











Modelowanie danych to fundament każdej solidnej architektury bazy danych. Choć teoria jest często przedstawiana na wykładach uniwersyteckich, praktyczne zastosowanie w środowiskach produkcyjnych ujawnia obszar pełen przypadków granicznych, wąskich gardłów wydajnościowych i logicznych niejasności. Diagramy relacji encji (ERD) są szkicami tych systemów, a mimo to często stają się źródłem sporów, gdy rzeczywisty świat odmawia uporządkowania się w prostokątach i liniach.
Zasiadliśmy z zespołem głównych administratorów baz danych i architektów danych, aby przeanalizować scenariusze, które ciągle zaskakują zespoły w fazie projektowania. To nie są ćwiczenia teoretyczne; to problemy, które pojawiają się, gdy wymagania biznesowe zderzają się z ograniczeniami fizycznymi przechowywania danych. Celem nie jest podanie szybkiego rozwiązania, ale głębokie zrozumienie istniejących kompromisów.
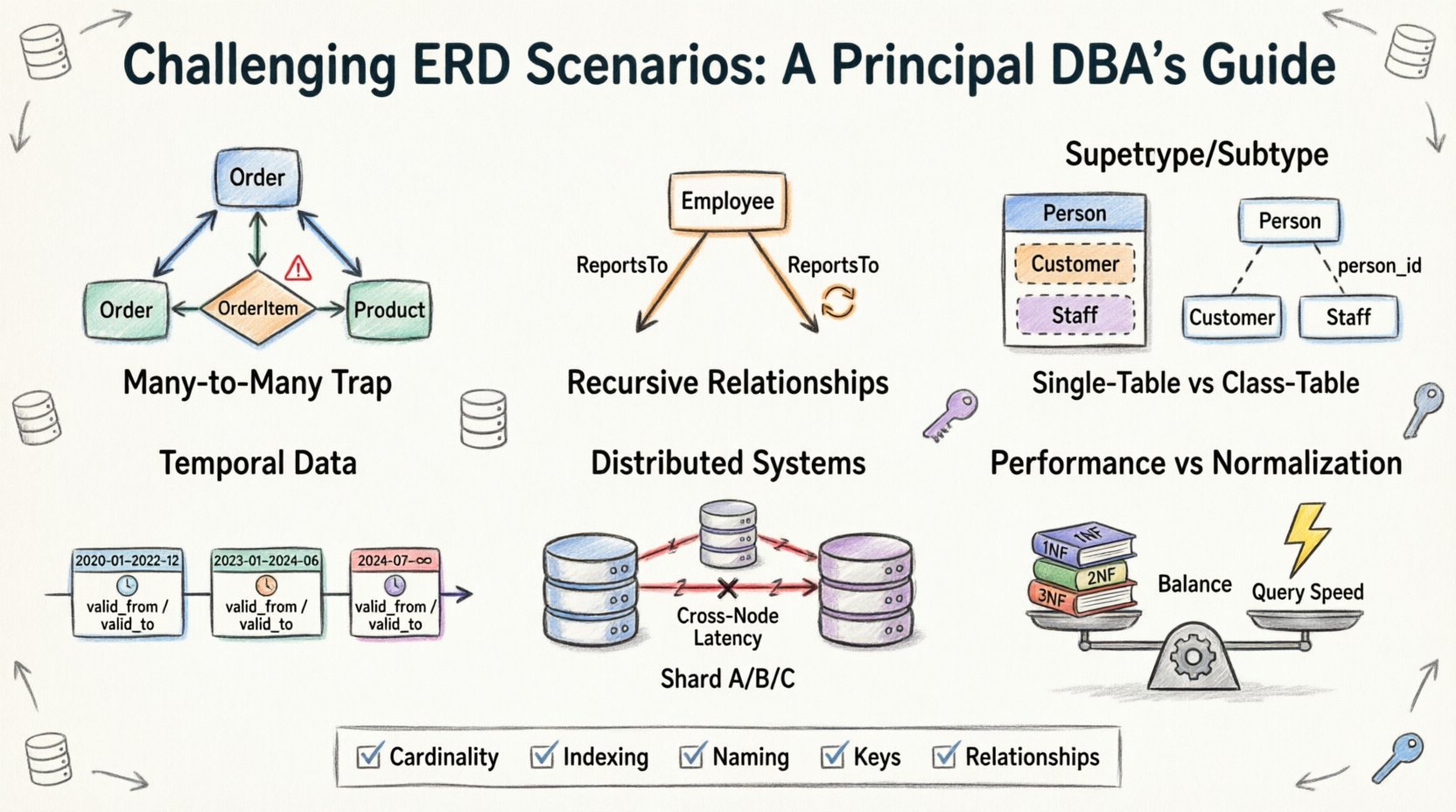
1. Pułapka wiele do wielu: Poza prostymi tabelami połączeń 🕸️
Najczęstszy punkt wyjścia w projektowaniu diagramów relacji encji to relacja wiele do wielu. Wydaje się to intuicyjne: uczeń może być zapisany na wiele kursów, a kurs może mieć wielu uczniów. Standardowym rozwiązaniem jest tabela mostowa lub asocjacyjna. Złożoność pojawia się jednak, gdy do samej relacji dodaje się atrybuty.
- Problem:Często zespoły próbują przechowywać dane o zapisie (jak oceny lub daty rejestracji) w głównej tabeli Student lub Course, co prowadzi do ogromnej nadmiarowości lub wartości null.
- Rzeczywistość:Samą relację należy traktować jako encję. Musi mieć własny klucz główny oraz klucze obce wskazujące na rodziców.
- Wyzwanie:Obsługa usuwania kaskadowego. Jeśli kurs zostanie usunięty, co stanie się z rekordami zapisu? Jeśli zapis zostanie usunięty, czy uczeń znika? Te decyzje definiują integralność danych.
W trakcie naszej rozmowy jeden z głównych administratorów baz danych zauważył, że tabela asocjacyjna często staje się wąskim gardłem wydajnościowym. Przy pobieraniu danych przez ten punkt połączenia silnik bazy danych musi wykonać operację połączenia, która może źle skalować się wraz ze wzrostem liczby wierszy do milionów. Rozwiązanie nie zawsze wymaga zmian architektonicznych; czasem wymaga denormalizacji, ale ta z kolei wprowadza anomalie aktualizacji.
Kluczowe rozważania dotyczące relacji wiele do wielu:
- Czy relacja ma atrybuty wymagające indeksowania?
- Czy relacja jest aktywna czy historyczna? (np. czy obecny zapis różni się od poprzedniego?)
- Jak system będzie obsługiwał zaniedbane rekordy, jeśli rodzic zostanie usunięty?
2. Relacje rekurencyjne: Hierarchie samodzielne 🌳
Dane hierarchiczne są wszędzie. Pomyśl o strukturze organizacyjnej, liście materiałów lub wątku komentarzy na forum. Modelowanie tego wymaga, by tabela odwoływała się do samej siebie. Choć koncepcyjnie proste, implementacja w schemacie relacyjnym stwarza konkretne wyzwania związane z głębokością i przeszukiwaniem.
Problem strukturalny:
Tworzysz tabelę z kluczem głównym i kolumną klucza obcego wskazującą na ten sam klucz główny w tej samej tabeli. Często nazywa się ją kolumną „parent_id”. Węzeł główny ma rodzica ustawionego na null.
Problem wydajnościowy:
Standardowe zapytania SQL mają trudności z głębokimi hierarchiami. Jeśli chcesz pobrać menedżera i wszystkich jego bezpośrednich i pośrednich podwładnych, prosty JOIN nie wystarczy. Potrzebujesz rekurencyjnych wyrażeń tabel wspólnych (CTE) lub procedur składowanych, które iterują po poziomach. Może to być kosztowne obliczeniowo.
Problem integralności:
Odwołania cykliczne to cichy zabójca. Jeśli pracownik A zarządza pracownikiem B, a pracownik B zarządza pracownikiem A, powstaje cykl. Baza danych musi temu zapobiegać, albo logika aplikacji musi go wykryć. W dużych systemach cykl może spowodować nieskończoną pętlę w narzędziach raportujących.
- Ograniczenia głębokości:Większość systemów ogranicza głębokość hierarchii (np. 32 poziomów), aby zapobiec błędom przepełnienia stosu podczas przeszukiwania.
- Agregacja ścieżek:Obliczanie całkowitego kosztu lub liczby elementów poddrzewa wymaga logiki rekurencyjnej, która trudno jest zoptymalizować w standardowych planach zapytań.
3. Modelowanie nadtypu i podtypu: Dylemat dziedziczenia 🧬
W programowaniu obiektowym dziedziczenie jest standardem. W bazach danych relacyjnych jest to wybór projektowy wpływający na przechowywanie i pobieranie danych. Pytanie brzmi: czy modelować pojazd jako jedną tabelę, czy rozdzielić go na Vehicle, Car i Truck?
Opcja A: Dziedziczenie jednej tabeli
Wszystkie atrybuty dla wszystkich podtypów znajdują się w jednej tabeli. Wartości NULL są używane dla nieużywanych atrybutów.
- Zalety:Proste zapytania, nie potrzeba sprzężeń do znalezienia dowolnego pojazdu.
- Wady:Zwiększenie rozmiaru tabeli, trudność w wymuszaniu ograniczeń specyficznych dla podtypu, wiele kolumn z wartościami NULL.
Opcja B: Dziedziczenie tabel klas
Jedna tabela dla nadtypu (Pojazd), a osobne tabele dla podtypów (Samochód, Ciężarówka), powiązane kluczem głównym.
- Zalety:Czysta separacja, brak wartości NULL, ściśle określone ograniczenia dla każdego podtypu.
- Wady:Wykonywanie zapytań wymaga łączenia wielu tabel, co może negatywnie wpływać na wydajność odczytu.
Nasze główne DBA zaznaczyły, że wybór często zależy od wzorców zapytań. Jeśli często zapytujesz określone podtypy, lepszym rozwiązaniem jest podejście tabel klas. Jeśli często agregujesz wszystkie podtypy, wygrywa podejście jednej tabeli. Diagram ERD musi jasno odzwierciedlać tę decyzję, aby uniknąć nieporozumień dla przyszłych programistów.
4. Dane czasowe: śledzenie zmian w czasie ⏳
Zasady biznesowe się zmieniają. Klient przeprowadza się, cena się aktualizuje, umowa wygasa. Przechowywanie tylko stanu „obecnego” często jest niewystarczające dla audytu lub raportowania. Wprowadza to projektowanie tabel czasowych lub wymiarów zmieniających się powoli (SCD).
Złożoność:
Zamiast aktualizować wiersz, wstawiasz nowy wiersz z datą rozpoczęcia i zakończenia ważności. Stary wiersz oznaczany jest jako nieaktywny. To podwaja wymagania pamięciowe dla danych historycznych i komplikuje zapytanie „obecnego widoku”.
Wyzwanie zapytania:
Wybieranie danych „na dzień” określonej chwili wymaga filtrowania według zakresu dat. Jeśli pominiesz logikę zakresu dat, możesz zwrócić nieprawidłową wersję rekordu. To często jest miejsce, gdzie pojawiają się problemy z integralnością danych w aplikacjach finansowych.
- Projekt zrzutu (snapshot): Przechowuj stan w określonej chwili. Wymaga okresowych zadań partii do zapisywania zrzutów.
- Projekt dziennika transakcji: Zapisuj każdą zmianę. Wysoki obciążenie zapisu, skomplikowana logika pobierania.
- Projekt okresowy: Przechowuj ważne przedziały czasu. Dobrze radzi sobie z przerwami w czasie, ale wymaga dokładnej obsługi granic.
5. Systemy rozproszone: fragmentacja i relacje 🔗
Gdy pojedyncza baza danych nie może pomieścić danych, konieczna staje się fragmentacja. To jest miejsce, w którym projektowanie ERD napotyka najbardziej surowe ograniczenia fizyczne. Relacje przekraczające granice fragmentacji są kosztowne.
Problem sprzężenia:
Jeśli tabela A jest fragmentowana według ID użytkownika, a tabela B jest powiązana z tabelą A, tabela B musi być fragmentowana według tego samego ID użytkownika, aby uniknąć sprzężeń rozproszonych. Jeśli tabela B jest fragmentowana inaczej, musisz kierować zapytanie do wielu fragmentów, agregować wyniki i łączyć lokalnie.
Integralność referencyjna:
Ograniczenia kluczy obcych są trudne do stosowania między rozproszonymi węzłami. Wiele systemów wyłącza klucze obce w środowiskach z fragmentacją, aby zapewnić dostępność. Przenosi to obciążenie integralności na warstwę aplikacji, która jest podatna na warunki wyścigu.
Kluczowe wnioski dotyczące rozproszonych modeli ERD:
- Unikaj relacji wiele do wielu, które obejmują wiele fragmentów.
- Znieormalizuj dane, aby zmniejszyć potrzebę łączenia danych między węzłami.
- Projektuj klucz partycji (klucz fragmentacji) na podstawie najczęściej występujących wzorców zapytań, a nie tylko klucza podstawowego.
6. Wydajność vs. Normalizacja: Równowaga kompromisów ⚖️
Normalizacja (1NF, 2NF, 3NF) jest nauczana jako złoty standard integralności danych. Jednak w systemach o wysokim przepływie, ściśła normalizacja może znacząco obniżyć wydajność. Model ERD musi osiągnąć równowagę między nimi.
Kiedy znieormalizować:
- Obciążenia zdominowane odczytami: Jeśli odczytujesz dane znacznie częściej niż je zapisujesz, dodanie nadmiarowych kolumn pozwala zaoszczędzić operacje łączenia.
- Wymagania raportowania: Agregacje na danych znormalizowanych wymagają skomplikowanych łączeń, które spowalniają pulpity monitoringu.
- Obciążenia zdominowane zapisami: Czasem zachowanie danych osobno zmniejsza zawieszenie blokad podczas aktualizacji.
Nasz panel podkreślił, że nie istnieje „doskonały” schemat. Jest to kompromis. Model ERD powinien dokumentować, gdzie występuje znieormalizacja i dlaczego, aby przyszli utrzymani rozumieli, że nadmiarowość jest celowa, a nie błąd.
Porównanie wzorców modelowania 📊
W celu wspomagania podejmowania decyzji, przedstawiamy podsumowanie omawianych wzorców modelowania i ich typowych zastosowań.
| Wzorzec | Najlepsze zastosowanie | Główny ryzyko | Złożoność |
|---|---|---|---|
| Jedna tabela | Proste hierarchie, mała różnorodność | Pola null, nadmiar schematu | Niska |
| Tabela klas | Ścisłe podtypy, różne atrybuty | Nadmiarowe obciążenie łączenia | Średnia |
| Rekursywny | Wykresy organizacyjne, kategorie | Głębokość przeszukiwania, cykle | Wysoki |
| Istotność przypisania | Wiele do wielu z atrybutami | Wydajność łączenia | Średni |
| Czasowy | Audyt, śledzenie historii | Złożoność zapytań | Wysoki |
| Rozproszone fragmentowanie | Ogromny zakres, poziome skalowanie | Integralność referencyjna | Bardzo wysoki |
Lista kontrolna do przeglądu schematu ERD ✅
Zanim zakończysz projektowanie diagramu relacji encji, użyj tej listy kontrolnej, aby wykryć typowe pułapki. Lepiej wykryć te problemy na etapie projektowania niż w środowisku produkcyjnym.
- Moc zbioru:Czy dokładnie zdefiniowałeś relacje jeden do jednego, jeden do wielu oraz wiele do wielu? Czy ograniczenia minimalne i maksymalne (0..1, 1..*) są jasno określone?
- Typy danych:Czy typy kolumn są odpowiednie dla oczekiwanej wielkości danych? (np. używanie Integer zamiast Varchar dla identyfikatorów).
- Możliwość wartości NULL:Czy klucze obce mogą mieć wartość NULL? Jeśli tak, czy logika odpowiednio obsługuje odłączone odniesienia?
- Strategia indeksowania:Czy schemat ERD wskazuje, które kolumny wymagają indeksowania dla poprawnej wydajności? Klucze obce często są indeksowane, aby przyspieszyć łączenia.
- Zasady nazewnictwa:Czy nazwy tabel i kolumn są spójne? Unikaj skrótów, które mogą być niejasne w przyszłości.
- Zasady biznesowe:Czy ograniczenia (np. „Użytkownik nie może mieć dwóch aktywnych subskrypcji”) są reprezentowane jako sprawdzenia logiczne lub ograniczenia bazy danych?
- Rozszerzalność: Czy schemat może pomieścić nowe atrybuty bez konieczności pełnej migracji? (na przykład przy użyciu wzorca EAV lub kolumn JSON tam, gdzie to odpowiednie).
Ostateczne rozważania na temat modelowania danych 🧠
Projektowanie diagramu relacji encji to nie tylko rysowanie pudełek i linii. Chodzi o zrozumienie przepływu danych, ograniczeń sprzętu oraz potrzeb biznesu. Przeprowadzane tutaj scenariusze reprezentują punkty zetknięcia teorii z praktyką.
Przewidując te wyzwania – głębokość rekurencji, rozproszone łączenia, historia czasowa oraz kompromisy wynikające z dziedziczenia – możesz tworzyć schematy odpornościowe. Dobrze zaprojektowany ERD zmniejsza dług techniczny i zapobiega potrzebie kosztownej refaktoryzacji w przyszłości. Jest to inwestycja w stabilność całego systemu.
Pamiętaj, że najlepszy schemat to ten, który ewoluuje razem z danymi. Dokumentacja jest kluczowa. Upewnij się, że każda odstępstwo od standardowej normalizacji jest uzasadniona i zapisana. Ta przejrzystość to właśnie to, co oddziela solidną architekturę bazy danych od kruchej.