











Mô hình hóa dữ liệu là nền tảng của bất kỳ kiến trúc cơ sở dữ liệu nào mạnh mẽ. Mặc dù lý thuyết thường được giảng dạy trong các khóa học đại học, nhưng việc áp dụng thực tế trong môi trường sản xuất lại phơi bày một bức tranh đầy những trường hợp đặc biệt, điểm nghẽn hiệu suất và những mâu thuẫn logic. Các sơ đồ quan hệ thực thể (ERD) đóng vai trò như bản vẽ thiết kế cho các hệ thống này, nhưng chúng thường trở thành nguồn gây tranh cãi khi thế giới thực từ chối nằm gọn trong những hình vuông và đường thẳng.
Chúng tôi đã ngồi trò chuyện cùng một nhóm các Trưởng nhóm Quản trị Cơ sở Dữ liệu cấp cao và Kiến trúc sư Dữ liệu để phân tích những tình huống thường xuyên làm khó các đội ngũ trong giai đoạn thiết kế. Những vấn đề này không phải là bài tập lý thuyết; chúng xuất hiện khi các yêu cầu kinh doanh va chạm với các giới hạn về lưu trữ vật lý. Mục tiêu ở đây không phải là đưa ra giải pháp nhanh chóng, mà là cung cấp sự hiểu biết sâu sắc về những thỏa hiệp cần thiết.
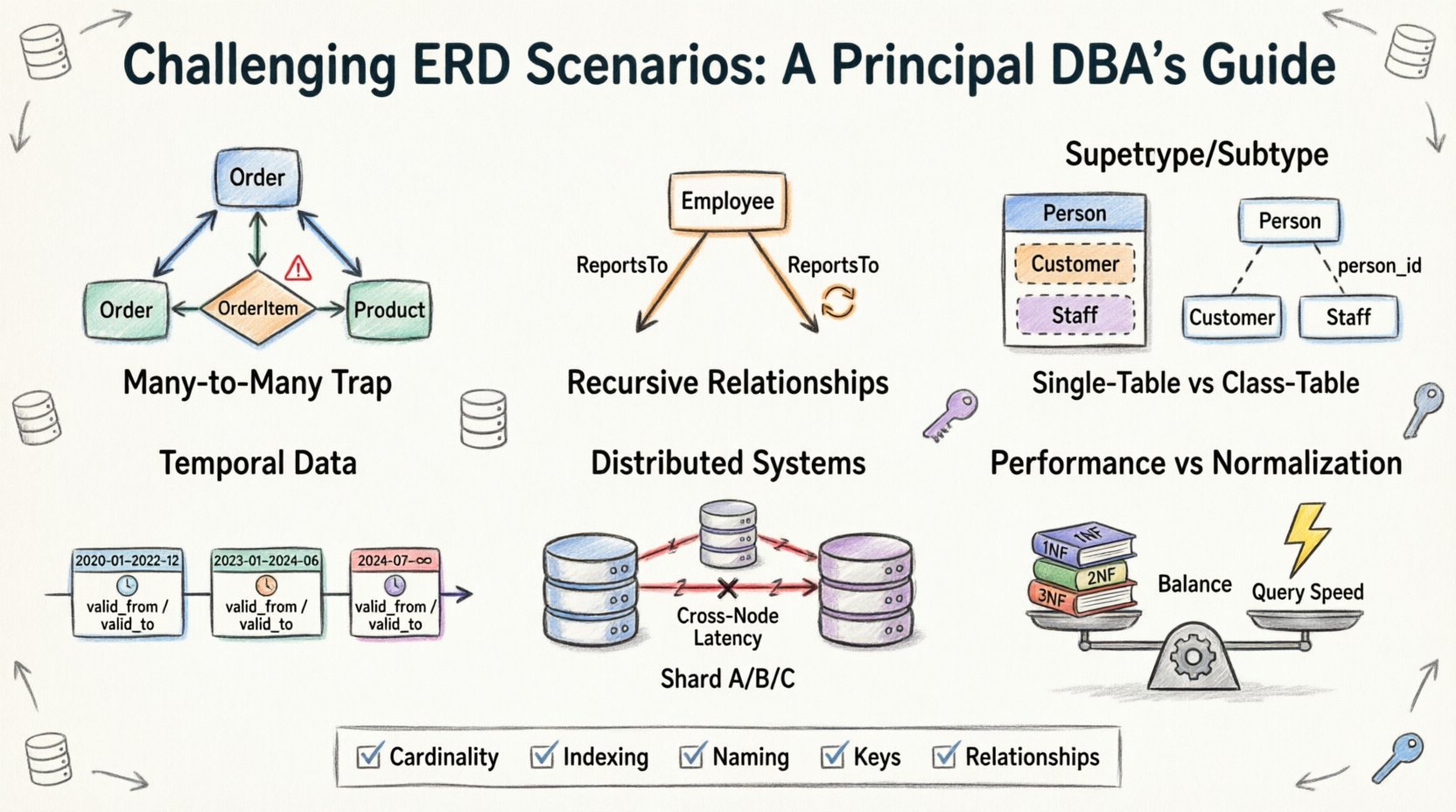
1. Bẫy Nhiều-Đa: Vượt ra ngoài các bảng nối đơn giản 🕸️
Điểm khởi đầu phổ biến nhất trong thiết kế ERD là mối quan hệ Nhiều-Đa. Có vẻ trực quan: một Sinh viên có thể đăng ký nhiều Khóa học, và một Khóa học có thể có nhiều Sinh viên. Giải pháp tiêu chuẩn bao gồm một bảng cầu nối hoặc bảng liên kết. Tuy nhiên, độ phức tạp nảy sinh khi các thuộc tính được đưa vào chính mối quan hệ.
- Vấn đề:Thường xuyên, các đội cố gắng lưu trữ dữ liệu đăng ký (như điểm số hoặc ngày đăng ký) vào bảng Sinh viên hoặc Khóa học chính, dẫn đến sự trùng lặp lớn hoặc các giá trị rỗng.
- Thực tế:Chính mối quan hệ đó là một thực thể. Nó phải có khóa chính riêng và các khóa ngoại trỏ trở lại các thực thể cha.
- Thách thức:Xử lý xóa lan truyền. Nếu một Khóa học bị xóa, các bản ghi Đăng ký sẽ ra sao? Nếu một bản ghi Đăng ký bị xóa, sinh viên có biến mất không? Những quyết định này định nghĩa tính toàn vẹn dữ liệu.
Trong cuộc thảo luận của chúng tôi, một Trưởng nhóm DBA nhận xét rằng bảng liên kết thường trở thành điểm nghẽn hiệu suất. Khi truy vấn dữ liệu qua điểm giao nhau này, bộ xử lý cơ sở dữ liệu phải thực hiện thao tác nối, điều này có thể không mở rộng tốt khi số lượng hàng tăng lên hàng triệu. Giải pháp không phải lúc nào cũng nằm ở kiến trúc; đôi khi cần phải loại bỏ chuẩn hóa, nhưng điều đó lại dẫn đến các bất thường khi cập nhật.
Những yếu tố cần cân nhắc cho mối quan hệ Nhiều-Đa:
- Mối quan hệ này có các thuộc tính cần được lập chỉ mục không?
- Mối quan hệ này là hiện tại hay lịch sử? (ví dụ: việc đăng ký hiện tại có khác với việc đăng ký trong quá khứ không?)
- Hệ thống sẽ xử lý các bản ghi bị mồ côi như thế nào nếu một thực thể cha bị xóa?
2. Mối quan hệ đệ quy: Các cấu trúc phân cấp tự tham chiếu 🌳
Dữ liệu phân cấp hiện diện ở khắp nơi. Hãy nghĩ đến sơ đồ tổ chức, danh sách vật liệu, hoặc một chuỗi bình luận trên diễn đàn. Việc mô hình hóa điều này đòi hỏi một bảng phải tham chiếu chính nó. Mặc dù về mặt khái niệm đơn giản, nhưng việc triển khai trong lược đồ quan hệ lại mang lại những thách thức cụ thể liên quan đến độ sâu và thao tác duyệt.
Vấn đề cấu trúc:
Bạn tạo một bảng với khóa chính và một cột khóa ngoại trỏ trở lại khóa chính của chính bảng đó. Cột này thường được gọi là cột ‘parent_id’. Nút gốc có giá trị cha là rỗng.
Vấn đề hiệu suất:
Các truy vấn SQL tiêu chuẩn gặp khó khăn với các cấu trúc phân cấp sâu. Nếu bạn cần lấy ra một quản lý cùng tất cả các cấp trực tiếp và gián tiếp dưới quyền, một lệnh JOIN đơn giản là không đủ. Bạn cần sử dụng các Biểu thức Bảng Chung đệ quy (CTE) hoặc các thủ tục lưu trữ lặp qua từng cấp. Điều này có thể tốn kém về mặt tính toán.
Vấn đề toàn vẹn:
Các tham chiếu vòng tròn là kẻ giết người thầm lặng. Nếu Nhân viên A quản lý Nhân viên B, và Nhân viên B quản lý Nhân viên A, bạn sẽ có một chu kỳ. Cơ sở dữ liệu phải ngăn chặn điều này, hoặc logic ứng dụng phải phát hiện nó. Trong các hệ thống lớn, một chu kỳ có thể gây ra vòng lặp vô hạn trong công cụ báo cáo.
- Giới hạn độ sâu:Hầu hết các hệ thống giới hạn độ sâu của cấu trúc phân cấp (ví dụ: 32 cấp) để ngăn lỗi tràn ngăn xếp trong quá trình duyệt.
- Tổng hợp đường đi:Việc tính toán tổng chi phí hoặc số lượng của một nhánh cây con đòi hỏi logic đệ quy, điều này khó tối ưu hóa trong các kế hoạch truy vấn tiêu chuẩn.
3. Mô hình hóa Siêu loại và Tiểu loại: Bế tắc kế thừa 🧬
Trong lập trình hướng đối tượng, kế thừa là điều chuẩn. Trong cơ sở dữ liệu quan hệ, đó là một lựa chọn thiết kế ảnh hưởng đến lưu trữ và truy xuất. Câu hỏi đặt ra là: bạn có mô hình hóa một phương tiện thành một bảng duy nhất, hay chia nó thành các bảng Phương tiện, Xe ô tô và Xe tải?
Tùy chọn A: Kế thừa bảng đơn
Tất cả các thuộc tính cho tất cả các kiểu con đều nằm trong một bảng. Các giá trị null được sử dụng cho các thuộc tính không dùng đến.
- Ưu điểm:Truy vấn đơn giản, không cần nối bảng để tìm bất kỳ phương tiện nào.
- Nhược điểm:Bảng bị phình to, khó áp dụng các ràng buộc cụ thể theo kiểu con, nhiều cột có thể để trống.
Tùy chọn B: Kế thừa bảng lớp
Một bảng cho siêu kiểu (Phương tiện), và các bảng riêng biệt cho các kiểu con (Xe ô tô, Xe tải) được liên kết bằng khóa chính.
- Ưu điểm:Tách biệt rõ ràng, không có giá trị null, ràng buộc nghiêm ngặt cho từng kiểu con.
- Nhược điểm:Truy vấn yêu cầu nối nhiều bảng, có thể ảnh hưởng đến hiệu suất đọc.
Các chuyên gia DBA cấp cao của chúng tôi nhấn mạnh rằng lựa chọn thường phụ thuộc vào mẫu truy vấn. Nếu bạn thường xuyên truy vấn các kiểu con cụ thể, cách tiếp cận bảng lớp sẽ tốt hơn. Nếu bạn thường xuyên tổng hợp tất cả các kiểu con, cách tiếp cận bảng đơn sẽ thắng. Sơ đồ ERD phải phản ánh rõ ràng quyết định này để tránh gây nhầm lẫn cho các nhà phát triển trong tương lai.
4. Dữ liệu thời gian: Theo dõi thay đổi theo thời gian ⏳
Các quy tắc kinh doanh thay đổi. Một khách hàng di chuyển, giá cả cập nhật, hợp đồng hết hạn. Việc lưu trữ chỉ trạng thái ‘hiện tại’ thường không đủ cho mục đích kiểm toán hoặc báo cáo. Điều này dẫn đến việc thiết kế các bảng thời gian hoặc các chiều thay đổi chậm (SCD).
Độ phức tạp:
Thay vì cập nhật một hàng, bạn chèn một hàng mới với ngày bắt đầu và kết thúc hiệu lực. Hàng cũ được đánh dấu là không hoạt động. Điều này làm gấp đôi dung lượng lưu trữ cho dữ liệu lịch sử và làm phức tạp truy vấn ‘xem hiện tại’.
Thách thức truy vấn:
Lấy dữ liệu ‘tại thời điểm’ cụ thể yêu cầu lọc theo khoảng ngày. Nếu bạn bỏ sót logic khoảng ngày, bạn có thể trả về phiên bản sai của một bản ghi. Đây thường là nơi các vấn đề toàn vẹn dữ liệu xuất hiện trong các ứng dụng tài chính.
- Thiết kế bản chụp:Lưu trạng thái tại một thời điểm cụ thể. Yêu cầu các tác vụ hàng loạt định kỳ để ghi bản chụp.
- Thiết kế nhật ký giao dịch:Ghi lại mọi thay đổi. Tốc độ ghi cao, logic truy xuất phức tạp.
- Thiết kế định kỳ:Lưu khoảng thời gian hợp lệ. Xử lý tốt các khoảng trống thời gian nhưng đòi hỏi quản lý ranh giới cẩn thận.
5. Hệ thống phân tán: Chia nhỏ dữ liệu và mối quan hệ 🔗
Khi một cơ sở dữ liệu đơn không thể chứa dữ liệu, việc chia nhỏ dữ liệu trở nên cần thiết. Đây là nơi thiết kế ERD phải đối mặt với những giới hạn vật lý nghiêm trọng nhất. Các mối quan hệ vượt qua ranh giới chia nhỏ dữ liệu là tốn kém.
Vấn đề nối:
Nếu bảng A được chia nhỏ theo ID người dùng, và bảng B liên kết với bảng A, thì bảng B phải được chia nhỏ theo cùng ID người dùng để tránh các phép nối phân tán. Nếu bảng B được chia nhỏ theo thứ khác, bạn phải định tuyến truy vấn đến nhiều shard, tổng hợp kết quả và nối cục bộ.
Toàn vẹn tham chiếu:
Các ràng buộc khóa ngoại rất khó thực thi trên các nút phân tán. Nhiều hệ thống vô hiệu hóa khóa ngoại trong môi trường phân mảnh để duy trì khả năng sẵn sàng. Điều này chuyển gánh nặng bảo toàn tính toàn vẹn sang lớp ứng dụng, nơi dễ xảy ra các điều kiện cạnh tranh.
Những điểm chính cho các sơ đồ ERD phân tán:
- Tránh các mối quan hệ nhiều – nhiều trải dài qua nhiều mảnh phân mảnh.
- Loại bỏ chuẩn hóa dữ liệu để giảm nhu cầu thực hiện các thao tác nối giữa các nút.
- Thiết kế khóa phân vùng (khóa phân mảnh) dựa trên các mẫu truy vấn thường xuyên nhất, chứ không chỉ dựa trên khóa chính.
6. Hiệu suất so với Chuẩn hóa: Cân bằng giữa các lợi ích ⚖️
Chuẩn hóa (1NF, 2NF, 3NF) được dạy như tiêu chuẩn vàng cho tính toàn vẹn dữ liệu. Tuy nhiên, trong các hệ thống có lưu lượng cao, chuẩn hóa nghiêm ngặt có thể làm giảm hiệu suất. Sơ đồ ERD phải cân bằng giữa hai yếu tố này.
Khi nào nên loại bỏ chuẩn hóa:
- Các tác vụ đọc dữ liệu nặng: Nếu bạn đọc dữ liệu nhiều hơn so với việc ghi, việc thêm các cột dư thừa sẽ giúp tiết kiệm thao tác nối.
- Yêu cầu báo cáo:Các phép tổng hợp trên dữ liệu đã chuẩn hóa đòi hỏi các thao tác nối phức tạp, làm chậm các bảng điều khiển.
- Các tác vụ ghi dữ liệu nặng:Đôi khi, giữ dữ liệu riêng biệt sẽ giảm thiểu xung đột khóa trong quá trình cập nhật.
Ban cố vấn của chúng tôi nhấn mạnh rằng không tồn tại lược đồ ‘hoàn hảo’ nào. Đó là một sự thỏa hiệp. Sơ đồ ERD nên ghi chép rõ ràng nơi xảy ra việc loại bỏ chuẩn hóa và lý do tại sao, để những người bảo trì trong tương lai hiểu rằng sự trùng lặp là có chủ ý, chứ không phải lỗi.
So sánh các mẫu mô hình hóa 📊
Để hỗ trợ ra quyết định, dưới đây là bản tóm tắt các mẫu mô hình hóa được thảo luận và các trường hợp sử dụng điển hình của chúng.
| Mẫu | Trường hợp sử dụng tốt nhất | Rủi ro chính | Độ phức tạp |
|---|---|---|---|
| Bảng đơn | Các cấu trúc phân cấp đơn giản, ít đa dạng | Các trường rỗng, bloat lược đồ | Thấp |
| Bảng lớp | Các kiểu con nghiêm ngặt, các thuộc tính riêng biệt | Chi phí nối | Trung bình |
| Đệ quy | Sơ đồ tổ chức, danh mục | Độ sâu duyệt, chu trình | Cao |
| Entiti liên kết | Nhiều-đến-nhiều với thuộc tính | Hiệu suất nối | Trung bình |
| Thời gian | Kiểm toán, theo dõi lịch sử | Độ phức tạp truy vấn | Cao |
| Chia sẻ phân tán | Quy mô lớn, mở rộng ngang | Toàn vẹn tham chiếu | Rất cao |
Danh sách kiểm tra để xem xét sơ đồ quan hệ thực thể ✅
Trước khi hoàn tất sơ đồ quan hệ thực thể, hãy sử dụng danh sách kiểm tra này để phát hiện các lỗi phổ biến. Tốt hơn hết là phát hiện những vấn đề này trong giai đoạn thiết kế thay vì trong môi trường sản xuất.
- Số lượng:Bạn đã xác định rõ các mối quan hệ Một-đến-Một, Một-đến-Nhiều và Nhiều-đến-Nhiều chưa? Các ràng buộc tối thiểu/tối đa (0..1, 1..*) có được nêu rõ ràng không?
- Kiểu dữ liệu:Các kiểu cột có phù hợp với kích thước dữ liệu mong đợi không? (ví dụ: sử dụng Integer thay vì Varchar cho ID).
- Khả năng rỗng:Các khóa ngoại có cho phép rỗng không? Nếu có, logic xử lý các tham chiếu bị tách rời một cách trơn tru không?
- Chiến lược chỉ mục:Sơ đồ ERD có chỉ ra các cột nào cần được chỉ mục để tối ưu hiệu suất không? Thường thì các khóa ngoại được chỉ mục để tăng tốc độ nối.
- Quy ước đặt tên:Tên bảng và cột có nhất quán không? Tránh sử dụng các viết tắt có thể gây hiểu lầm sau này.
- Quy tắc kinh doanh:Các ràng buộc (ví dụ: “Một người dùng không thể có hai đăng ký hoạt động”) có được biểu diễn dưới dạng kiểm tra logic hay ràng buộc cơ sở dữ liệu không?
- Khả năng mở rộng:Lộ trình có thể hỗ trợ các thuộc tính mới mà không cần phải di dời toàn bộ? (ví dụ: sử dụng mẫu EAV hoặc các cột JSON khi phù hợp).
Suy nghĩ cuối cùng về mô hình hóa dữ liệu 🧠
Thiết kế sơ đồ quan hệ thực thể không chỉ đơn thuần là vẽ các hình hộp và đường kẻ. Đó là việc hiểu rõ luồng dữ liệu, các giới hạn về phần cứng và nhu cầu của doanh nghiệp. Các tình huống được thảo luận ở đây đại diện cho những điểm nghẽn nơi lý thuyết gặp thực tiễn.
Bằng cách lường trước những thách thức này—độ sâu đệ quy, phép nối phân tán, lịch sử theo thời gian và sự đánh đổi trong kế thừa—bạn có thể xây dựng các lược đồ có khả năng chống chịu tốt. Một sơ đồ ERD được thiết kế cẩn thận sẽ giảm nợ kỹ thuật và ngăn ngừa nhu cầu tái cấu trúc tốn kém sau này. Đó là một khoản đầu tư vào sự ổn định của toàn bộ hệ thống.
Hãy nhớ rằng lược đồ tốt nhất là lược đồ có thể phát triển cùng với dữ liệu. Tài liệu là chìa khóa. Đảm bảo rằng mọi sự lệch khỏi chuẩn chuẩn hóa đều được lý giải và ghi lại. Tính minh bạch này chính là yếu tố phân biệt kiến trúc cơ sở dữ liệu mạnh mẽ với kiến trúc dễ bị tổn thương.