











एक टिकाऊ डेटा आर्किटेक्चर डिज़ाइन करने के लिए एक विरोधाभासी लक्ष्यों के बीच संतुलन बनाए रखना आवश्यक है। अखंडता, प्रदर्शन और रखरखाव अक्सर अलग-अलग दिशाओं में खींचते हैं। जब प्रणाली पढ़ने पर अधिक निर्भर कार्यभार की ओर ध्यान केंद्रित करती है, तो स्कीमा डिज़ाइन के पारंपरिक नियमों को गहन तनाव का सामना करना पड़ता है। एंटिटी रिलेशनशिप डायग्राम (ERD) एक स्थिर नक्शे से अधिक बन जाता है; यह एप्लिकेशन लॉजिक और स्टोरेज इंजन के बीच संविदा के रूप में कार्य करता है। यह मार्गदर्शिका उच्च आयतन पढ़ने वाले कार्यभार के संदर्भ में विशेष रूप से सामान्यीकृत और असामान्यीकृत दृष्टिकोणों के रणनीतिक विचलन का अध्ययन करती है।
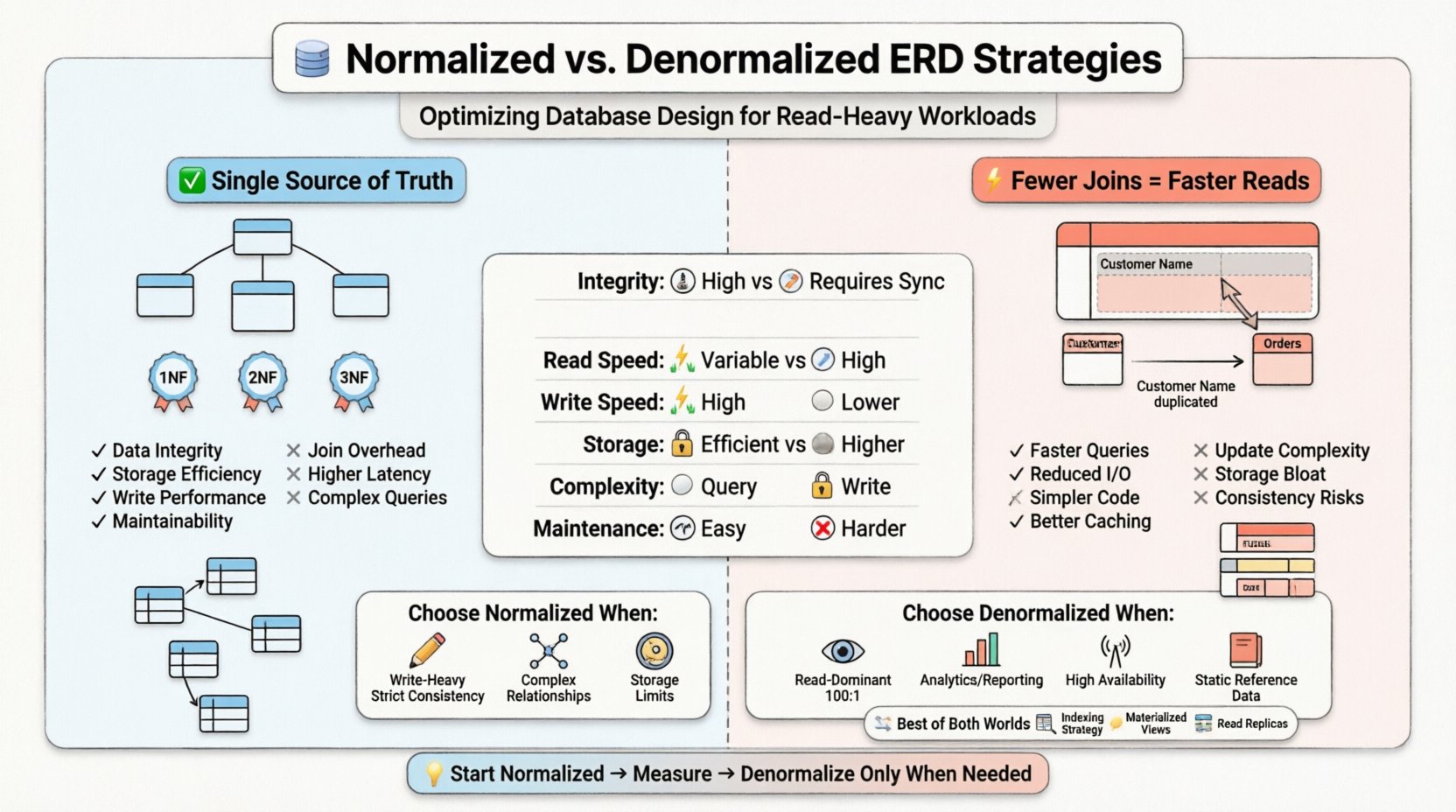
सामान्यीकृत या असामान्यीकृत करने का निर्णय द्विआधारी नहीं है। इसमें डेटा दोहराव की लागत के बारे में समझना और डेटा प्राप्ति की लागत के बीच तुलना करना शामिल है। ऐसे वातावरणों में जहां पढ़ने के ऑपरेशन लेनदेन लॉग में अधिकांश होते हैं, जॉइन की जटिलता को कम करना अक्सर मुख्य अनुकूलन लक्ष्य बन जाता है। हालांकि, अतिरिक्तता को लागू करने से डेटा संगतता और लेखन ऑपरेशन के लिए नए चुनौतियाँ उत्पन्न होती हैं। हमें विकल्पों का विश्लेषण करना होगा ताकि उचित संरचनात्मक रणनीति का चयन किया जा सके।
🏗️ ERD डिज़ाइन में सामान्यीकरण को समझना
सामान्यीकरण एक व्यवस्थित प्रक्रिया है जिसका उपयोग डेटा दोहराव को कम करने और डेटा अखंडता में सुधार करने के लिए किया जाता है। यह डेटाबेस में विशेषताओं और तालिकाओं को व्यवस्थित करता है ताकि डेटा डालने, अपडेट करने और हटाने के दौरान विचलनों को कम किया जा सके। लक्ष्य यह सुनिश्चित करना है कि प्रत्येक डेटा के एक ही स्थान पर संग्रहित किया जाए।
सामान्यीकरण के मूल सिद्धांत
एंटिटी रिलेशनशिप डायग्राम बनाते समय, वास्तुकार आमतौर पर ‘सामान्य रूप’ के नाम से जाने वाले नियमों के एक पदानुक्रम का पालन करते हैं। प्रत्येक रूप विशिष्ट प्रकार की दोहराव के समाधान करता है।
- पहला सामान्य रूप (1NF):यह सुनिश्चित करता है कि प्रत्येक कॉलम में परमाणु मान हों और कोई भी दोहराए गए समूह न हों। इससे पंक्तियों के लिए एक समतल संरचना बनती है।
- दूसरा सामान्य रूप (2NF):1NF पर आधारित है और आंशिक निर्भरता को हटाता है। विशेषताओं को पूर्ण मुख्य कुंजी पर निर्भर होना चाहिए, केवल इसके एक हिस्से पर नहीं।
- तीसरा सामान्य रूप (3NF):प्रत्यक्ष निर्भरता को दूर करता है। गैर-कुंजी विशेषताओं को केवल मुख्य कुंजी पर निर्भर होना चाहिए, अन्य गैर-कुंजी विशेषताओं पर नहीं।
एक अत्यधिक सामान्यीकृत ERD में, तालिकाएं बहुत छोटी होती हैं। एक ग्राहक तालिका उनकी पता तालिका से अलग हो सकती है, जो विदेशी कुंजी के माध्यम से जुड़ी होती है। एक आदेश तालिका ग्राहक को संदर्भित करती है, और एक आदेश आइटम तालिका आदेश को संदर्भित करती है। इस संरचना के कारण यह सुनिश्चित होता है कि यदि एक ग्राहक बदल जाता है, तो अपडेट एक ही स्थान पर होता है और स्वचालित रूप से प्रसारित हो जाता है।
सामान्यीकृत स्कीमा के लाभ
- डेटा अखंडता:एकल स्रोतों के रूप में सच्चाई के जोखिम को कम करता है।
- स्टोरेज दक्षता:कम दोहराए गए डेटा का अर्थ है कि डेटाबेस का आकार छोटा होता है।
- लेखन प्रदर्शन:आमतौर पर डेटा डालने, अपडेट करने और हटाने के ऑपरेशन तेज होते हैं क्योंकि एक से अधिक तालिकाओं में कम पंक्तियों को छूने की आवश्यकता होती है।
- रखरखाव:डेटा संरचना में परिवर्तन स्थानीय होते हैं। किसी विशिष्ट एंटिटी में नया विशेषता जोड़ने के लिए असंबंधित तालिकाओं में जाने वाले परिवर्तनों की आवश्यकता नहीं होती है।
पढ़ने पर अधिक निर्भर प्रणालियों के लिए नुकसान
जबकि सामान्यीकरण लेखन-पर अधिक निर्भर या मिश्रित वातावरणों में अच्छा प्रदर्शन करता है, यह पढ़ने के ऑपरेशन के लिए अवरोध उत्पन्न करता है। एक पूर्ण रिकॉर्ड बनाने के लिए आवश्यक प्रत्येक जॉइन डिस्क या मेमोरी कैश पर एक भौतिक संचालन का प्रतिनिधित्व करता है। पढ़ने पर अधिक निर्भर कार्यभार में, प्रणाली को एक ही डैशबोर्ड दृश्य को दिखाने के लिए पांच या छह अलग-अलग तालिकाओं से डेटा प्राप्त करने की आवश्यकता हो सकती है।
- जॉइन ओवरहेड:प्रश्न प्रोसेसर को तालिकाओं के बीच कुंजियों को मैच करना होता है। इससे सीपीयू साइकल और मेमोरी बैंडविड्थ का उपयोग होता है।
- आई/ओ ऑपरेशन:यदि तालिकाएं बड़ी हैं, तो स्टोरेज इंजन को संबंधित डेटा प्राप्त करने के लिए कई खोज करनी होगी।
- लेटेंसी: बहुल खोजों का संचयी समय अंतिम उपयोगकर्ता के लिए प्रतिक्रिया समय को बढ़ाता है।
🔗 अनियमितता का दृष्टिकोण
अनियमितता डेटाबेस डिजाइन में जानबूझकर अतिरेक लाने की प्रक्रिया है। उद्देश्य पठन प्रदर्शन के लिए प्रणाली को अनुकूलित करना है, जिससे आवश्यक जॉइन की संख्या कम हो जाए। एंटिटी रिलेशनशिप आरेख में, इसका प्रतिनिधित्व उन कॉलम के रूप में होता है जो अन्य तालिकाओं से डेटा की प्रतिलिपि बनाते हैं या संबंधित जानकारी को संग्रहीत करने वाली विस्तृत तालिकाएं होती हैं।
अनियमितता कैसे काम करती है
ग्राहक के नाम को खोजने के लिए विदेशी कुंजी संग्रहीत करने के बजाय, अनियमित आदेश तालिका में ग्राहक का नाम सीधे संग्रहीत किया जा सकता है। यदि ग्राहक अपना नाम बदलता है, तो आदेश रिकॉर्ड को अपडेट करना या चिह्नित करना होगा, या प्रणाली को स्वीकार करना होगा कि आदेश खरीद के समय के नाम को दर्शाता है।
इस रणनीति में पठन पथ से लेखन पथ की ओर जटिलता स्थानांतरित होती है। अब प्रणाली को डेटा की अतिरेक प्रतिलिपियों के अपडेट के तर्क को संभालना होगा।
पठन-भारी लोड के लिए लाभ
- तेज़ क्वेरी निष्पादन: कम जॉइन का मतलब कम गणनात्मक ओवरहेड होता है।
- कम I/O: एकल तालिका स्कैन में अधिक डेटा प्राप्त किया जाता है, बजाय बहुल खोजों के।
- सरलीकृत क्वेरीज़: एप्लिकेशन कोड को परिणामों को एकत्र करने के लिए कम तर्क की आवश्यकता होती है।
- कैशिंग की कार्यक्षमता: समतल संरचनाएं अक्सर मेमोरी में प्रभावी रूप से कैश करने में आसान होती हैं।
जोखिम और नुकसान
अनियमितता की प्राथमिक लागत डेटा संगतता है। यदि स्रोत डेटा बदलता है, तो सभी अतिरेक प्रतिलिपियों को एक साथ अपडेट करना होगा। ऐसा न करने पर डेटा अद्यतन नहीं होता है।
- अपडेट विचलन: ग्राहक के नाम को अपडेट करने के लिए उस ग्राहक को संदर्भित करने वाले प्रत्येक आदेश रिकॉर्ड को खोजना और बदलना होगा।
- स्टोरेज ब्लोट: डेटा की प्रतिलिपि बनाने से डेटाबेस का कुल आकार बढ़ता है।
- लेखन में जटिलता: लेखन लेनदेन अधिक जटिल हो जाते हैं, जिसमें अक्सर अधिक लॉक या लंबे लेनदेन समय की आवश्यकता होती है।
- स्कीमा कठोरता: एक नया फ़ील्ड जोड़ने के लिए एक तालिका के बजाय कई तालिकाओं को अपडेट करने की आवश्यकता हो सकती है।
📈 पठन-भारी लोड विशेषताओं का विश्लेषण
सही रणनीति चुनने के लिए, लोड की विशिष्ट प्रकृति को समझना आवश्यक है। पठन-भारी प्रणालियां लेनदेन प्रणालियों से महत्वपूर्ण रूप से भिन्न होती हैं, जहां लेखन अक्सर आम और महत्वपूर्ण होते हैं।
क्वेरी पैटर्न
क्या एप्लिकेशन जटिल विश्लेषणात्मक क्वेरीज़ या सरल खोजों का कार्य करता है? बहुत सारी तालिकाओं के बीच एकत्रीकरण वाली जटिल क्वेरीज़ को अनियमितता से लाभ मिलता है। यदि सूचकांक अच्छी तरह से ट्यून किए गए हैं, तो ID द्वारा सरल खोजें नॉर्मलाइजेशन के साथ उचित प्रदर्शन कर सकती हैं।
- पॉइंट क्वेरीज़: ID द्वारा एकल रिकॉर्ड को प्राप्त करना।
- रेंज क्वेरीज़:एक तारीख की सीमा के भीतर रिकॉर्ड के सेट को प्राप्त करना।
- एग्रीगेशन्स:बड़े डेटासेट्स के आधार पर कुल, औसत या गिनती की गणना करना।
लेटेंसी आवश्यकताएं
उच्च आवृत्ति वाले ट्रेडिंग प्लेटफॉर्म या रियल-टाइम डैशबोर्ड कठिन जॉइन्स द्वारा पेश की जाने वाली लेटेंसी को झेल नहीं सकते। इन परिस्थितियों में, डेनॉर्मलाइज़ेशन एक विकल्प के बजाय आवश्यकता होती है। विपरीत रूप से, यदि एप्लिकेशन कुछ सौ मिलीसेकंड के देरी को सहन कर सकता है, तो सही इंडेक्सिंग के साथ नॉर्मलाइज़ेशन पर्याप्त हो सकता है।
डेटा संगतता सहिष्णुता
तुरंत संगतता की आवश्यकता है? यदि प्रणाली अंततः संगतता को सहन कर सकती है, तो डेनॉर्मलाइज़ेशन बहुत सुरक्षित हो जाती है। रीड रिप्लिका या असिंक्रोनस अपडेट तंत्र लेखन ऑपरेशन को ब्लॉक किए बिना अतिरिक्त डेटा के सिंक्रनाइज़ेशन को संभाल सकते हैं।
📋 रणनीतिक तुलना तालिका
निम्नलिखित तालिका डेटाबेस डिज़ाइन के संदर्भ में दोनों प्रक्रियाओं के मुख्य अंतरों का सारांश प्रस्तुत करती है।
| फीचर | नॉर्मलाइज़्ड स्कीमा | डेनॉर्मलाइज़्ड स्कीमा |
|---|---|---|
| डेटा अखंडता | उच्च (एकमात्र सत्य का स्रोत) | कम (सिंक लॉजिक की आवश्यकता होती है) |
| पढ़ने का प्रदर्शन | चर (जॉइन्स पर निर्भर है) | उच्च (कम जॉइन्स) |
| लेखन प्रदर्शन | उच्च (न्यूनतम अतिरिक्तता) | कम (बहुत सारी पंक्तियों को अपडेट करना) |
| स्टोरेज उपयोग | कुशल | अधिक (अतिरिक्त डेटा) |
| जटिलता | उच्च क्वेरी जटिलता | उच्च लेखन जटिलता |
| रखरखाव योग्यता | स्कीमा बदलाव के लिए आसान | स्कीमा बदलाव के लिए कठिन |
🧭 आर्किटेक्ट्स के लिए निर्णय ढांचा
सही रास्ता चुनने के लिए व्यावसायिक आवश्यकताओं का तकनीकी सीमाओं के साथ मूल्यांकन करना आवश्यक है। निम्नलिखित ढांचा निर्णय लेने की प्रक्रिया को मार्गदर्शन करने में मदद करता है।
नॉर्मलाइजेशन कब चुनें
- लेखन तीव्रता: यदि लेखन संचालन पढ़ने की तुलना में अक्सर होते हैं, तो नॉर्मलाइजेशन अपडेट विचलनों को रोकता है।
- कठोर सुसंगतता: वित्तीय प्रणालियाँ या मेडिकल रिकॉर्ड अक्सर कठोर ACID संगतता की आवश्यकता होती है जहाँ अतिरेक अस्वीकार्य है।
- जटिल संबंध: जब एकताएँ बार-बार बदलने वाले बहु-से-बहु संबंधों के साथ होती हैं, तो नॉर्मलाइजेशन मैपिंग को स्पष्ट रूप से संभालती है।
- स्टोरेज सीमाएँ: यदि डिस्क स्पेस महंगा है, तो अतिरेक को कम करना लाभदायक होता है।
डेनॉर्मलाइजेशन कब चुनें
- पढ़ने की प्राधान्यता: यदि पढ़ने की संख्या लेखन की तुलना में काफी अधिक हों (उदाहरण के लिए, 100:1), तो कम जॉइन्स से प्राप्त प्रदर्शन लाभ लेखन लागत को बराबर कर देता है।
- रिपोर्टिंग और विश्लेषण: डेटा वेयरहाउस और रिपोर्टिंग इंजन अक्सर एग्रीगेशन क्वेरी को तेज करने के लिए डेनॉर्मलाइज करते हैं।
- उच्च उपलब्धता: वितरित प्रणालियाँ डेटा को डेनॉर्मलाइज कर सकती हैं ताकि स्थानीय नोड्स पर पढ़ने की अनुमति मिल सके बिना अन्य पार्टीशन्स तक नेटवर्क हॉप करने के बिना।
- स्थिर संदर्भ डेटा: डेटा जो दुर्लभ रूप से बदलता है (उदाहरण के लिए, देश कोड, मुद्रा दरें) प्रतिलिपि बनाने के लिए एक प्रमुख उम्मीदवार है।
🛠️ हाइब्रिड दृष्टिकोण और अनुकूलन
एक चरम को दूसरे के ऊपर चुनने की आवश्यकता दुर्लभ होती है। आधुनिक प्रणालियाँ अक्सर दोनों मॉडलों के लाभों को संतुलित करने के लिए हाइब्रिड रणनीतियों का उपयोग करती हैं।
इंडेक्सिंग रणनीतियाँ
डेनॉर्मलाइज करने से पहले यह सुनिश्चित करें कि नॉर्मलाइज्ड स्कीमा पूरी तरह से इंडेक्स किया गया है। कवरिंग इंडेक्स स्टोरेज इंजन को इंडेक्स से ही सभी आवश्यक डेटा प्राप्त करने की अनुमति दे सकते हैं, जिससे टेबल लुकअप से बचा जा सकता है। इससे कभी-कभी डेटा अतिरेक के बिना ही नॉर्मलाइज्ड रीड स्पीड के निकट पहुंचा जा सकता है।
- संयुक्त इंडेक्स: रेंज स्कैन को तेज करने के लिए कॉलम को सबसे अधिक चयनात्मक फील्ड्स के अनुसार क्रमबद्ध करें।
- आंशिक इंडेक्स: केवल डेटा के विशिष्ट उपसमूहों को इंडेक्स करें ताकि इंडेक्स का आकार और रखरखाव लागत कम हो।
मैटेरियलाइज्ड व्यूज
एक मैटेरियलाइज्ड व्यू एक डेटाबेस ऑब्जेक्ट है जो किसी प्रश्न के परिणाम को भौतिक रूप से स्टोर करता है। यह सिस्टम को बेस टेबल्स को बदले बिना डेटा का डेनॉर्मलाइज्ड दृश्य बनाए रखने की अनुमति देता है। जब आधारभूत डेटा में परिवर्तन होता है, तो मैटेरियलाइज्ड व्यू को ताजा किया जा सकता है।
- पूर्व-गणना:जटिल संघननों की पूर्व-गणना की जाती है।
- ताजा करने के चक्र:एक योजना के अनुसार चलाने या डेटा में परिवर्तन पर ट्रिगर करने के लिए सेट किया जा सकता है।
- पढ़ने का अलगाव:प्रश्न मैटेरियलाइज्ड व्यू पर टकराते हैं, जबकि लेखन बेस टेबल्स में जाते हैं।
पढ़ने के प्रतिकृति
वितरित आर्किटेक्चर में, पढ़ने के प्रतिकृति को डेटा की डेनॉर्मलाइज्ड प्रतिलिपि स्थापित करने के लिए कॉन्फ़िगर किया जा सकता है। प्राथमिक नोड लेखन का प्रबंधन करता है और सामान्यीकृत स्कीमा बनाए रखता है। प्रतिकृति असंगत रूप से अपडेट प्राप्त करती है और अनुकूलित स्कीमा के साथ पढ़ने के ट्रैफिक को सेवा करती है।
- पढ़ने को स्केल करें:बहुत सारे नोड्स के बीच लोड को वितरित करता है।
- भौगोलिक निकटता:डेटा को उपयोगकर्ता के पास रखता है।
- अंततः सुसंगतता:डेटा प्रसार में थोड़ी देरी को स्वीकार करता है।
⚠️ स्कीमा डिज़ाइन में आम गलतियाँ
स्पष्ट रणनीति के साथ भी, कार्यान्वयन त्रुटियाँ प्रदर्शन को कमजोर कर सकती हैं। डिज़ाइनकारों को आम गलतियों के खिलाफ सतर्क रहना चाहिए।
अत्यधिक नॉर्मलाइज़ेशन
एक ही अवधारणा के लिए बहुत सारी टेबलें बनाने से अत्यधिक जॉइन्स की स्थिति बनती है। जबकि 3NF एक मानक है, लेकिन पढ़ने वाले प्रणालियों में इसका अनबुद्ध अनुसरण प्रदर्शन को खराब कर सकता है। कभी-कभी 3NF के नियंत्रित उल्लंघन की आवश्यकता होती है।
असंगत डेनॉर्मलाइज़ेशन
एप्लिकेशन के केवल कुछ हिस्सों को डेनॉर्मलाइज़ करना और दूसरों को नॉर्मलाइज़ रखना एक टूटी हुई प्रणाली बनाता है। असंगतता विकासकर्ताओं के लिए प्रदर्शन विशेषताओं की भविष्यवाणी करने में कठिनाई पैदा करती है।
डेटा आयतन को नजरअंदाज करना
एक छोटे डेटासेट के लिए काम करने वाला स्कीमा जब आयतन बढ़ता है तो विफल हो सकता है। डेनॉर्मलाइज़ेशन रिकॉर्ड की संख्या के साथ भंडारण की आवश्यकता को रेखीय रूप से बढ़ाता है। यदि डेटा घातीय रूप से बढ़ता है, तो अतिरिक्तता के भंडारण लागत और रखरखाव के भार को नियंत्रित करना असंभव हो सकता है।
अपडेट लॉजिक की जटिलता
अतिरिक्त डेटा को सिंक करने के लिए लॉजिक को लागू करना आसान नहीं है। इसके लिए अक्सर ट्रिगर, एप्लिकेशन-स्तर के लेनदेन या मैसेज क्यू की आवश्यकता होती है। यदि यह लॉजिक विफल होता है, तो डेटा की खराबी चुपचाप हो जाती है।
🔍 कार्यान्वयन के विचार
डिज़ाइन से कार्यान्वयन में जाते समय, सफलता सुनिश्चित करने के लिए विशिष्ट तकनीकी विवरणों को संबोधित किया जाना चाहिए।
लेनदेन प्रबंधन
डेनॉर्मलाइज्ड अपडेट अक्सर कई पंक्तियों तक फैलते हैं। इन्हें एकल लेनदेन में लपेटा जाना चाहिए ताकि परमाणुता सुनिश्चित हो सके। यदि सिस्टम आधे रास्ते में क्रैश हो जाता है, तो डेटा को वापस ले जाना चाहिए ताकि असंगतता से बचा जा सके।
कैश परतें
सामान्यीकरण के बावजूद, मेमोरी में अक्सर एक्सेस किए जाने वाले डेटा को कैश करने से डेटाबेस लोड को और कम किया जा सकता है। जब आधार डेटा में परिवर्तन होता है, तो कैश को अमान्य करना या अपडेट करना चाहिए।
मॉनिटरिंग और मीट्रिक्स
निरंतर मॉनिटरिंग आवश्यक है। प्रश्न निष्पादन समय, लॉक प्रतिस्पर्धा और स्टोरेज वृद्धि का अनुसरण करें। यदि लेखन लेटेंसी बढ़ती है, तो यह इंगित कर सकता है कि सामान्यीकरण अपडेट तर्क बहुत भारी है।
📝 वार्ड डिजाइनकारों के लिए अंतिम विचार
सामान्यीकृत और असामान्यीकृत ईआरडी रणनीतियों के बीच चयन एक मूल आर्किटेक्चरल निर्णय है। यह निर्धारित करता है कि डेटा प्रणाली के माध्यम से कैसे प्रवाहित होता है और स्टोरेज इंजन एप्लिकेशन के साथ कैसे बातचीत करता है। प्रत्येक परिदृश्य के लिए एकमात्र सही उत्तर नहीं है।
- पहले मापें: अनुमानों पर आधारित अनुकूलन न करें। बॉटलनेक्स की पहचान करने के लिए वर्तमान लोड का प्रोफाइलिंग करें।
- सरल शुरू करें: सामान्यीकृत डिजाइन से शुरू करें। केवल तभी असामान्यीकृत करें जब प्रदर्शन मापदंड आवश्यकता का संकेत दें।
- निर्णयों को दस्तावेज़ीकृत करें: स्पष्ट रूप से दर्ज करें कि अतिरिक्तता क्यों लागू की गई थी। भविष्य के रखरखाव कर्मचारियों को व्यापार के लाभ-हानि को समझने की आवश्यकता होगी।
- विकास के लिए योजना बनाएं: स्कीमा डिजाइनों का विकास होना चाहिए। आज काम करने वाली रणनीति डेटा पैटर्न में परिवर्तन के साथ समायोजन की आवश्यकता महसूस कर सकती है।
जॉइन्स के तकनीकी विवरण, अतिरिक्तता की लागत और पढ़ने पर अधिक निर्भर लोड की विशिष्ट आवश्यकताओं को समझकर वार्ड डिजाइनकार ऐसी प्रणालियां डिजाइन कर सकते हैं जो दोनों बलवान और प्रदर्शनीय हों। लक्ष्य कठोर नियमों का पालन करना नहीं है, बल्कि विशिष्ट डेटा वातावरण के लिए सबसे उपयुक्त उपकरण का उपयोग करना है।