











Projektowanie solidnej architektury danych wymaga balansowania sprzecznych priorytetów. Integralność, wydajność i utrzymywalność często napędzają w różnych kierunkach. Gdy system zmienia nacisk na operacje skupione na odczytach, tradycyjne zasady projektowania schematów doznają istotnego napięcia. Diagram relacji encji (ERD) staje się więcej niż statycznym projektem; pełni rolę umowy między logiką aplikacji a silnikiem przechowywania danych. Ten przewodnik bada strategiczne rozbieżności między podejściem znormalizowanym a nieznormalizowanym, szczególnie w kontekście dużych obciążeń odczytowych.
Decyzja o znormalizowaniu czy nieznormalizowaniu nie jest binarna. Wymaga ona zrozumienia kosztu duplikacji danych w stosunku do kosztu pobierania danych. W środowiskach, gdzie operacje odczytu dominują w dziennikach transakcji, minimalizacja złożoności połączeń często staje się głównym celem optymalizacji. Jednak wprowadzanie nadmiarowości stwarza nowe wyzwania dla spójności danych i operacji zapisu. Musimy przeanalizować kompromisy, aby wybrać odpowiednią strategię strukturalną.
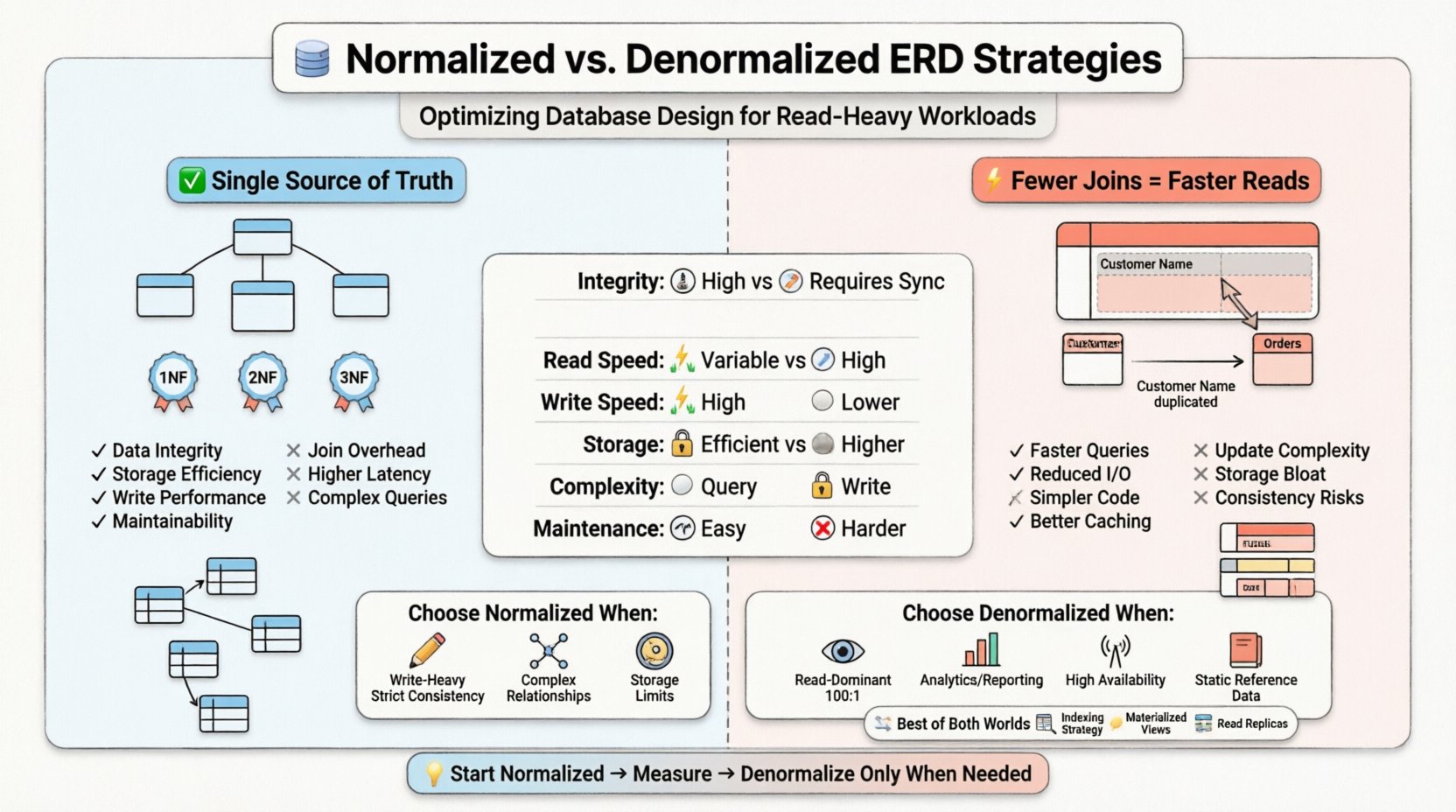
🏗️ Zrozumienie normalizacji w projektowaniu diagramów relacji encji
Normalizacja to systematyczny proces stosowany do zmniejszania nadmiarowości danych i poprawy integralności danych. Organizuje atrybuty i tabele w bazie danych relacyjnej w celu minimalizacji anomalii podczas operacji wstawiania, aktualizacji i usuwania. Celem jest zapewnienie, że każda część danych jest przechowywana dokładnie w jednym miejscu.
Podstawowe zasady normalizacji
Podczas tworzenia diagramu relacji encji architekci zazwyczaj przestrzegają hierarchii zasad znanych jako Formy Normalne. Każda forma rozwiązuje konkretne typy nadmiarowości.
- Pierwsza Forma Normalna (1NF): Zapewnia, że każda kolumna zawiera wartości atomowe oraz brak powtarzających się grup. Ustanawia płaską strukturę dla wierszy.
- Druga Forma Normalna (2NF): Buduje się na 1NF poprzez usunięcie częściowych zależności. Atrybuty muszą zależeć od całego klucza głównego, a nie tylko od jego części.
- Trzecia Forma Normalna (3NF): Usuwa zależności przechodnie. Atrybuty niekluczowe muszą zależeć wyłącznie od klucza głównego, a nie od innych atrybutów niekluczowych.
W bardzo znormalizowanym diagramie relacji encji tabele są szczegółowe. Tabela klienta może istnieć osobno od tabeli adresu, która jest powiązana za pomocą klucza obcego. Tabela zamówienia odnosi się do klienta, a tabela pozycji zamówienia odnosi się do zamówienia. Ta struktura zapewnia, że jeśli klient zmienia adres, aktualizacja odbywa się w jednym miejscu i automatycznie się rozprzestrzenia.
Zalety znormalizowanego schematu
- Integralność danych: Jedne źródła prawdy zmniejszają ryzyko sprzecznych informacji.
- Efektywność przechowywania: Mniej danych nadmiarowych oznacza mniejszy rozmiar bazy danych.
- Wydajność zapisu: Operacje wstawiania, aktualizacji i usuwania są zazwyczaj szybsze, ponieważ mniej wierszy musi być dotykanych w wielu tabelach.
- Utrzywalność: Zmiany w strukturze danych są lokalizowane. Dodanie nowego atrybutu do określonej encji nie wymaga przekazywania zmian do niepowiązanych tabel.
Wady dla systemów skupionych na odczytach
Choć normalizacja wyróżnia się w środowiskach skupionych na zapisie lub mieszanych, wprowadza opór dla operacji odczytu. Każde połączenie wymagane do złożenia pełnego rekordu reprezentuje operację fizyczną na dysku lub pamięci podręcznej. W obciążeniu skupionym na odczytach system może potrzebować pobrania danych z pięciu lub sześciu różnych tabel, aby wyświetlić jedną stronę pulpitu.
- Nadmiar połączeń: Przetwarzacz zapytań musi dopasować klucze między tabelami. To zużywa cykle procesora i przepustowość pamięci.
- Operacje wejścia/wyjścia: Jeśli tabele są duże, silnik przechowywania musi wykonać wiele poszukiwań, aby pobrać powiązane dane.
- Opóźnienie: Skumulowany czas wielu wyszukiwań zwiększa czas odpowiedzi dla użytkownika końcowego.
🔗 Metoda denormalizacji
Denormalizacja to celowe wprowadzanie nadmiarowości do projektu bazy danych. Celem jest optymalizacja systemu pod kątem wydajności odczytu poprzez zmniejszenie liczby potrzebnych połączeń. W diagramie relacji encji manifestuje się to jako kolumny, które powielają dane z innych tabel, albo szersze tabele, które łączą powiązane informacje.
Jak działa denormalizacja
Zamiast przechowywać klucz obcy do wyszukania nazwy klienta, tabela zleceń zdenormalizowana może przechowywać nazwę klienta bezpośrednio. Jeśli klient zmieni swoją nazwę, rekord zlecenia musi zostać zaktualizowany lub oznaczony, albo system akceptuje, że zlecenie odzwierciedla nazwę w momencie zakupu.
Ta strategia przesuwa złożoność z drogi odczytu na drogę zapisu. System musi teraz obsługiwać logikę aktualizacji nadmiarowych kopii danych.
Zalety dla obciążeń zdominowanych odczytami
- Szybsze wykonywanie zapytań:Mniejsza liczba połączeń oznacza mniejsze obciążenie obliczeniowe.
- Zmniejszone I/O: Więcej danych jest pobieranych w jednym skanowaniu tabeli zamiast wielu wyszukiwań.
- Uproszczone zapytania:Kod aplikacji wymaga mniej logiki do złożenia wyników.
- Efektywność buforowania:Płaskie struktury są często łatwiejsze do skutecznego buforowania w pamięci.
Ryzyka i wady
Głównym kosztem denormalizacji jest spójność danych. Jeśli dane źródłowe ulegną zmianie, wszystkie kopie nadmiarowe muszą zostać zaktualizowane jednocześnie. Niepowodzenie w tym prowadzi do zaniechanych danych.
- Anomalie aktualizacji: Aktualizacja nazwy klienta wymaga znalezienia i zmiany każdego rekordu zlecenia, które odnosi się do tego klienta.
- Zwiększenie zużycia pamięci:Powielanie danych zwiększa całkowity rozmiar bazy danych.
- Złożoność operacji zapisu:Transakcje zapisu stają się bardziej złożone, często wymagając więcej blokad lub dłuższych czasów trwania transakcji.
- Sztywność schematu:Dodanie nowego pola może wymagać aktualizacji wielu tabel, a nie tylko jednej.
📈 Analiza cech obciążenia zdominowanego odczytami
Aby wybrać odpowiednią strategię, należy zrozumieć konkretną naturę obciążenia. Systemy zdominowane odczytami znacznie różnią się od systemów transakcyjnych, w których zapisy są częste i krytyczne.
Wzorce zapytań
Czy aplikacja wykonuje złożone zapytania analityczne czy proste wyszukiwania? Złożone zapytania zawierające agregacje na wielu tabelach korzystają z denormalizacji. Proste wyszukiwania po ID mogą działać wystarczająco dobrze z normalizacją, jeśli indeksy są dobrze dopasowane.
- Zapytania punktowe: Pobieranie pojedynczego rekordu po ID.
- Zapytania zakresowe: Pobieranie zestawu rekordów w zakresie dat.
- Agregacje: Obliczanie sum, średnich lub liczb w dużych zestawach danych.
Wymagania dotyczące opóźnienia
Platformy handlowe o wysokiej częstotliwości lub panele monitoringu w czasie rzeczywistym nie mogą pozwolić sobie na opóźnienie spowodowane złożonymi połączeniami. W tych scenariuszach denormalizacja jest często wymagana, a nie opcją. Z kolei jeśli aplikacja może tolerować kilka setek milisekund opóźnienia, normalizacja może być wystarczająca przy odpowiednim indeksowaniu.
Wytrzymałość na spójność danych
Czy wymagana jest natychmiastowa spójność? Jeśli system może tolerować spójność ostateczną, denormalizacja staje się znacznie bezpieczniejsza. Kopie odczytowe lub mechanizmy aktualizacji asynchronicznej mogą obsłużyć synchronizację danych nadmiarowych bez blokowania operacji zapisu.
📋 Tabela porównawcza strategii
Poniższa tabela podsumowuje kluczowe różnice między oboma podejściami w kontekście projektowania baz danych.
| Cecha | Schemat normalizowany | Schemat denormalizowany |
|---|---|---|
| Integralność danych | Wysoka (jedyny źródłowy punkt prawdy) | Niższa (wymaga logiki synchronizacji) |
| Wydajność odczytu | Zmienne (zależy od połączeń) | Wysoka (mniej połączeń) |
| Wydajność zapisu | Wysoka (minimalna nadmiarowość) | Niższa (aktualizacja wielu wierszy) |
| Użycie pamięci | Efektywne | Wyższe (dane nadmiarowe) |
| Złożoność | Wysoka złożoność zapytań | Wysoka złożoność zapisu |
| Utrzymywalność | Łatwe zmiany schematu | Trudniejsze zmiany schematu |
🧭 Ramy decyzyjne dla architektów
Wybór odpowiedniej drogi wymaga oceny wymagań biznesowych pod kątem ograniczeń technicznych. Poniższa ramy pomaga kierować procesem podejmowania decyzji.
Kiedy wybrać normalizację
- Intensywność zapisu: Jeśli operacje zapisu występują częściej niż odczyty, normalizacja zapobiega anomalii aktualizacji.
- Streści spójności: Systemy finansowe lub rekordy medyczne często wymagają ścisłej zgodności z ACID, gdzie nadmiarowość jest nieakceptowalna.
- Złożone relacje: Gdy encje mają często zmieniające się relacje wiele do wielu, normalizacja obsługuje mapowanie sprawnie.
- Ograniczenia pamięci: Jeśli miejsce na dysku jest ograniczone, minimalizacja nadmiarowości jest korzystna.
Kiedy wybrać denormalizację
- Dominacja odczytów: Jeśli odczyty znacznie przewyższają zapisy (np. 100:1), zyski wydajności z mniejszej liczby połączeń przewyższają koszty zapisu.
- Raportowanie i analizy: Magazyny danych i silniki raportowania często denormalizują dane, aby przyspieszyć zapytania agregujące.
- Wysoka dostępność: Systemy rozproszone mogą denormalizować dane, aby umożliwić odczyty na węzłach lokalnych bez przejść sieciowych do innych partycji.
- Dane referencyjne statyczne: Dane, które rzadko się zmieniają (np. kody krajów, stopy walutowe), są idealnym kandydatem na duplikację.
🛠️ Hybrydowe podejścia i optymalizacja
Zwykle nie ma potrzeby wybierania jednego skrajnego rozwiązania na rzecz drugiego. Nowoczesne systemy często stosują hybrydowe strategie, aby zrównoważyć korzyści obu modeli.
Strategie indeksowania
Zanim denormalizujesz, upewnij się, że schemat normalizowany jest w pełni indeksowany. Indeksy pokrywające pozwalają silnikowi przechowywania na pobieranie wszystkich niezbędnych danych bezpośrednio z indeksu, unikając poszukiwań w tabeli. Może to czasem osiągnąć prędkość odczytu zbliżoną do denormalizowanej, bez nadmiarowości danych.
- Indeksy złożone: Uporządkuj kolumny według najbardziej selektywnych pól, aby przyspieszyć skany zakresowe.
- Indeksy częściowe: Indeksuj tylko określone podzbiory danych, aby zmniejszyć rozmiar indeksu i koszty jego utrzymania.
Widoki materializowane
Widok materializowany to obiekt bazy danych, który fizycznie przechowuje wynik zapytania. Pozwala systemowi utrzymywać uproszczoną (nieznormalizowaną) wersję danych bez modyfikowania tabel podstawowych. Gdy dane podstawowe ulegają zmianie, widok materializowany może zostać odświeżony.
- Wstępne obliczenia:Złożone agregacje są obliczane z góry.
- Cykle odświeżania:Może być skonfigurowane do działania według harmonogramu lub wyzwalania przy zmianie danych.
- Oddzielenie odczytu:Zapytania dotykają widoku materializowanego, podczas gdy zapisy są przekazywane do tabel podstawowych.
Repliki odczytu
W architekturach rozproszonych repliki odczytu mogą być skonfigurowane w celu przechowywania nieznormalizowanych kopii danych. Węzeł główny obsługuje zapisy i utrzymuje znormalizowaną strukturę schematu. Replikę otrzymuje aktualizacje asynchronicznie i obsługuje ruch odczytowy przy użyciu zoptymalizowanego schematu.
- Skalowanie odczytów:Rozdziela obciążenie na wielu węzłach.
- Bliskość geograficzna:Umieszcza dane bliżej użytkownika.
- Spójność ostateczna:Zgadza się na niewielkie opóźnienie w propagacji danych.
⚠️ Powszechne pułapki w projektowaniu schematu
Nawet przy jasnej strategii błędy w implementacji mogą naruszać wydajność. Architekci muszą być na baczności przed powszechnymi błędami.
Zbyt duża normalizacja
Tworzenie zbyt wielu tabel dla jednego pojęcia może prowadzić do nadmiernych połączeń. Choć 3NF jest standardem, ślepe przestrzeganie go w systemach z dużym obciążeniem odczytu może pogorszyć wydajność. Czasem konieczne jest kontrolowane naruszenie 3NF.
Niespójna denormalizacja
Denormalizacja tylko niektórych części aplikacji, podczas gdy inne pozostają znormalizowane, tworzy system rozdrobniony. Niespójność utrudnia programistom przewidywanie charakterystyk wydajności.
Ignorowanie objętości danych
Schemat działający dla małego zestawu danych może zawieść przy wzroście objętości danych. Denormalizacja powoduje liniowy wzrost wymagań pamięciowych wraz z liczbą rekordów. Jeśli dane rosną wykładniczo, koszty przechowywania i obciążenie utrzymania nadmiarowości mogą stać się niemożliwe do zarządzania.
Złożoność logiki aktualizacji
Zaimplementowanie logiki utrzymywania zgodności danych nadmiarowych jest nieproste. Często wymaga ona wyzwalaczy, transakcji na poziomie aplikacji lub kolejek komunikatów. Jeśli ta logika zawiedzie, uszkodzenie danych występuje bezpiecznie, bez ostrzeżeń.
🔍 Uwagi dotyczące implementacji
Przy przejściu od projektowania do implementacji należy rozwiązać konkretne szczegóły techniczne, aby zapewnić sukces.
Zarządzanie transakcjami
Aktualizacje nieznormalizowane często obejmują wiele wierszy. Muszą one być zawarte w jednej transakcji, aby zapewnić atomowość. Jeśli system zawiesi się w połowie, dane muszą zostać cofnięte, aby uniknąć niezgodności.
Warstwy buforowania
Nawet przy denormalizacji buforowanie często dostępnego danych w pamięci może dalej zmniejszyć obciążenie bazy danych. Bufor powinien być invalidowany lub aktualizowany, gdy zmienia się podstawowe dane.
Monitorowanie i metryki
Nieprzerwane monitorowanie jest niezbędne. Śledź czasy wykonania zapytań, konkurencję o blokady i wzrost magazynowania. Jeśli zauważysz wzrost opóźnień zapisu, może to wskazywać, że logika aktualizacji denormalizacji jest zbyt ciężka.
📝 Ostateczne rozważania dla architektów
Wybór między strategiami ERD znormalizowanymi i denormalizowanymi to podstawowe decyzje architektoniczne. Określa ona sposób przepływu danych przez system oraz sposób działania silnika magazynowania w interakcji z aplikacją. Nie ma jednej poprawnej odpowiedzi, która byłaby odpowiednia w każdej sytuacji.
- Najpierw pomiary: Nie optymalizuj na podstawie założeń. Profiluj bieżący obciążenie, aby zidentyfikować węzły zatkania.
- Zacznij prosto: Zacznij od projektu znormalizowanego. Denormalizuj tylko wtedy, gdy metryki wydajności wskazują na potrzebę.
- Dokumentuj decyzje: Jasno zapisz, dlaczego wprowadzono nadmiarowość. Przyszli utrzymani potrzebują zrozumieć zalety i wady.
- Planuj ewolucję: Projektowanie schematów musi ewoluować. Strategia działająca dziś może wymagać dostosowania wraz z zmianą wzorców danych.
Zrozumienie mechanizmów łączeń, kosztów nadmiarowości oraz specyficznych wymagań obciążeń odczytu pozwala architektom projektować systemy zarówno wytrzymałe, jak i wydajne. Celem nie jest ślepe przestrzeganie sztywnych zasad, ale stosowanie najbardziej odpowiedniego narzędzia dla konkretnego środowiska danych.