











Die Gestaltung einer robusten Datenarchitektur erfordert das Abwägen widersprüchlicher Prioritäten. Integrität, Leistungsfähigkeit und Wartbarkeit ziehen oft in verschiedene Richtungen. Wenn das System seinen Fokus auf leseintensive Operationen verlegt, erfahren die traditionellen Regeln der Schema-Design-Prinzipien erheblichen Druck. Das Entitäts-Beziehungs-Diagramm (ERD) wird zu mehr als einem statischen Bauplan; es fungiert als Vertrag zwischen der Anwendungslogik und der Speicherengine. Dieser Leitfaden untersucht die strategische Divergenz zwischen normalisierten und denormalisierten Ansätzen insbesondere im Kontext von hochvolumigen Lese-Workloads.
Die Entscheidung zwischen Normalisierung und Denormalisierung ist nicht binär. Sie erfordert das Verständnis der Kosten der Datenredundanz gegenüber den Kosten der Datenabrufung. In Umgebungen, in denen Leseoperationen die Transaktionsprotokolle dominieren, wird die Minimierung der Join-Komplexität oft zum primären Optimierungsziel. Allerdings schafft die Einführung von Redundanz neue Herausforderungen für die Datenkonsistenz und Schreiboperationen. Wir müssen die Vor- und Nachteile analysieren, um die geeignete strukturelle Strategie auszuwählen.
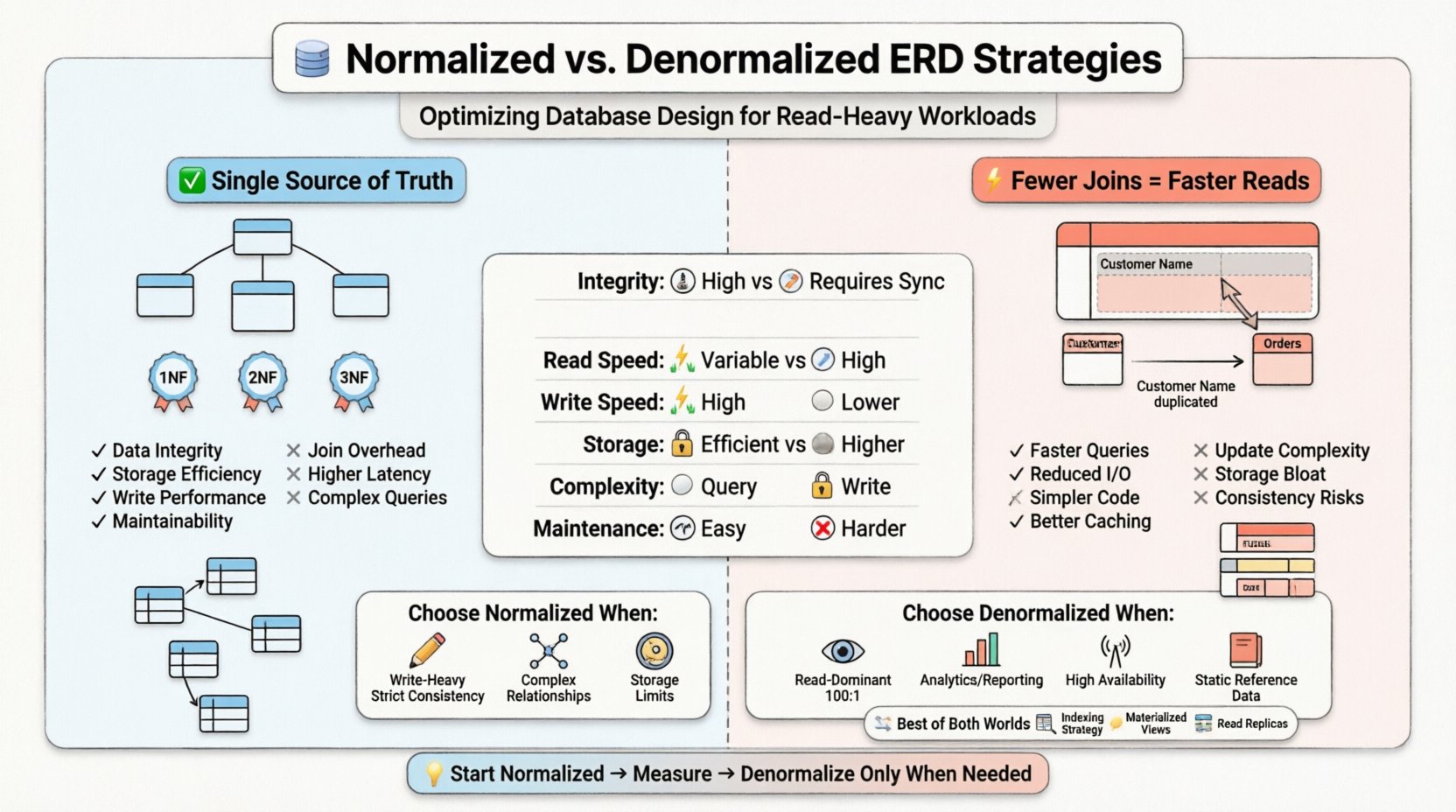
🏗️ Verständnis der Normalisierung im ERD-Design
Die Normalisierung ist ein systematischer Prozess, der eingesetzt wird, um Datenredundanz zu reduzieren und die Datenintegrität zu verbessern. Sie ordnet Attribute und Tabellen in einer relationalen Datenbank so an, dass Anomalien bei Einfüge-, Aktualisierungs- und Löschoperationen minimiert werden. Ziel ist es sicherzustellen, dass jeder Datenbestand an genau einer Stelle gespeichert wird.
Grundprinzipien der Normalisierung
Beim Erstellen eines Entitäts-Beziehungs-Diagramms halten Architekten typischerweise eine Hierarchie von Regeln ein, die als Normalformen bekannt sind. Jede Form behandelt spezifische Arten von Redundanz.
- Erste Normalform (1NF): Stellt sicher, dass jede Spalte atomare Werte enthält und keine sich wiederholenden Gruppen vorhanden sind. Dadurch entsteht eine flache Struktur für Zeilen.
- Zweite Normalform (2NF): Baut auf 1NF auf, indem partielle Abhängigkeiten beseitigt werden. Attribute müssen sich auf den gesamten Primärschlüssel beziehen, nicht nur auf einen Teil davon.
- Dritte Normalform (3NF): Beseitigt transitive Abhängigkeiten. Nicht-Schlüssel-Attribute dürfen sich nur auf den Primärschlüssel beziehen, nicht auf andere Nicht-Schlüssel-Attribute.
In einem stark normalisierten ERD sind die Tabellen feinkörnig. Eine Kundentabelle könnte getrennt von ihrer Adresstabelle existieren, die über einen Fremdschlüssel verknüpft ist. Eine Auftragstabelle verweist auf den Kunden, und eine Auftragspositionstabelle verweist auf den Auftrag. Diese Struktur stellt sicher, dass bei einem Umzug eines Kunden die Aktualisierung an einer einzigen Stelle erfolgt und automatisch propagiert wird.
Vorteile einer normalisierten Schema-Struktur
- Datenintegrität: Einzige Quellen der Wahrheit verringern das Risiko widersprüchlicher Informationen.
- Speichereffizienz: Weniger redundant gespeicherte Daten bedeuten ein kleineres Datenbank-Format.
- Schreibleistung: Einfüge-, Aktualisierungs- und Löschoperationen sind im Allgemeinen schneller, da weniger Zeilen über mehrere Tabellen hinweg berührt werden müssen.
- Wartbarkeit: Änderungen an Datenstrukturen sind lokalisiert. Das Hinzufügen eines neuen Attributs zu einer bestimmten Entität erfordert keine kaskadierenden Änderungen an unabhängigen Tabellen.
Nachteile für leseintensive Systeme
Während die Normalisierung in schreiblastigen oder gemischten Umgebungen hervorragt, führt sie zu Reibung bei Leseoperationen. Jeder Join, der erforderlich ist, um einen vollständigen Datensatz zusammenzustellen, stellt eine physische Operation auf der Festplatte oder im Speicher-Cache dar. Bei einem leseintensiven Workload muss das System möglicherweise Daten aus fünf oder sechs verschiedenen Tabellen abrufen, um eine einzelne Dashboard-Ansicht darzustellen.
- Join-Aufwand: Der Abfrageprozessor muss Schlüssel über Tabellen hinweg abgleichen. Dies verbraucht CPU-Zyklen und Speicherbandbreite.
- I/O-Operationen: Wenn Tabellen groß sind, muss die Speicherengine mehrere Suchvorgänge durchführen, um verwandte Daten abzurufen.
- Latenz: Die kumulierte Zeit mehrerer Abfragen erhöht die Antwortzeit für den Endbenutzer.
🔗 Der Denormalisierungsansatz
Denormalisierung ist die bewusste Einführung von Redundanz in die Datenbankgestaltung. Ziel ist es, das System für die Leseleistung zu optimieren, indem die Anzahl der benötigten Joins reduziert wird. In der Entitäts-Beziehungs-Diagramm äußert sich dies in Spalten, die Daten aus anderen Tabellen duplizieren, oder breiteren Tabellen, die verwandte Informationen zusammenfassen.
Wie die Denormalisierung funktioniert
Anstatt einen Fremdschlüssel zu speichern, um einen Kundennamen abzurufen, könnte eine denormalisierte Auftragstabelle den Kundennamen direkt speichern. Wenn sich der Kunde seinen Namen ändert, muss der Auftragseintrag aktualisiert oder markiert werden, oder das System akzeptiert, dass der Auftrag den Namen zum Zeitpunkt des Kaufs widerspiegelt.
Diese Strategie verlagert die Komplexität von der Lese- zur Schreibpfad. Das System muss nun die Logik für die Aktualisierung redundanter Datenkopien verarbeiten.
Vorteile für Lese-lastige Workloads
- Schnellere Abfrageausführung: Weniger Joins bedeuten geringeren Rechenaufwand.
- Reduzierter I/O-Aufwand: Mehr Daten werden bei einer einzigen Tabellenabfrage statt mehrerer Abfragen abgerufen.
- Einfachere Abfragen: Die Anwendungslogik benötigt weniger Logik, um Ergebnisse zusammenzustellen.
- Effizienz der Caching-Verarbeitung: Flachere Strukturen sind oft einfacher, effektiv im Speicher zu cachen.
Risiken und Nachteile
Die Hauptkosten der Denormalisierung sind die Datenkonsistenz. Wenn sich die Quelldaten ändern, müssen alle redundanten Kopien gleichzeitig aktualisiert werden. Ein Versäumnis führt zu veralteten Daten.
- Aktualisierungsanomalien: Die Aktualisierung eines Kundennamens erfordert das Auffinden und Ändern jedes Auftragseintrags, der auf diesen Kunden verweist.
- Speicherplatzschwellung: Die Replikation von Daten erhöht die Gesamtgröße der Datenbank.
- Komplexität bei Schreibvorgängen: Schreibtransaktionen werden komplexer, oft erfordern sie mehr Sperren oder längere Transaktionszeiten.
- Schema-Starrheit: Das Hinzufügen eines neuen Feldes kann das Aktualisieren mehrerer Tabellen erfordern, nicht nur einer.
📈 Analyse der Merkmale von Lese-lastigen Workloads
Um die richtige Strategie zu wählen, muss man die spezifische Art des Workloads verstehen. Lese-lastige Systeme unterscheiden sich erheblich von transaktionalen Systemen, bei denen Schreibvorgänge häufig und kritisch sind.
Abfragemuster
Führt die Anwendung komplexe analytische Abfragen oder einfache Abfragen durch? Komplexe Abfragen, die Aggregationen über viele Tabellen beinhalten, profitieren von der Denormalisierung. Einfache Abfragen nach ID könnten mit Normalisierung ausreichend gut funktionieren, wenn Indizes gut abgestimmt sind.
- Punktabfragen: Abrufen eines einzelnen Datensatzes anhand der ID.
- Bereichsabfragen:Abrufen einer Gruppe von Datensätzen innerhalb eines Datumsbereichs.
- Aggregationen:Berechnung von Summen, Durchschnitten oder Zählungen über große Datensätze.
Latenzanforderungen
Hochfrequenzhandelsplattformen oder Echtzeit-Dashboards können die durch komplexe Joins verursachte Latenz nicht verkraften. In diesen Szenarien ist eine Denormalisierung oft eine Notwendigkeit statt eine Wahl. Umgekehrt reicht bei Anwendungen, die einige Hundert Millisekunden Verzögerung tolerieren können, möglicherweise eine Normalisierung aus, sofern geeignete Indizes vorhanden sind.
Toleranz gegenüber Datenkonsistenz
Wird sofortige Konsistenz benötigt? Wenn das System eine spätere Konsistenz tolerieren kann, wird die Denormalisierung viel sicherer. Lese-Replicas oder asynchrone Aktualisierungsmechanismen können die Synchronisierung redundanter Daten bewältigen, ohne Schreibvorgänge zu blockieren.
📋 Strategische Vergleichstabelle
Die folgende Tabelle fasst die wesentlichen Unterschiede zwischen den beiden Ansätzen im Kontext der Datenbankgestaltung zusammen.
| Funktion | Normalisiertes Schema | Denormalisiertes Schema |
|---|---|---|
| Datenintegrität | Hoch (Einziges Quellensystem für die Wahrheit) | Niedriger (Erfordert Synchronisationslogik) |
| Lesegeschwindigkeit | Variabel (hängt von Joins ab) | Hoch (Weniger Joins) |
| Schreibgeschwindigkeit | Hoch (Minimale Redundanz) | Niedriger (Aktualisierung mehrerer Zeilen) |
| Speicherplatznutzung | Effizient | Höher (Redundante Daten) |
| Komplexität | Hohe Abfragekomplexität | Hohe Schreibkomplexität |
| Wartbarkeit | Einfach bei Schemaänderungen | Schwieriger bei Schemaänderungen |
🧭 Entscheidungsrahmen für Architekten
Die Auswahl des richtigen Weges erfordert die Bewertung der geschäftlichen Anforderungen im Vergleich zu technischen Einschränkungen. Der folgende Rahmen hilft bei der Leitung des Entscheidungsprozesses.
Wann man Normalisierung wählen sollte
- Schreibintensität: Wenn Schreibvorgänge im Verhältnis zu Lesevorgängen häufig auftreten, verhindert die Normalisierung Aktualisierungsanomalien.
- Strenge Konsistenz: Finanzsysteme oder medizinische Aufzeichnungen erfordern oft strenge ACID-Konformität, bei der Redundanz inakzeptabel ist.
- Komplexe Beziehungen: Wenn Entitäten viele-zu-viele-Beziehungen haben, die häufig wechseln, verarbeitet die Normalisierung die Abbildung sauber.
- Speicherbeschränkungen: Wenn Speicherplatz knapp ist, ist die Minimierung von Redundanz vorteilhaft.
Wann man Denormalisierung wählen sollte
- Lesedominanz: Wenn Lesevorgänge deutlich häufiger sind als Schreibvorgänge (z. B. 100:1), überwiegen die Leistungsverbesserungen durch weniger Joins die Schreibkosten.
- Berichterstattung und Analytik: Data-Warehouses und Berichtssysteme denormalisieren oft, um Aggregationsabfragen zu beschleunigen.
- Hohe Verfügbarkeit: Verteilte Systeme können Daten denormalisieren, um Lesevorgänge auf lokalen Knoten ohne Netzwerkwechsel zu anderen Partitionen zu ermöglichen.
- Statische Referenzdaten: Daten, die selten geändert werden (z. B. Ländercodes, Währungssätze), sind ideale Kandidaten für Duplikation.
🛠️ Hybridansätze und Optimierung
Es ist selten notwendig, eine Extremposition gegenüber der anderen zu wählen. Moderne Systeme setzen oft hybride Strategien ein, um die Vorteile beider Modelle auszugleichen.
Indizierungsstrategien
Bevor Sie denormalisieren, stellen Sie sicher, dass das normalisierte Schema vollständig indiziert ist. Deckende Indizes ermöglichen es dem Speicher-Engine, alle notwendigen Daten direkt aus dem Index abzurufen, wodurch Tabellen-Abfragen vermieden werden. Dadurch kann man manchmal nahezu denormalisierte Leseleistungen erzielen, ohne Datenredundanz.
- Komposite Indizes: Ordnen Sie die Spalten nach den selektivsten Feldern, um Bereichssuchen zu beschleunigen.
- Teilindizes: Indizieren Sie nur bestimmte Datenuntergruppen, um die Indexgröße und die Wartungskosten zu reduzieren.
Materialisierte Ansichten
Eine materialisierte Ansicht ist ein Datenbankobjekt, das das Ergebnis einer Abfrage physisch speichert. Sie ermöglicht es dem System, eine denormalisierte Ansicht der Daten aufrechtzuerhalten, ohne die Basis-Tabellen zu verändern. Wenn die zugrundeliegenden Daten sich ändern, kann die materialisierte Ansicht aktualisiert werden.
- Vorab-Berechnung:Komplexe Aggregationen werden im Voraus berechnet.
- Aktualisierungszyklen:Kann so eingestellt werden, dass sie nach einem Zeitplan ausgeführt werden oder bei Datenänderungen ausgelöst werden.
- Lesetrennung:Abfragen greifen auf die materialisierte Ansicht zu, während Schreibvorgänge in die Basis-Tabellen gehen.
Lesereplikate
In verteilten Architekturen können Lesereplikate so konfiguriert werden, dass sie denormalisierte Kopien von Daten hosten. Der primäre Knoten verarbeitet Schreibvorgänge und erhält die normalisierte Schemastruktur aufrecht. Die Replikat erhält Aktualisierungen asynchron und dient Leseanfragen mit dem optimierten Schema.
- Skalierung von Lesevorgängen:Verteilt die Last auf mehrere Knoten.
- Geografische Nähe:Platziert die Daten näher am Benutzer.
- Eventuelle Konsistenz:Akzeptiert eine geringe Verzögerung bei der Datenweiterleitung.
⚠️ Häufige Fehler bei der Schema-Design
Selbst mit einer klaren Strategie können Implementierungsfehler die Leistung beeinträchtigen. Architekten müssen wachsam bleiben gegenüber häufigen Fehlern.
Über-Normalisierung
Die Erstellung zu vieler Tabellen für ein einzelnes Konzept kann zu übermäßigen Joins führen. Obwohl 3NF eine Norm ist, kann die blindlings strikte Einhaltung in Lese-lastigen Systemen die Leistung beeinträchtigen. Manchmal ist ein kontrollierter Verstoß gegen 3NF notwendig.
Inkonsistente Denormalisierung
Die Denormalisierung nur bestimmter Teile der Anwendung, während andere normalisiert bleiben, führt zu einem fragmentierten System. Die Inkonsistenz macht es für Entwickler schwierig, die Leistungsmerkmale vorherzusagen.
Ignorieren des Datenvolumens
Ein Schema, das für ein kleines Datenvolumen funktioniert, kann versagen, wenn das Volumen wächst. Die Denormalisierung erhöht die Speicheranforderungen linear mit der Anzahl der Datensätze. Wenn die Daten exponentiell wachsen, können die Speicherkosten und die Wartungsaufwände durch Redundanz unbeherrschbar werden.
Komplexität der Aktualisierungslogik
Die Implementierung der Logik, um redundante Daten synchron zu halten, ist nicht trivial. Oft erfordert dies Trigger, Transaktionen auf Anwendungsebene oder Nachrichtenwarteschlangen. Wenn diese Logik fehlschlägt, tritt eine Datenkorruption stumm auf.
🔍 Implementierungsgesichtspunkte
Beim Übergang von der Gestaltung zur Implementierung müssen spezifische technische Details berücksichtigt werden, um den Erfolg zu gewährleisten.
Transaktionsverwaltung
Denormalisierte Aktualisierungen erstrecken sich oft über mehrere Zeilen. Diese müssen in einer einzigen Transaktion zusammengefasst werden, um die Atomsicherheit zu gewährleisten. Wenn das System mitten im Prozess abstürzt, muss die Datenbank rückgängig gemacht werden, um Inkonsistenzen zu vermeiden.
Caching-Ebenen
Selbst bei einer De-Normalisierung kann das Cachen von häufig zugegriffenen Daten im Speicher die Datenbanklast weiter reduzieren. Der Cache sollte ungültig gemacht oder aktualisiert werden, wenn sich die zugrundeliegenden Daten ändern.
Überwachung und Metriken
Eine kontinuierliche Überwachung ist unerlässlich. Verfolgen Sie die Ausführungszeiten von Abfragen, die Sperrkonkurrenz und das Speicherwachstum. Wenn die Schreiblatenz stark ansteigt, könnte dies darauf hindeuten, dass die Logik zur De-Normalisierung zu aufwendig ist.
📝 Endgültige Überlegungen für Architekten
Die Wahl zwischen normalisierten und de-normalisierten ERD-Strategien ist eine grundlegende architektonische Entscheidung. Sie bestimmt, wie Daten durch das System fließen, und wie die Speicherengine mit der Anwendung interagiert. Es gibt keine einzig richtige Antwort, die für jedes Szenario gilt.
- Zuerst messen: Optimieren Sie nicht aufgrund von Annahmen. Profilieren Sie die aktuelle Arbeitslast, um Engpässe zu identifizieren.
- Einfach beginnen: Beginnen Sie mit einer normalisierten Gestaltung. De-Normalisieren Sie erst, wenn Leistungsmetriken einen Bedarf anzeigen.
- Entscheidungen dokumentieren: Dokumentieren Sie klar, warum Redundanz eingeführt wurde. Zukünftige Wartende müssen die Abwägungen verstehen.
- Für die Entwicklung planen: Schema-Entwürfe müssen sich weiterentwickeln. Eine Strategie, die heute funktioniert, könnte Anpassungen erfordern, wenn sich die Datenmuster ändern.
Durch das Verständnis der Mechanismen von Joins, der Kosten der Redundanz und der spezifischen Anforderungen von lesedichten Workloads können Architekten Systeme gestalten, die sowohl robust als auch leistungsfähig sind. Das Ziel besteht nicht darin, eine starre Regel zu befolgen, sondern das am besten geeignete Werkzeug für die jeweilige Datenumgebung anzuwenden.