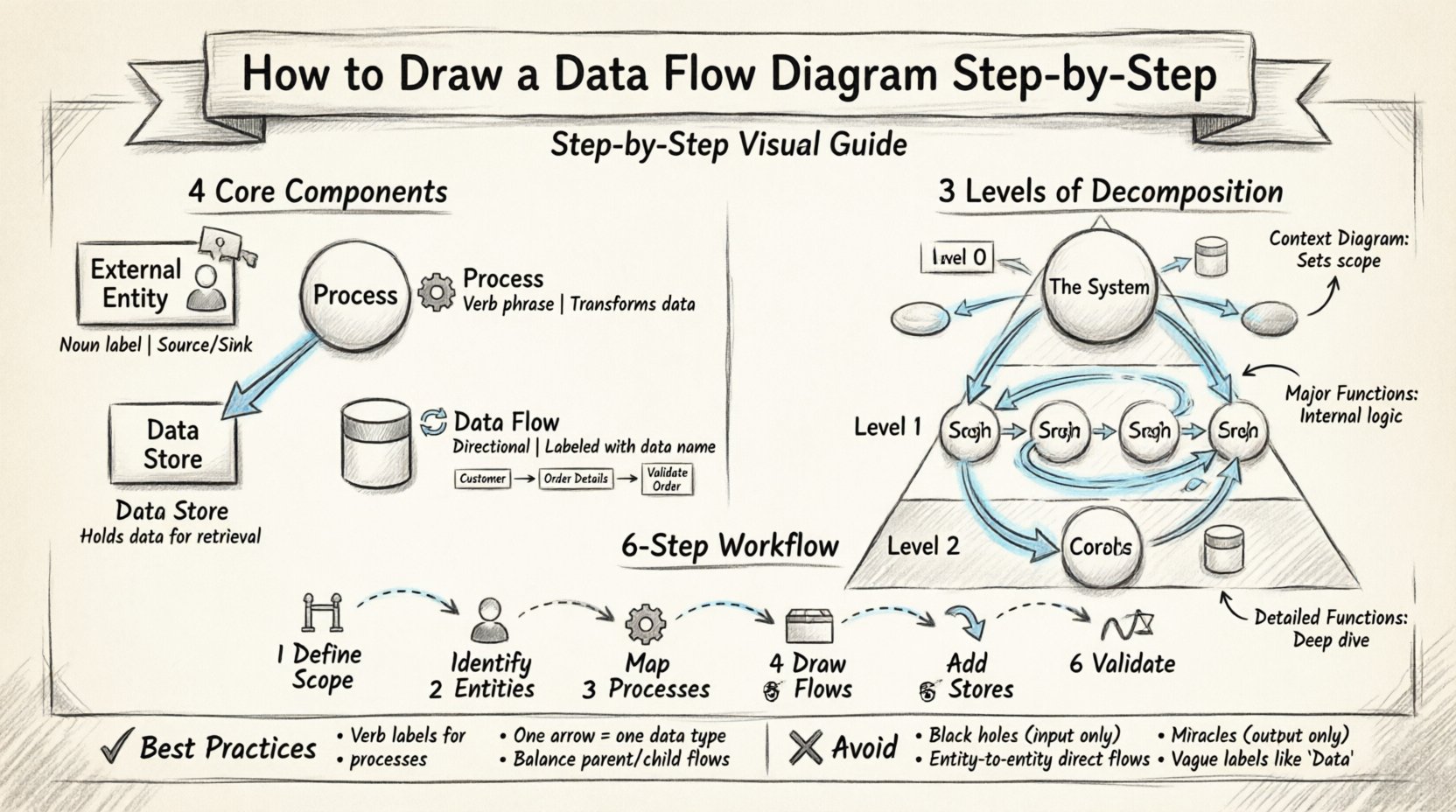
🛠️ Cztery podstawowe elementy
Pełny DFD opiera się na czterech podstawowych symbolach. Każdy narysowany element musi należeć do jednej z tych kategorii. Użycie innych kształtów wprowadza niepewność. Standardowa notacja zwykle opiera się na metodzie Yourdona i DeMarcosa lub metodzie Gane’a i Sarsona. Choć symbole mogą nieco się różnić między tymi stylami, logika podstawowa pozostaje taka sama.
1. Jednostki zewnętrzne 👤
Jednostki zewnętrzne reprezentują źródła lub miejsca docelowe danych poza granicami systemu. Są to akcje interakcji z systemem. Mogą to być osoby, organizacje lub inne systemy.
- Źródło: Jednostka dostarcza dane wejściowe do systemu (np. klient składający zamówienie).
- Odbiornik: Jednostka otrzymuje dane wyjściowe z systemu (np. urzędnik podatkowy otrzymujący raporty).
W diagramie są one zwykle przedstawiane jako prostokąty lub kwadraty. Oznaczane są frazami rzeczownikowymi wskazującymi ich rolę.
2. Procesy ⚙️
Procesy reprezentują działania, które przekształcają dane wejściowe w dane wyjściowe. Są one sercem diagramu. Proces zawsze musi mieć co najmniej jedno wejście i jedno wyjście.
- Przekształcenie: Przekształca dane z jednej postaci w inną (np. przekształcanie surowych danych sprzedaży w raport podsumowujący).
- Oznaczanie: Procesy są zwykle oznaczane frazami czasownikowymi (np. „Oblicz podatek”, „Weryfikuj użytkownika”).
Są często przedstawiane jako okręgi, zaokrąglone prostokąty lub bańki w zależności od standardu notacji.
3. Magazyny danych 📂
Magazyny danych reprezentują miejsca, gdzie informacje są przechowywane do późniejszego użytku. Nie jest to fizyczny plik bazy danych, lecz logiczny magazyn. Dane wpływają do magazynu w celu przechowywania i wypływają do pobrania.
- Otwarte vs. Zamknięte: Dane mogą być odczytywane z magazynu i zapisywane do niego.
- Trwałość: Dane pozostają dostępne nawet jeśli proces, który je utworzył, został zakończony.
Typowe symbole to otwarte prostokąty lub cylindry reprezentujące pliki i bazy danych.
4. Przepływy danych 🔄
Przepływy danych pokazują ruch danych między jednostkami, procesami i magazynami. Są to strzałki kierunkowe.
- Kierunek: Strzałka wskazuje kierunek ruchu danych.
- Zawartość: Każdy przepływ musi być oznaczony konkretnymi danymi przesyłanymi (np. „Szczegóły zamówienia”, „Potwierdzenie płatności”).
- Spójność: Dane nie mogą przepływać między dwiema jednostkami zewnętrznymi bez przechodzenia przez proces.
| Składnik | Kształt symbolu | Typ etykiety | Funkcja |
|---|---|---|---|
| Jednostka zewnętrzna | Prostokąt / Kwadrat | Imię rzeczowe | Źródło lub miejsce docelowe |
| Proces | Okrąg / Prostokąt z zaokrąglonymi rogami | Zdanie czasownika | Przekształć dane |
| Magazyn danych | Otwarty prostokąt / Cylindry | Imię rzeczowe | Przechowuj dane |
| Przepływ danych | Strzałka | Nazwa danych | Przenieś dane |
📈 Poziomy dekompozycji
Złożone systemy nie mogą być zrozumiane w jednym widoku. Diagramy przepływu danych są hierarchiczne. Zaczynasz od ogólnego przeglądu na najwyższym poziomie i stopniowo rozkładasz procesy na bardziej szczegółowe. To nazywane jest dekompozycją.
Poziom 0: Diagram kontekstowy 🌍
Diagram kontekstowy to najwyższy poziom. Pokazuje cały system jako pojedynczy balon procesu. Ilustruje sposób, w jaki system oddziałuje ze światem zewnętrznym.
- W centrum narysowany jest tylko jeden proces.
- Obiekty zewnętrzne otaczają proces.
- Przepływy danych łączą obiekty z pojedynczym procesem.
- Na tym poziomie nie pokazuje się magazynów danych.
Ten diagram określa zakres. Określa granice projektu.
Poziom 1: Główne procesy 🔍
Poziom 1 rozszerza pojedynczy proces z diagramu kontekstowego na główne podprocesy. To tutaj zaczyna się pojawiać logika wewnętrzna.
- Pojedynczy proces staje się grupą 3 do 7 głównych procesów.
- Tutaj wprowadzane są magazyny danych.
- Obiekty zewnętrzne pozostają takie same jak na poziomie 0.
- Przepływy muszą być zrównoważone z wejściami i wyjściami poziomu 0.
Poziom 2: Szczegółowe funkcje 🔬
Poziom 2 rozkłada konkretne procesy z poziomu 1. Używany jest do złożonych operacji, które wymagają dalszego wyjaśnienia.
- Skupia się na jednym procesie z poprzedniego poziomu.
- Pokazuje szczegółową logikę i podkroki.
- Używane, gdy proces poziomu 1 jest zbyt złożony, aby zarządzać nim w jednym widoku.
| Poziom | Skupienie | Procesy | Magazyny danych |
|---|---|---|---|
| Poziom 0 | Zakres systemu | 1 (System) | Brak |
| Poziom 1 | Główne funkcje | 3 do 7 | Tak |
| Poziom 2 | Szczegóły szczegółowe | Zależne od poziomu 1 | Tak |
✍️ Metodologia rysowania krok po kroku
Tworzenie diagramu przepływu danych wymaga systematycznego podejścia. Postępowanie zgodnie z tymi krokami zapewnia spójność i jasność na przestrzeni całego dokumentu.
Krok 1: Zdefiniuj zakres i granice 🚧
Zacznij od identyfikacji tego, co znajduje się wewnątrz systemu, a co poza nim. Ta decyzja określa położenie jednostek zewnętrznych. Wszystko poza granicą to jednostka zewnętrzna. Wszystko wewnątrz to proces, magazyn lub przepływ. Nie dodawaj tutaj szczegółów implementacji, takich jak sprzęt czy kod.
Krok 2: Zidentyfikuj jednostki zewnętrzne 👥
Wypisz wszystkie strony, które oddziałują z systemem. Zadaj pytania takie jak:
- Kto przesyła informacje do systemu?
- Kto otrzymuje raporty lub dane wyjściowe z systemu?
- Czy istnieją inne systemy wymieniające dane z tym systemem?
Narysuj te jednostki wokół obwodu obszaru pracy. Używaj jasnych, opisowych nazw.
Krok 3: Określ główne procesy ⚙️
Zidentyfikuj główne funkcje, które system musi wykonywać w celu przekształcenia danych wejściowych w wyjściowe. Połącz powiązane działania. Na przykład „Zarządzanie zamówieniami” może być głównym procesem, który zawiera „Weryfikacja zamówienia” i „Aktualizacja magazynu” jako podprocesy.
- Utrzymuj liczbę procesów możliwą do zarządzania (idealnie poniżej 7 na poziomie 1).
- Upewnij się, że każdy proces ma jasne przeznaczenie.
- Oznacz procesy czasownikami (na przykład „Przetwarzanie płatności”).
Krok 4: Zmapuj przepływy danych 🔄
Narysuj strzałki łączące jednostki z procesami oraz procesy z procesami. Każda strzałka musi mieć etykietę opisującą dane.
- Sprawdź, czy dane poruszają się logicznie.
- Upewnij się, że żaden przepływ nie przekracza granicy systemu bez przechodzenia przez proces.
- Oznacz przepływy konkretnymi pakietami danych (na przykład „ID klienta”, a nie tylko „Dane”).
Krok 5: Dodaj magazyny danych 📂
Zidentyfikuj, gdzie musi być przechowywana informacja. Jeśli dane będą potrzebne później, muszą trafić do magazynu.
- Połącz magazyny z procesami, które do nich odczytują lub zapisują dane.
- Upewnij się, że dane przepływają do magazynu, aby je zapisać.
- Upewnij się, że dane wychodzą z magazynu, aby je użyć.
Krok 6: Weryfikacja i zrównoważenie ⚖️
To najważniejszy krok techniczny. Zrównoważenie zapewnia, że wejścia i wyjścia procesu nadrzędnego odpowiadają wejściom i wyjściom jego diagramu potomka (poziom niżej).
- Jeśli poziom 0 ma wejście „Zamówienie”, poziom 1 również musi pokazywać „Zamówienie” wpływające do głównego procesu.
- Jeśli poziom 1 dzieli proces, podprocesy muszą obsługiwać te same dane wejściowe i wyjściowe co proces nadrzędny.
- Sprawdź istnienie procesów sierot (procesów bez przepływu danych).
- Sprawdź istnienie niezależnych magazynów danych (magazynów bez przepływu danych wejściowych lub wyjściowych).
🧠 Najlepsze praktyki i zasady
Przestrzeganie rygorystycznych zasad zapobiega zamieszaniu. Odstępstwa mogą prowadzić do nieprawidłowego rozumienia logiki systemu.
1. Zasady nazewnictwa 🏷️
Spójność jest kluczowa. Używaj standardowego schematu nazewnictwa dla wszystkich elementów.
- Obiekty: liczba mnoga rzeczowników (np. „Klienci”, „Dostawcy”).
- Procesy: frazy z czasownikiem (np. „Aktualizuj inwentarz”).
- Magazyny: rzeczowniki (np. „Plik inwentarza”).
- Przepływy: nazwy danych (np. „Aktualizacja stanu magazynowego”).
2. Unikaj logiki sterowania 🚫
Diagramy przepływu danych nie są schematami blokowymi. Nie dodawaj diamentów decyzyjnych ani pętli reprezentujących przepływ sterowania. Jeśli decyzja wpływa na przepływ danych, przedstaw ją poprzez podział przepływu na różne ścieżki oparte na treści danych, a nie na warunku logicznym.
3. Jedna strzałka, jeden pakiet danych
Nie łącz wielu rodzajów danych w jedną strzałkę. Jeśli proces wysyła zarówno „Dane zamówienia”, jak i „Dane płatności”, narysuj dwie osobne strzałki.
4. Brak bezpośrednich przepływów między obiektami zewnętrznymi
Dane nie mogą bezpośrednio przechodzić z jednego obiektu zewnętrznego do drugiego bez przechodzenia przez system. Jeśli tak się dzieje, oznacza to, że system jest pomijany, albo zakres diagramu jest niepoprawny.
5. Unikaj czarnych dziur i milionów
- Czarna dziura: Proces, który ma wejścia, ale nie ma wyjść. Dane znikają. Jest to niemożliwe.
- Milion: Proces, który ma wyjścia, ale nie ma wejść. Dane pojawiają się znikąd. Jest to niemożliwe.
⚠️ Powszechne błędy do uniknięcia
Nawet doświadczeni analitycy popełniają błędy. Znajomość typowych pułapek oszczędza czas podczas przeglądów.
Błąd 1: Mieszanie poziomów
Połączenie szczegółów poziomu 0 i poziomu 1 na tej samej stronie powoduje zamieszanie. Zachowaj każdy poziom osobno, aby zachować przejrzystość.
Błąd 2: Niespójna kierunek przepływu
Upewnij się, że strzałki wskazują w poprawnym kierunku. Powszechnym błędem jest rysowanie strzałki od magazynu do procesu, gdy proces faktycznie zapisuje dane do magazynu.
Błąd 3: Nieprecyzyjne etykiety
Unikaj etykiet takich jak „Informacje”, „Dane” lub „Szczegóły”. Bądź konkretny. „Dane klienta” jest lepsze. „Dane” są bezużyteczne w analizie.
Błąd 4: Ignorowanie magazynów danych
Pomijanie magazynów danych prowadzi do niekompletnego modelu. Jeśli dane są używane później, muszą być przechowywane. Nieuwzględnienie magazynów sugeruje system bez stanu, co rzadko jest poprawne dla złożonych aplikacji.
🔍 Zaawansowane rozważania
Wraz z rozwojem systemów, DFD wymagają bardziej rygorystycznego utrzymania. Rozważ następujące aspekty w większych projektach.
Działanie fizyczne w porównaniu do logicznego DFD
- Logiczny DFD: Skupia się na wymaganiach biznesowych. Ignoruje szczegóły implementacji technicznej, takie jak pliki papierowe w porównaniu do baz danych.
- Fizyczny DFD: Odbija rzeczywistą implementację. Określa sprzęt, oprogramowanie i typy plików.
Najlepszą praktyką jest stworzenie najpierw logicznego DFD w celu uzgodnienia wymagań, a następnie wyprowadzenie fizycznego DFD do celów rozwoju.
Zrównoleglenie i czas
Standardowe DFD nie pokazują czasu ani zrównoleglenia. Pokazują, co się dzieje, a nie kiedy. W systemach, gdzie czas jest krytyczny, mogą być wymagane inne techniki modelowania, takie jak diagramy przejść stanów, obok DFD.
Bezpieczeństwo i kontrola dostępu
Choć DFD nie pokazują jawnie protokołów bezpieczeństwa, przepływy danych powinny wskazywać na poufne informacje. Przepływy zawierające „Hasło” lub „Numer karty kredytowej” powinny być zaznaczone. Pomaga to architektom bezpieczeństwa w identyfikacji miejsc, gdzie potrzebna jest szyfrowanie.
📝 Podsumowanie przepływu pracy
Tworzenie diagramu przepływu danych to dyscyplinowane ćwiczenie myślenia systemowego. Wymaga rozkładania złożonego systemu na zarządzalne części, zachowując przy tym integralność przepływu danych. Proces przemieszcza się od makrowidoku diagramu kontekstowego do mikrowidoku szczegółowych procesów.
Sukces zależy od:
- Jasne określenie granic.
- Spójne oznaczanie składników.
- Ścisłe przestrzeganie zasad równowagi.
- Weryfikacja z zaangażowanymi stronami.
Śledząc te kroki i unikając powszechnych pułapek, tworzysz wiarygodny projekt dla rozwoju systemu. Ten dokument stanowi fundament dla projektowania baz danych, architektury oprogramowania i inicjatyw poprawy procesów. Pozostaje niezastąpionym narzędziem do zrozumienia, jak informacje przepływają przez każdy zorganizowany system.