











Die Datenmodellierung ist die Grundlage jeder robusten Datenbankarchitektur. Während die Theorie oft in universitären Kursen vermittelt wird, offenbart die praktische Anwendung in Produktionsumgebungen ein Gebiet voller Sonderfälle, Leistungsengpässe und logischer Unklarheiten. Entity-Relationship-Diagramme (ERDs) dienen als Baupläne für diese Systeme, werden jedoch oft zu Quellen von Streitigkeiten, wenn die Realität sich nicht sauber in Kästchen und Linien fügen lässt.
Wir haben mit einer Runde leitender Datenbankadministratoren und Datenarchitekten gesprochen, um die Szenarien zu analysieren, die Teams bei der Entwurfsphase regelmäßig herausfordern. Es handelt sich hierbei nicht um theoretische Übungen, sondern um Probleme, die entstehen, wenn geschäftliche Anforderungen mit physischen Speicherbeschränkungen kollidieren. Ziel ist es nicht, eine schnelle Lösung anzubieten, sondern ein tiefes Verständnis der dabei involvierten Kompromisse zu vermitteln.
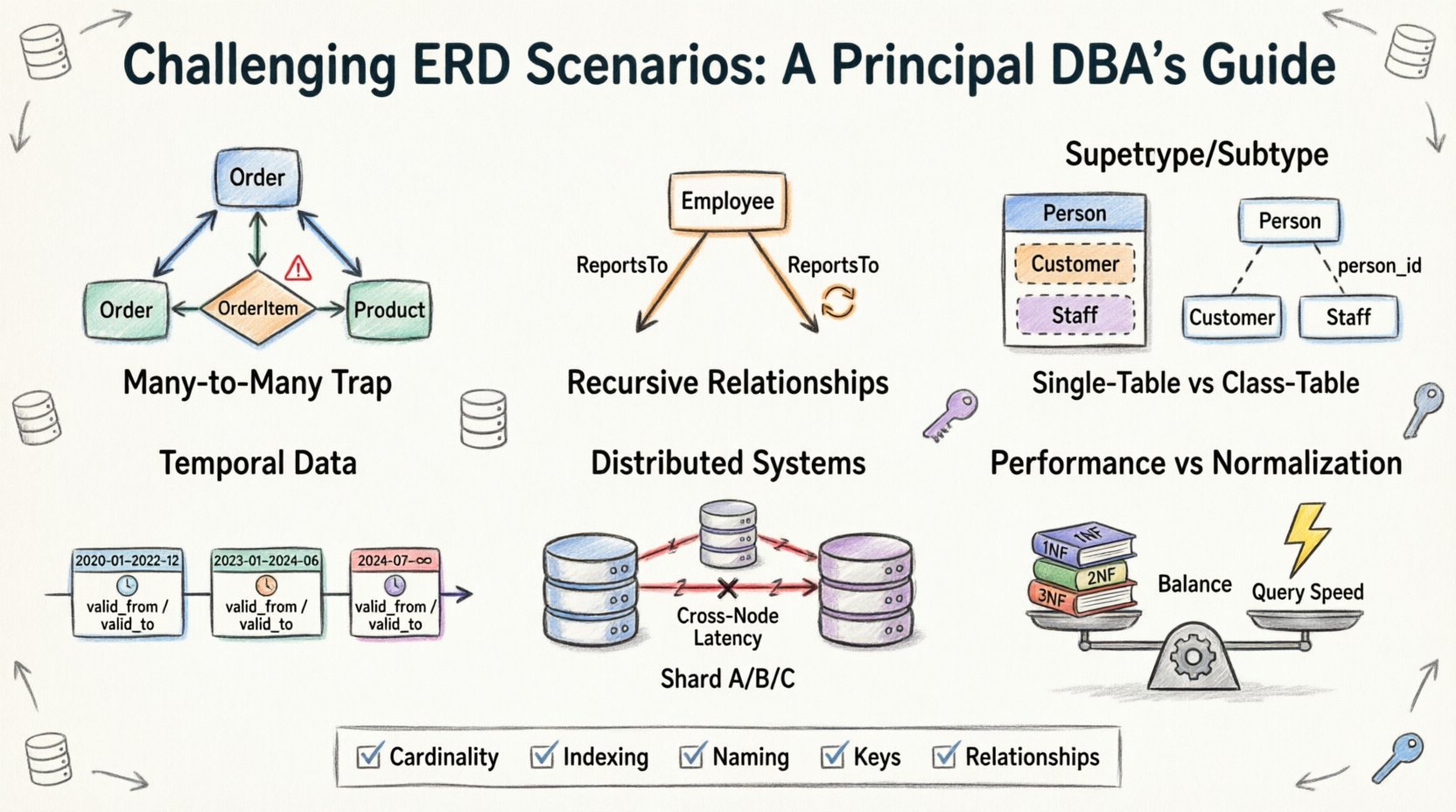
1. Die Many-to-Many-Falle: Weiter als einfache Join-Tabellen 🕸️
Der häufigste Ausgangspunkt bei der ERD-Entwicklung ist die Many-to-Many-Beziehung. Es scheint intuitiv: Ein Student kann sich in vielen Kursen einschreiben, und ein Kurs kann viele Studenten haben. Die Standardlösung sieht eine Brückentabelle oder assoziative Tabelle vor. Die Komplexität entsteht jedoch, wenn Attribute direkt in die Beziehung selbst eingefügt werden.
- Das Problem:Oft versuchen Teams, Einschreibungsdaten (wie Noten oder Anmeldedaten) in der Haupttabelle für Studenten oder Kurse zu speichern, was zu massiver Redundanz oder Nullwerten führt.
- Die Realität:Die Beziehung selbst ist eine Entität. Sie muss über einen eigenen Primärschlüssel und Fremdschlüssel verfügen, die auf die Eltern verweisen.
- Die Herausforderung:Behandlung von kaskadierenden Löschvorgängen. Wenn ein Kurs entfernt wird, was geschieht mit den Einschreibungsdaten? Wenn eine Einschreibung gelöscht wird, verschwindet dann der Student? Diese Entscheidungen definieren die Datenintegrität.
Während unserer Diskussion stellte ein leitender DBA fest, dass die assoziative Tabelle oft zu einer Leistungsbremse wird. Beim Abfragen von Daten über diese Verbindung muss die Datenbankengine eine Join-Operation durchführen, die sich schlecht skaliert, wenn die Zeilenzahl in die Millionen wächst. Die Lösung ist nicht immer architektonisch; manchmal erfordert sie eine Denormalisierung, was jedoch Aktualisierungsanomalien verursacht.
Wichtige Überlegungen bei Many-to-Many:
- Hat die Beziehung Attribute, die indiziert werden müssen?
- Ist die Beziehung aktuell oder historisch? (z. B. unterscheidet sich eine aktuelle Einschreibung von einer vergangenen?)
- Wie wird das System Orphan-Records behandeln, wenn ein Elternteil gelöscht wird?
2. Rekursive Beziehungen: Selbstreferenzierende Hierarchien 🌳
Hierarchische Daten gibt es überall. Denken Sie an eine Organigramm, eine Stückliste oder einen Kommentarverlauf in einem Forum. Die Modellierung erfordert eine Tabelle, die sich selbst referenziert. Obwohl dies konzeptionell einfach erscheint, führt die Implementierung in einer relationalen Struktur zu spezifischen Herausforderungen hinsichtlich Tiefe und Durchlauf.
Das strukturelle Problem:
Sie erstellen eine Tabelle mit einem Primärschlüssel und einer Fremdschlüsselspalte, die auf den Primärschlüssel derselben Tabelle verweist. Diese Spalte wird oft als „parent_id“ bezeichnet. Der Wurzelknoten hat einen null-Wert für das Elternteil.
Das Leistungsproblem:
Standard-SQL-Abfragen haben Schwierigkeiten mit tiefen Hierarchien. Wenn Sie einen Manager und alle dessen direkten und indirekten Untergebenen abrufen müssen, reicht ein einfacher JOIN nicht aus. Sie benötigen rekursive Common Table Expressions (CTEs) oder gespeicherte Prozeduren, die die Ebenen durchlaufen. Dies kann rechnerisch kostspielig sein.
Das Integritätsproblem:
Zirkuläre Referenzen sind eine stille Gefahr. Wenn Mitarbeiter A Mitarbeiter B verwaltet und Mitarbeiter B Mitarbeiter A verwaltet, entsteht eine Schleife. Die Datenbank muss dies verhindern, oder die Anwendungslogik muss es erkennen. In großen Systemen kann eine Schleife eine endlose Schleife in Berichtswerkzeugen verursachen.
- Tiefenbegrenzungen:Die meisten Systeme begrenzen die Hierarchietiefe (z. B. auf 32 Ebenen), um Stack-Overflow-Fehler beim Durchlaufen zu vermeiden.
- Pfadaggregation:Die Berechnung der Gesamtkosten oder der Anzahl eines Teilbaums erfordert rekursive Logik, die sich in Standard-Abfrageplänen schwer optimieren lässt.
3. Supertyp- und Subtyp-Modellierung: Das Vererbungs-Dilemma 🧬
In der objektorientierten Programmierung ist Vererbung Standard. In relationalen Datenbanken ist sie eine Gestaltungsoption, die Speicherung und Abruf beeinflusst. Die Frage lautet: Modellieren Sie ein Fahrzeug als eine einzige Tabelle oder teilen Sie es in Fahrzeug, Auto und LKW auf?
Option A: Einzeltabellenvererbung
Alle Attribute für alle Untertypen befinden sich in einer einzigen Tabelle. Nullwerte werden für nicht verwendete Attribute verwendet.
- Vorteile:Einfache Abfragen, keine Joins erforderlich, um ein Fahrzeug zu finden.
- Nachteile:Tabellenüberlastung, schwer zu durchsetzende, typspezifische Einschränkungen, viele spaltenweise nullbare Felder.
Option B: Klassentabellenvererbung
Eine Tabelle für den OberTyp (Fahrzeug) und separate Tabellen für die Untertypen (Auto, LKW), die über den Primärschlüssel verknüpft sind.
- Vorteile:Saubere Trennung, keine Nullwerte, strenge Einschränkungen pro Untertyp.
- Nachteile:Die Abfrage erfordert das Verknüpfen mehrerer Tabellen, was die Leseleistung beeinträchtigen kann.
Unsere Haupt-DBAs wiesen darauf hin, dass die Wahl oft von den Abfragemustern abhängt. Wenn Sie häufig bestimmte Untertypen abfragen, ist der Klassentabellenansatz besser. Wenn Sie häufig alle Untertypen aggregieren, gewinnt der Einzeltabellenansatz. Das ERD muss diese Entscheidung eindeutig widerspiegeln, um zukünftige Entwickler vor Verwirrung zu bewahren.
4. Temporale Daten: Verfolgung von Änderungen im Zeitverlauf ⏳
Geschäftsregeln ändern sich. Ein Kunde zieht um, ein Preis wird aktualisiert, ein Vertrag läuft ab. Die Speicherung nur des „aktuellen“ Zustands ist oft für Audits oder Berichterstattung unzureichend. Dies führt zur Gestaltung temporaler Tabellen oder langsam veränderlicher Dimensionen (SCD).
Die Komplexität:
Anstatt eine Zeile zu aktualisieren, fügen Sie eine neue Zeile mit einem gültigen Start- und Enddatum ein. Die alte Zeile wird als inaktiv markiert. Dies verdoppelt die Speicheranforderung für historische Daten und kompliziert die Abfrage für die „aktuelle Ansicht“.
Die Abfrage-Herausforderung:
Die Auswahl von Daten „zum Zeitpunkt“ eines bestimmten Zeitpunkts erfordert eine Filterung nach dem Datumsbereich. Wenn Sie die Logik für den Datumsbereich übersehen, könnten Sie die falsche Version einer Aufzeichnung zurückgeben. Dies ist oft der Punkt, an dem Integritätsprobleme in Finanzanwendungen auftreten.
- Snapshot-Design:Speichern Sie den Zustand zu einem bestimmten Zeitpunkt. Erfordert periodische Batch-Jobs, um Snapshots zu schreiben.
- Transaktionsprotokoll-Design:Erfassen Sie jede Änderung. Hoher Schreibvolumen, komplexe Abruflogik.
- Periodisches Design:Speichern Sie gültige Intervalle. Behandelt Zeitlücken gut, erfordert aber sorgfältige Grenzverwaltung.
5. Verteilte Systeme: Sharding und Beziehungen 🔗
Wenn eine einzelne Datenbank die Daten nicht mehr aufnehmen kann, wird Sharding notwendig. Hier trifft das ERD-Design auf seine schwersten physischen Einschränkungen. Beziehungen, die Sharding-Grenzen überschreiten, sind kostspielig.
Das Join-Problem:
Wenn Tabelle A nach Benutzer-ID shardet und Tabelle B mit Tabelle A verknüpft ist, muss Tabelle B ebenfalls nach derselben Benutzer-ID shardet werden, um verteilte Joins zu vermeiden. Wenn Tabelle B nach etwas anderem shardet, müssen Sie die Abfrage an mehrere Shards weiterleiten, die Ergebnisse aggregieren und lokal joinen.
Referenzielle Integrität:
Fremdschlüsselbeschränkungen sind schwer über verteilte Knoten hinweg durchzusetzen. Viele Systeme deaktivieren Fremdschlüssel in sharded-Umgebungen, um die Verfügbarkeit zu gewährleisten. Dies verlagert die Verantwortung für die Integrität auf die Anwendungsebene, die anfällig für Race-Conditions ist.
Wichtige Erkenntnisse für verteilte ERDs:
- Vermeiden Sie viele-zu-viele-Beziehungen, die mehrere Shards überbrücken.
- Normalisieren Sie Daten nicht, um den Bedarf an Join-Operationen über Knoten hinweg zu reduzieren.
- Entwerfen Sie den Partitionsschlüssel (Sharding-Schlüssel) basierend auf den häufigsten Abfragemustern, nicht nur auf dem Primärschlüssel.
6. Leistung vs. Normalisierung: Das Gleichgewicht der Kompromisse ⚖️
Die Normalisierung (1NF, 2NF, 3NF) wird als Goldstandard für Datenintegrität vermittelt. In Systemen mit hoher Durchsatzrate kann jedoch eine strikte Normalisierung die Leistung beeinträchtigen. Das ERD muss beide Aspekte ausbalancieren.
Wann sollte man nicht normalisieren:
- Leseintensive Workloads: Wenn Sie Daten viel häufiger lesen als schreiben, spart das Hinzufügen redundanter Spalten Join-Operationen.
- Berichterstattungsanforderungen:Aggregationen auf normalisierten Daten erfordern komplexe Joins, die Dashboards verlangsamen.
- Schreibintensive Workloads:Manchmal reduziert die Trennung von Daten die Sperrkonflikte während Aktualisierungen.
Unser Panel betonte, dass es kein „perfektes“ Schema gibt. Es ist ein Kompromiss. Ein ERD sollte dokumentieren, wo die Nicht-Normalisierung erfolgt und warum, damit zukünftige Wartende verstehen, dass die Redundanz bewusst ist, nicht ein Fehler.
Vergleich von Modellierungsmustern 📊
Zur Unterstützung der Entscheidungsfindung finden Sie hier eine Zusammenfassung der besprochenen Modellierungsmuster und ihrer typischen Einsatzfälle.
| Muster | Beste Anwendungssituation | Hauptrisiko | Komplexität |
|---|---|---|---|
| Einzelne Tabelle | Einfache Hierarchien, geringe Vielfalt | Null-Felder, Schema-Bloat | Niedrig |
| Klassentabelle | Strenge Untertypen, unterschiedliche Attribute | Join-Aufwand | Mittel |
| Rekursiv | Organigramme, Kategorien | Durchlauftiefe, Zyklen | Hoch |
| Assoziatives Entität | Viele-zu-Viele mit Attributen | Join-Leistung | Mittel |
| Temporär | Auditing, Verlaufserfassung | Abfragekomplexität | Hoch |
| Verteiltes Sharding | Massive Skalierung, horizontales Wachstum | Referenzielle Integrität | Sehr hoch |
Prüfliste für die ERD-Überprüfung ✅
Bevor Sie ein Entitäts-Beziehungs-Diagramm endgültig festlegen, verwenden Sie diese Prüfliste, um häufige Fehler zu erkennen. Es ist besser, diese Probleme in der Entwurfsphase zu erkennen, als in der Produktion.
- Kardinalität: Haben Sie eindeutig die Eins-zu-Eins-, Eins-zu-Viele- und Viele-zu-Viele-Beziehungen definiert? Sind die Mindest- und Höchstgrenzen (0..1, 1..*) explizit angegeben?
- Daten-Typen: Sind die Spaltentypen für die erwartete Datenmenge geeignet? (z. B. Integer gegenüber Varchar für IDs).
- Nullbarkeit: Sind Fremdschlüssel nullbar? Wenn ja, behandelt die Logik verwaiste Verweise angemessen?
- Indizierungsstrategie: Zeigt das ERD an, welche Spalten für die Leistungsoptimierung indiziert werden müssen? Fremdschlüssel werden oft indiziert, um Joins zu beschleunigen.
- Namenskonventionen: Sind Tabellen- und Spaltennamen konsistent? Vermeiden Sie Abkürzungen, die später missverständlich sein könnten.
- Geschäftsregeln: Werden Einschränkungen (z. B. „Ein Benutzer kann keine zwei aktiven Abonnements haben“) als logische Prüfungen oder Datenbankbeschränkungen dargestellt?
- Erweiterbarkeit: Kann das Schema neue Attribute aufnehmen, ohne eine vollständige Migration zu erfordern? (z. B. unter Verwendung eines EAV-Musters oder JSON-Spalten, wo angebracht).
Abschließende Gedanken zur Datenmodellierung 🧠
Das Erstellen eines Entitäts-Beziehungs-Diagramms geht nicht nur darum, Kästchen und Linien zu zeichnen. Es geht darum, den Datenfluss zu verstehen, die Beschränkungen der Hardware und die Bedürfnisse des Geschäfts zu berücksichtigen. Die hier besprochenen Szenarien repräsentieren die Reibungspunkte, an denen Theorie auf Praxis trifft.
Durch die Vorabberücksichtigung dieser Herausforderungen – rekursive Tiefe, verteilte Joins, zeitliche Historie und Abstraktionskompromisse bei Vererbung – können Sie resilient gestaltete Schemata erstellen. Ein gut durchdachtes ERD reduziert technische Schulden und verhindert die Notwendigkeit kostspieliger Umgestaltungen in der Zukunft. Es ist eine Investition in die Stabilität des gesamten Systems.
Denken Sie daran, dass das beste Schema das ist, das sich mit den Daten entwickelt. Dokumentation ist entscheidend. Stellen Sie sicher, dass jede Abweichung von der Standardnormalisierung gerechtfertigt und dokumentiert ist. Diese Transparenz ist es, die eine robuste Datenbankarchitektur von einer fragilen unterscheidet.